







友情提醒:
先看目录,了解文章结构,点击目录可跳转到文章指定位置。
第一章、快速了解中文乱码
1.1)编码相关概念介绍
1.1.1)字符集和字符编码方案的区别
字符集
字符集是一组字符的集合,它定义了可以在文本中使用的字符的范围。
字符编码方案
计算机只能理解和处理二进制数据。计算机无法直接处理中文,英文等字符信息。而我们作为人类,也很难看懂二进制数据。
于是出现了字符编码方案,编码方案是一种将字符集中的字符映射到数字或字节序列的规则。作用就好比是翻译一样,将文本信息(字母、数字、字符、表情符号)翻译成计算机可以理解的唯一的二进制数据。
总结:字符集定义了可以使用的字符,而编码方案定义了如何在计算机中表示和存储这些字符。
1.1.2)ASCII字符集介绍
ASCII(美国信息交换标准代码)是一种字符编码标准,在ASCII编码中,每个字符都用唯一的7位二进制数表示(共128个字符)。例如,大写字母"A"的ASCII码是65,小写字母"a"的ASCII码是97。
对应关系如图:
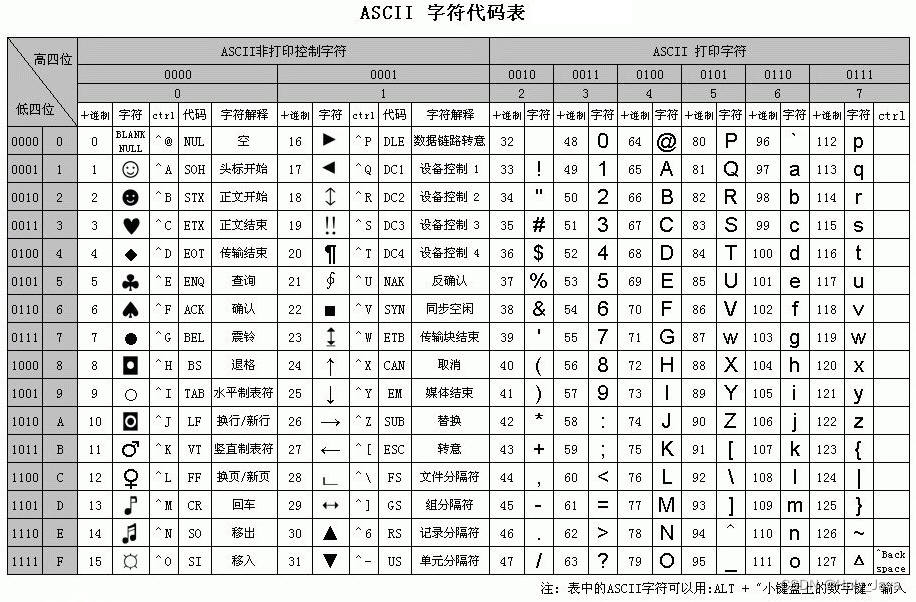
因为最多只能表示128个字符,而且还只有英文字符和一些特殊符合,所以对于表示中文字符还有一些其他字符的时候有局限性。
于是Unicode字符集闪亮登场。
1.1.3)Unicode字符集介绍
Unicode被称为万国码,是ASCII的超集,Unicode编码包含了ASCII编码中的所有字符,同时还包含了更多的字符和符号。这是为了解决ASCII编码字符不够用的问题。
Unicode编码使用16位或更多位的二进制数来表示字符,可以表示1,111,998个可能的编码字符。覆盖了全球范围内几乎所有语言和符号的需求。因此成为了现代计算机系统中文本处理和国际化的标准。
1.2)字符编码方案
1.2.1)ASCII编码方案
ASCII编码是最早的ASCII字符集对应的字符编码方案,用于在计算机和通信设备中表示文本数据。虽然说ASCII编码方案慢慢在被UTF-8编码方案取代,但是仍然常用于一些旧系统、嵌入式系统、网络通信协议以及特定的数据交换格式中
1.2.2)UTF-8、UTF-16、UTF-32编码方案
UTF-8编码: 基于Unicode的字符编码方案,可变长度的编码方案,它使用1到4个字节来表示Unicode字符。UTF-8编码兼容ASCII编码,因此ASCII文本也是有效的UTF-8文本。这使它成为互联网和许多计算机系统中最常用的字符编码方案。
UTF-16编码: 固定长度的编码方案,使用2个字节或4个字节来表示Unicode字符,在存储时可能会占用更多的空间。
UTF-32编码: 固定长度的编码方案,使用4个字节来表示所有的Unicode字符。在存储时可能会占用更多的空间。
区别:
UTF-16和UTF-32在存储时比UTF-8占用更多的空间。
