







一、简介
1.1 什么是Hive
Hive是基于Hadoop的一个数据仓库工具。可以将结构化的数据文件映射为一张表,并提供完整的sql查询功能,底层是将sql语句转换为MapReduce任务进行运行。
Hive提供了一系列的工具,可以用来进行数据提取、转化、加载(ETL Extract-Transform-Load ),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制,本质上是一种大数据离线分析工具。
Hive通过类SQL的语法,来进行分布式的计算,HQL用起来和SQL非常的类似,Hive在执行的过程中会将HQL转换为MapReduce去执行,所以Hive其实是基于Hadoop的一种分布式计算框架,底层仍然是MapReduce,逻辑架构图如下:
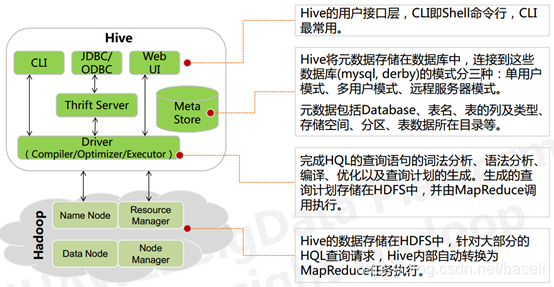
从上图看出hive的内部架构由四部分组成:
1、用户接口: shell/CLI, jdbc/odbc, webui Command Line Interface
CLI,Shell 终端命令行(Command Line Interface),采用交互形式使用 Hive 命令行与 Hive 进行交互,最常用(学习,调试,生产)
JDBC/ODBC,是 Hive 的基于 JDBC 操作提供的客户端,用户(开发员,运维人员)通过 这连接至 Hive server 服务
Web UI,通过浏览器访问 Hive
2、跨语言服务 : thrift server 提供了一种能力,让用户可以使用多种不同的语言来操纵hive
Thrift 是 Facebook 开发的一个软件框架,可以用来进行可扩展且跨语言的服务的开发, Thrift 允许客户端使用包括Java、C++、Ruby和其他很多种语言,通过编程的方式远程访问Hive,Hive 集成了该服务,能让不同的编程语言调用 Hive 的接口
3、底层的Driver: 驱动器Driver,编译器Compiler,优化器Optimizer,执行器Executor
Driver 组件完成 HQL 查询语句从词法分析,语法分析,编译,优化,以及生成逻辑执行 计划的生成。生成的逻辑执行计划存储在 HDFS 中,并随后由 MapReduce 调用执行
Hive 的核心是驱动引擎, 驱动引擎由四部分组成:
(1) 解释器:解释器的作用是将 HiveSQL 语句转换为抽象语法树(AST)
(2) 编译器:编译器是将语法树编译为逻辑执行计划
(3) 优化器:优化器是对逻辑执行计划进行优化
(4) 执行器:执行器是调用底层的运行框架执行逻辑执行计划
元数据,通俗的讲,就是存储在 Hive 中的数据的描述信息。
Hive 中的元数据通常包括:表的名字,表的列和分区及其属性,表的属性(内部表和 外部表),表的数据所在目录
Metastore 默认存在自带的 Derby 数据库中。缺点就是不适合多用户操作,并且数据存 储目录不固定。数据库跟着 Hive 走,极度不方便管理
解决方案:通常存我们自己创建的 MySQL 库(本地 或 远程)
Hive 和 MySQL 之间通过 MetaStore 服务交互
HiveQL 通过命令行或者客户端提交,经过 Compiler 编译器,运用 MetaStore 中的元数 据进行类型检测和语法分析,生成一个逻辑方案(Logical Plan),然后通过的优化处理,产生 一个 MapReduce 任务。
Hive的数据组织
1、Hive 的存储结构包括数据库、表、视图、分区和表数据等。数据库,表,分区等等都对 应 HDFS(HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用)上的一个目录。表数据对应 HDFS 对应目录下的文件。
2、Hive 中所有的数据都存储在 HDFS 中,没有专门的数据存储格式,因为 Hive 是读模式 (Schema On Read),可支持 TextFile,SequenceFile,RCFile 或者自定义格式等
3、 只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据
Hive 的默认列分隔符:控制符 Ctrl + A,\x01 Hive 的
Hive 的默认行分隔符:换行符 \n
4、Hive 中包含以下数据模型:
database:在 HDFS 中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
table:在 HDFS 中表现所属 database 目录下一个文件夹
external table:与 table 类似,不过其数据存放位置可以指定任意 HDFS 目录路径
partition:在 HDFS 中表现为 table 目录下的子目录
bucket:在 HDFS 中表现为同一个表目录或者分区目录下根据某个字段的值进行 hash 散列之后的多个文件
view:与传统数据库类似,只读,基于基本表创建
5、Hive 的元数据存储在 RDBMS 中,除元数据外的其它所有数据都基于 HDFS 存储。默认情 况下,Hive 元数据保存在内嵌的 Derby 数据库中,只能允许一个会话连接,只适合简单的 测试。实际生产环境中不适用,为了支持多用户会话,则需要一个独立的元数据库,使用 MySQL 作为元数据库,Hive 内部对 MySQL 提供了很好的支持。
6、Hive 中的表分为内部表、外部表、分区表和 Bucket 表
内部表和外部表的区别:
删除内部表,删除表元数据和数据
删除外部表,删除元数据,不删除数据
内部表和外部表的使用选择:
大多数情况,他们的区别不明显,如果数据的所有处理都在 Hive 中进行,那么倾向于 选择内部表,但是如果 Hive 和其他工具要针对相同的数据集进行处理,外部表更合适。
使用外部表访问存储在 HDFS 上的初始数据,然后通过 Hive 转换数据并存到内部表中
使用外部表的场景是针对一个数据集有多个不同的 Schema
通过外部表和内部表的区别和使用选择的对比可以看出来,hive 其实仅仅只是对存储在 HDFS 上的数据提供了一种新的抽象。而不是管理存储在 HDFS 上的数据。所以不管创建内部 表还是外部表,都可以对 hive 表的数据存储目录中的数据进行增删操作。
分区表和分桶表的区别:
Hive 数据表可以根据某些字段进行分区操作,细化数据管理,可以让部分查询更快。同 时表和分区也可以进一步被划分为 Buckets,分桶表的原理和 MapReduce 编程中的 HashPartitioner 的原理类似。
分区和分桶都是细化数据管理,但是分区表是手动添加区分,由于 Hive 是读模式,所 以对添加进分区的数据不做模式校验,分桶表中的数据是按照某些分桶字段进行 hash 散列 形成的多个文件,所以数据的准确性也高很多
1.2 为什么使用Hive
直接使用 MapReduce 所面临的问题:
1、人员学习成本太高
2、项目周期要求太短
3、MapReduce实现复杂查询逻辑开发难度太大
使用 Hive优势:
1、更友好的接口:操作接口采用类 SQL 的语法,提供快速开发的能力
2、更低的学习成本:避免了写 MapReduce,减少开发人员的学习成本
3、更好的扩展性:可自由扩展集群规模而无需重启服务,还支持用户自定义函数
1.3 Hive特点
优点:
1、可扩展性,横向扩展,Hive 可以自由的扩展集群的规模,一般情况下不需要重启服务 横向扩展:通过分担压力的方式扩展集群的规模 纵向扩展:一台服务器cpu i7-6700k 4核心8线程,8核心16线程,内存64G => 128G
2、延展性,Hive 支持自定义函数,用户可以根据自己的需求来实现自己的函数
3、良好的容错性,可以保障即使有节点出现问题,SQL 语句仍可完成执行
缺点:
1、Hive 不支持记录级别的增删改操作,但是用户可以通过查询生成新表或者将查询结 果导入到文件中(当前选择的 hive-2.3.2 的版本支持记录级别的插入操作)
2、Hive 的查询延时很严重,因为 MapReduce Job 的启动过程消耗很长时间,所以不能 用在交互查询系统中。
