










数据优化——分库分表(一)概念及运用场景-详解
数据优化——分库分表(三)中间件讲解
数据优化——分库分表(四)高级策略
1 range
- 自增ID,根据ID范围进行分表(左闭右开)
- 比如1~1000000是table1;
- 1000001~2000000是table2;
- 2000001~3000000table3;
优点:
- id是⾃增⻓,可以⽆限增⻓
- 扩容不⽤迁移数据,容易理解和维护
缺点:
- ⼤部分读和写都访会问新的数据,有IO瓶颈,整体资源利⽤率低。
- 数据倾斜严重,热点数据过于集中,部分节点有瓶颈
比如:做一个用户数据,用户肯定是越新越活跃,一般来说老用户的活跃程度没有新用户的高,所以按上面的分库分表方法的话会导致后面的库表压力大,前面的库表压力小,造成缺点的产生。
适合: 日活流水记录(需要新旧数据整合)
1.1 拓展-range延伸
按上面的来看,感觉range策略很鸡肋的样子,其实也不然,因为没有万能的策略,只有适合的策略。通过上面可以看出range其实是一个一定范围内的划分(看单词含义就应该知道)。而这个范围不应该限定于数字之间,可以把它延伸扩展。例如:
- 时间 年、⽉、⽇范围,比如按照⽉份⽣成 库或表 pay_log_2022_01、pay_log_2022_02
- 空间 地理位置:省份、区域(华东、华北、华南)⽐如按照 省份 ⽣成 库或表
思考1 :为什么按地域分的时候多按(华东、华北、华南)而不是直接按省份建表建库?
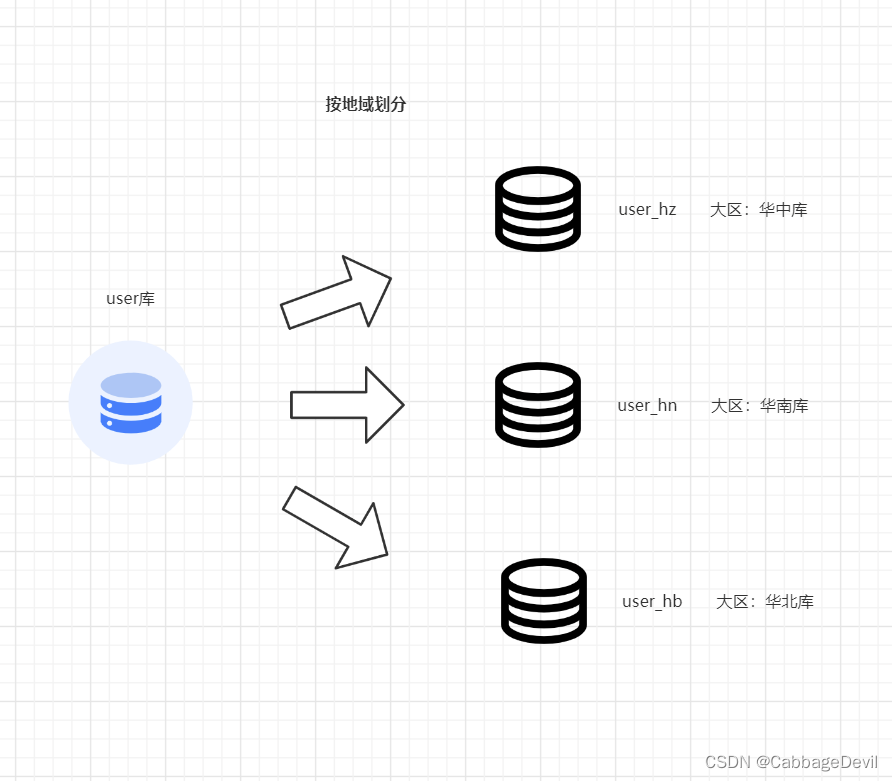
