










数据优化——分库分表(一)概念及运用场景-详解
数据优化——分库分表(二)策略讲解
数据优化——分库分表(三)中间件讲解
1 什么是高级策略
在数据优化——分库分表(二)策略讲解中我们已经讲解了一些基础的策略去实行分库分表。虽然他们是可行的,但是也蕴藏着一些问题。而在基础略之上可以解决此类问题的,我称呼为高级策略,那我们先来总结一下问题所在。
- 数据是源能源不断的,所以数据库需要扩容,而基础策略扩容难
- 多维度查询难。如聚合查询,条件查询等。
2 扩容问题
如果是按照基础策略,我们扩容的时候需要数据迁移,虽然我们设计基础策略的时候取模可以让迁移的成本降低,但是这个数据迁移的过程会影响到业务,我们需要的是程序不下线的动态扩容。
缺点:
- 不能动态扩容
- 如果提前预建库表,第一提高了项目的建立预算,第二如果达不到预估量浪费资源
2.1 在路由key中添加库表位
我们以订单号举例
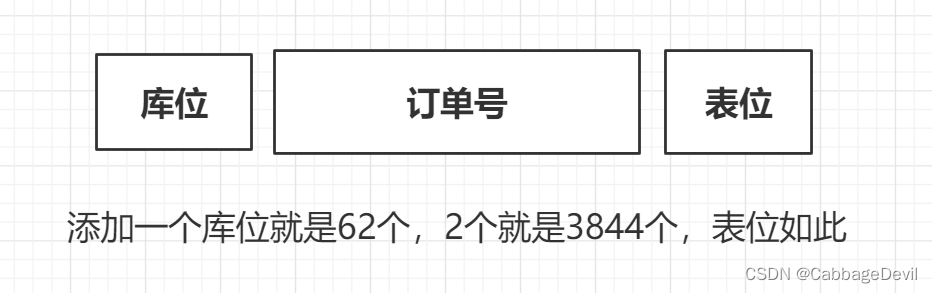
通过添加库位和表位来路由的方式,这样就可以动态扩容了。当然,我们简单的做可以把库位表位添加在头尾,这样方便我们获取,但是为了防止别人知道我们的规则,我们也可以藏在订单号中。
例如: 我现有的库位A/B,表位0/1/2,那我就有6个表,单表1000W就可以容纳6000W的数据,现在我数据量到了1E。我们可以添加C/D两个库位来提升到1.2E的数据容纳量,也可以通过添加表位3/4/5,来满足需要。这样我们就实现了动态的扩容。
