






 在无并发和并发100的场景下,针对1000万、500万、200万不同数据量的查询进行了测试。无并发时,数据量减半对性能提升不明显;而在并发100的情况下,数据量从1000万减少到500万,性能只提升了一倍。
在无并发和并发100的场景下,针对1000万、500万、200万不同数据量的查询进行了测试。无并发时,数据量减半对性能提升不明显;而在并发100的情况下,数据量从1000万减少到500万,性能只提升了一倍。
表名:log_request_test1(1000万)``log_request_test2(500万)``log_request_test3(200万)
由于是新表,所以不存在收缩数据库。
CREATE TABLE log_request_test1 (
ID bigint(20) NOT NULL AUTO_INCREMENT,
TRANSACTION_ID varchar(40) DEFAULT NULL,
LOG_LEVEL varchar(5) DEFAULT NULL,
HOST_NAME varchar(50) DEFAULT NULL,
HOST_IP varchar(20) DEFAULT NULL,
SERVICE_ID int(11) DEFAULT NULL,
CLIENT_IP varchar(20) DEFAULT NULL,
REQ_PATH varchar(50) DEFAULT NULL,
CONTENT longtext,
USER_ID varchar(20) DEFAULT NULL,
TTID varchar(10) DEFAULT NULL,
CREATED_DATE datetime(3) NOT NULL,
APP_NAMESPACE varchar(100) DEFAULT NULL,
PRIMARY KEY (ID),
KEY Idx_Req_CreatedDate (CREATED_DATE),
