







在云计算方面,Salesforce 可以称为业界的领袖,它不仅在产品方面比较成熟,而且在思维方面也是引领潮流的,特别是在SaaS(Software as a Service,软件即服务)和PaaS(Platform as a Service,平台即服务)这个两个领域内。
![]()
图1. Salesforce 商标(图源自Salesforce.com)
首先,简要地介绍一下Salesforce的历史:Salesforce.com在1999年由前甲骨文高管 Marc Benioff 创立,他创办Salesforce的核心理念就是"No Software(消灭软件)",但是其意义并不是排斥所有的软件,而是主要排斥运行在企业数据中心的软件(On-Premise Software),也就是希望让用户能直接通过互联网来诸如CRM等软件服务,并同时让用户无需自己搭建和维护软件所需的硬件和系统等资源。Salesforce的主要产品包括Sales Cloud(CRM)、Service Cloud、Chatter和Force.com等。下面是它的主要发展史:
- 1999年,Salesforce在美国旧金山成立。
- 2001年,推出了第一款SaaS应用CRM,同时也受到众多厂商和客户的热议。
- 2004年,Sunguard成为Salesforce第1000位用户。
- 2005年,推出了名为"AppExchange"的程序商店,以丰富用户选择。
- 2006年,推出了首个运行在云计算平台的语言Apex,并在语法上类似Java。
- 2007年,推出了它的PaaS平台Force.com,来让用户更方便地在Saleforce平台上开发在线应用,同时Salesforce凭借Force.com得到了华尔街日报的科技创新奖(Technology Innovation Award)。
- 2009年,Salesforce成为首家年收入达到10亿美元的云计算公司,并在年初推出了名为"Service Cloud"在线客户服务应用。
- 2010年,Salesforce将推出名为"Chatter"的企业级在线SNS服务,类似于企业内部的"LinkedIn",同时其CRM应用已更名为"Sales Cloud"。
Salesforce的整体架构
虽然Salesforce这些产品从表面而言有所不同,但是从全局而言,它们却是一个整体,具体可看下图:
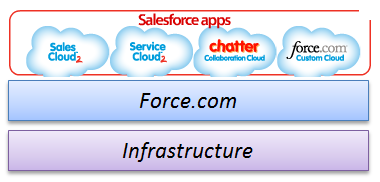
图2. Salesforce的整体架构 (图部分源自Salesforce.com)
从这张Salesforce的整体架构图可以看成,Force.com 是 Salesforce 整体架构的核心,因为它首先整合和控制了底层的物理的基础设施,接着给上层的Sales Cloud,Service Cloud,Chatter和基于Force.com的定制应用提供PaaS服务,最后,那些Force.com上层的应用以SaaS形式供用户使用。这样做的好处主要有两方面:其一是关于成本的,因为通过这个统一的架构能极大地整合多种应用,从而降低了在基础设施方面的投入。其二是在软件架构方面,因为使用这个统一的架构,使得所有上层的SaaS服务都依赖Force.com的API,这样将有效地确保API的稳定性并避免了重复,从而方便了用户和Saelsforce在这个平台上开发应用。
虽然Salesforce的"Sales Cloud"等SaaS应用也比较经典,但由于Force.com堪称整个架构的核心,同时也是最值得的学习和借鉴的部分,所以本系列接下来将会把重点对准Force.com。
Force.com
Force.com是Salesforce在2007推出的PaaS平台,并且已经有超过47000位企业已经使用了这个平台。Force.com基于多租户的架构,其主要通过提供完善的开发环境等功能来帮助企业和第三方供应商交付健壮的,可靠的和可伸缩的在线应用。

