







在日常办公中,员工经常需要从PDF文件中提取表格数据。手动进行OCR识别、表格提取、重命名和导出操作繁琐且容易疲劳。例如,行政人员处理办公用品采购清单PDF时,每次都要重复这些步骤,自动化工具可大大节省时间。
以下是使用 Python 和飞桨实现扫描 PDF 文档自定义指定多个识别区域,识别固定位置的文字并导出到 Excel 的详细步骤及开发教程:
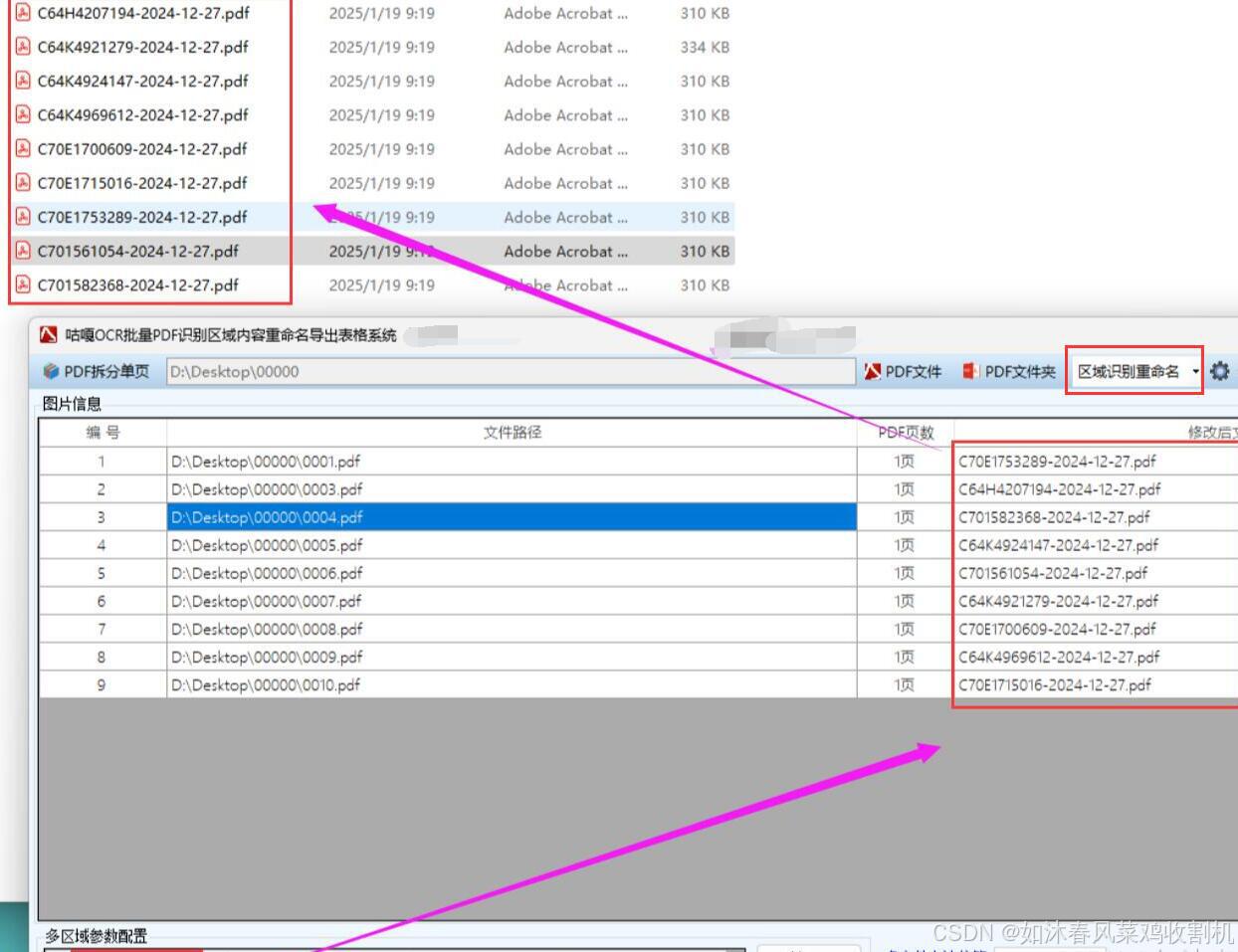
一、开发思路
- 使用
pdf2image将 PDF 文档转换为图像,以便进行 OCR 识别。 - 使用飞桨的
PaddleOCR进行文字识别。 - 使用
openpyxl库将识别结果存储到 Excel 文件中。 - 开发一个简单的用户界面(可选),方便用户输入 PDF 路径、指定识别区域等信息。
二、环境搭建
首先,确保你已经安装了所需的 Python 库:
pip install paddlepaddle paddleocr pdf2image openpyxl
三、具体实现步骤
1. PDF 转图像
from pdf2image import convert_from_path
def pdf_to_image(pdf_path, output_folder):
images = convert_from_path(pdf_path)
image_paths = []
for i, image in enumerate(images):
image_path = os.path.join(output_folder, f"page_{i}.jpg")
image.save(image_path, 'JPEG')
image_paths.append(image_path)
return image_paths
代码解释:
convert_from_path函数将 PDF 文档转换为图像列表。- 遍历图像列表,将每个图像以
page_<页码>.jpg的格式保存到指定的输出文件夹,并将生成的图像路径存储在image_paths列表中。
2. 图像区域文字识别
from paddleocr import PaddleOCR
def ocr_image(image_path, regions):
ocr = PaddleOCR()
results = []
for left, top, right, bottom in regions:
image = cv2.imread(image_path)
cropped_image = image[top:bottom, left:right]
ocr_result = ocr.ocr(cropped_image)
if ocr_result:
t 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