1.2.3)GBK编码方案
**GBK 编码:**是一种简体中文的字符集编码方式,在GB2312编码的基础上进行了扩展,不适用于其他语言的字符表示。使用双字节来表示字符,其中包括了汉字、英文字母、数字和标点符号等。
第二章、乱码产生的原因
2.1)导致乱码的原因:乱码多为中文乱码
2.1.1)错误的编码识别
1、GBK方式保存文本,以UTF-8方式来解码,由于UTF-8和GBK编码方式不一致,就会导致乱码。
原始中文字符:"你好世界"
GBK编码保存后的字符:D6D0BAF3CAAC
以UTF-8方式解码后可能出现的乱码:ä½ å¥½ä¸-ç-¨ç-
2、以UTF-8方式保存文本,以GBK的方式解码,由于UTF-8和GBK编码方式不一致,就会导致乱码。
原始中文字符:"你好世界"
UTF-8编码保存后的字符:E4BDA0E5A5BDE4B896E7958C
以GBK方式解码后可能出现的乱码:浣犲ソ浣犲ソ涓
2.1.2)多次编码转换
在文本处理过程中,假设一个文本文件本身是UTF-8编码,但以GBK编码进行转换,然后再将其以UTF-8编码进行转换,这样就会导致编码方式的混乱。由于UTF-8和GBK使用不同的字节序列来表示字符,多次编码转换可能会导致字符的编码方式混乱,最终导致中文乱码的出现。
2.1.3)中文乱码分类表
| 乱码原因 | 未乱码的原文本 | 乱码后的文本 |
|---|---|---|
| GBK保存文本、以UTF-8编码读取 | 举头望明月低头思故乡666qwer | ��ͷ�����µ�ͷ˼����666qwer |
| GBK保存文本、以UTF-8编码读取,再次用GBK的格式再次解码 | 举头望明月低头思故乡666qwer | 锟斤拷头锟斤拷锟斤拷锟铰碉拷头思锟斤拷锟斤拷666qwer |
| UTF-8保存文本、以GBK方式读取 | 举头望明月低头思故乡666qwer | 涓惧ご鏈涙槑鏈堜綆澶存�濇晠涔�666qwer |
| UTF-8保存文本、以GBK编码读取,再次用UTF-8的格式再次解码 | 举头望明月低头思故乡666qwer | 举头望明月低头�?�故�?666qwer |
| 以ISO8859-1方式读取UTF-8编码的中文字符串 | 举头望明月低头思故乡666qwer | 举头望明月低头æ€æ•ä¹¡666qwer |
| 以ISO-8859-1方式读取GBK编码 | 举头望明月低头思故乡666qwer | ¾ÙÍ·ÍûÃ÷ÔµÍͷ˼¹ÊÏç666qwer |
2.2)用代码复现中文乱码
2.2.1)GBK保存文本、UTF-8解码

import java.io.*;
public class GBKReader {
public static void main(String[] args) {
String gbkString = "举头望明月低头思故乡666qwer"; // GBK编码的中文字符串