图1. Force.com 商标(图源自参[3])
总体而言,Force.com主要有五方面功能:
- 强大的定制功能:在Force.com,不仅UI能够定制,而且诸如Workflow和表格等也能被定制。
- 提供完善的开发环境:首先,通过Visualforce能方便地使用"Drag & Drop"的方式来设计页面。其次,Salesforce提供基于Eclipse的IDE来快速地开发应用。最后,Salesforce还提供Sandbox来方便用户测试。
- 支持复杂的事务和流程:通过Force.com专属的APEX语言,能方便地设计和开发复杂的事务和流程。
- 优秀的整合功能:用户除了可以在AppExchange购买其所需的功能和应用,而且还可以通过Force.com的Web Service接口来和其他应用整合,比如SAP等。
- 久经考验的基础设施:由于Salesforce除了通过在多个大洲建有数据中心来应对灾难的发生,而且在可用性和安全性等方面也有一定积累,所以在Salesforce能长时间地支持众多服务的正常运行。
概念
虽然对我们而言,多租户(Multitenancy)可以算是一个非常新颖的概念,但是其实这个概念已经由来已久了。简单而言,多租户指得就是一个单独的软件实例可以为多个组织服务。一个支持多租户的软件需要在设计上能对它的数据和配置信息进行虚拟分区,从而使得每个使用这个软件的组织能使用到一个单独的虚拟实例,并且可以对这个虚拟实例进行定制化。但是要让一个软件支持多租户并非易事,因为不仅对它的软件架构进行相应的修改,而且需要对它的数据库结构进行特殊的设计,同时在安全和隔离性方面也要有所保障。
还有,为了帮助大家进一步理解多租户这个概念,特别选取两个和多租户比较接近的概念来进行进一步的辨析。
多租户和多用户的区别
多用户的关键点在于不同的用户拥有不同的访问权限,但是多个用户共享同一个的实例。而在多租户中,多个组织使用的实例各不相同。
多租户和虚拟化的区别
多租户和虚拟化在概念是比较类似,都是给每个用户一个虚拟的实例,并且都支持定制化,但是它们作用的层次不同:虚拟化主要是虚拟出一个操作系统的实例,而多租户则是主要虚拟出一个应用的实例。
优缺点
多租户的优点:
- 经济:因为通过一个软件实例被多个组织共享,从而减低了整体资源的消耗,也同时减低应用运行的成本和相应的管理开支。
- 易于更新和开发:因为所有组织都共享同一套核心代码,所以能够让软件更新和开发更简单。
- 管理方便:首先,通过使用了多租户架构能减少物理资源和软件资源,这将简化管理。其次。由于多租户软件主要由有经验的云供应商运营,所以能依赖那些非常经验的管理人员来提升效率。
多租户的缺点:
- 更复杂:由于一个软件需要做出极大地修改,才能支持多租户架构,而且这种修改,往往会增加整个软件在架构方面的复杂性。
- 不够安全:因为众多组织的应用和数据共享同一套软件和基础设施,如果出现机器宕机,软件出现问题或者大规模的数据被暴露等情况,将会造成更严重的后果,因为影响面更大。
几种模型
在现有的实现中,主要有三种常见的模型,而且区别主要在于采用不同的数据库模式(Database Schema):
- 私有表(图1-a):它是最简单的扩展模式,就是为每个租户的自定义数据创建一个新表。优点是简单。缺点是涉及到高成本的DDL操作,并且它的整合度不高。
- 扩展表(图1-b):总体而言,比较类似于私有表,但是一个扩展表会被多个租户共享,所以无论是共享表还是基本表都会有租户栏位。好处是比私有表更高的整合度和更少的DDL操作,但是在架构上比私有表更复杂。
