







1B(byte字节) = 8 b(bit字/位)
int占4个字节,long占8个,float占8个,double占16个。
res = res * i / j; 不等于 res *= i / j;
一般的写题步骤
1、判断数据范围
2、选择算法
3、分析时间复杂度
4、时间复杂度可行(小于1亿)开始写程序否则重新选择算法。
5、得出答案后,验证一下边界值,看看答案是否正确(第十二届jb的第二题就是边界问题)
高效率输入输出
输入
一旦涉及循环输入、循环输出则要考虑使用高效率输入输出(先分析时间复杂度视情况而定)
循环输入(空着停止输入)
Scanner in = new Scanner(System.in);
while(in.hasNext()){
int n = in.nextInt();
}
import java.io.*;
import java.util.Scanner;
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
Scanner sc = new Scanner(new BufferedReader(new InputStreamReader(System.in)));
StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));//这种输入方式,输入单个整数的效率要比Scanner(System.in)快了将近一倍
//输入多个整数
String[] a1 = br.readLine().split(" ");//读取一行内以空格分隔的两个整数
int n1 = Integer.parseInt(a[0]);
int n2 = Integer.parseInt(a[1]);
int n3 = sc.nextInt();
int n4 = sc.nextInt();
//输入多个字符
char[] a1 = new char[5];
a1 = br.readLine().toCharArray();//获取一行输入并把获取的字符串转为char数组
int a, b;
while(in.nextToken() != StreamTokenizer.TT_EOF) // 表示读到了文件末尾
{
a = (int)in.nval;//in.nval默认输出是double
in.nextToken();
b = (int)in.nval;
}
总结:一寸长,一寸强:StreamTokenizer > BufferedReader > Scanner.
输出
import java.io.*;
PrintWriter pw = new PrintWriter(System.out);
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
//输出整数
int a = 1;
bw.write(a + "");//加""是为了把a转为字符类型,不然无法输出,""里的内容随意
//平时要是输出的数据量不大的话,建议还是使用System.out.print()就够用了,时间大差不差
System.out.print(a);//输出数据量小时比BufferedWriter快一倍
pw.print(a);
复制数组
//一维数组
int[] a = new int[]{1, 2, 3, 4, 5};
int[] b = new int[N];
System.arraycopy(a,0,b,0,N)
b = Arrays.copyOf(a, a.length);
//二维数组
int[][] c = new int[N][N];
int[][] d = new int[N][N];
for(int i = 0; i < N; i ++)
System.arraycopy(c[i],0,d[i],0,N);
for(int i = 0; i < N; i ++)
d[i] = c[i].clone();
技巧
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
br.readLine(); //可以用于抵消一个空行
System.exit(0);//运行此代码会正常退出程序,可以用于调试,找出错误的代码,可以用二分的思想来调试
while循环
int i = 3;
while (i -- > 0){} 的结果是 2,1, 0;这里的运行顺序是,i > 0 --> i - 1 --> 花括号内代码
读入N行连续的数字(就是读入第一行之后,第二行接着第一行后面继续读入)
String[] s = in.readLine().split("\\s+");//"\\s"表示 空格,回车,换行等空白符,"+"表示多个
//split里面必须要写这个,不然测试无法通过,用“ ” 会把空字符读入,虽然也能AC,但测试用例过不了,很迷
重要知识点
时间类题目:月份可以用一个数组来存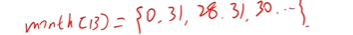
平年闰年如何判断呢?
闰年
1、年份不能被100整除,能被4整除的是闰年
2、年份能被400整除,是闰年
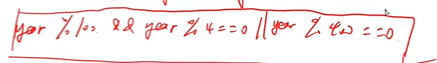
如何把数字翻转过来?
int y = i, x = i;
for (int j = 0; j < 4; j ++ ) {
y = y * 10 + x % 10;
x /= 10;
}
常用的符号优先级要记得 &&、 ||、 ==、 !=

写模拟类型的题目时:一定要考虑到各种各样的情况,以及要自己手动模拟一遍,找找规律,其实任何题目都可以这样
常用距离公式
曼:折线距离,只能沿着横向或纵向走
欧:直线距离,