try {
// 以GBK方式解码为字节数组
byte[] gbkBytes = gbkString.getBytes("GBK");
// 以UTF-8方式解码为字符串
String utf8String = new String(gbkBytes, "UTF-8");
// 输出结果
System.out.println("Original GBK String: " + gbkString);
System.out.println("Decoded UTF-8 String: " + utf8String);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
}
2.2.2)GBK保存文本、UTF-8解码、GBK再次解码

package com.test.springboot.test;
import java.io.UnsupportedEncodingException;
public class EncodingExample {
public static void main(String[] args) {
String originalString = "举头望明月低头思故乡666qwer"; // 要保存的文本
try {
// 以GBK编码保存文本
byte[] gbkBytes = originalString.getBytes("GBK");
// 用UTF-8方式解码
String utf8String = new String(gbkBytes, "UTF-8");
// 再次用GBK格式解码
String decodedString = new String(utf8String.getBytes("UTF-8"), "GBK");
// 输出结果
System.out.println("Original String: " + originalString);
System.out.println("Decoded String: " + decodedString);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
}
2.2.3)UTF-8保存文本、GBK解码

public class GBKReader {
public static void main(String[] args) {
String utf8String = "你好"; // UTF-8编码的中文字符串
try {
// 以UTF-8方式解码为字节数组
byte[] utf8Bytes = utf8String.getBytes("UTF-8");
// 以GBK方式解码为字符串
String gbkString = new String(utf8Bytes, "GBK");