3、Hive 不支持事务(因为没有增删改,所以主要用来做 OLAP(联机分析处理),而 不是 OLTP(联机事务处理),这就是数据处理的两大级别)。
Hive 和 RDBMS 的对比:
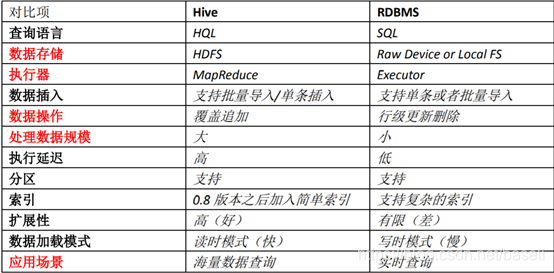
总结:
Hive 具有 SQL 数据库的外表,但应用场景完全不同,Hive 只适合用来做海量离线数 据统计分析,也就是数据仓库。
1.4 数据类型
1.4.1 基本数据类型
Hive 支持关系型数据中大多数基本数据类型
| 类型 | 描述 | 示例 |
| boolean | true/false | TRUE |
| tinyint | 1字节的有符号整数 | -128~127 1Y |
| smallint | 2个字节的有符号整数,-32768~32767 | 1S |
| int | 4个字节的带符号整数 | 1 |
| bigint | 8字节带符号整数 | 1L |
| float | 4字节单精度浮点数 | 1.0 |
| double | 8字节双精度浮点数 | 1.0 |
| deicimal | 任意精度的带符号小数 | 1.0 |
| String | 字符串,变长 | “a”,’b’ |
| varchar | 变长字符串 | “a”,’b’ |
| char | 固定长度字符串 | “a”,’b’ |
| binary | 字节数组 | 无法表示 |
| timestamp | 时间戳,纳秒精度 | 122327493795 |
| date | 日期 | ‘2018-04-07’ |
和其他的SQL语言一样,这些都是保留字。需要注意的是所有的这些数据类型都是对Java中接口的实现,因此这些类型的具体行为细节和Java中对应的类型是完全一致的。例如,string类型实现的是Java中的String,float实现的是Java中的float,等等。
1.4.2 复杂数据类型
| 类型 | 描述 | 示例 |
| array | 有序的的同类型的集合 | array(1,2) |
| map | key-value,key必须为原始类型,value可以任意类型 | map(‘a’,1,’b’,2) |
| struct | 字段集合,类型可以不同 | struct(‘1’,1,1.0), named_stract(‘col1’,’1’,’col2’,1,’clo3’,1.0) |
1.4.3 存储格式
Hive会为每个创建的数据库在HDFS上创建一个目录,该数据库的表会以子目录形式存储,表中的数据会以表目录下的文件形式存储。对于default数据库,默认的缺省数据库没有自己的目录,default数据库下的表默认存放在/user/hive/warehouse目录下。
(1)textfile
textfile为默认格式,存储方式为行存储。数据不做压缩,磁盘开销大,数据解析开销大。
(2)SequenceFile
SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。
SequenceFile支持三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。
(3)RCFile
一种行列存储相结合的存储方式。
(4)ORCFile
数据按照行分块,每个块按照列存储,其中每个块都存储有一个索引。hive给出的新格式,属于RCFILE的升级版,性能有大幅度提升,而且数据可以压缩存储,压缩快 快速列存取。
(5)Parquet
Parquet也是一种行式存储,同时具有很好的压缩性能;同时可以减少大量的表扫描和反序列化的时间。
1.4.5 数据格式
当数据存储在文本文件中,必须按照一定格式区别行和列,并且在Hive中指明这些区分符。Hive默认使用了几个平时很少出现的字符,这些字符一般不会作为内容出现在记录中。
Hive默认的行和列分隔符如下表所示。
| 分隔符 | 描述 |
| \n | 对于文本文件来说,每行是一条记录,所以\n 来分割记录 |
| ^A (Ctrl+A) | 分割字段,也可以用\001 来表示 |
| ^B (Ctrl+B) | 用于分割 Arrary 或者 Struct 中的元素,或者用于 map 中键值之间的分割,也可以用\002 分割。 |
| ^C | 用于 map 中键和值自己分割,也可以用\003 表示。 |
二、安装
2.1 Hive下载
下载地址http://mirrors.hust.edu.cn/apache/
选择合适的Hive版本进行下载,进到stable-2文件夹可以看到稳定的2.x的版本是2.3.x
2.2 Hive安装
上传Hive包
解压安装包
[hadoop@hadoop3 ~]$ tar -zxvf apache-hive-2.3.3-bin.tar.gz -C apps/
修改配置文件
配置文件所在目录apache-hive-2.3.3-bin/conf
[hadoop@hadoop3 apps]$ cd apache-hive-2.3.3-bin/
[hadoop@hadoop3 apache-hive-2.3.3-bin]$ ls
bin binary-package-licenses conf examples hcatalog jdbc lib LICENSE NOTICE RELEASE_NOTES.txt scripts
[hadoop@hadoop3 apache-hive-2.3.3-bin]$ cd conf/
[hadoop@hadoop3 conf]$ ls
beeline-log4j2.properties.template ivysettings.xml
hive-default.xml.template llap-cli-log4j2.properties.template
hive-env.sh.template llap-daemon-log4j2.properties.template
hive-exec-log4j2.properties.template parquet-logging.properties
hive-log4j2.properties.template
[hadoop@hadoop3 conf]$ pwd
/home/hadoop/apps/apache-hive-2.3.3-bin/conf
[hadoop@hadoop3 conf]$
新建hive-site.xml并添加以下内容
[hadoop@hadoop3 conf]$ touch hive-site.xml[hadoop@hadoop3 conf]$ vi hive-site.xml
javax.jdo.option.ConnectionURL
jdbc:mysql://hadoop1:3306/hivedb?createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionUserName
root
username to use against metastore database
javax.jdo.option.ConnectionPassword
root
password to use against metastore database
以下可选配置,该配置信息用来指定 Hive 数据仓库的数据存储在 HDFS 上的目录
hive.metastore.warehouse.dir
/hive/warehouse
hive default warehouse, if nessecory, change it
如果连接使用mysql等其他数据库作为元数据库,一定要记得加入驱动包,将mysql驱动包(mysql-connector-java-5.1.40-bin.jar)该 jar 包放置在 hive
安装完成,配置环境变量
[hadoop@hadoop3 lib]$ vi ~/.bashrc
#Hive
export HIVE_HOME=/home/hadoop/apps/apache-hive-2.3.3-bin
export PATH=$PATH:$HIVE_HOME/bin
