







什么是MVCC?
MVCC, 即多版本并发控制。MVCC 的实现,是通过保存数据在某个时间点的快照来实现的。根据事务开始的时间不同,每个事务对同一张表,同一时刻看到的数据可能是不一样的。
MVCC使得大部分支持行锁的事务引擎,不再单纯的使用行锁来进行数据库的并发控制,取而代之的是把数据库的行锁与行的多个版本结合起来,只需要很小的开销,就可以实现非锁定读,从而大大提高数据库系统的并发性能。
MVCC 解决了并发读写不冲突。是通过在每行纪录后面保存两个隐藏的列来实现的。这两个列,一个保存了行的创建版本号,一个保存了行的删除版本号。每开始一个新的事务,系统版本号都会自动递增。事务开始时刻的系统版本号会作为事务的版本号,用来和查询到的每行纪录的版本号进行比较。
在InnoDB中,给每行增加两个隐藏字段来实现MVCC,一个用来记录数据行的创建时间,另一个用来记录行的过期时间(删除时间)。在实际操作中,存储的并不是时间,而是事务的版本号,每开启一个新事务,事务的版本号就会递增。
于是乎,默认的隔离级别(REPEATABLE READ)下,增删查改变成了这样:
-
SELECT
-
读取创建版本小于或等于当前事务版本号,并且删除版本为空或大于当前事务版本号的记录。这样可以保证在读取之前记录是存在的。
-
-
INSERT
-
将当前事务的版本号保存至行的创建版本号
-
-
UPDATE
-
新插入一行,并以当前事务的版本号作为新行的创建版本号,同时将原记录行的删除版本号设置为当前事务版本号
-
-
DELETE
-
将当前事务的版本号保存至行的删除版本号
-
MVCC的实现原理
对于 InnoDB ,聚簇索引记录中包含 3 个隐藏的列:
-
ROW ID:隐藏的自增 ID,如果表没有主键,InnoDB 会自动按 ROW ID 产生一个聚集索引树。
-
事务 ID:记录最后一次修改该记录的事务 ID。
-
回滚指针:指向这条记录的上一个版本。
我们拿上面的例子,对应解释下 MVCC 的实现原理,如下图:
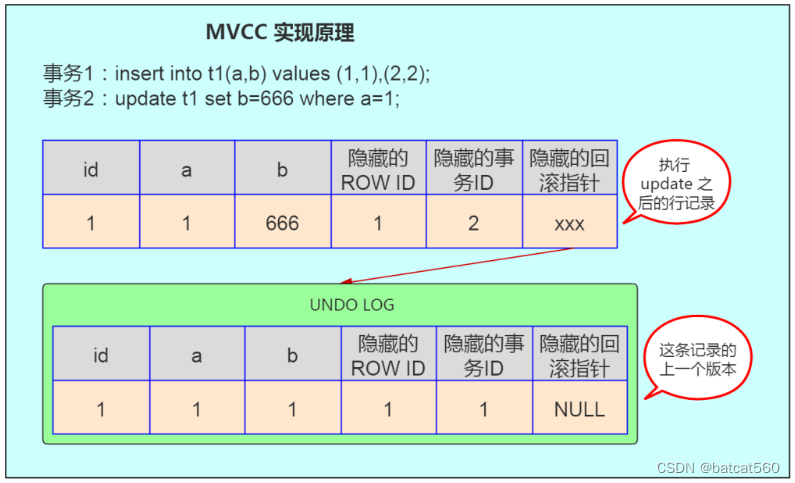
如图,首先 insert 语句向表 t1 中插入了一条数据,a 字段为 1,b 字段为 1, ROW ID 也为 1 ,事务 ID 假设为 1,回滚指针假设为 null。当执行 update t1 set b=666 where a=1 时,大致步骤如下:
-
数据库会先对满足 a=1 的行加排他锁;
-
然后将原记录复制到 undo 表空间中;
-
修改 b 字段的值为 666,修改事务 ID 为 2;
-
并通过隐藏的回滚指针指向 undo log 中的历史记录;
-
事务提交,释放前面对满足 a=1 的行所加的排他锁。
在前面实验的第 6 步中,session2 查询的结果是 session1 修改之前的记录,这个记录就是来自 undolog 中。
因此可以总结出 MVCC 实现的原理大致是:
InnoDB 每一行数据都有一个隐藏的回滚指针,用于指向该行修改前的最后一个历史版本,这个历史版本存放在 undo log 中。如果要执行更新操作,会将原记录放入 undo log 中,并通过隐藏的回滚指针指向 undo log 中的原记录。其它事务此时需要查询时,就是查询 undo log 中这行数据的最后一个历史版本。
MVCC 最大的好处是读不加锁,读写不冲突,极大地增加了 MySQL 的并发性。通过 MVCC,保证了事务 ACID 中的 I(隔离性)特性。















 2906
2906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