// 输出结果
System.out.println("Original UTF-8 String: " + utf8String);
System.out.println("Decoded GBK String: " + gbkString);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
}
2.2.4)UTF-8保存文本、GBK解码、UTF-8再次解码

import java.io.*;
public class GBKReader {
public static void main(String[] args) {
String originalString = "举头望明月低头思故乡666qwer";
try {
// 以UTF-8方式编码为字节数组
byte[] utf8Bytes = originalString.getBytes("UTF-8");
// 以GBK方式解码为字符串
String gbkString = new String(utf8Bytes, "GBK");
// 以UTF-8方式再次解码为字符串
String utf8DecodedString = new String(gbkString.getBytes("GBK"), "UTF-8");
// 输出结果
System.out.println("Original String: " + originalString);
System.out.println("Decoded GBK String: " + gbkString);
System.out.println("Decoded UTF-8 String: " + utf8DecodedString);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
}
2.2.5)ISO8859-1方式读取UTF-8编码

import java.io.*;
public class GBKReader {
public static void main(String[] args) {
String utf8String = "举头望明月低头思故乡666qwer"; // UTF-8编码的中文字符串
try {
// 以UTF-8方式解码为字节数组
byte[] utf8Bytes = utf8String.getBytes("UTF-8");
// 以ISO-8859-1方式解码为字符串
String isoString = new String(utf8Bytes, "ISO-8859-1");
// 输出结果
System.out.println("Original UTF-8 String: " + utf8String);