使修改的配置文件立即生效
- [hadoop@hadoop3 lib]$ source ~/.bashrc
验证安装
[hadoop@hadoop3 ~]$ hive --help
Usage ./hive --service serviceName
Service List: beeline cleardanglingscratchdir cli hbaseimport hbaseschematool help hiveburninclient hiveserver2 hplsql jar lineage llapdump llap llapstatus metastore metatool orcfiledump rcfilecat schemaTool version
Parameters parsed:
--auxpath : Auxiliary jars
--config : Hive configuration directory
--service : Starts specific service/component. cli is default
Parameters used:
HADOOP_HOME or HADOOP_PREFIX : Hadoop install directory
HIVE_OPT : Hive options
For help on a particular service:
./hive --service serviceName --help
Debug help: ./hive --debug --help
[hadoop@hadoop3 ~]$
初始化元数据库
注意:当使用的 hive 是 2.x 之前的版本,不做初始化也是 OK 的,当 hive 第一次启动的 时候会自动进行初始化,只不过会不会生成足够多的元数据库中的表。在使用过程中会 慢慢生成。但最后进行初始化。如果使用的 2.x 版本的 Hive,那么就必须手动初始化元 数据库。使用命令:
[hadoop@hadoop3 ~]$ schematool -dbType mysql -initSchema
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/apps/apache-hive-2.3.3-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:mysql://hadoop1:3306/hivedb?createDatabaseIfNotExist=true
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: root
Starting metastore schema initialization to 2.3.0
Initialization script hive-schema-2.3.0.mysql.sql
Initialization script completed
schemaTool completed
[hadoop@hadoop3 ~]$
启动 Hive 客户端
hive --service cli和hive效果一样
[hadoop@hadoop3 ~]$ hive --service cli
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/apps/apache-hive-2.3.3-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/home/hadoop/apps/apache-hive-2.3.3-bin/lib/hive-common-2.3.3.jar!/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive>
三、常用命令
3.1 创建数据库
hive> create database myhive;
OK
Time taken: 7.847 seconds
hive>
3.2 使用指定数据库
hive> use myhive;
OK
Time taken: 0.047 seconds
hive>
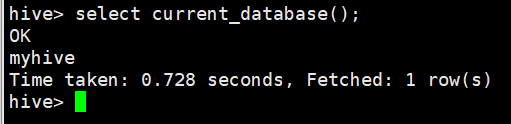
3.3 查看当前数据库
hive> select current_database();
OK
myhive
Time taken: 0.728 seconds, Fetched: 1 row(s)
hive>
3.4 创建表
创建的表分为内部表和外部表,外部表在建表的时候必须同时指定一个指向实际数据的路径(LOCATION),Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
每天采集的ng日志和埋点日志、每天收集到的网站数据,需要做大量的统计数据分析,在存储的时候建议使用外部表,因为日志数据是采集程序实时采集进来的,一旦被误删,恢复起来非常麻烦。而且外部表方便数据的共享。
抽取过来的业务数据,其实用外部表或者内部表问题都不大,就算被误删,恢复起来也是很快的,如果需要对数据内容和元数据进行紧凑的管理, 建议使用内部表。
在做统计分析时候用到的中间表,结果表可以使用内部表,因为这些数据不需要共享,使用内部表更为合适。并且很多时候结果分区表我们只需要保留最近3天的数据,用外部表的时候删除分区时无法删除数据。
例:在数据库myhive创建一张student表
hive> create table student(id int, name string, sex string, age int, department string) row format delimited fields terminated by ",";
OK
Time taken: 0.718 seconds
hive>
3.4.1 语法说明
hql不区分大小写,[]里的属性是可选属性。
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY(col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY(col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
3.4.2 参数说明
1. CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。
2. EXTERNAL 关键字可以让用户创建一个外部表,默认是内部表。外部表在建表的时候必须同时指定一个指向实际数据的路径(LOCATION),Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
3.COMMENT 是给表字段或者表内容添加注释说明的。
4.PARTITIONED BY 给表做分区,决定了表是否是分区表。
在Hive Select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作。有时候只需要扫描表中关心的一部分数据,因此建表时引入了partition概念。分区表指的是在创建表时指定的partition的分区空间。
Hive可以对数据按照某列或者某些列进行分区管理,所谓分区我们可以拿下面的例子进行解释。
当前互联网应用每天都要存储大量的日志文件,几G、几十G甚至更大都是有可能。存储日志,其中必然有个属性是日志产生的日期。在产生分区时,就可以按照日志产生的日期列进行划分。把每一天的日志当作一个分区。
将数据组织成分区,主要可以提高数据的查询速度。至于用户存储的每一条记录到底放到哪个分区,由用户决定。即用户在加载数据的时候必须显示的指定该部分数据放到哪个分区。
实现细节:
1)、一个表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下。
2)、表和列名不区分大小写。
3)、分区是以字段的形式在表结构中存在,通过describetable命令可以查看到字段存在, 但是该字段不存放实际的数据内容,仅仅是分区的表示(伪列) 。