KEY Idx_Req_TransactionId (TRANSACTION_ID,CREATED_DATE)
) ENGINE=InnoDB AUTO_INCREMENT=24391720 DEFAULT CHARSET=utf8
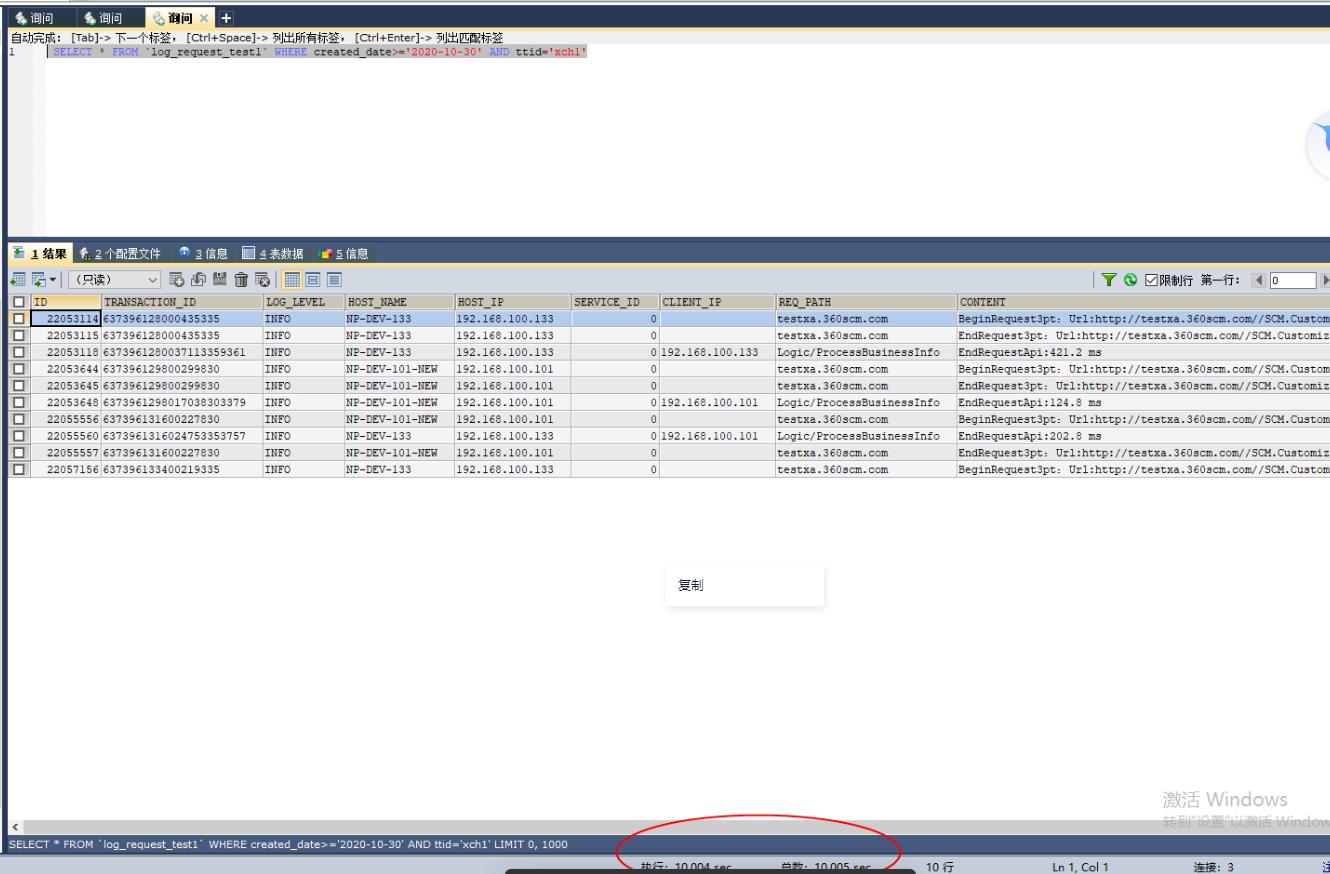
测试场景1: 无并发情况下查询10月30日后, ttid是 xch1的数据:
总量是1000万的查询,需要10秒
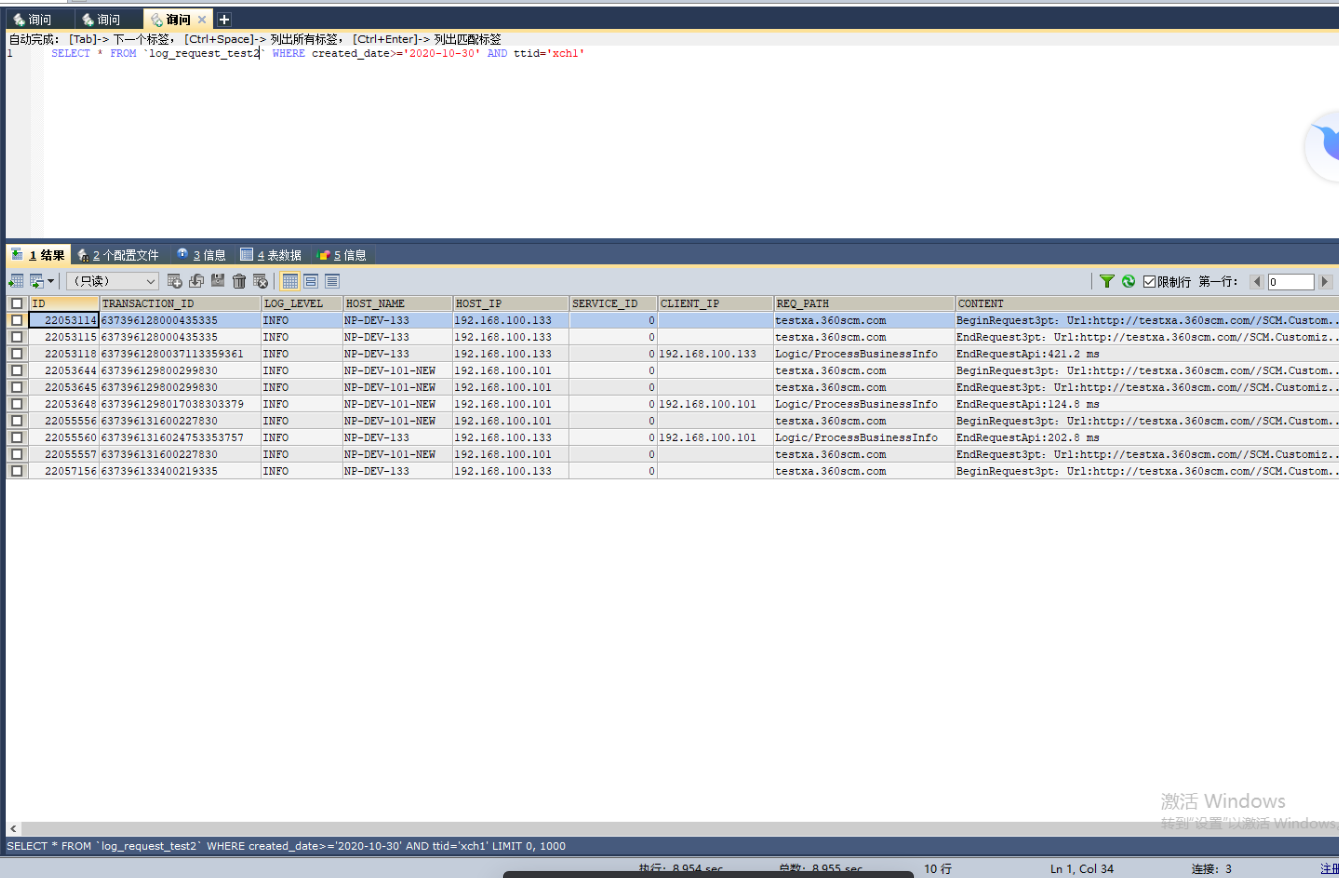