- 通用表(图1-c): 主要通过一个通用表来存放所有自定义信息,里面有租户栏位和许许多多统一的数据栏位(比如500个)。像这种统一的数据栏位会使用非常灵活的格式让转储各种类型的数据,比如VARCHAR。由于在每一行中的数据栏位都会以一个Key一个Value形式存放所有自定义数据,导致通用表的行都会很宽,而且会出现很多空值,所以通用表这种方式也被称为"Sparse Column"。好处是极高的整合度并避免了DDL操作,但是在处理数据方面难度加大。
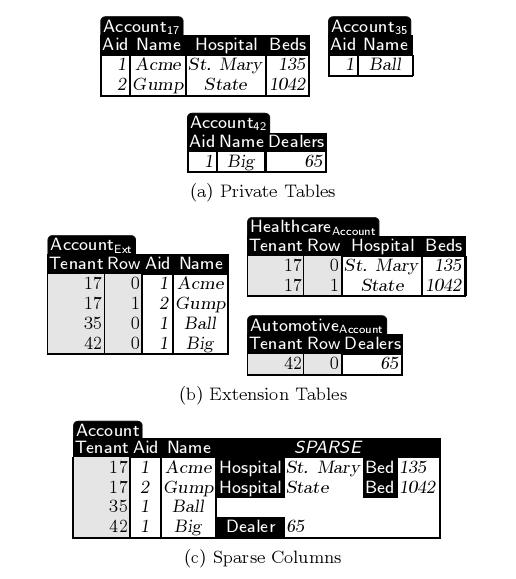
图1. 多种模式(图源自参[7])
差异与取舍
| 模型 | 机制 | 优点 | 缺点 |
| 私有表 | 为每个租户的自定义数据创建一个新表 | 简单 | 需要DDL操作,低整合度 |
| 扩展表 | 一个扩展表会被多个租户共享 | 高整合度,少DDL操作 | 有点复杂 |
| 通用表 | 通过一个通用表来存放所有自定义信息 | 极高整合度,无DDL操作 | 实现难度高 |
在实战中,具体选择那个模型,主要还是看那个模型更适合。
关于多租户的介绍已经基本结束了,下一篇将详细介绍Force.com的多租户架构。
由于Force.com所负载的应用不论是在定制方面的灵活性上,还是所承受的负载上,对基于多租户的架构而言,都是史无前例的,导致之前提到的一些模型或者改动已经无法满足要求了,所以Salesforce在Force.com引入了通过Metadata(元数据)驱动的多租户架构来动态生成快速的,可伸缩的和可定制的应用。接下来,将一步步为大家揭开Force.com多租户架构的神秘面纱,首先是它的总体架构。
总体架构
在介绍Force.com的整个架构之前,请看下图,此图是根据Salesforce首席架构师Craig Weissman在2009年旧金山QCon大会上的演讲总结而成。
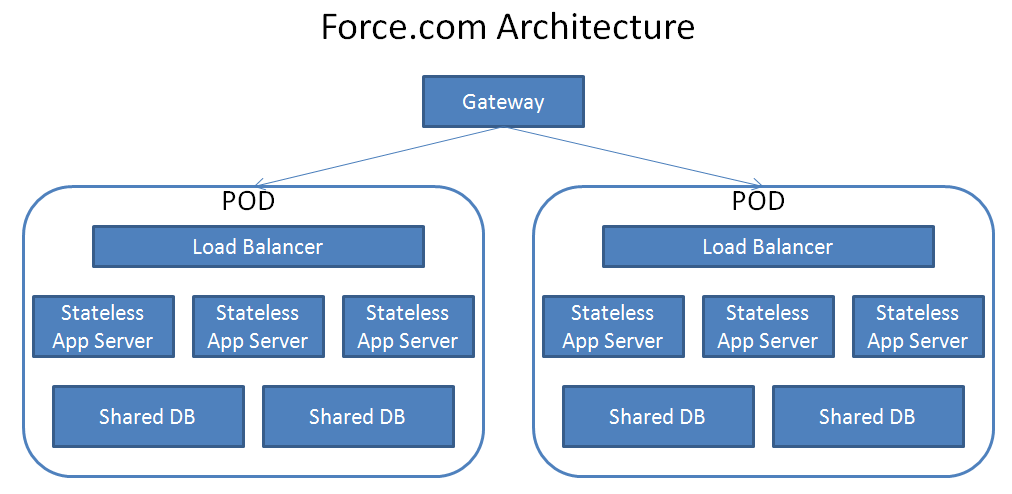
图1. Force.com的架构图
首先,在最前面是Gateway(网关),网关将接受所有访问Force.com的请求,无论它是访问Sales Cloud,还是关于第三方定制程序的。接下来,网关会根据这个请求所属的租户把请求转发给对应的POD,什么是POD?简单的来说,POD就是一组集群服务器,每个POD都运行同一套Force.com系统,而且每个POD支持成千上万个租户,Salesforce总共有10多个POD来支撑它所有服务的运营,并把所有租户平衡地分配给每个POD,而且主要通过建立新的POD来支撑新的租户。当POD收到请求之后,POD会先通过其内置的Load Balancer(负载均衡器)来将请求转发给负载略轻的App Server(应用服务器),由于为了简化架构和方便伸缩(Scale),所以应用服务器是Stateless(无状态),而且在一个POD内会有多个应用服务器以应对大规模的请求。最后,当应用服务器在处理请求的时候,如果发现请求所需的数据没有被Cache住的话,应用服务器会调用这个租户所属的Shared DB(共享数据库)来取得相关数据,虽然共享数据库是使用成熟的Oracle数据库产品,但是在数据库表的设计上面为多租户做了很多地优化。
接下来,将介绍Force.com是如何通过Metadata来动态生成和定制应用的。
Metadata驱动
首先,Force.com的Metadata是基于大家非常熟悉的面向对象的概念,所以也可以把Metadata认为是对象,也就是说Force.com是由一个个对象组装而成,而且Force.com中的对象可以是表格,也可以是UI,甚至可以是用户权益等。一个Force.com的对象和这个对象下面的字段可以对应一个数据库的表和这个表的列,而且Force.com对象之间的关系(relationship)在功能上类似于数据库的引用完整性約束(referential integrity constraint),但与数据库中每个数据库表对应于独立的存储地址不同的是,Force.com使用几个共享的大数据库表来作为堆存储(heap storage)来放置所有对象,另外这些存储Metadata的表也被称为"UDD(Universal Data Dictionary)"。