System.out.println("Decoded ISO-8859-1 String: " + isoString);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
}
2.2.6)以ISO-8859-1方式读取GBK编码

public class ISO8859Reader {
public static void main(String[] args) {
String gbkString = "举头望明月低头思故乡666qwer"; // GBK编码的字符串
try {
// 以GBK方式解码为字节数组
byte[] gbkBytes = gbkString.getBytes("GBK");
// 以ISO-8859-1方式解码为字符串
String isoString = new String(gbkBytes, "ISO-8859-1");
// 输出结果
System.out.println("Original GBK String: " + gbkString);
System.out.println("Decoded ISO-8859-1 String: " + isoString);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
}
第二章、乱码问题结合实际解决
2.1)各类软件乱码
2.1.1)Windows的tomcat启动,控制台乱码
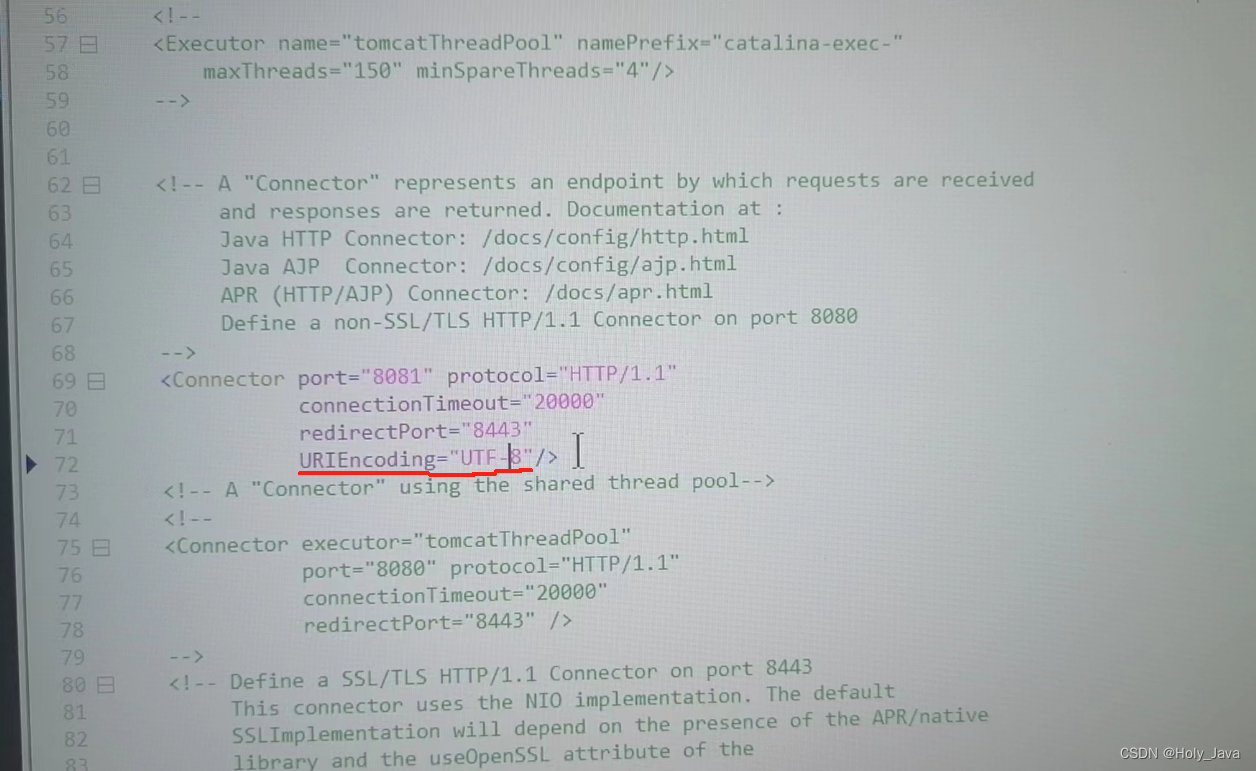
这是因为Windows默认为GBK编码,需要修改tomcat的logging.properties 配置。
在 Tomcat 的apache-tomcat-9.0.30\conf\server.xml 文件中的 Connector 标签中添加 URIEncoding=“UTF-8” 属性。
URIEncoding="UTF-8
如图:
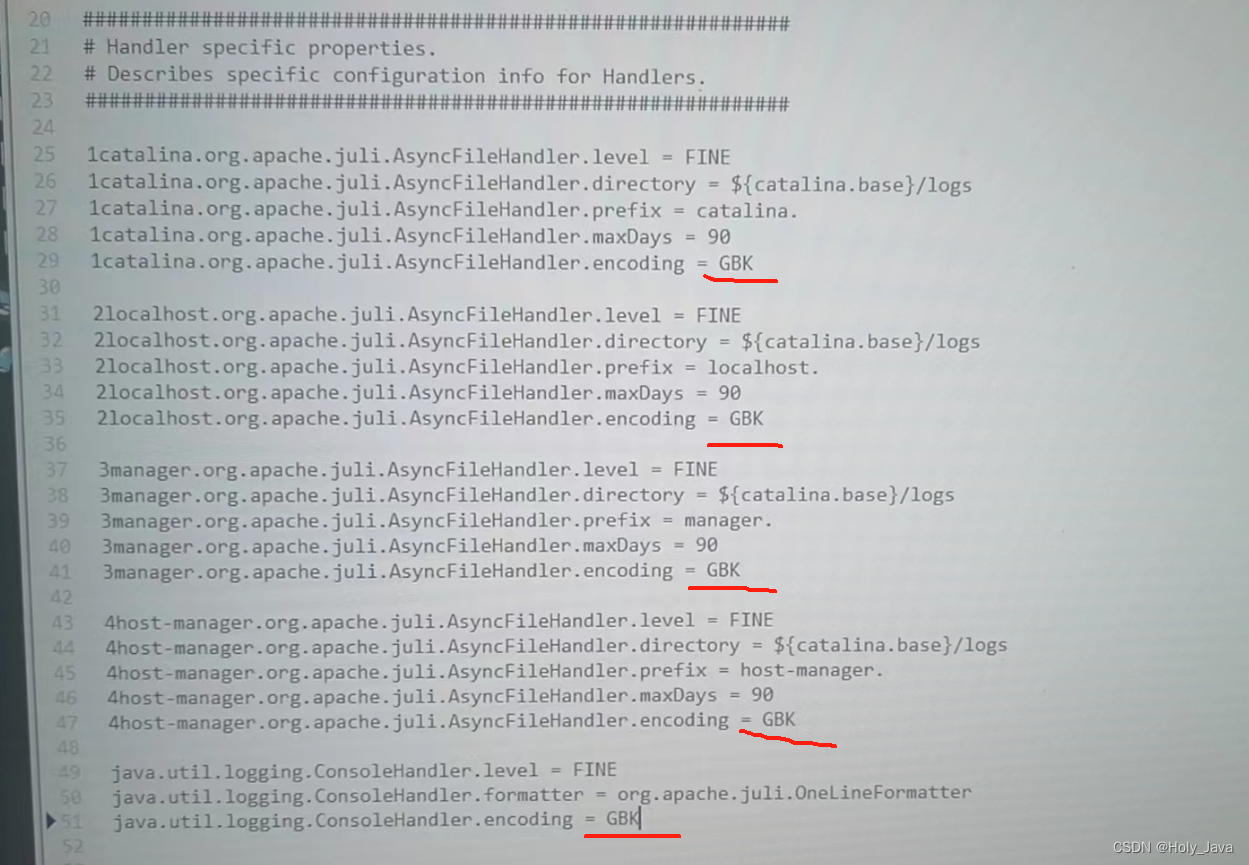
②在 Tomcat 的pache-tomcat-9.0.30\conf\logging.properties 文件中修改UTF-8,变成GBK。
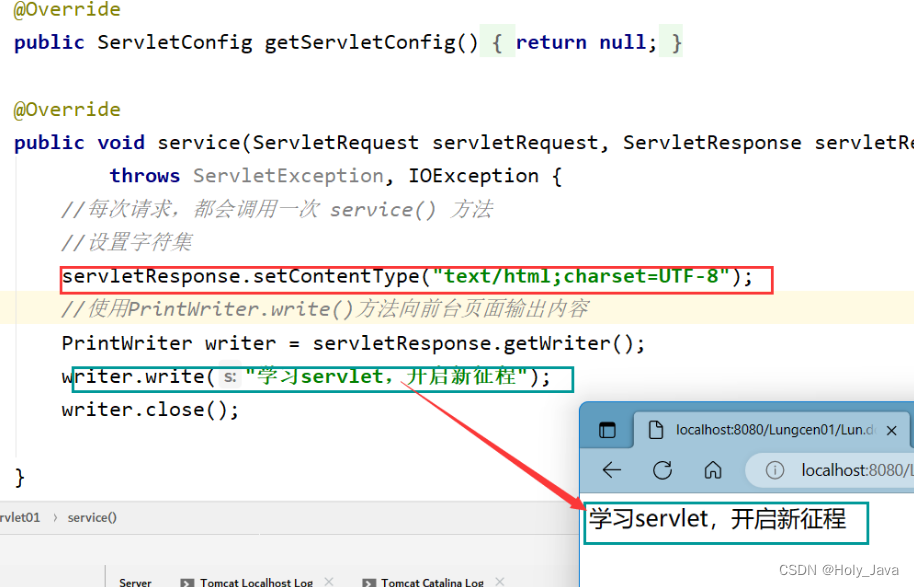
2.1.2)在Servlet中输出中文乱码
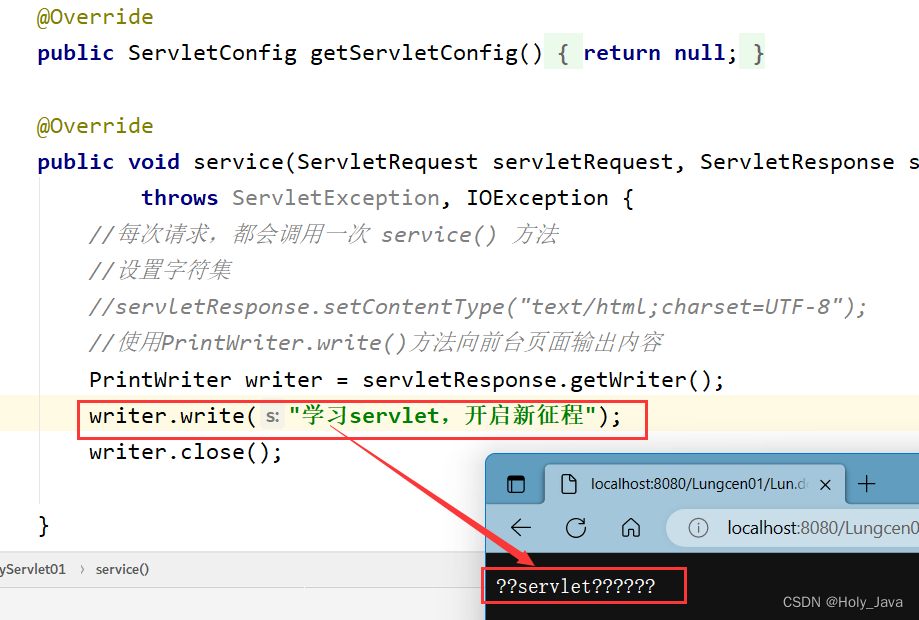
需要设置响应的编码,告诉浏览器编码格式是UTF-8
servletResponse.setContentType("text/html;charset=UTF-8");
设置后:
2.1.3)cmd控制台运行java命令显示乱码
问题