5.CLUSTERED BY 对于每一个表(table)或者分区, Hive 可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分,Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
把表(或者分区)组织成桶(Bucket)有两个理由:
(1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
(2)使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
如果通过数据文件LOAD 到分桶表中,会存在额外的MR负担。所以实际生产中分桶策略使用频率较低,更常见的还是使用数据分区。
6.ROW FORMAT DELIMITED FIELDS TERMINATED BY ',', 这里指定表存储中列的分隔符,默认是 \001,这里指定的是逗号分隔符,还可以指定其他列的分隔符。
7.STORED AS SEQUENCEFILE|TEXTFILE|RCFILE,如果文件数据是纯文本,可以使用 STORED AS TEXTFILE,如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
8.LOCATION 定义 hive 表的数据在 hdfs 上的存储路径,一般管理表(内部表不要自定义),但是如果定义的是外部表,则需要直接指定一个路径
3.4.3 创建表的三种方式
1. 使用 create 命令
CREATE TABLE `employee`(
`dept_no` int,
`addr` string,
`tel` string)
partitioned by(statis_date string )
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
详细参考上述建表说明。
可以使用describe formatted employee查看建表相关的各种配置属性以及默认属性。
2. create table ...as select..(CTAS)
create table employee1
as
select * from employee where statis_date='20180229';
1)使用查询创建并填充表,select 中选取的列名会作为新表的列名(所以通常是要取别名);
2)会改变表的属性、结构,比如只能是内部表、分区分桶也没了:
- 目标表不允许使用分区分桶的,FAILED: SemanticException [Error 10068]: CREATE-TABLE-AS-SELECT does not support partitioning in the target table,对于旧表中的分区字段,如果通过 select * 的方式,新表会把它看作一个新的字段,这里要注意 ;
- 目标表不允许使用外部表,如 create external table … as select… 报错 FAILED: SemanticException [Error 10070]: CREATE-TABLE-AS-SELECT cannot create external table;
- 创建的表存储格式会变成默认的格式 TEXTFILE 。
3)可以指定表的存储格式,行和列的分隔符等。
3. 使用 like 创建相同结构的表
CREATE TABLE LIKE
- 用来复制表的结构
- 需要外部表的话,通过 create external table like … 指定
- 不填充数据
3.4.4 创建分区表的常用操作
1. 创建一个分区表,以 ds 为分区列:
create table invites(id int, name string) partitioned by (ds string) row format delimited fieldsterminated by '\t' stored as textfile;
2. 将数据添加到时间为 2013-08-16 这个分区中:
load data local inpath'/home/hadoop/Desktop/data.txt' overwrite into table invites partition(ds='2013-08-16');
3. 将数据添加到时间为 2013-08-20 这个分区中:
load data local inpath'/home/hadoop/Desktop/data.txt' overwrite into table invites partition(ds='2013-08-20');
4. 从一个分区中查询数据:
select * from inviteswhere ds ='2013-08-12';
5. 往一个分区表的某一个分区中添加数据:
insert overwrite tableinvites partition (ds='2013-08-12') select id,max(name) from test group by id;
可以查看分区的具体情况,使用命令:
hadoop fs -ls /home/hadoop.hive/warehouse/invites
或者:
show partitionstablename;
3.4.5 创建分区表的常用操作
1. 创建带桶的 table :
create tablebucketed_user(id int,name string)clustered by (id) sorted by(name) into 4buckets row format delimited fields terminated by '\t' stored as textfile;
首先,我们使用CLUSTERED BY 子句来指定划分桶所用的列和要划分的桶的个数:
CREATE TABLE bucketed_user(id INT) name STRING)
CLUSTERED BY (id) INTO 4BUCKETS;
在这里,我们使用用户ID来确定如何划分桶(Hive使用对值进行哈希并将结果除 以桶的个数取余数。这样,任何一桶里都会有一个随机的用户集合(PS:其实也能说是随机,不是吗?)。
对于map端连接的情况,两个表以相同方式划分桶。处理左边表内某个桶的 mapper知道右边表内相匹配的行在对应的桶内。因此,mapper只需要获取那个桶 (这只是右边表内存储数据的一小部分)即可进行连接。这一优化方法并不一定要求两个表必须桶的个数相同,两个表的桶个数是倍数关系也可以。 用HiveQL对两个划分了桶的表进行连接,可参见“map连接”部分(P400)。
桶中的数据可以根据一个或多个列另外进行排序。由于这样对每个桶的连接变成了高效的 归并排序(merge-sort) , 因此可以进一步提升map端连接的效率。以下语法声明一个表使其使用排序桶:
CREATE TABLE bucketed_users(id INT, name STRING)
CLUSTERED BY (id) SORTED BY(id ASC) INTO 4 BUCKETS;
我们如何保证表中的数据都划分成桶了呢?把在Hive外生成的数据加载到划分成 桶的表中,当然是可以的。其实让Hive来划分桶更容易。这一操作通常针对已有的表。 Hive 并不检查数据文件中的桶是否和表定义中的桶一致(无论是对于桶的数量或用于划分桶的列)。如果两者不匹配,在査询时可能会碰到错 误或未定义的结果。因此,建议让Hive来进行划分桶的操作。
2. 往表中插入数据:
INSERT OVERWRITE TABLEbucketed_users SELECT * FROM users;
物理上,每个桶就是表(或分区)目录里的一个文件。它的文件名并不重要,但是桶 n 是按照字典序排列的第 n 个文件。 事实上,桶对应于 MapReduce 的输出文件分区:一个作业产生的桶(输出文件)和reduce任务个数相同.
