






简单的说,二分搜索树是一种某个节点的左孩子小于这个节点的值,右孩子大于这个节点的值的特殊二叉树。(什么是二叉树就不说了),特点是:二分搜索树的中序遍历得到的结果是有序的;这篇博客的大致目录:
1.二分搜索树添加节点
2.判断是否存在某个数据
2.递归的先序、中序和后序遍历
3.借助栈的先序非递归遍历
4.层序遍历(广度优先遍历)
5.查找最大值和最小值
6.删除最大值和最小值
7.删除任意元素
8.时间复杂度分析
- 首先是二分搜索树的创建,向二分搜索树中添加节点的实现:
思路:如果树为空的话,创建一个Node存储要添加的数据并将这个节点作为树的根;
如果树不为空,如果添加的值大于当前节点的值,则往当前节点的右子树添加;
如果添加的值小于当前节点的值,则往当前节点的左子树添加;
如果添加的值等于当前节点的值,忽略即可,不再添加到树中;
首先准备一个节点Node:使用泛型表示节点中可以存放任意类型的数据,并且要求E继承Comparable,是可比较大小的;每个节点应保存其左孩子和右孩子的信息。
public class Node<E extends Comparable<E>>{
private E e;
private Node left;
private Node right;
public Node(E e) {
this.e = e;
this.left = null;
this.right = null;
}
}一个二分搜索树应当具备的属性:根节点root和树的大小size:
package com.gby.tree;
import java.util.Stack;
public class BST<E extends Comparable<E>> {
public class Node<E extends Comparable<E>>{
private E e;
private Node left;
private Node right;
public Node(E e) {
this.e = e;
this.left = null;
this.right = null;
}
}
//一个树应当具备根节点和size两个属性
private Node root;
private int size;
public BST(Node root) {
this.root = root;
this.size = 0;
}
//初始化时root为Null, size为0
public BST() {
this.root = null;
this.size = 0;
}
public int getSize(){
return size;
}
}添加节点:
public void add(E e){
root = add(root,e);
}
//参数node为要添加元素e的树的根,返回添加节点的后,树新的的根
private Node add(Node node, E e) {
//如果添加元素的树的根为null,即树为空,直接创建一个新的节点作为根
if(node == null){
size ++;
return new Node(e);
}
//树不为空
if(e.compareTo((E) node.e) < 0){ //添加的元素小于根节点的元素值,则加入左子树;左孩子为空则创建
node.left = add(node.left,e);
}else if(e.compareTo((E) node.e) > 0){ //添加的元素大于根节点的元素值,则加入右子树;右孩子为空则创建
node.right = add(node.right,e);
}
size++;
return node;
}- 判断是否存在某个节点:
//查询元素,返回节点所在树的根
public boolean contains(E e){
return contains(root, e);
}
public boolean contains(Node node,E e){
if(node == null){
return false;
}
if(e.compareTo((E) node.e) < 0){
return contains(node.left,e);
}else if(e.compareTo((E) node.e) == 0){
return true;
}else
return contains(node.right,e);
}- 先序遍历: 先访问根节点,再先序遍历左子树,再先序遍历右子树
//先序遍历二分搜索树
public void preOrder(){
preOrder(root);
}
//先序遍历以node为根的二分搜索树
private void preOrder(Node node) {
if(node == null)
return;
System.out.println(node.e); //以输出表示访问
preOrder(node.left);
preOrder(node.right);
}
中序遍历和后序遍历:
//中序遍历
public void inOrder(){
inOrder(root);
}
private void inOrder(Node node) {
if(node == null){
return;
}
inOrder(node.left);
System.out.println(node.e);
inOrder(node.right);
}
//后序遍历
public void postOrder(){
postOrder(root);
}
private void postOrder(Node node){
if(node == null){
return;
}
postOrder(node.left);
postOrder(node.right);
System.out.println(node.e);
}借助于栈的非递归先序遍历:
/**
* 二分搜索树的非递归遍历
*/
public void preOrderNR(){
Stack<Node> stack = new Stack<Node>();
stack.push(root);
while(!stack.isEmpty()){
Node cur = stack.pop();
System.out.println(cur.e); //访问根节点
//依次将cur的右孩子和左孩子入栈,因为栈具有后入先出的特点,先序遍历需要先遍历左子树,所以左孩子先出栈,则后入栈
if(cur.right!=null)
stack.push(cur.right);
if(cur.left!=null)
stack.push(cur.left);
}
}- 层序遍历:先序、中序和后序遍历本质上都是深度优先遍历,层序遍历是一种广度优先的遍历,遍历的方式为:
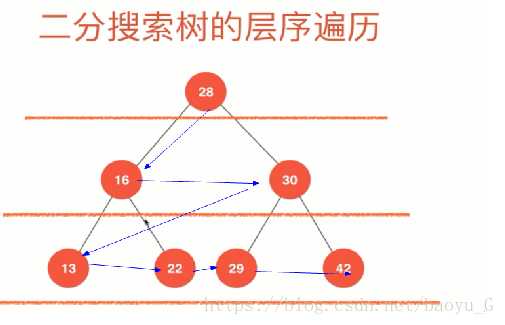
28-16-30-13-22-19-42
借助于队列实现层序遍历:
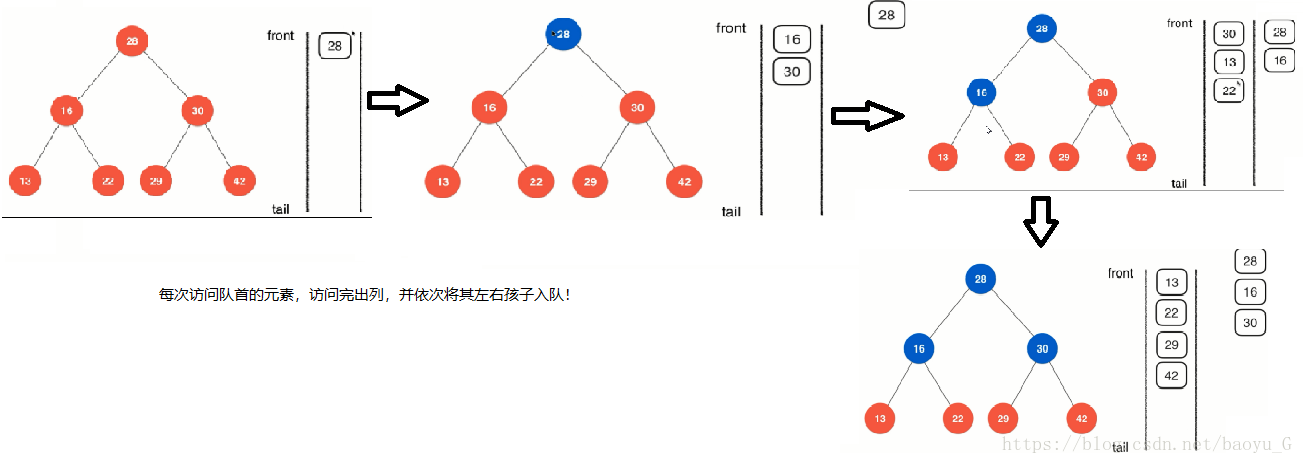
public void levelOrder(){
Queue<Node> queue = new LinkedList<Node>();
queue.add(root);
while(!queue.isEmpty()){
Node node = queue.remove();
System.out.println(node.e);
if(node.left!=null)
queue.add(node.left);
if(node.right!=null)
queue.add(node.right);
}
} - 查找最大值和最小值
前面说,平衡二叉树具有某个节点的左孩子小于这个节点,右孩子大于这个节点的特点;所以,某个节点的左孩子一定小于这个节点,右孩子一定大于这个节点。那么,对于一个平衡二叉树,最小的节点就是从根节点开始,不断向左子树遍历,直到找到一个没有左孩子的节点,最大的节点就是不断向右子树遍历,直到找到一个没有右孩子的节点;这就是查找最大值和最小值的思路。
下面是代码实现:
//二分搜索树中最大的元素
public E maxNum(){
if(size == 0)
throw new IllegalArgumentException("no node in bst.");
return (E) maxNum(root).e;
}
//在参数node为根的树中查找最大值,并返回最大值所在的节点
private Node maxNum(Node node){
if(node.right == null)
return node;
return maxNum(node.right);
}相似的,下面是最小值的查找:
//寻找二分搜索树中最小的元素
public E miniNum(){
if(size == 0)
throw new IllegalArgumentException("no node in bst.");
return (E) miniNum(root).e;
}
public Node miniNum(Node node){
if(node.left == null){
return node;
}
return miniNum(node.left);
}- 删除最大值和最小值
据上,最大节点是没有右孩子的,最小节点是没有左孩子的;但是,最大节点可以有左孩子,最小的节点可以有右孩子;所以需要保留最大节点的左子树和最小节点的右子树,将最大节点的左子树的根替代最大节点的位置,最小节点的右子树的根替代最小节点的位置;
//删除最大的元素
public E removeMax(){
E max = maxNum();
removeMax(root);
return max;
}
//删除以node为根的树的最大节点(node.right=null),并返回新的根
private Node removeMax(Node node) {
if(node.right==null){ //根节点的右孩子为空,则根为这个树的最大节点
Node leftChild = node.left;
node.left = null;
size--; //维护size的大小
return leftChild;
}
node.right = removeMax(node.right); //根有右孩子,不是最大节点
return node;
}删除最大节点时,如果根就是最大节点,则新的根就是左孩子;如果根不是最大节点,即根有右孩子,则在右子树中找最大值并删除;如果根的右孩子就是最大值,而右孩子又有左孩子,删除右孩子需要让根的右孩子变为根的右孩子的左孩子,所以需要将左孩子(要删除的节点的子树的根)返回,赋值给node.right,把这棵树连起来;所以有了上面的代码。
类似的,下面时删除最小的节点:
//删除二分搜索树中最小的元素
public E removeMiniNum(){
E e = miniNum();
removeMiniNum(root);
return e;
}
private Node removeMiniNum(Node node) {
if(node.left==null){
Node rightNode = node.right;
node.right=null;
size--;
return rightNode;
}
node.left = removeMiniNum(node.left);
return node;
}- 删除二分搜索树中的任意一个节点
//删除以node为根的树中的e,并返回新的树的根节点
private Node remove(Node node,E e){
if(node==null) //根为Null,直接返回
return node;