使用cmd命令窗口,运行java命令时候出现中文乱码
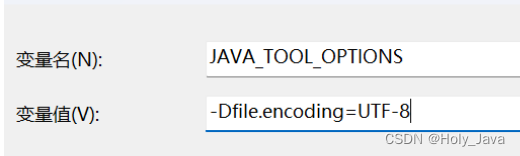
解决
桌面上我的电脑图标—》右击选择属性—》高级系统设置—》高级—》环境变量—》系统变量栏点击新建:框中分别输入如下值
JAVA_TOOL_OPTIONS
-Dfile.encoding=UTF-8
打开cmd命令行,运行javac命令,此时不再乱码,成功解决
2.1.4)向webservice接口传递中文,返回的数据中文乱码
可能是因为webservice默认是UTF-8的编码,我们传过去的中文不是UTF-8编码而是GBK,于是webservice返回给我们的数据就可能乱码。
解决:调用WebService之前,把含有中文的字符串转为UTF-8的编码,然后用转换后的字符串去调用WebService
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
public class EncodingConverter {
public static String getUnicodeString(String sValue) {
// 将字符串从默认编码转换为UTF-8编码的Unicode字符串
byte[] utf8Bytes = sValue.getBytes(StandardCharsets.UTF_8);
return new String(utf8Bytes, StandardCharsets.UTF_8);
}
public static void main(String[] args) {
String inputString = "你好,世界!"; // 输入的字符串
String unicodeString = getUnicodeString(inputString);
System.out.println(unicodeString); // 输出转换后的Unicode字符串
}
}
2.1.5)navicat中文注释乱码
乱码情况如图
乱码原因:使用的是Windows系统,默认编码为GBK。而navicat连接属性中设置了65001 UTF-8。导致编码冲突,如图:

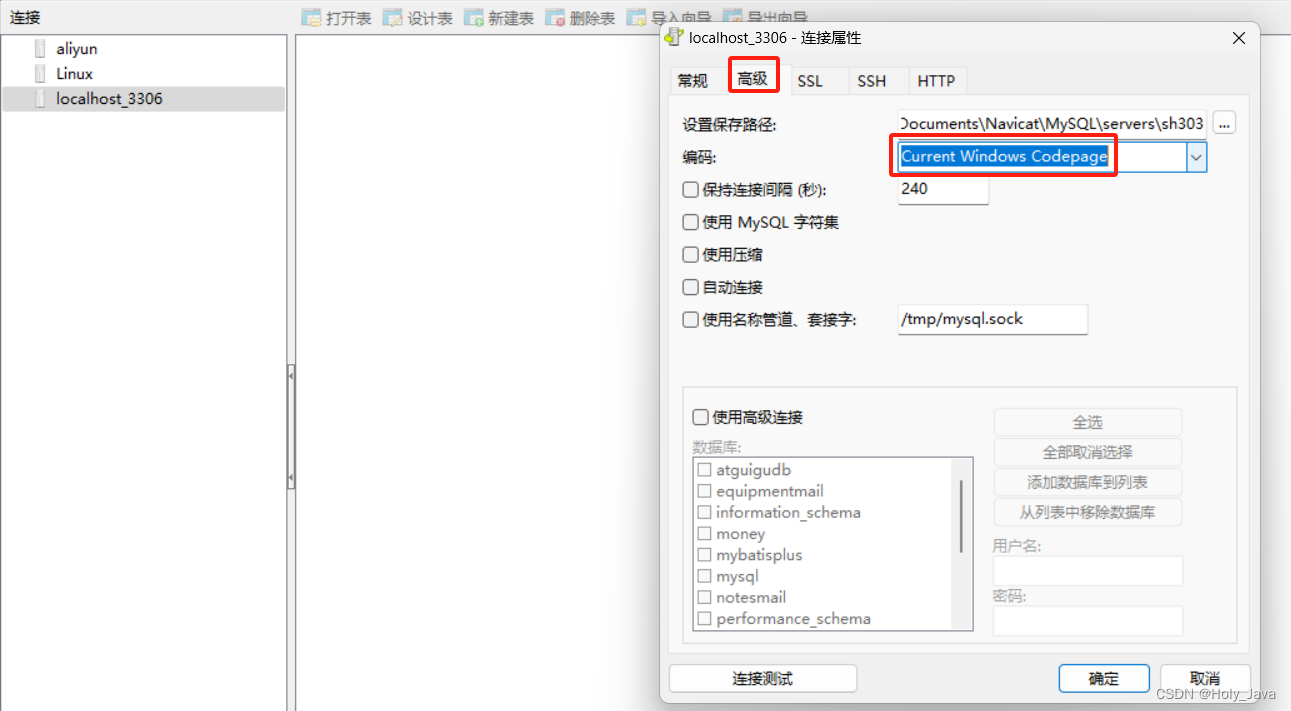
Navicate中右键数据库连接→连接属性→高级
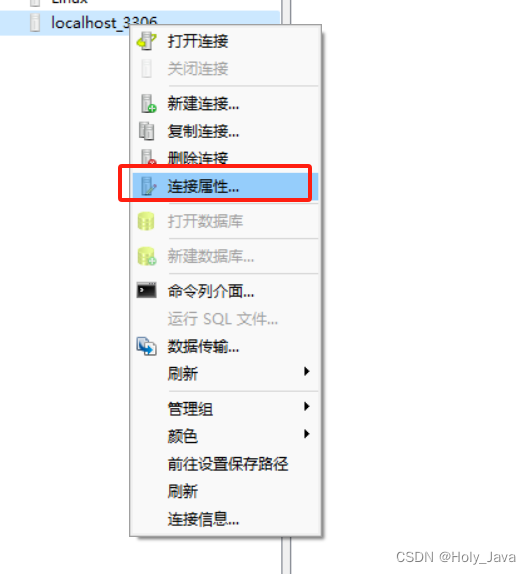
不勾选使用MySQL字符集。同事修改连接属性为Current Windows Codepage
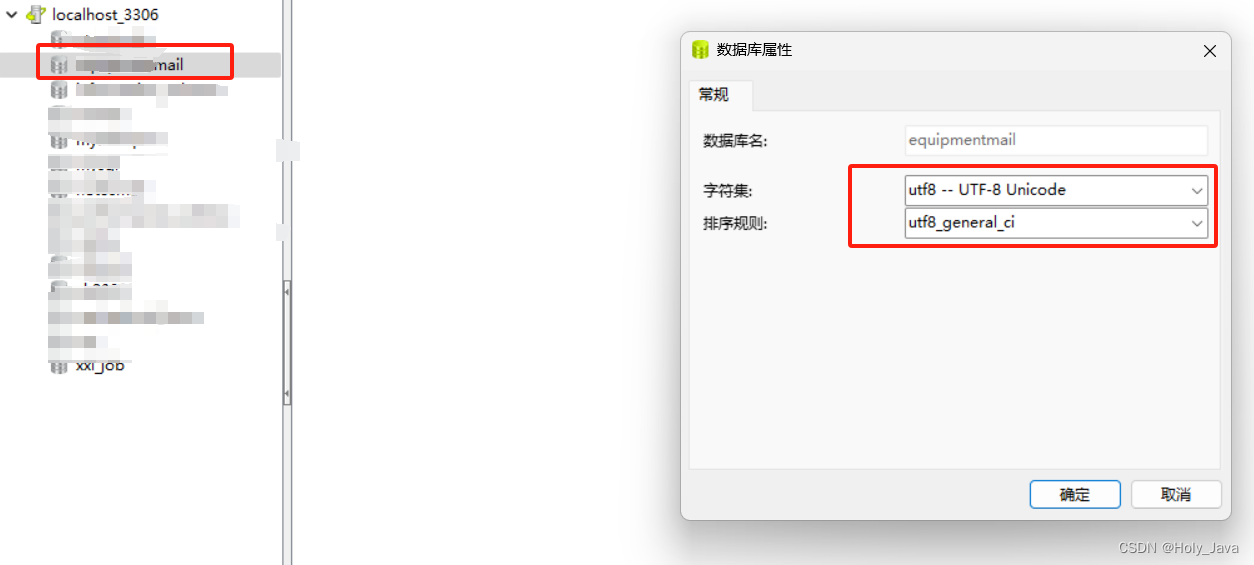
连接属性不影响数据库属性,依然为UTF-8
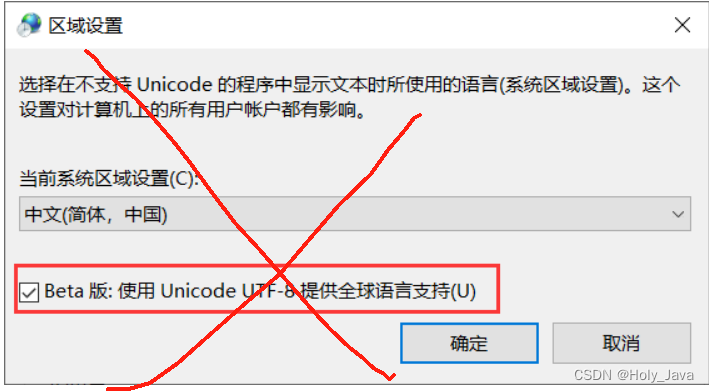