3. 对桶中的数据进行采样:
hive> SELECT * FROMbucketed_users
> TABLESAMPLE(BUCKET 1 OUT OF 4 ON id);
0 Nat
4 Ann
桶的个数从1开始计数。因此,前面的查询从4个桶的第一个中获取所有的用户。 对于一个大规模的、均匀分布的数据集,这会返回表中约四分之一的数据行。我们 也可以用其他比例对若干个桶进行取样(因为取样并不是一个精确的操作,因此这个 比例不一定要是桶数的整数倍)。
注:tablesample是抽样语句,语法:TABLESAMPLE(BUCKET x OUTOF y)
y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。例如,table总共分了64份,当y=32时,抽取(64/32=)2个bucket的数据,当y=128时,抽取(64/128=)1/2个bucket的数据。x表示从哪个bucket开始抽取。例如,table总bucket数为32,tablesample(bucket 3 out of 16),表示总共抽取(32/16=)2个bucket的数据,分别为第3个bucket和第(3+16=)19个bucket的数据。
3.5 从指定文件中往表中加载数据
hive> load data local inpath "/home/hadoop/student.txt" into table student;
Loading data to table myhive.student
OK
Time taken: 1.854 seconds
hive>

上面使用到的文本文件student.txt需要将其存入hive中,student.txt数据格式如下:
95002,刘晨,女,19,IS
95017,王风娟,女,18,IS
95018,王一,女,19,IS
95013,冯伟,男,21,CS
95014,王小丽,女,19,CS
95019,邢小丽,女,19,IS
95020,赵钱,男,21,IS
95003,王敏,女,22,MA
95004,张立,男,19,IS
95012,孙花,女,20,CS
95010,孔小涛,男,19,CS
95005,刘刚,男,18,MA
95006,孙庆,男,23,CS
95007,易思玲,女,19,MA
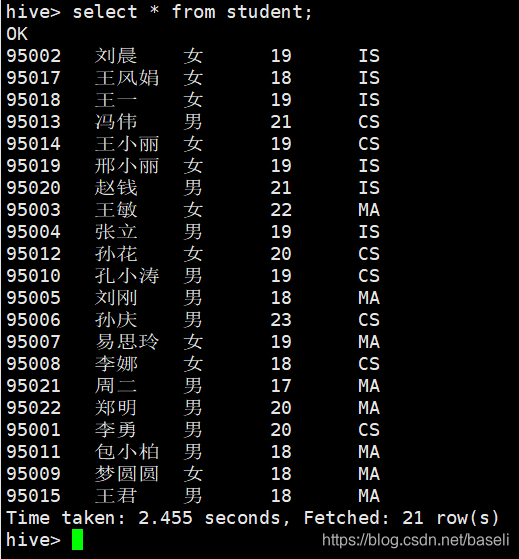
3.6 查询数据
hive> select * from student;
OK
95002 刘晨 女 19 IS
95017 王风娟 女 18 IS
95018 王一 女 19 IS
95013 冯伟 男 21 CS
95014 王小丽 女 19 CS
95019 邢小丽 女 19 IS
95020 赵钱 男 21 IS
95003 王敏 女 22 MA
95009 梦圆圆 女 18 MA
95015 王君 男 18 MA
Time taken: 2.455 seconds, Fetched: 21 row(s)
hive>
3.7 查看表结构
hive> desc student;
OK
id int
name string
sex string
age int
department string
Time taken: 0.102 seconds, Fetched: 5 row(s)
hive>
hive> desc extended student;
OK
id int
name string
sex string
age int
department string
Detailed Table Information Table(tableName:student, dbName:myhive, owner:hadoop, createTime:1522750487, lastAccessTime:0, retention:0, sd:StorageDescriptor(cols:[FieldSchema(name:id, type:int, comment:null), FieldSchema(name:name, type:string, comment:null), FieldSchema(name:sex, type:string, comment:null), FieldSchema(name:age, type:int, comment:null), FieldSchema(name:department, type:string, comment:null)], location:hdfs://myha01/user/hive/warehouse/myhive.db/student, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters:{serialization.format=,, field.delim=,}), bucketCols:[], sortCols:[], parameters:{}, skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[], skewedColValueLocationMaps:{}), storedAsSubDirectories:false), partitionKeys:[], parameters:{transient_lastDdlTime=1522750695, totalSize=523, numRows=0, rawDataSize=0, numFiles=1}, viewOriginalText:null, viewExpandedText:null, tableType:MANAGED_TABLE, rewriteEnabled:false)
Time taken: 0.127 seconds, Fetched: 7 row(s)
hive>
hive> desc formatted student;
OK
# col_name data_type comment
id int
name string
sex string
age int
department string
# Detailed Table Information
Database: myhive
Owner: hadoop
CreateTime: Tue Apr 03 18:14:47 CST 2018
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://myha01/user/hive/warehouse/myhive.db/student
Table Type: MANAGED_TABLE
Table Parameters:
numFiles 1
numRows 0
rawDataSize 0
totalSize 523
transient_lastDdlTime 1522750695
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim ,
serialization.format ,
Time taken: 0.13 seconds, Fetched: 34 row(s)
hive>
3.8 常用DDL语句
3.8.1 库操作
1、创建库
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment] //关于数据块的描述
[LOCATION hdfs_path] //指定数据库在HDFS上的存储位置
[WITH DBPROPERTIES (property_name=property_value, ...)]; //指定数据块属性
默认地址:/user/hive/warehouse/db_name.db/table_name/partition_name/…
(1)创建普通的数据库
0: jdbc:hive2://hadoop3:10000> create database t1;No rows affected (0.308 seconds)0: jdbc:hive2://hadoop3:10000> show databases;+----------------+| database_name |+----------------+| default || myhive || t1 |+----------------+3 rows selected (0.393 seconds)0: jdbc:hive2://hadoop3:10000> (2)创建库的时候检查存与否
0: jdbc:hive2://hadoop3:10000> create database if not exists t1;No rows affected (0.176 seconds)0: jdbc:hive2://hadoop3:10000> (3)创建库的时候带注释
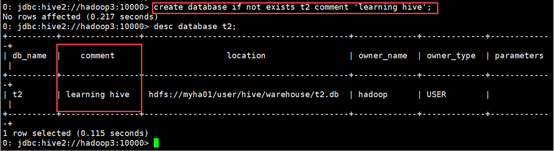
0: jdbc:hive2://hadoop3:10000> create database if not exists t2 comment 'learning hive';
No rows affected (0.217 seconds)
0: jdbc:hive2://hadoop3:10000>
(4)创建带属性的库
0: jdbc:hive2://hadoop3:10000> create database if not exists t3 with dbproperties('creator'='hadoop','date'='2019-04-05');No rows affected (0.255 seconds)0: jdbc:hive2://hadoop3:10000>2、查看库
查看库的方式:
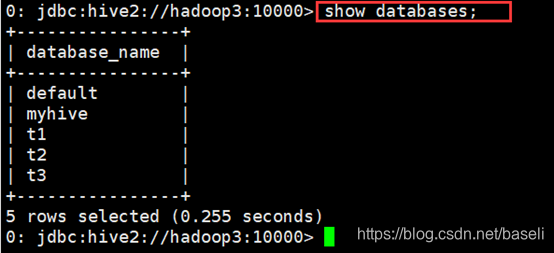
(1)查看有哪些数据库
0: jdbc:hive2://hadoop3:10000> show databases;
+----------------+
| database_name |
+----------------+
| default |
| myhive |
| t1 |
| t2 |
| t3 |
+----------------+
5 rows selected (0.164 seconds)
0: jdbc:hive2://hadoop3:10000>
(2)显示数据库的详细属性信息
语法
desc database [extended] dbname;
示例
0: jdbc:hive2://hadoop3:10000> desc database extended t3;+----------+----------+------------------------------------------+-------------+-------------+------------------------------------+| db_name | comment | location | owner_name | owner_type | parameters |+----------+----------+------------------------------------------+-------------+-------------+------------------------------------+| t3 | | hdfs://myha01/user/hive/warehouse/t3.db | hadoop | USER | {date=2018-04-05, creator=hadoop} |+----------+----------+------------------------------------------+-------------+-------------+------------------------------------+1 row selected (0.11 seconds)0: jdbc:hive2://hadoop3:10000>
(3)查看正在使用哪个库
0: jdbc:hive2://hadoop3:10000> select current_database();+----------+| _c0 |+----------+| default |+----------+1 row selected (1.36 seconds)0: jdbc:hive2://hadoop3:10000>
(4)查看创建库的详细语句