当然了,还有一些免迁移的动态扩容设计方式,就是我们之前说过的range策略 ,但是这种策略也有一定的问题,我们在数据优化——分库分表(二)策略讲解也提到过,所以需要选择符合自己业务的策略。
2.2 库表位带来的问题(面试题)
添加库表后还是会带来问题,因为我们的数据没有经过迁移,旧的库表基本接近饱和,而新建的库表则空虚,如果还是按之前的随机方式方式肯定不行的。
对策:
我们可以效仿Nginx给数据库做加权,也就是weight 权重配置。当然weight 的方式有很多
- 库表位可以使用对象形式,配置权重,避免数据倾斜、数据集中(普通)
- 编写算法,根据不同的,配置权重,不同的库表位配置不同的权重(复杂)
- 配置库表为的时候我们可能是以配置项的方式配置,在配置的时候多写几个重复值,增加难度,比如{A,B,C,C,D,D,D}这样我们随机到C和D的概率肯定会大于A和B(简单快捷)
3 查询问题
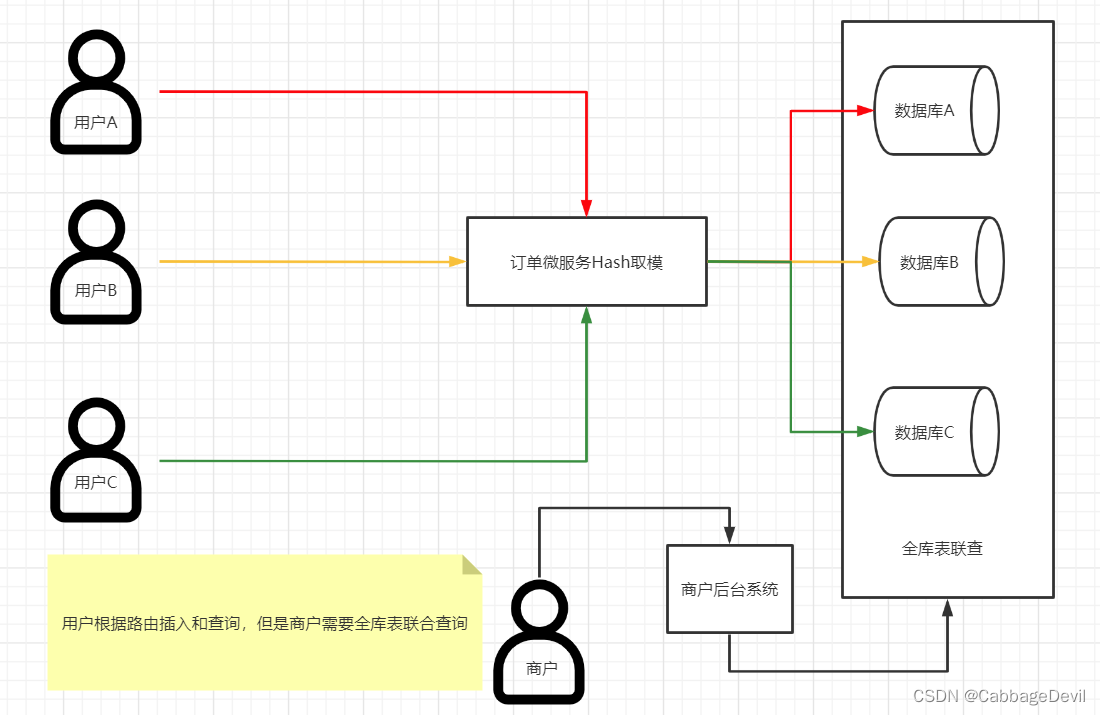
我们还是以订单为例,我们要查询订单的时候,用户是可以通过库表位+自己的ID定位到指定的库表,哪怕是列表查询,也是不需要全库表联查的,这样提高了效率。但是我们以商家的维度查询订单的时候是没有这些条件的,只能全库表联查,那就发生了分库分表很常见的join问题。这样大大降低了性能效率。
这个也是行业内分库分表的痛点,除了我们说的电商行业还有很多行业也有类似痛点
比如:
- 人事领域,招聘信息按面试人uesrId分库分表后,需要查询所有人的面试信息
- 大数据,用户的操作按userId分库分表后,需要集合所有用户画像进行算法总结