if(e.compareTo((E) node.e)<0){ //如果e小于当前节点,则进入左子树寻找
node.left = remove(node.left,e);
}else if(e.compareTo((E) node.e)>0){ //e大于当前节点,进入右子树寻找,并返回右子树删除后的根节点和前面的节点保持连接
node.right=remove(node.right,e);
}else{ //node.e = e
if(node.left==null){ //要删除的节点没有左子树,则把右子树的根节点返回给上一层循环的node.X连接起来
Node rightNode = node.right;
node.right = null;
size--;
return rightNode;
}else if(node.right==null){
Node leftNode = node.left;
node.left = null;
size--;
return leftNode;
}
//待删除的节点的左右子树均不为空,则找到右子树的最小值或者左子树的最大值替代这个节点
Node successor = miniNum(node.right);
successor.right = removeMiniNum(node.right);
successor.left = node.left;
node.left = node.right = null;
return successor;
}
return null;
}完整代码:
package com.gby.tree;
import java.util.LinkedList;
import java.util.Queue;
import java.util.Stack;
import com.gby.tree.BST.Node;
public class BST<E extends Comparable<E>> {
public class Node<E extends Comparable<E>>{
private E e;
private Node left;
private Node right;
public Node(E e) {
this.e = e;
this.left = null;
this.right = null;
}
}
//一个树应当具备根节点和size两个属性
private Node root;
private int size;
public BST(Node root) {
this.root = root;
this.size = 0;
}
public BST() {
this.root = null;
this.size = 0;
}
public int getSize(){
return size;
}
public void add(E e){
root = add(root,e);
}
//返回添加节点的树的根
private Node add(Node node, E e) {
//如果添加元素的树的根为null,即树为空,直接创建一个新的节点作为根
if(node == null){
size ++;
return new Node(e);
}
//树不为空
if(e.compareTo((E) node.e) < 0){ //添加的元素小于根节点的元素值,则加入左子树
node.left = add(node.left,e);
}else if(e.compareTo((E) node.e) > 0){ //添加的元素大于根节点的元素值,则加入右子树
node.right = add(node.right,e);
}
size++;
return node;
}
//查询元素
public boolean contains(E e){
return contains(root, e);
}
public boolean contains(Node node,E e){
if(node == null){
return false;
}
if(e.compareTo((E) node.e) < 0){
return contains(node.left,e);
}else if(e.compareTo((E) node.e) == 0){
return true;
}else
return contains(node.right,e);
}
//先序遍历二分搜索树
public void preOrder(){
preOrder(root);
}
//先序遍历以node为根的二分搜索树
private void preOrder(Node node) {
if(node == null)
return;
System.out.println(node.e);
preOrder(node.left);
preOrder(node.right);
}
/**
* 二分搜索树的非递归遍历
*/
public void preOrderNR(){
Stack<Node> stack = new Stack<Node>();
stack.push(root);
while(!stack.isEmpty()){
Node cur = stack.pop();
System.out.println(cur.e); //访问根节点
//依次将cur的右孩子和左孩子入栈,因为栈具有后入先出的特点,先序遍历需要先遍历左子树,所以左孩子先出栈,则后入栈
if(cur.right!=null)
stack.push(cur.right);
if(cur.left!=null)
stack.push(cur.left);
}
}
//中序遍历
public void inOrder(){
inOrder(root);
}
private void inOrder(Node node) {
if(node == null){
return;
}