0: jdbc:hive2://hadoop3:10000> show create database t3;+----------------------------------------------+| createdb_stmt |+----------------------------------------------+| CREATE DATABASE `t3` || LOCATION || 'hdfs://myha01/user/hive/warehouse/t3.db' || WITH DBPROPERTIES ( || 'creator'='hadoop', || 'date'='2018-04-05') |+----------------------------------------------+6 rows selected (0.155 seconds)0: jdbc:hive2://hadoop3:10000>
3、删除库
删除库操作
drop database dbname;drop database if exists dbname;默认情况下,hive 不允许删除包含表的数据库,有两种解决办法:
1、 手动删除库下所有表,然后删除库
2、 使用 cascade 关键字
drop database if exists dbname cascade;
默认情况下就是 restrict drop database if exists myhive ==== drop database if exists myhive restrict
(1)删除不含表的数据库
0: jdbc:hive2://hadoop3:10000> show tables in t1;+-----------+| tab_name |+-----------++-----------+No rows selected (0.147 seconds)0: jdbc:hive2://hadoop3:10000> drop database t1;No rows affected (0.178 seconds)0: jdbc:hive2://hadoop3:10000> show databases;+----------------+| database_name |+----------------+| default || myhive || t2 || t3 |+----------------+4 rows selected (0.124 seconds)0: jdbc:hive2://hadoop3:10000>
(2)删除含有表的数据库
0: jdbc:hive2://hadoop3:10000> drop database if exists t3 cascade;No rows affected (1.56 seconds)0: jdbc:hive2://hadoop3:10000>
4、切换库
use database_name
0: jdbc:hive2://hadoop3:10000> use t2;No rows affected (0.109 seconds)0: jdbc:hive2://hadoop3:10000>
3.8.2 表操作
1、创建表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
•CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXIST 选项来忽略这个异常•EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION)•LIKE 允许用户复制现有的表结构,但是不复制数据•COMMENT可以为表与字段增加描述•PARTITIONED BY 指定分区
•ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES
(property_name=property_value, property_name=property_value, ...)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,
用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive 通过 SerDe 确定表的具体的列的数据。
•STORED AS
SEQUENCEFILE //序列化文件
| TEXTFILE //普通的文本文件格式
| RCFILE //行列存储相结合的文件
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname //自定义文件格式
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCE 。•LOCATION指定表在HDFS的存储路径最佳实践:
如果一份数据已经存储在HDFS上,并且要被多个用户或者客户端使用,最好创建外部表
反之,最好创建内部表。
如果不指定,就按照默认的规则存储在默认的仓库路径中。
使用t2数据库进行操作
(1)创建默认的内部表
0: jdbc:hive2://hadoop3:10000> create table student(id int, name string, sex string, age int,department string) row format delimited fields terminated by ",";No rows affected (0.222 seconds)0: jdbc:hive2://hadoop3:10000> desc student;+-------------+------------+----------+| col_name | data_type | comment |+-------------+------------+----------+| id | int | || name | string | || sex | string | || age | int | || department | string | |+-------------+------------+----------+5 rows selected (0.168 seconds)0: jdbc:hive2://hadoop3:10000>
(2)外部表
0: jdbc:hive2://hadoop3:10000> create external table student_ext
(id int, name string, sex string, age int,department string) row format delimited fields terminated by "," location "/hive/student";No rows affected (0.248 seconds)0: jdbc:hive2://hadoop3:10000> (3)分区表
0: jdbc:hive2://hadoop3:10000> create external table student_ptn(id int, name string, sex string, age int,department string). . . . . . . . . . . . . . .> partitioned by (city string). . . . . . . . . . . . . . .> row format delimited fields terminated by ",". . . . . . . . . . . . . . .> location "/hive/student_ptn";No rows affected (0.24 seconds)0: jdbc:hive2://hadoop3:10000> 添加分区
0: jdbc:hive2://hadoop3:10000> alter table student_ptn add partition(city="beijing");No rows affected (0.269 seconds)0: jdbc:hive2://hadoop3:10000> alter table student_ptn add partition(city="shenzhen");No rows affected (0.236 seconds)0: jdbc:hive2://hadoop3:10000> 如果某张表是分区表。那么每个分区的定义,其实就表现为了这张表的数据存储目录下的一个子目录
如果是分区表。那么数据文件一定要存储在某个分区中,而不能直接存储在表中。
(4)分桶表
0: jdbc:hive2://hadoop3:10000> create external table student_bck(id int, name string, sex string, age int,department string). . . . . . . . . . . . . . .> clustered by (id) sorted by (id asc, name desc) into 4 buckets. . . . . . . . . . . . . . .> row format delimited fields terminated by ",". . . . . . . . . . . . . . .> location "/hive/student_bck";No rows affected (0.216 seconds)0: jdbc:hive2://hadoop3:10000> (5)使用CTAS创建表
作用: 就是从一个查询SQL的结果来创建一个表进行存储
现象student表中导入数据
0: jdbc:hive2://hadoop3:10000> load data local inpath "/home/hadoop/student.txt" into table student;No rows affected (0.715 seconds)0: jdbc:hive2://hadoop3:10000> select * from student;+-------------+---------------+--------------+--------------+---------------------+| student.id | student.name | student.sex | student.age | student.department |+-------------+---------------+--------------+--------------+---------------------+| 95002 | 刘晨 | 女 | 19 | IS || 95017 | 王风娟 | 女 | 18 | IS || 95018 | 王一 | 女 | 19 | IS || 95013 | 冯伟 | 男 | 21 | CS || 95014 | 王小丽 | 女 | 19 | CS || 95019 | 邢小丽 | 女 | 19 | IS || 95020 | 赵钱 | 男 | 21 | IS || 95003 | 王敏 | 女 | 22 | MA || 95004 | 张立 | 男 | 19 | IS || 95012 | 孙花 | 女 | 20 | CS || 95010 | 孔小涛 | 男 | 19 | CS || 95005 | 刘刚 | 男 | 18 | MA || 95006 | 孙庆 | 男 | 23 | CS || 95007 | 易思玲 | 女 | 19 | MA || 95008 | 李娜 | 女 | 18 | CS || 95021 | 周二 | 男 | 17 | MA || 95022 | 郑明 | 男 | 20 | MA || 95001 | 李勇 | 男 | 20 | CS || 95011 | 包小柏 | 男 | 18 | MA || 95009 | 梦圆圆 | 女 | 18 | MA || 95015 | 王君 | 男 | 18 | MA |+-------------+---------------+--------------+--------------+---------------------+21 rows selected (0.342 seconds)0: jdbc:hive2://hadoop3:10000> 使用CTAS创建表
0: jdbc:hive2://hadoop3:10000> create table student_ctas as select * from student where id < 95012;WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution
engine (i.e. spark, tez) or using Hive 1.X releases.No rows affected (34.514 seconds)0: jdbc:hive2://hadoop3:10000> select * from student_ctas. . . . . . . . . . . . . . .> ;+------------------+--------------------+-------------------+-------------------+--------------------------+| student_ctas.id | student_ctas.name | student_ctas.sex | student_ctas.age | student_ctas.department |+------------------+--------------------+-------------------+-------------------+--------------------------+| 95002 | 刘晨 | 女 | 19 | IS || 95003 | 王敏 | 女 | 22 | MA || 95004 | 张立 | 男 | 19 | IS || 95010 | 孔小涛 | 男 | 19 | CS || 95005 | 刘刚 | 男 | 18 | MA || 95006 | 孙庆 | 男 | 23 | CS || 95007 | 易思玲 | 女 | 19 | MA || 95008 | 李娜 | 女 | 18 | CS || 95001 | 李勇 | 男 | 20 | CS || 95011 | 包小柏 | 男 | 18 | MA || 95009 | 梦圆圆 | 女 | 18 | MA |+------------------+--------------------+-------------------+-------------------+--------------------------+11 rows selected (0.445 seconds)0: jdbc:hive2://hadoop3:10000>
(6)复制表结构
0: jdbc:hive2://hadoop3:10000> create table student_copy like student;No rows affected (0.217 seconds)0: jdbc:hive2://hadoop3:10000> 注意:
如果在table的前面没有加external关键字,那么复制出来的新表。无论如何都是内部表
如果在table的前面有加external关键字,那么复制出来的新表。无论如何都是外部表
2、查看表
查看当前使用的数据库中有哪些表
0: jdbc:hive2://hadoop3:10000> show tables;+---------------+| tab_name |+---------------+| student || student_bck || student_copy || student_ctas || student_ext || student_ptn |+---------------+6 rows selected (0.163 seconds)0: jdbc:hive2://hadoop3:10000> 查看非当前使用的数据库中有哪些表
0: jdbc:hive2://hadoop3:10000> show tables in myhive;+-----------+| tab_name |+-----------+| student |+-----------+1 row selected (0.144 seconds)0: jdbc:hive2://hadoop3:10000> 查看数据库中以xxx开头的表
0: jdbc:hive2://hadoop3:10000> show tables like 'student_c*';+---------------+| tab_name |+---------------+| student_copy || student_ctas |+---------------+2 rows selected (0.13 seconds)0: jdbc:hive2://hadoop3:10000> 0: jdbc:hive2://hadoop3:10000> desc student;+-------------+------------+----------+| col_name | data_type | comment |+-------------+------------+----------+| id | int | || name | string | || sex | string | || age | int | || department | string | |+-------------+------------+----------+5 rows selected (0.149 seconds)0: jdbc:hive2://hadoop3:10000> 查看表的详细信息(格式不友好)
0: jdbc:hive2://hadoop3:10000> desc extended student;
查看表的详细信息(格式友好)
0: jdbc:hive2://hadoop3:10000> desc formatted student;
查看分区信息
0: jdbc:hive2://hadoop3:10000> show partitions student_ptn;
0: jdbc:hive2://hadoop3:10000> show create table student_ptn;
3、修改表
0: jdbc:hive2://hadoop3:10000> alter table student rename to new_student;
A. 增加一个字段
0: jdbc:hive2://hadoop3:10000> alter table new_student add columns (score int);
B. 修改一个字段的定义
0: jdbc:hive2://hadoop3:10000> alter table new_student change name new_name string;
C. 删除一个字段
不支持
D. 替换所有字段
0: jdbc:hive2://hadoop3:10000> alter table new_student replace columns (id int, name string, address string);
A. 添加分区
静态分区
添加一个
0: jdbc:hive2://hadoop3:10000> alter table student_ptn add partition(city="chongqing");添加多个
0: jdbc:hive2://hadoop3:10000> alter table student_ptn add partition(city="chongqing2") partition(city="chongqing3") partition(city="chongqing4");动态分区
先向student_ptn表中插入数据,数据格式如下图
0: jdbc:hive2://hadoop3:10000> load data local inpath "/home/hadoop/student.txt" into table student_ptn partition(city="beijing");
现在我把这张表的内容直接插入到另一张表student_ptn_age中,并实现sex为动态分区(不指定到底是哪中性别,让系统自己分配决定)
首先创建student_ptn_age并指定分区为age
0: jdbc:hive2://hadoop3:10000> create table student_ptn_age(id int,name string,sex string,department string) partitioned by (age int);从student_ptn表中查询数据并插入student_ptn_age表中
0: jdbc:hive2://hadoop3:10000> insert overwrite table student_ptn_age partition(age). . . . . . . . . . . . . . .> select id,name,sex,department,age from student_ptn;WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.No rows affected (27.905 seconds)0: jdbc:hive2://hadoop3:10000>
B. 修改分区
修改分区,一般来说,都是指修改分区的数据存储目录
在添加分区的时候,直接指定当前分区的数据存储目录
0: jdbc:hive2://hadoop3:10000> alter table student_ptn add if not exists partition(city='beijing') . . . . . . . . . . . . . . .> location '/student_ptn_beijing' partition(city='cc') location '/student_cc';No rows affected (0.306 seconds)0: jdbc:hive2://hadoop3:10000> 修改已经指定好的分区的数据存储目录
0: jdbc:hive2://hadoop3:10000> alter table student_ptn partition (city='beijing') set location '/student_ptn_beijing';此时原先的分区文件夹仍存在,但是在往分区添加数据时,只会添加到新的分区目录
C. 删除分区
0: jdbc:hive2://hadoop3:10000> alter table student_ptn drop partition (city='beijing');
4、删除表
0: jdbc:hive2://hadoop3:10000> drop table new_student;
5、清空表
0: jdbc:hive2://hadoop3:10000> truncate table student_ptn;3.8.3 其他辅助命令
四、Java集成(springBoot)
4.1 添加依赖和配置
//pom.xml文件配置
org.springframework.boot
spring-boot-starter-web
com.alibaba
druid-spring-boot-starter
1.1.1
org.springframework.boot
spring-boot-starter-jdbc
org.springframework.data
spring-data-hadoop
2.5.0.RELEASE
org.apache.hive
hive-jdbc
2.3.3
org.eclipse.jetty.aggregate
*
org.apache.tomcat
tomcat-jdbc
jdk.tools
jdk.tools
1.8
system
${JAVA_HOME}/lib/tools.jar
//properties配置文件中增加如下hive配置
#hive
hive.url = jdbc.hive2//10.76.148.15:8183/hive
hive.driver-class-name = org.apache.hive.jdbc.HiveDriver
hive.user = root
hive.password = root
4.2 初始化连接
//配置数据源与JdbcTemplate
//使用SpringBoot默认的org.apache.tomcat.jdbc.pool.DataSource 数据源,并使用这个数据源装配一个JdbcTemplate,也可以使用其他连接池。
import com.didichuxing.fe.offline.util.ConfigPropertyUtil;
import org.apache.tomcat.jdbc.pool.DataSource;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.jdbc.core.JdbcTemplate;
import java.util.ArrayList;
import java.util.List;