总量是500万的查询,需要8.9秒
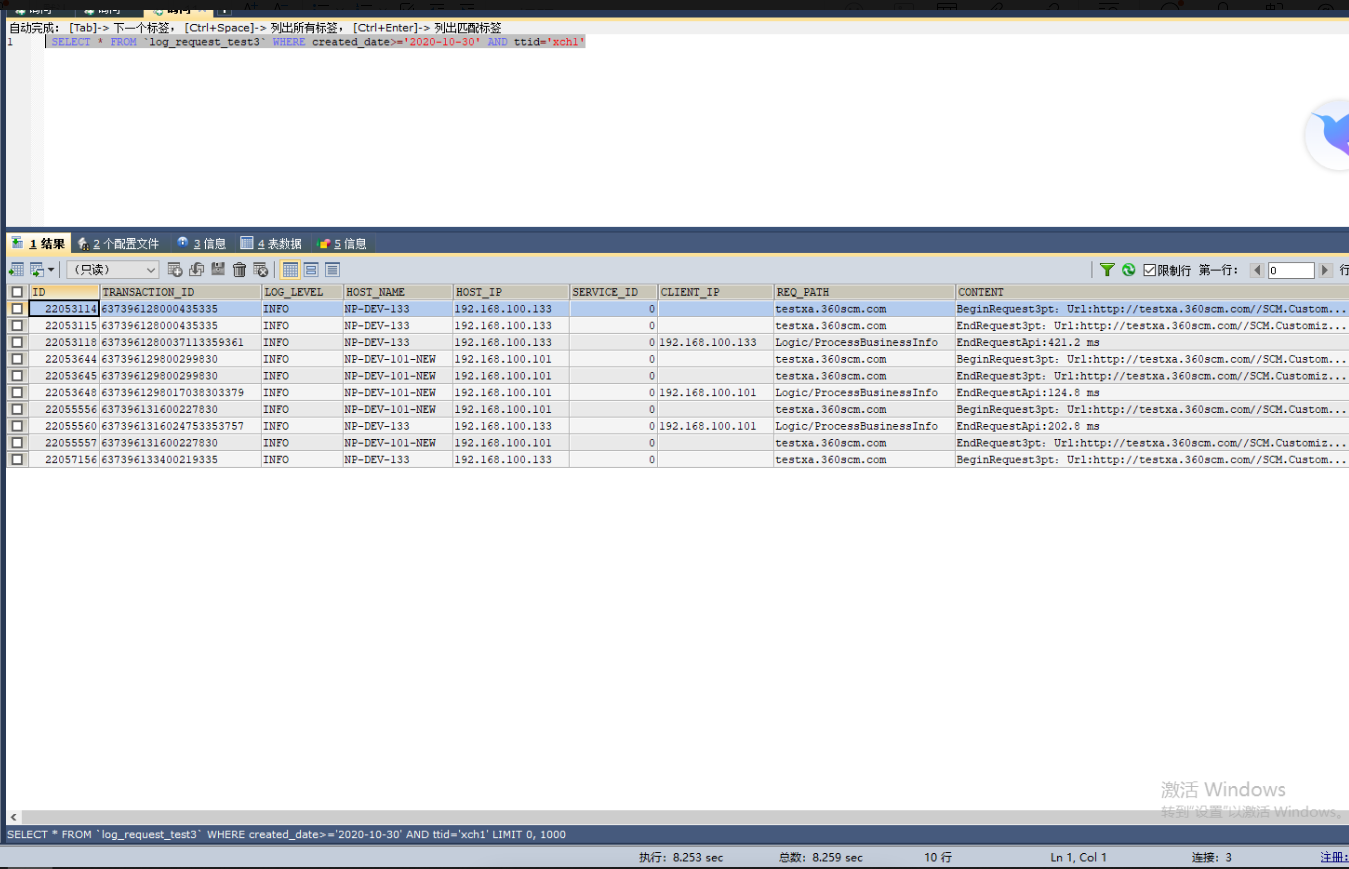
总量是200万的查询,需要8.2秒
结论1:
无并发情况下,数据从1000万减少到500万, 200万,性能提升不大
测试场景2:并发100情况下查询10月30日后, ttid是 xch1的数据:
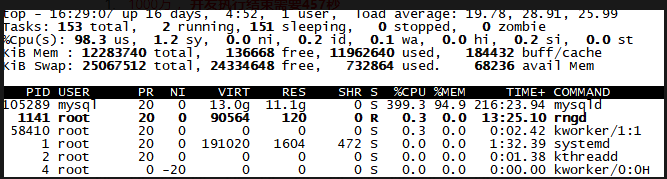
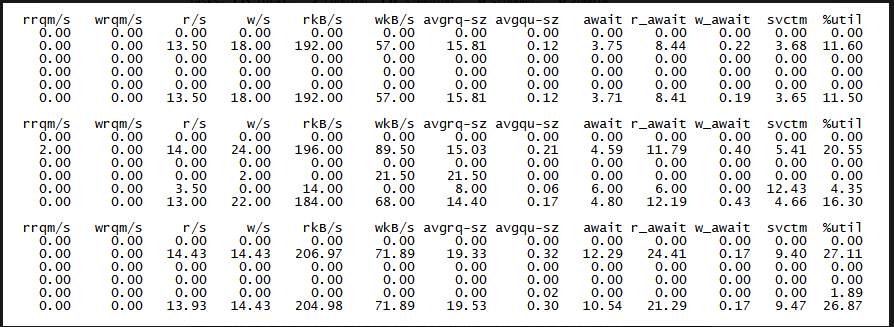
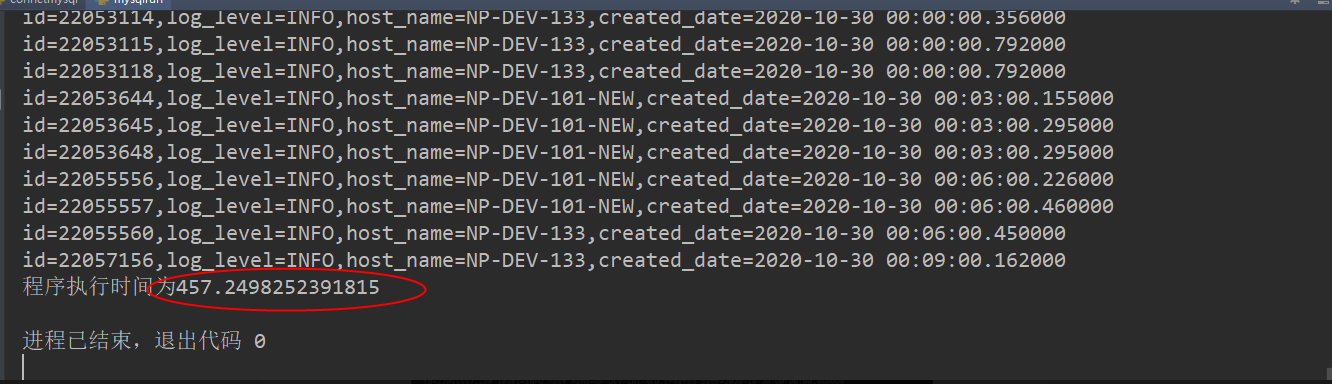