多行输入时,注意换行符号有可能会被读取,要注意处理换行符号
写题的时候,不要用流程图分析,效率低,尽量用伪代码来写来分析。
Comparable是排序接口;若一个类实现了Comparable接口,就意味着“该类支持排序”。可以使用Arrays.sort()对该类进行排序
Integer.compare(x,y):如果(x == y)则返回0,如果(x <y)则返回-1,如果(x> y),则返回1。
Arrays.fill(int[] arr, int x); //将arr内的每个元素赋值为x,数组初始化
所以判断字符串内容是否相同要用 equals 方法而不能直接用 ==
String s1 = "qwe";
String s2 = "qwe";
s1 == s2 // true
String s1 = new String("qwe");
String s2 = new String("qwe");
s1 == s2 // false
从1开始的算法
前缀和
C++的 pair<int, int>的 java版
class PIIs implements Comparable<PIIs>
{
public int t;
public int id;
public PIIs(int t,int id)
{
this.t = t;
this.id = id;
}
@Override
public int compareTo(PIIs o) {
// TODO 自动生成的方法存根
return Integer.compare(t, o.t);
}
}
//初始化
static PIIs[] b = new PIIs[N];
b[i] = new PIIs(t, id);

宽搜:
每次取出队头元素,将扩展出的所有元素放到队尾

宽搜模板
1、判断数组,st[] 入队时判重(判重有两种、入队判重、出队判重(少用))
2、queue队列,
框架

题目里遇到的深搜和宽搜的状态一般有两种
1、每一个格子是一个状态,从当前状态扩展到其他状态(蓝桥杯常用)
2、给一个比较小的矩阵,整个是一个状态,然后枚举会变成什么状态,
就是从一个矩阵变成另一个矩阵,把整体当做一个状态,
bfs 与dfs 的一些不同的点:
bfs 可以找到最小的步数
dfs 只可以找到某一条路径
字符型在判断时使用单引号’#’
树的直径
具体例子:

距离x最远的是y点,然后再求离y点最远的点,也就是z点,yz就是树的直径
图的存储方式:
1、邻接矩阵,适合稠密图,点数不是很多的图
2、邻接表vect、单链表

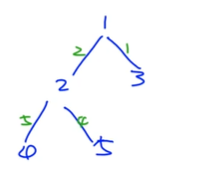
存一下每个点能到达哪些点,对于每一个点开一个vector,每一个点存一个结构体,

vocter的从长度的数量,就是边的2倍
可以看一下
浪费了1个多小时才找到的bug
当 n 需要全局使用的时候,千万不能用while ( n – > 0) 来循环,因为循环完之后,n 会变成0,后面调用n的时候,n就是0,会导致后面的循环无法执行,第一次循环可以使用for,不会改变n的值
用数组来模拟单链表(用的最多的是邻接表:n个链表组成,用处:存储图和树)与双链接表(优化某些问题)
为什么不使用class类来模拟呢?
因为每次都需要new一次创建节点,会非常慢
单链表
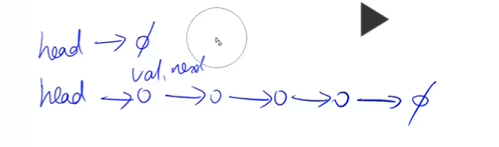
头节点:head,最开始指向一个空节点
插入一些元素后,如上面的截图所示
每个节点都会存一个value和一个下一个节点的地址(next指针)
可以用e[N]某个节点的值,ne[N]保存某个节点的next的指针,那么这两个如何关联起来呢?
是使用下标关联起来的:例如
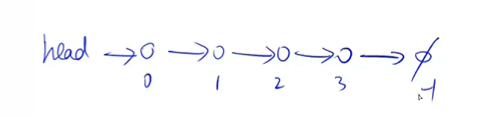

如何把节点插入到链表内

贪心问题
很多贪心算法题的数据范围都是105,凡是105的贪心问题的都是排序问题(O(nlogn))
106~107的贪心一般都是扫描一遍(O(n))
1000的贪心一般时间复杂度都是(O(n2)),一般为两层循环
100的贪心三层循环(O(n3))
最大值最小值常数(巨坑)
Integer.MIN_VALUE 是一个负整数
Double.MIN_VALUE 是0


分解质因数
补充一个知识点:因数等于约数,一个整数的最大公约数是它本身
筛法求质数:线性筛法
代码模板
public class Main {
static final int N = 1000010;
static int[] primes = new int[N]; //存所有的质数
static int cnt; // 质数的数量
static boolean[] st = new boolean[N]; // 是否被筛过
static void get_primes(int n){ // O(n)
for (int i = 2; i <= n; i ++ ) {
if (!st[i]) primes[cnt ++ ] = i;
for (int j = 0; primes[j] * i <= n; j ++ ) {
st[primes[j] * i] = true;
if (i % primes[j] == 0) break;
}
}
}
public static void main(String[] args) {
get_primes(100000);
for (int i = 0; i < 20; i ++ ) System.out.println(primes[i]);
}
}















 222
222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