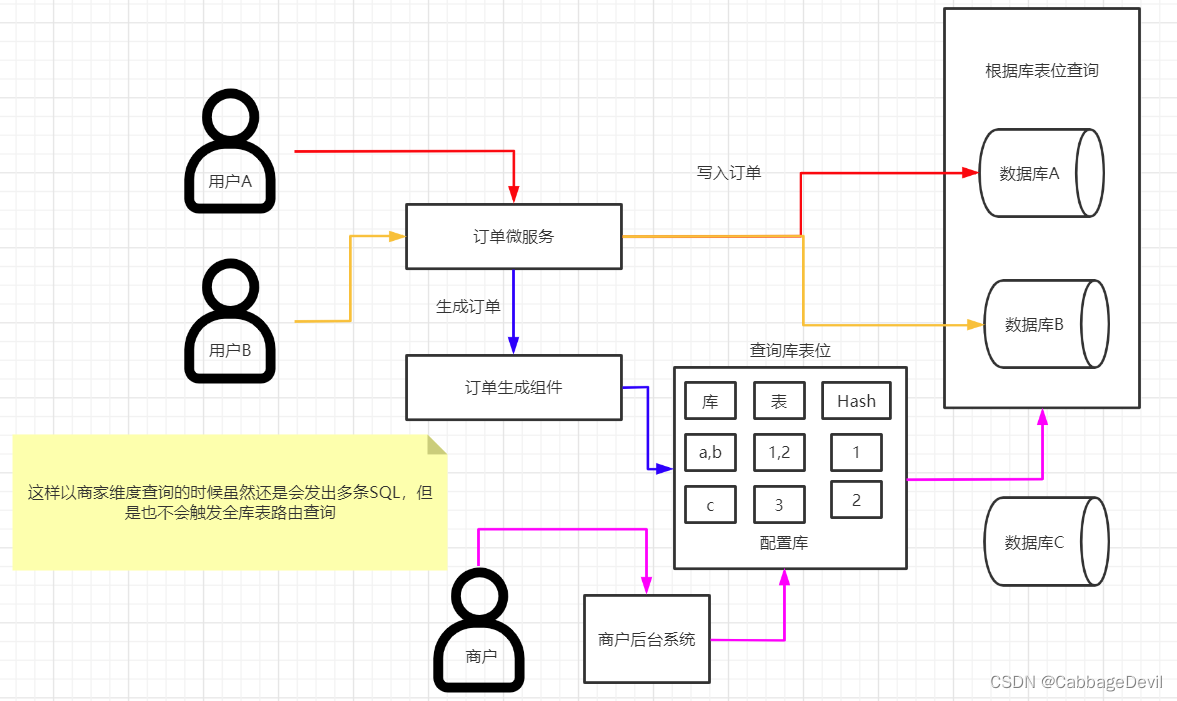
3.1 字段解析配置
在上面的结构上加入字段的解析,建一个表,存储订单对应的库表位,商家生成的订单号固定前缀或者后缀。说白了就是订单号里包含商家的信息。
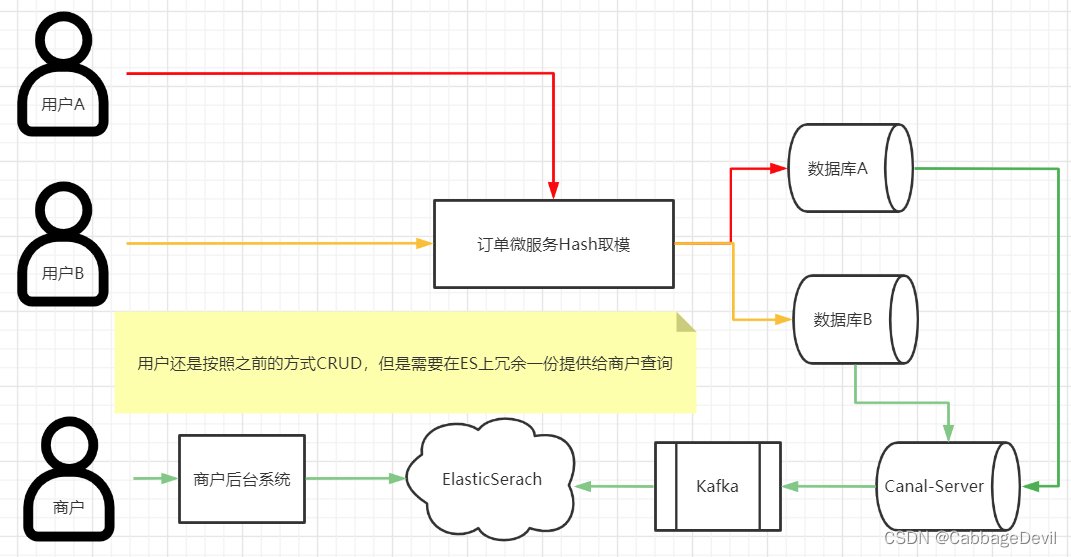
3.2 NoSQL方案
ES的能力在这里就不做过多介绍了,加入了MQ是为了削峰。
3.3 双写冗余
当然拉,这种方法最吃钱了,因为数据库的数据量翻倍了,数据库的预算也是要增加的,但是由于C端跟B端的并发量不同,如果C端的表容纳1000W数据,那B端的表可以收容2-3千万的数据,没必要按C端的数据库配置一比一翻倍,这样节省一点成本。
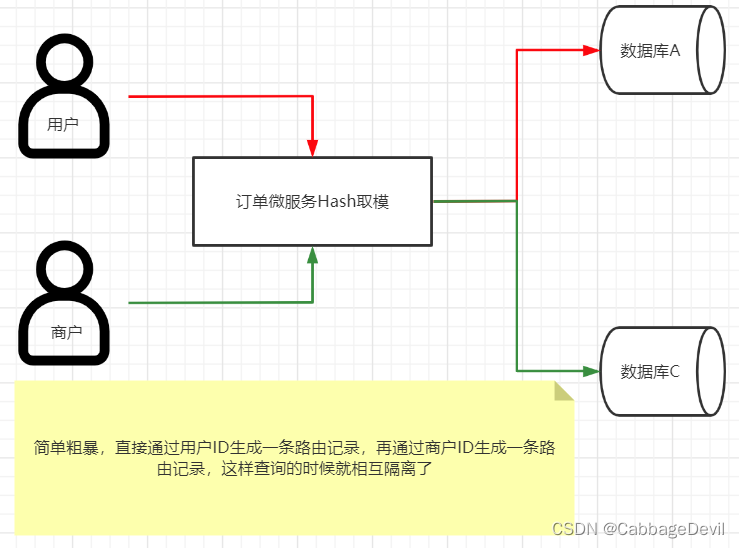
但是这样做就需要做分布式事务,分布式事务可以使用Seata分布式事务框架,Seata支持下面三种模式。
- AT:隔离性好和低改造成本, 但性能低
- TCC:性能和隔离性,但改造成本大
- Saga:性能和低改造成本,但隔离性不好
上面的方式对于高并发不是很友好,如果业务可以妥协,那还有支持高并发的MQ版本一致性解决方案。通过MQ的ACK来做事务确认,一般来说项目正常是不会出现错误的,但是如果还是遇到死信,那就人工介入即可。这里我也不过多介绍,又需要的请自行查阅。














 1546
1546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