需要注意的是:不要去直接修改Windows的编码方案为UTF-8,那会导致文件路径出现异常,同时影响各类软件的使用。如图:别这么改
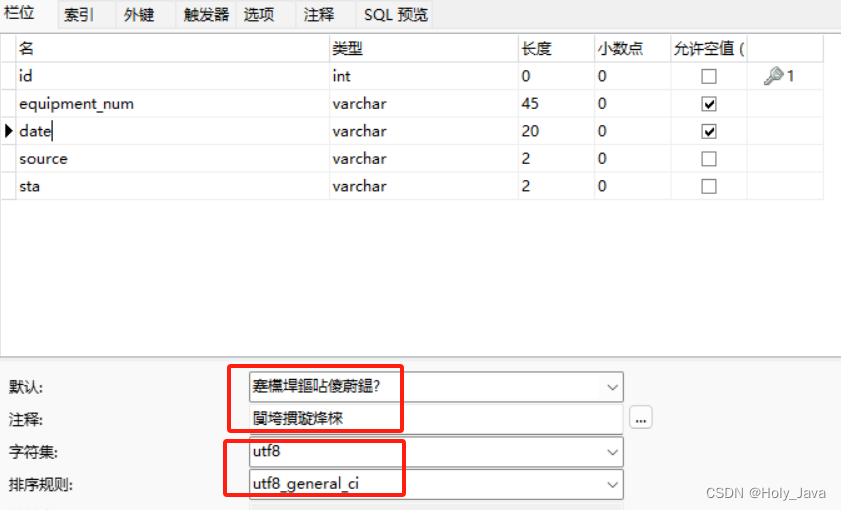
2.1.6)navicat10.1.7数据乱码
建数据库和数据表时我选择的编码是utf8mb4_unicode_ci,而navicat10版本不支持这个字符编码只支持utf8_general_ci。更新navicat到最新版本就好
2.1.7)workbench数据乱码
设置MySQL 服务器字符集: 这是数据库服务器的默认字符集。
SHOW VARIABLES LIKE 'character_set_server';
SHOW VARIABLES LIKE 'collation_server';
确认 character_set_server 的值是否为 utf8mb4,collation_server 的值是否为 utf8mb4_unicode_ci 或 utf8mb4_general_ci。
如果不是,需要修改 MySQL 服务器的配置文件 (my.cnf 或 my.ini),并重启 MySQL 服务器。
设置数据库字符集: 这是特定数据库的字符集。
SHOW VARIABLES LIKE 'character_set_database';
SHOW VARIABLES LIKE 'collation_database';
确认 character_set_database 的值是否为 utf8mb4,collation_database 的值是否为 utf8mb4_unicode_ci 或 utf8mb4_general_ci。
如果不是,可以使用以下 SQL 语句修改数据库字符集:
ALTER DATABASE <database_name> CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
设置表字符集: 这是特定表的字符集。
SHOW CREATE TABLE <table_name>;
在输出结果中,查找 DEFAULT CHARSET= 和 COLLATE=。 确认 DEFAULT CHARSET 的值是否为 utf8mb4,COLLATE 的值
是否为 utf8mb4_unicode_ci 或 utf8mb4_general_ci。 如果不是,可以使用以下 SQL 语句修改表字符集:
ALTER TABLE <table_name> CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
设置列字符集: 这是特定列的字符集。
如果你的 name 列的字符集与表字符集不同,可以使用以下 SQL 语句修改列字符集:
ALTER TABLE <table_name> MODIFY `name` VARCHAR(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
设置 Navicat 字符集:
在 Navicat 中,选择 "工具" -> "选项"。
在 "数据" -> "连接" 中,设置 "编码" 为 "UTF-8"。
在 "数据" -> "高级" 中,设置 "使用 Unicode" 为 "是"。
设置 MySQL Workbench 字符集:
在 MySQL Workbench 中,选择 "Edit" -> "Preferences"。
在 "General" -> "Appearance" 中,设置 "Font" 为支持中文的字体,例如 "SimSun" 或 "Microsoft YaHei"。
在 "SQL Editor" 中,设置 "Default Character Set" 为 "utf8mb4"。
在连接数据库时,确保连接设置中的 "Character Set" 为 "utf8mb4"。
2.2)IDEA相关设置,防止乱码
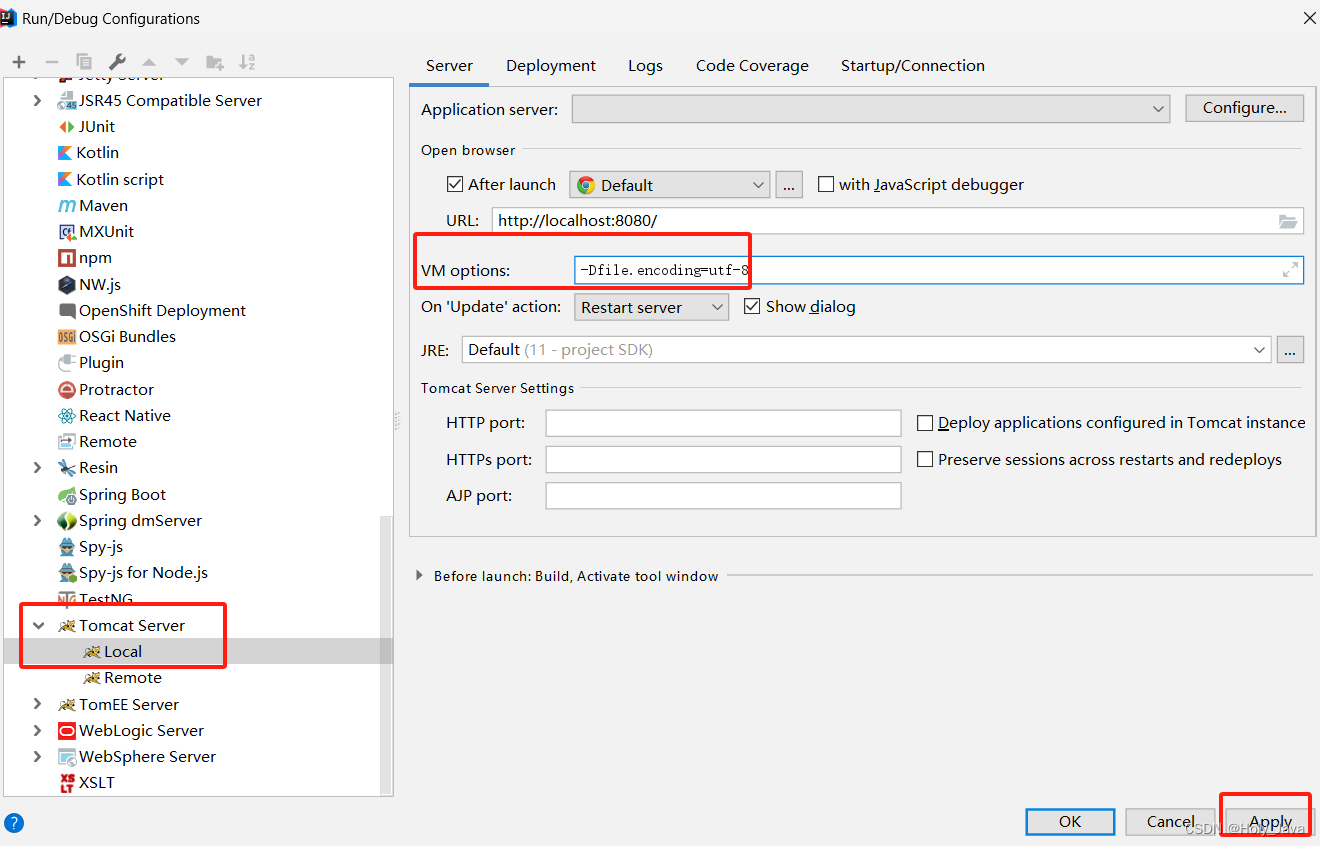
2.2.1)IDEA中tomcat配置
找到Edit Configurations
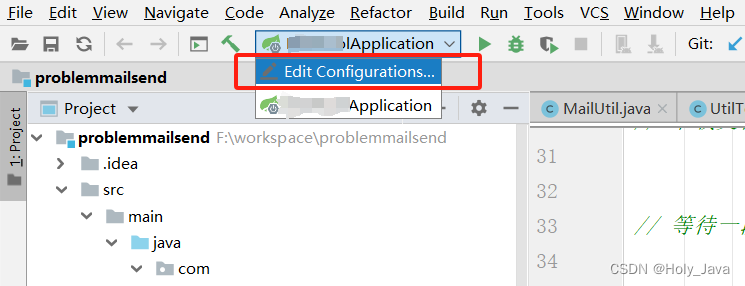
找到Tomcat server 加上如下配置:
-Dfile.encoding=utf-8
如图:
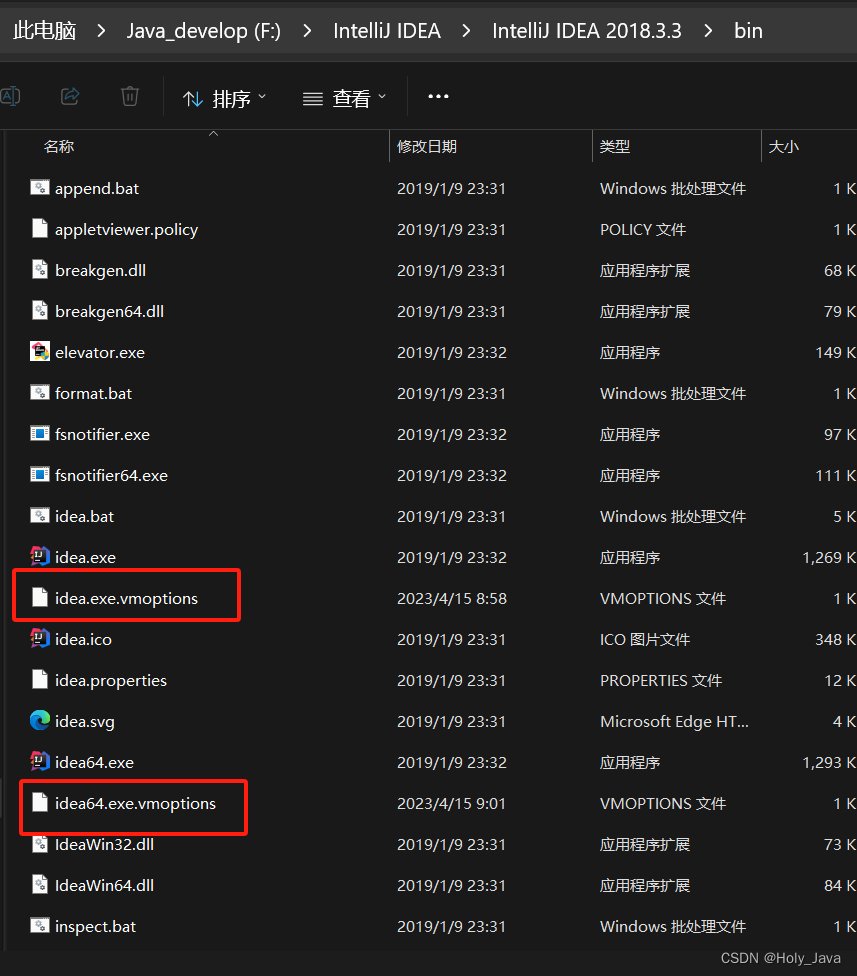
2.2.2)IDEA控制台乱码
找到IDEA的安装路径,例如我的安装路径:F:\IntelliJ IDEA\IntelliJ IDEA 2018.3.3\bin路径下面有两个文件:
idea64.exe.vmoptions
idea.exe.vmoptions
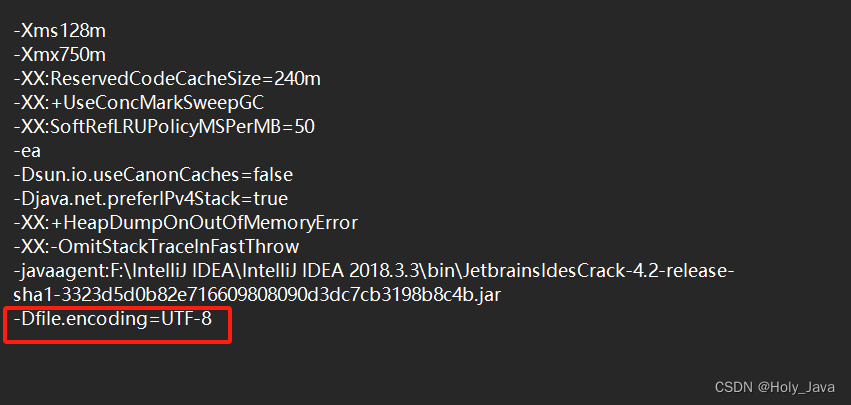
在这两个文件后面加上:
-Dfile.encoding=UTF-8
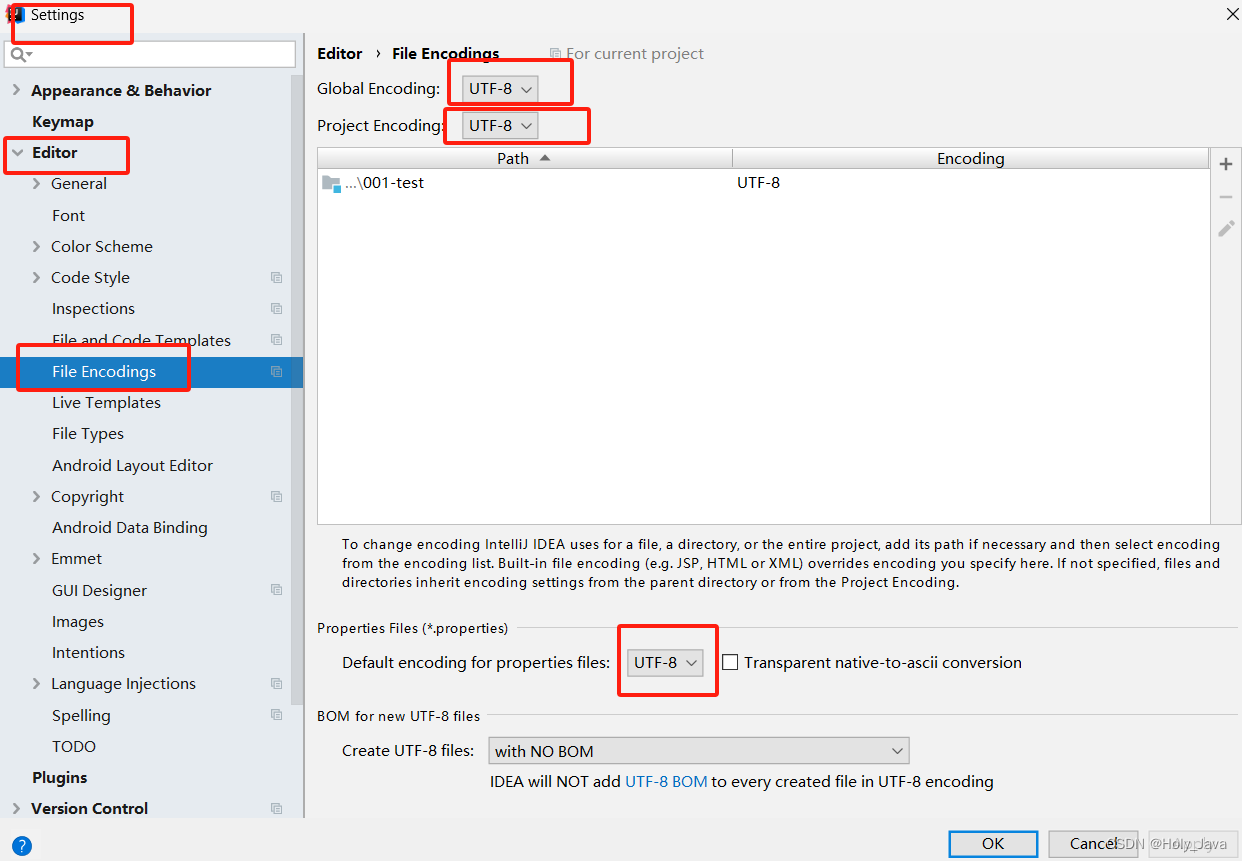
2.2.3)IDEA软件默认编码格式设置
2.3)各类文件乱码
2.3.1)jsp文件乱码
在头部设置编码格式为UTF-8
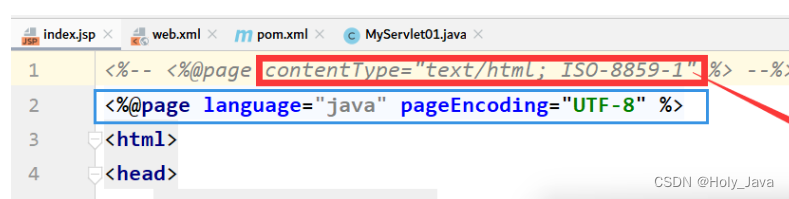
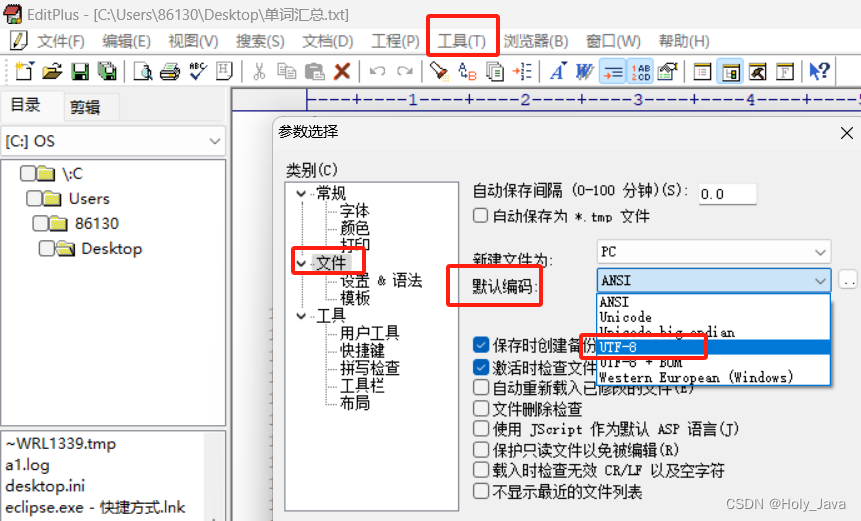
2.3.2)editplus打开文件乱码
EditPlus软件—》菜单中的“工具” > 首选项—》文件”选项卡—》默认编码—》选择UTF-8—》保存


















 4077
4077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