inOrder(node.left);
System.out.println(node.e);
inOrder(node.right);
}
//后续遍历
public void postOrder(){
postOrder(root);
}
private void postOrder(Node node){
if(node == null){
return;
}
postOrder(node.left);
postOrder(node.right);
System.out.println(node.e);
}
//基于队列的层序遍历
public void levelOrder(){
Queue<Node> queue = new LinkedList<Node>();
queue.add(root);
while(!queue.isEmpty()){
Node node = queue.remove();
System.out.println(node.e);
if(node.left!=null)
queue.add(node.left);
if(node.right!=null)
queue.add(node.right);
}
}
//寻找二分搜索树中最小的元素
public E miniNum(){
if(size == 0)
throw new IllegalArgumentException("no node in bst.");
return (E) miniNum(root).e;
}
//二分搜索树中最小的元素;
public Node miniNum(Node node){
if(node.left == null){
return node;
}
return miniNum(node.left);
}
//二分搜索树中最大的元素
public E maxNum(){
if(size == 0)
throw new IllegalArgumentException("no node in bst.");
return (E) maxNum(root).e;
}
private Node maxNum(Node node){
if(node.right == null)
return node;
return maxNum(node.right);
}
//删除二分搜索树中最小的元素
public E removeMiniNum(){
E e = miniNum();
removeMiniNum(root);
return e;
}
private Node removeMiniNum(Node node) {
if(node.left==null){
Node rightNode = node.right;
node.right=null;
size--;
return rightNode;
}
node.left = removeMiniNum(node.left);
return node;
}
//删除最大的元素
public E removeMax(){
E max = maxNum();
removeMax(root);
return max;
}
//删除以node为根的树的最大节点(node.right=null),并返回新的根
private Node removeMax(Node node) {
if(node.right==null){ //该节点为要删除的节点
Node leftChild = node.left;
node.left = null;
size--;
return leftChild;
}
node.right = removeMax(node.right);
return node;
}
//删除某个元素
public void remove(E e){
remove(root,e);
}
//删除以node为根的树中的e
private Node remove(Node node,E e){
if(node==null)
return node;
if(e.compareTo((E) node.e)<0){
node.left = remove(node.left,e);
}else if(e.compareTo((E) node.e)>0){
node.right=remove(node.right,e);
}else{ //node.e = e
if(node.left==null){
Node rightNode = node.right;
node.right = null;
size--;
return rightNode;
}else if(node.right==null){
Node leftNode = node.left;
node.left = null;
size--;
return leftNode;
}
//待删除的节点的左右子树均不为空
Node successor = miniNum(node.right);
successor.right = removeMiniNum(node.right);
successor.left = node.left;
node.left = node.right = null;
return successor;
}
return null;
}
}- 时间复杂度分析
增加一个元素时,需要逐一比较和节点的大小,每次进入左子树或者右子树,最复杂的情况是插入到树的最底层,时间复杂度和树的高度h是O(h)的关系,而对于一个满二叉树,BST中h和节点个数n的关系是n=2^h-1,则h=log2(n+1),所以时间复杂度为O(logn);同理,查询和删除也是这样的时间复杂度。














 2374
2374











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