接着,是关于应用的,一个在Force.com上运行的应用实例是通过组合许许多多个对象来生成的,也可以说一个应用实例是使用Metadata来描述的,比如,在应用初始的时候,每个客户都是使用同一个版本和同样规模的对象,而且用户通过添加和更新对象来定制应用,比如增加新的UI和字段等,同时系统会对共享的和定制的对象进行严格地分离,使得既能非常方便地更新共享代码,也能保证某个用户定制过的部分不影响到其他用户。在实现上,Force.com并没有实际地为一个新对象生成一个数据库表,而且以元数据的形式存储在几张大表中,并在运行时候,Force.com会有一套引擎来通过分析数据库中的Metadata来动态生成一个虚拟应用实例和这个应用所需的模块(Virtual Application Componets),比如公共UI(Common Application Screen),定制UI(Tenant-Specific Screen)和其他对象等。
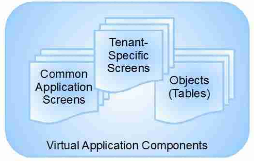
图2. 虚拟应用模块图(源自参[1])
还有,虽然Metadata驱动这种和Java很类似的动态生成机制在速度上有天生缺陷,但是Force.com也内置与Sun的Hotspot技术有异曲同工之妙的Metadata Cache来加速常用Metadata的读取。
下面,将分别介绍Force.com的两大组成部分:应用服务器和共享数据库。
应用服务器
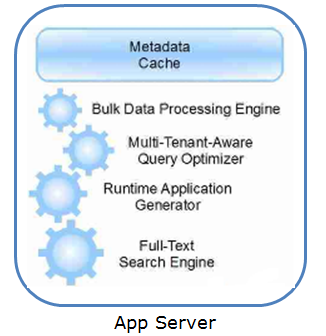
应用服务器主要包括五大核心模块:
- Metadata Cache:用于存放那些最近用到的和比较常用的Metadata来加速应用的生成。
- 大规模数据处理引擎:主要用来加速处理大量的数据读写和在线事务。
- 多租户感知的查询优化引擎:这个引擎将通过维护多租户的信息来帮助Oracle自带的基于成本的查询优化器更好地适应多租户环境。
- 运行时应用生成器:这个生成器主要根据用户的请求来动态生成应用,并且利用上面提到的查询优化引擎来提升效率。
- 全文检索引擎:在数据库对数据进行更新的同时,这个引擎会异步更新这个数据的相关索引。
共享数据库
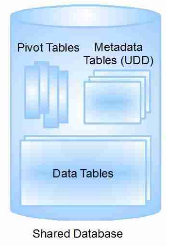
图1. Force.com的架构(图源自参[1])
整个共享数据库主要有三种类型的数据库表:
- Metadata表:主要存放用户定制的对象和对象所包含的字段的结构信息,也被称为"UDD"。
- 数据表:主要存储那些用户定制的对象和对象所包含的字段的数据。
- Pivot表:用来维护那些用于检索(indexing),唯一性和关系等denormalized (去规范化)数据以优化系统的效率。
还有,在物理层面,数据库里面所有表格,包括底下的索引,都根据每个租户不同的租户ID(OrgID)来使用Oracle的Hash分区技术进行分区。通过Hash分区这种久经考验的技术能够将大规模的数据平均地分割成多个更小的和更容易管理的分块,从而帮助大数据库系统能够在多租户的环境下提升速度,伸缩性和可用性等。
本篇结束,下篇将主要对应用服务器内部的一些模块(比如查询优化引擎,外部全文检索引擎等)和数据库表的设计进行详细的描述。
大规模数据处理引擎
由于Force.com需要处理的数据量不论是来自网页端,还是来自Web Service端都是非常巨大的,所以Salesforce在Force.com中引入了特制的大规模数据处理引擎来处理大量的数据读写和在线事务。它主要有两大特点:其一是对大规模数据处理进行了优化,特别是当一个API调用发来很多待处理的数据时,这个引擎能非常快速地处理。其二是这个引擎内置错误恢复机制,当处理大规模数据时候,假如其中一个步骤发生错误时,这个引擎会捕捉和修复这个错误,并且保持这个步骤之前正确的结果以避免整个重做。