答案1:如果是按省份建表建库也会导致上面说的“有IO瓶颈,整体资源利⽤率低”等问题,因为省份之间的数据量是不一样的,拿广西跟北上广比,从用户使用频率到使用量基本是有倍数上的差距,如果广西一个库,上海一个库,那就会导致广西的库性能过剩,上海的库性能告急。所以按地域划分,可以均匀些,把各大冷热数据均摊,提高机器的使用率。比如扩大到世界范围时候,也不会按各大洲各大国去划分,而是按经纬度去划分,为了也是混合数据,提高机器的负荷率。
2 hash取模(Hash分库分表是最普遍的方案)
思考2:为什么不直接取模?而是要先Hash呢?
回答2:因为有时候你用来分库分表的字段不一定是整数类型,所以先Hash可以提高规则的适配度,总之,统一规则即可。
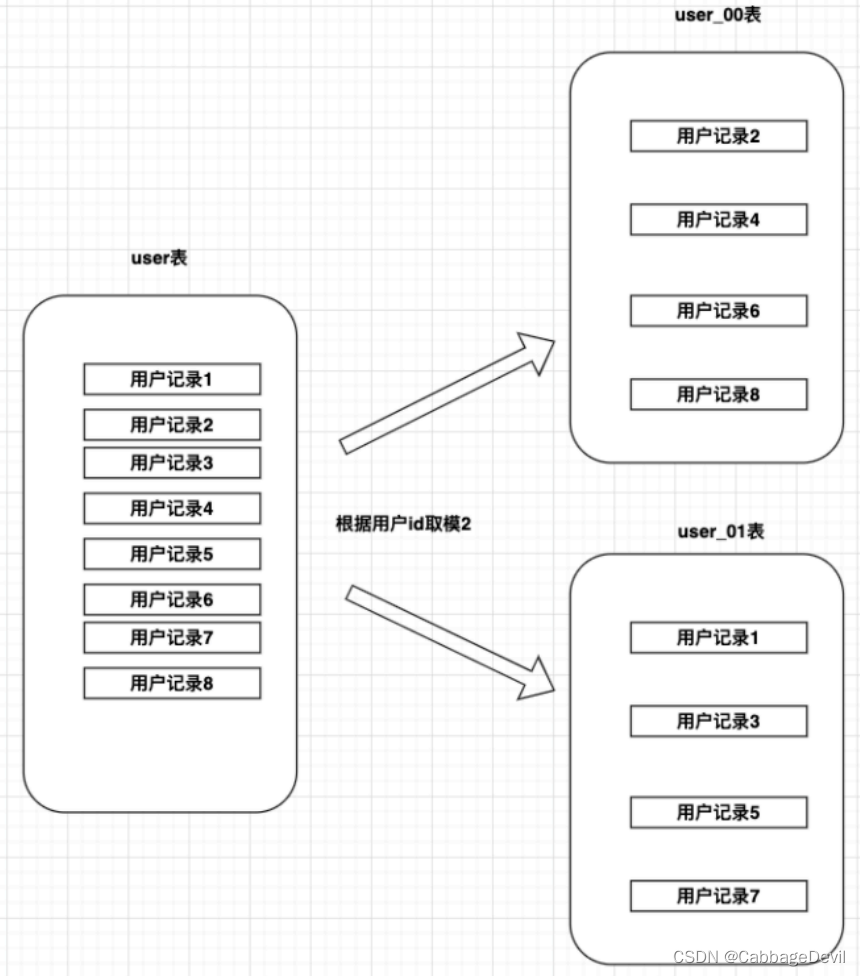
例子:
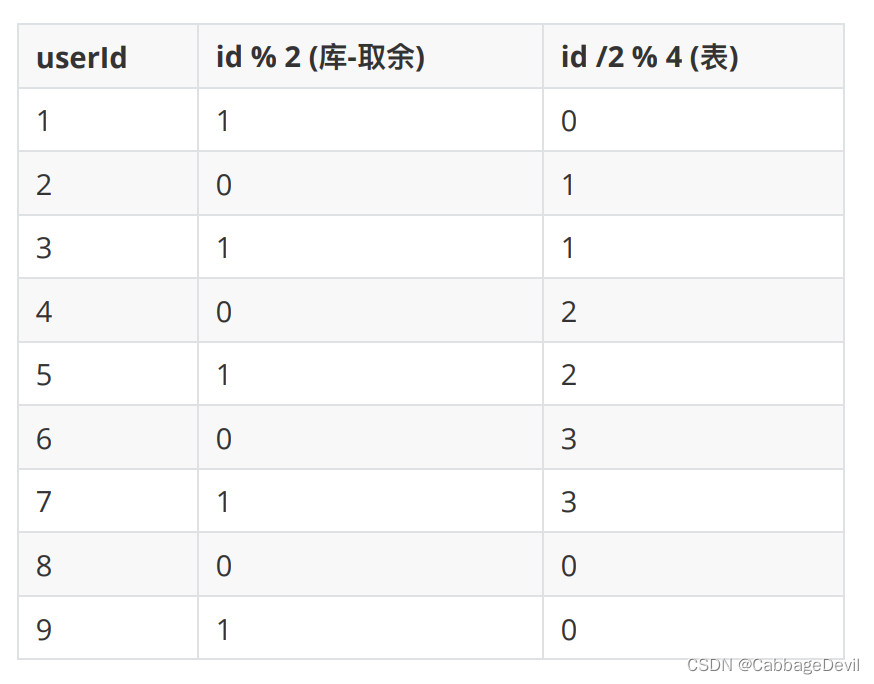
⽤户ID是整数型的,要分2库,每个库表数量4张表,⼀共8张表,⽤户ID取模后,值是0到7的要平均分配到每张表
一般规则:
库ID = userId % 库数量 2
表ID = userId / 库数量 2 % 表数量 4
PS:如果你发现某些表的数据量不够,说明你的规则发生了问题,在建表后应该先数据量的测试判断自己的策略无误再使用。
优点:
- 保证数据较均匀的分散落在不同的库、表中,可以有效的避免热点数据集中问题
缺点:
- 扩容不是很⽅便,需要数据迁移














 91
91











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