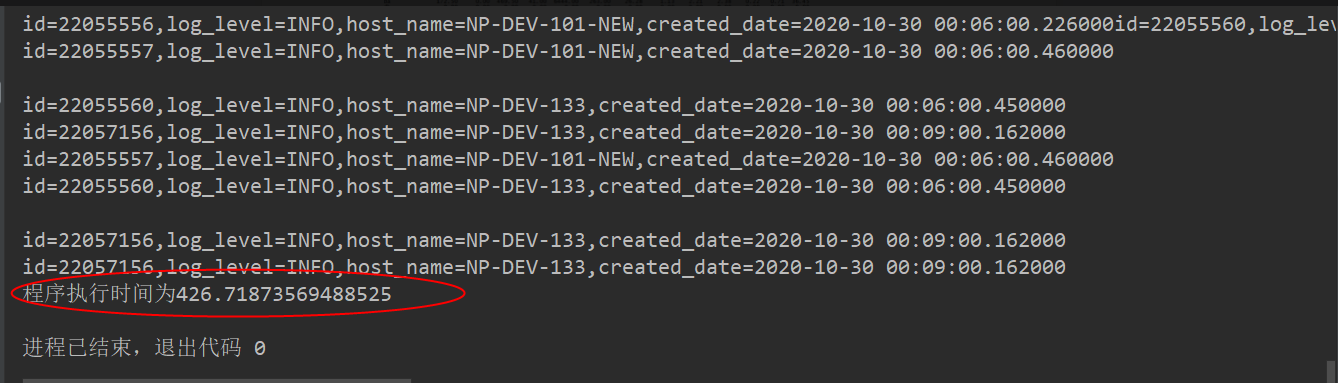
2. 500万 ,并发执行结束需要426秒
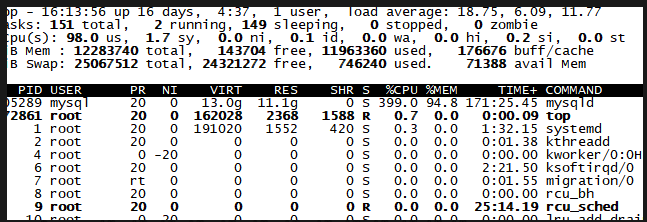
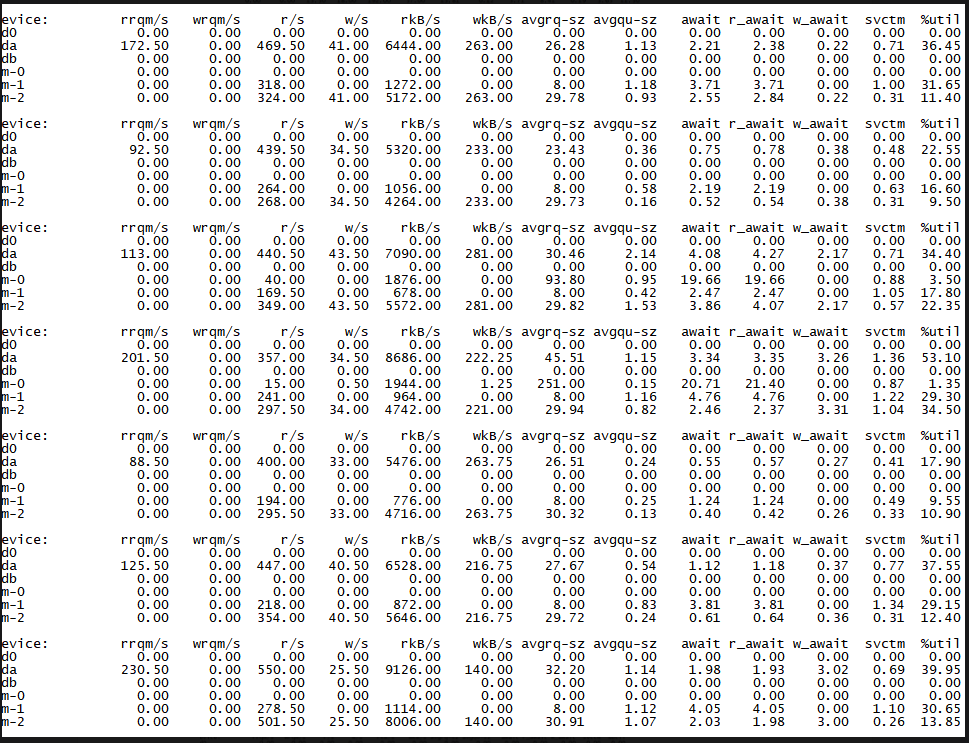
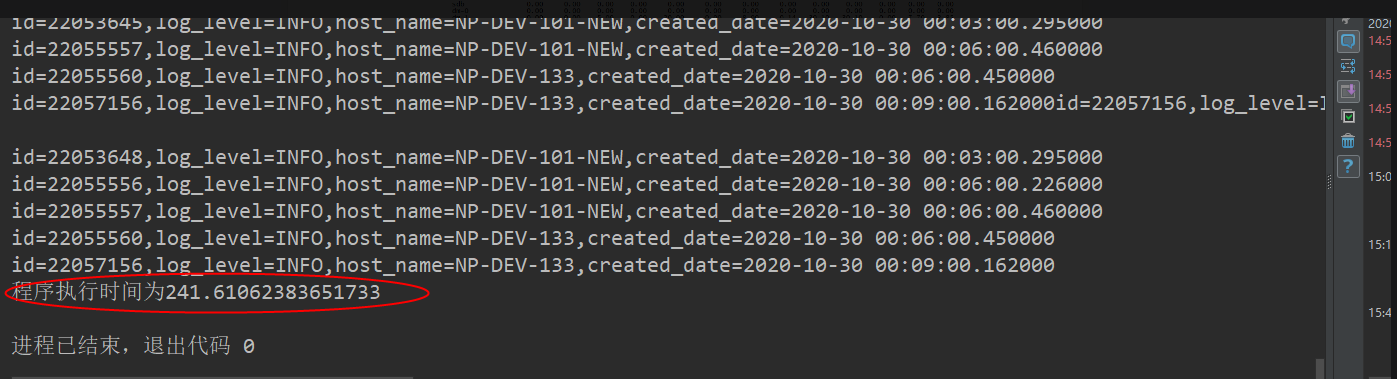
3 200万 ,并发执行结束需要241秒



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