多租户感知的查询优化引擎
大多数现在数据库都自带基于成本的查询优化器,这种优化器主要是基于数据库表和索引数据等相关数值来进行计算和比较。但是由于传统的基于成本的优化器都是主要为单租户的环境设计的,所以他们并不能很好地适应多租户的环境,因为在数据库中是没有多租户这个概念。为了让优化器能够在多租户环境下良好工作,Salesforce在Oracle自带优化器的基础上搭建了一个多租户感知的查询优化引擎,它也主要有两个特点:其一是这个引擎为每个多租户对象维护了一整套便于优化的数据(租户层的,组层的和用户层的)。其二是这个引擎也维护租户和租户下面用户的安全信息,这样不仅能提升了效率,因为能避免将那些不属于这个租户的数据加入到计算,而且能提升数据的安全性。
全文检索引擎
全文检索功能对Web应用而言,基本可以算是一种基本功能,而对基于Force.com的应用而言,同样如此,Force.com为此内置一个全文检索引擎,其是基于大名鼎鼎的Lucene技术。当一个运行在Force.com平台上的应用对数据库中数据进行更新的时候,会有一组称为检索服务器的后台进程来异步更新数据相关的索引。通过这种异步机制不仅能够保证检索工作不影响处理事务的效率,而且同时也能让用户使用到最新的搜索结果。为了优化这个检索流程,系统会同步将修改过的数据复制到一个内部"等待检索"的表,之后检索服务器会访问这个表来进行检索,这样好处是减少了检索服务器的I/O处理量。而且为了更好地适应多租户环境,检索引擎自动为每个租户维护一个独立的索引。
数据库表的设计
下图为Force.com的数据库表结构:
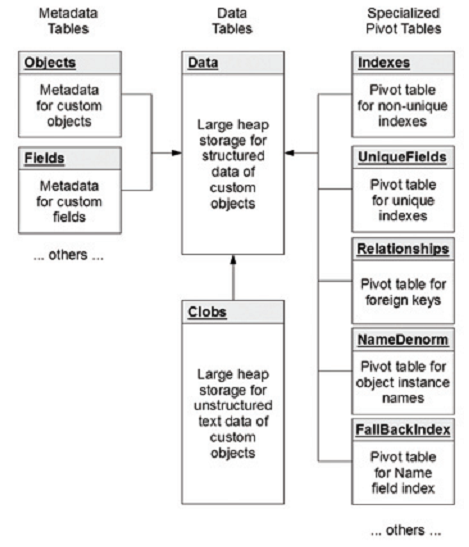
图1. 数据库表的结构(图源自参[4])
Metadata表
Metadata表的作用是存储用户定制的对象和对象所包含的字段的结构信息,不保存具体的数据,主要有两大类:
- Object Metadata表:这个表主要存储对象的信息,其中主要字段包括对象的ID(ObjID),拥有这个对象的租户的ID(OrgID)和这个对象的名字(ObjName)。
- Field Metadata表:这个表主要存储对象附带字段的信息,其中主要字段包括字段的ID(FieldID),拥有这个字段的租户的ID(OrgID),这个字段的名字(FieldName),这个字段的数据类型(datatype)和一个布尔字段(IsIndexed)来定义这个字段是否需要被检索。
Data表
Data表的作用和Metadata表正好相反,它主要存储那些用户定制的对象和对象所包含的字段的数据,主要也包括两大类:
- Data表:这个表放置着上面那些对象和字段所对应的数据,核心字段有全局唯一的ID(GUID),租户ID(OrgID),对象的ID(ObjID)和存放对象名字的"Nature Name(自然名称)",比如这行和一个会计对象有关,这行的""Nature Name"字段可能是"Account Name",除了这些核心字段之外,这个表还有名字从Value0到Value500的501个数据列来存储数据,而且这些列都是varchar的形式来承载不同类型的数据,这种数据列也被称为"flex列"。
- Clob表:这个表主要存放那些CLOB(Character Large Object,字符大对象)数据,对象最大支持到32000个字符。
Pivot表
Pivot表,也称为"数据透视表",在Force.com中是以denormalized (去规范化)格式存储那些用于特殊目的的数据,比如用于检索(indexing),唯一性和关系等,主要作用是加速这些特殊数据的读取以提升系统整体的性能。主要有五种Pivot表:
- Index Pivot表:由于Data表里面数据都是以"flex列"的形式存储,所以很难在Data表的基础上对表中的数据进行检索,所以Force.com引入Index Pivot表来解决这个问题,系统在运行的时候会将需要索引的数据从Data表同步到Index Pivot表中相对应的字段来方便检索,比如这个数据的类型是日期型的,那么它将会被同步到Index Pivot表中的日期字段。
- UniqueFields Pivot表:这个表是用来帮助系统在Data表中字段实现唯一性。
- Relationships Pivot表:Force.com提供了"Relationship"这个数据类型来定义多个对象之间的关系,而Relationships Pivot表则起到方便和加速"Relationship"数据读取的作用。
- NameDenorm表:是一个简单的数据表用于存储对象的ID(ObjID)和这个对象的实例的名字,主要让一些仅需获取名字的查询调用,从而让一些简单的查询无需查询规模庞大的Data表。
- FallbackIndex表:这个表将记录所有对象的名字,来免去成本高昂的"UNION"操作,从而加速查询。
APEX
APEX的语言是为Force.com度身定做的一门语法上类似Java的强类型面向对象语言,主要可以通过APEX在Force.com上创建Web Service,编辑复杂的商业逻辑和整合多个Force.com的模块等。APEX主要以两种方式执行:其一是以单独脚本的形式,按照用户的需要执行。其二是以触发器的形式,当一个特定的数据处理事件发生的之前或者之后,与这个事件绑定的APEX代码将会被执行。而且所有APEX代码将会以Metadata的形式存储在Metadata表内。当一段APEX代码被调用的时候,APEX的翻译器(runtime interpreter)将会从Metadata Cache读取编译之后的APEX代码,而且能够同时被多个租户共享以提升效率。
那么为什么要在Force.com引入APEX这门新的语言,而不是像Google App Engine那样支持已经有一定市场占有率的语言,比如Java和Pyhon。Salesforce的首席架构师在谈到这点时,他提出了一个非常重要的原因,那就是安全,首先,Salesforce会APEX语言度身设计一组管理工具,通过这个工具能够非常方便地监控APEX脚本的执行,并且能知道这个脚本在执行过程所耗费的CPU时间,内存容量和SQL语句的数量等数据来判断是否需要中断这个APEX脚本,以避免影响到属于其他租户的应用,如果中断的话,系统会抛出一个runtime exception给上层的调用者。其次,基于APEX语言的代码能够对其内嵌的SOQL(Sforce Object Query Language)和SOSL(Sforce Object Search Language)进行验证来避免实际运行时出现错误。还有,在安全方面除了APEX自带的功能之外,Salesforce还要求每个上传到Force.com的APEX脚本,都需要自带能覆盖其75%代码的测试用例,这种做法不仅显著地提升APEX代码的质量从而确保平台整体运行的稳定,而且在Force.com自己更新的时候,能使用这些用例来确保新的更新不会影响现有的基于Force.com的应用。
设计理念
根据 Craig Weissman 的演讲和几份官方的白皮书,在Force.com的设计方面Salesforce团队主要有下面这五大考量:
- 数据驱动:由于 Salesforce 主要面向企业用户,导致其上面运行的应用,无论是 CRM ,还是报表工具,都是以数据的CRUD(增删改查)为核心,所以 Force.com 需要由数据来驱动,而且也需要为此做一定程度的优化。
- 规模经济:由于需要在低价格和灵活付费的基础上提供可定制化应用,所以需要让尽可能多用户共享同一套系统,来大幅减低基础设施和管理等资源的投入,并实现规模经济的效益。