public class HiveConfig {
private static final Logger logger = LoggerFactory.getLogger(HiveConfig.class);
private static volatile HiveConfig config = null;
private static ConfigPropertyUtil propertyUtil = ConfigPropertyUtil.getInstance("hiveConfig.properties");
private DataSource dataSource = null;
private JdbcTemplate jdbcTemplate = null;
private List sparkTableNameList = null;
public static HiveConfig getInstance(){
if(config == null){
synchronized (HiveConfig.class){
if (config == null){
config = new HiveConfig();
}
}
}
return config;
}
private HiveConfig(){
init();
}
private void init() {
dataSource = new DataSource() {
{
try{
setUrl(propertyUtil.getPropertyVal("hive.url"));
setDriverClassName(propertyUtil.getPropertyVal("hive.driver-class-name"));
setUsername(propertyUtil.getPropertyVal("hive.user"));
setPassword(propertyUtil.getPropertyVal("hive.password"));
logger.info("hive数据源dataSource初始化完成");
}catch(Exception e){
logger.error(e.getMessage());
}
}
};
jdbcTemplate = new JdbcTemplate(dataSource);
}
public DataSource getDataSource() {
return dataSource;
}
public JdbcTemplate getJdbcTemplate() {
return jdbcTemplate;
}
}
4.3 执行hive的sql语句操作hive
import com.didichuxing.fe.offline.config.HiveConfig;
import com.didichuxing.fe.offline.entity.TableInfo;
import com.didichuxing.fe.offline.util.DateUtil;
import com.didichuxing.fe.offline.util.ParquetShema;
import com.didichuxing.fe.offline.util.SparkTool;
import org.apache.hadoop.conf.Configuration;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.tomcat.jdbc.pool.DataSource;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.dao.DataAccessException;
import org.springframework.jdbc.core.JdbcTemplate;
import org.apache.hadoop.fs.Path;
import java.nio.file.Paths;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.List;
public class HiveJdbcDao {
private static final Logger logger = (Logger) LoggerFactory.getLogger(HiveJdbcDao.class);
private static HiveJdbcDao hiveJdbcDao = null;
public static HiveJdbcDao getInstance(){
if(hiveJdbcDao == null){
synchronized (MysqlBaseDao.class){
if (hiveJdbcDao == null){
hiveJdbcDao = new HiveJdbcDao();
}
}
}
return hiveJdbcDao;
}
private HiveJdbcDao(){
}
private DataSource jdbcDataSource = HiveConfig.getInstance().getDataSource();
private JdbcTemplate hiveJdbcTemplate = HiveConfig.getInstance().getJdbcTemplate();
/**
* 查询hive表中字段名以及类型
* @param abstractSql
* @return
* @throws SQLException
*/
public List selectTableInfoFromHive(String abstractSql){
List tableInfoList = new ArrayList();
TableInfo tableInfo = new TableInfo();
Statement statement = null;
logger.info("Running sql: " + abstractSql);
try {
statement = jdbcDataSource.getConnection().createStatement();
ResultSet res = statement.executeQuery(abstractSql);
while (res.next()) {
tableInfo.setColumnName(res.getString(1));
tableInfo.setColumnType(res.getString(2));
tableInfo.setColumnComment(res.getString(3));
tableInfoList.add(tableInfo);
}
} catch (SQLException e) {
logger.info(e.getMessage());
}
return tableInfoList;
}
/**
* 查询hive库中表名
* @param abstractSql
* @return
* @throws SQLException
*/
public List selectTableNameFromHive(String abstractSql){
List tableNameList = new ArrayList();
Statement statement = null;
logger.info("Running sql: " + abstractSql);
try {
statement = jdbcDataSource.getConnection().createStatement();
ResultSet res = statement.executeQuery(abstractSql);
logger.error( "hive表名String[]: " +res.toString());
while (res.next()) {
tableNameList.add(res.getString(1));
}
} catch (SQLException e) {
logger.info(e.getMessage());
}
return tableNameList;
}
/**
* 自动从本地数据加载进入hive
* @param filepath
*/
public void loadIntoHiveTable(String filepath, String tableName) {
String dateFileFormat = DateUtil.getYesterdayFileFormat();
String[] dateSplit = dateFileFormat.split("/");
StringBuffer buildSql = new StringBuffer();
buildSql.append("load data inpath " ).append("\'").append(filepath).append("\'")
.append(" into table fe.").append(tableName).append(" partition (year = ")
.append(dateSplit[0]).append(", month = ").append(dateSplit[1])
.append(",day = ").append(dateSplit[2]).append(")");
// String sql = "load data inpath " + "\'" + filepath + "\'" +
// " into table fe." + tableName + " partition (year = " + dateSplit[0] + ", month = "
// + dateSplit[1] + ",day = " + dateSplit[2] + ")";
logger.info("将数据加载进入hive表的sql : {}", buildSql.toString());
try {
hiveJdbcTemplate.execute(buildSql.toString());
} catch (DataAccessException dae) {
logger.error(dae.toString());
}
}
/**
* 对hive表结构进行更新(增加字段)
* @param abstractSql
*/
public void updateHiveTable(String abstractSql) {
try {
hiveJdbcTemplate.execute(abstractSql);
} catch (DataAccessException dae) {
logger.error(dae.toString());
}
}
}
五、工具/命令连接方式
六、本文术语
MapReduce:
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
Hadoop:
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),其中一个组件是HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算
Metadata:
元数据包含用Hive创建的database、table等的元信息。元数据存储在关系型数据库中。如Derby、MySQL等。
Metastore:
客户端连接metastore服务,metastore再去连接MySQL数据库来存取元数据。有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore 服务即可。
HDFS:
HDFS,是Hadoop Distributed File System的简称,是Hadoop抽象文件系统的一种实现。Hadoop抽象文件系统可以与本地系统、Amazon S3等集成,甚至可以通过Web协议(webhsfs)来操作。HDFS的文件分布在集群机器上,同时提供副本进行容错及可靠性保证。例如客户端写入读取文件的直接操作都是分布在集群各个机器上的,没有单点性能压力。
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件的访问操作;集群中的DataNode管理存储的数据。
HDFS有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以实现流的形式访问(streaming access)文件系统中的数据。

















 3937
3937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









