







大数据开发之路—2
第一篇博客简单记录了HDFS的搭建,有点划水了。因为Hadoop版本上到2.0以后加入了一个非常重要的工具–统一资源管理YARN。这也是我研究项目的最重要的一个工具之一。所以再简单补充一下YARN的配置,然后接着大数据开发环境的部署。
Hadoop搭建之YARN
Hadoop安装以后,只需要简单的配置几个文件就可以完成YARN的安装。
在hadoop安装目录下
cd etc/hadoop
首先配置yarn-site.xml,设置一下resourcemanager运行的主机名:
vim yarn-site.xml
配置如下:
<configuration>
<property>
<name>yarn.nodemanager.auxservices</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
</configuration>
然后配置mapred-site.xml,设置mapreduce使用YARN:
vim mapred-site.xml
配置如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
将刚配置的文件发送到hadoop2、hadoop3:
scp -r hadoop/ hadoop2:/usr/local/hadoop/etc/
scp -r hadoop/ hadoop3:/usr/local/hadoop/etc/
在hadoop1启动YARN:
start-yarn.sh
查看YARN是否启动成功:
jps
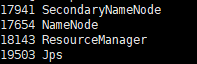
看到ResourceManager已启动成功。
在浏览器中输入hadoop1:8088:

至此,YARN已经安装成功!
Hadoop数据库技术
提到Hadoop的数据库技术很容易就想到HBase和Hive,但是实际上这并不是两个并行的技术,他们在Hadoop中担任的角色和发挥的作用是不同的,关于HBase和Hive的详细内容之后博主会专门写一篇来分析,今天就只是讲一下大数据开发环境的安装和部署。
HBase
安装HBase一定要注意版本的兼容性问题,我们安装的是Hadoop2.9.2版本,因此这里选择HBase2.2…x版本进行安装。图片来源:Hbase版本与Hadoop版本支持关系(官方)

- 安装包下载与安装
在/usr/local目录下
wget http://mirrors.hust.edu.cn/apache/hbase/stable/hbase-2.2.4-bin.tar.gz
tar -xvzf hbase-2.2.4-bin.tar.gz
mv hbase-2.2.4/ hbase
- 修改环境变量并测试
修改环境变量:
vim ~/.bashrc
export HBASE_HOME=/usr/local/hbase
export PATH=$PATH:$HBASE_HOME/bin
source ~/.bashrc
测试:
hbase version
出现如下表示成功:

3. HBase配置
切换到/usr/local/hbase/conf目录下,首先需要设置一下java环境,修改hbase-env.sh:
vim hbase-env.sh
export JAVA_HOME=/usr/local/java/jdk8u252-b09
因为我们配置的分布式HBase,并且HBase需要zookeeper作为通信,我们使用了HBase中内置的zookeeper,在hbase-site.xml中进行设置:
vim hbase-site.xml
配置如下:
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop1:9000/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop1,hadoop2,hadoop3</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/zookeeper</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
这里最后一条属性很重要,之前没有添加这条属性,导致启动HBase的时候HMaster几乎瞬间挂掉。
另外若要使用内置zookeeper,需要中hbase-env.sh设置:
export HBASE_MANAGES_ZK=true
设置完以后,将配置好的hbase安装包发送到hadoop2、hadoop3:
scp -r hbase/ hadoop2:/usr/local
scp -r hbase/ hadoop3:/usr/local
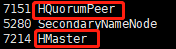
启动HBase检测是否安装成功。
start-hbase.sh
在hadoop1上出现
在hadoop2、hadoop3上出现
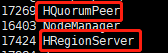
表明启动成功。
在浏览器中输入:hadoop1:16010出现如下界面。

至此,HBase已安装成功。
Hive
Hive是一个基于Hadoop的数据仓库平台。通过Hive,我们可以方便地进行ETL的工作。Hive的数据存放在HDFS中,而元数据需要放在mysql中,因此需要安装mysql数据库。
- mysql安装
首先在三台机器上安装mysql数据库:
apt-get install mysql-server
apt-get install mysql-client
设置数据库可远程访问:
vim /etc/mysql/mysql.conf.d/mysqld.cnf
将bind-address= 127.0.0.1注释掉即可,然后重启数据库。
service mysql restart
- Hive下载与安装
在/usr/local/hive目录下下载Hive安装包并解压:
wget https://mirror.bit.edu.cn/apache/hive/stable-2/apache-hive-2.3.7-bin.tar.gz
tar -xvzf apache-hive-2.3.7-bin.tar.gz
mv apache-hive-2.3.7-bin hive
- 设置环境变量
vim ~/.bashrc
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
source ~/.bashrc
测试一下:
hive version
出现以下界面表示安装成功:

- Hive配置
首先在HDFS中创建hive所用目录:
hadoop fs -mkdir -p /tmp
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
其中/tmp用来存放日志等,/warehouse用来存放数据。
然后下载mysql连接所用的对应jar包到hive目录下:
wget https://mirrors.tuna.tsinghua.edu.cn/mysql/downloads/Connector-J/mysql-connector-java-5.1.48.tar.gz
tar -xvzf mysql-connector-java-5.1.48.tar.gz
mv mysql-connector-java-5.1.48/mysql-connector-java-5.1.48.jar /lib
创建数据库,配置hive用户和权限:
mysql
mysql>create database metastore;
mysql>grant all on metastore.* to hive@'%' identified by 'hive';
mysql>grant all on metastore.* to hive@'localhost' identified by 'hive';
mysql>flush privileges;
然后复制配置文件模板:
mv hive-env.sh.template hive-env.sh
mv hive-exec-log4j2.properties.template hive-exec-log4j2.properties
mv hive-log4j2.properties.template hive-log4j2.properties
mv hive-default.xml.template hive-default.xml
配置hive-env.sh:
vim hive-env.sh
配置JAVA环境和Hadoop环境:
export JAVA_HOME=/usr/local/java/jdk8u252-b09
export HADOOP_HOME=/usr/local/hadoop
然后需要新增一个hive-site.xml文件:
vim hive-site.xml
配置一下mysql的连接,用户名密码等。
<configuration>
<property>
<name>hive.exec.scratchdir</name>
<value>/usr/local/hive/tmp</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/usr/local/hive/warehouse</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/usr/local/hive/log</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/metastore?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
</property>
</configuration>
配置完mysql连接以后,需要在hadoop的core-site.xml中添加两条property:
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
<description>Allow the superuser oozie to impersonate any members of the group group1 and group2 </description>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
<description>The superuser can connect only from host1 and host2 to impersonate a user </description>
</property>
初始化Hive:
schematool -dbType mysql -initSchema hive hive
后台启动Hive:
nohup hiveserver2 &
通过beeline连接hive:
beeline
beeline>!connect jdbc:hive2://localhost:10000 hive hive
出现以下表示hive已安装成功。
Connecting to jdbc:hive2://localhost:10000
Connected to: Apache Hive (version 2.3.7)
Driver: Hive JDBC (version 2.3.7)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://localhost:10000> show databases;
+----------------+
| database_name |
+----------------+
| default |
+----------------+
1 row selected (3.498 seconds)
0: jdbc:hive2://localhost:10000>
至此,基于Hadoop的这套体系的基础环境基本上已搭建完成,不过我们没有搭建zookeeper,而是使用了HBase内置的zookeeper,这是因为我们的环境多用于测试,真正的项目实战中还是尽量使用外置的zookeeper作为协调服务应用程序。后期我们也将会安装外置的zookeeper。之后的博客中,我们将会介绍几个经典的大数据开发实战项目,请大家敬请期待!















 2574
2574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