- 安全为先:由于在一套物理设备上将承载数以万计客户的企业级应用,那么如果出现严重的程序错误或者数据方面遗失或者错乱,将会发生非常严重的后果,所以安全问题是一个 Salesforce绝不能轻视的问题。
- 定制方便:虽然各个企业都会存在一部分比较通用的流程,但是每个企业都可能存在一部分私有或者独特的流程,所以Force.com需要提供方便的定制功能来帮助用户将更快捷地将企业的业务迁移到其上。
- 功能丰富:虽然用户能在 Force.com 上进行开发和定制,但是如果 Force.com 能提供更多的功能模块或者能让用户购买和整合第三方的应用将非常有效地帮助用户开发应用。
虽然这些设计理念说起来很容易,但是实现起来是非常艰难的。可贵地是,Salesforce 团队在开发 Force.com 的过程中基本实现了这些设计理念。
总结
关于本系列的总结,也主要包括五个方面:
- Trade-Off 是难免的:为了满足设计目标,有时不得不做Trade-Off 。由于 Salesforce 所需要承载的多租户应用的规模之大,定制化需求之高都是前所未见的,所以Salesforce并没有采用在第二篇所提到几种常见模型,而是从长计议,采用了更灵活但技术要求更高的 Metadata 方式。 还有为了避免在数据库中执行成本非常高并会 Locking 整个数据库的 DDL(数据库定义语句)操作,所以在 Force.com 运行的时候是无法创建和修改数据库表,而这样将会提升实现的难度。
- 优化很重要,虽然 Force.com 的多租户架构就像 Java 一样,采用了很多动态生成的机制。很显然,如果像早期的Java那样缺乏优化的话,那么 Force.com 整体的性能将会非常糟糕,从而无法实现其设计要求。但幸运的是,Salesforce 团队不仅做了优化,而且凭借着其很多核心成员来自于 Oracle 的背景,在数据库端做了很多高水平的优化,比如添加了很多貌似累赘的 Pivot 表来加快部分常用数据的读取。
- 人才很重要:经过本系列的介绍,可以看出 Force.com 的整个架构并不全是在现有的框架和库的基础上构建的,而是为了设计目标开发了很多比较底层和比较复杂的模块,而且这些模块是只有那些顶级的程序员才能编写出来的,所以说如果没有硅谷那个庞大的优秀程序员池,Salesforce 就很难走到今天。
- 软件是一个进化的工程:刚开始的时候 Salesforce 架构是普普通通的 B/S 架构,但是随着用户不断地提出定制化的要求,Salesforce 也不得不在架构中引入多租户的概念,之后,由于用户需要更灵活的,可伸缩的和功能更强大的平台,导致 Salesforce 不断地对其架构进行重构,到最后,终于整出了 Force.com 这一优秀的 PaaS 平台。
- 有用的创新才珍贵:Salesforce 不仅在 Force.com 引入很多创新,而且都非常有效。在这些创新当中,最有用的除了 Metadata 驱动这种多租户架构实现机制之外,还有一个名为"回收站(Recycle Bin)"的概念,这个回收站主要存储30天来那些从数据表里面删除的数据,如果用户在30天内发现数据是误删,可以对数据进行恢复,这样既减低数据误删的可能性,而且能回收部分物理资源,比如硬盘空间等。
最后,我想说虽然到现在为止,Salesforce 还不能算是一场巨大的商业胜利,但是它在产品和思路方面有很多值得我们借鉴的地方,这也是我写本文的初衷,并谢谢大家花时间在这个系列上面,希望能对得起大家的时间。还有,如果大家对本系列有什么疑问或者见解,那么就不要吝惜你的时间,请留下你的评论。















 3512
3512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









