






总目录
第1章 引言
第2章 Hyperledger Fabric v2.0的新增功能
第3章 关键概念
第4章 入门
第5章 开发应用程序
第6章 教程(上)
第6章 教程(下)
第7章 部署生产网络
第8章 操作指南
第9章 升级到最新版本
6.教程(下)
使用CouchDB
本教程将描述使用CouchDB作为带有Hyperledger Fabric的状态数据库所需的步骤。现在,您应该已经熟悉了Fabric的概念,并且已经研究了一些示例和教程。
这些说明使用Fabric v2.0版本中引入的新Fabric链码生命周期。如果您希望使用以前的生命周期模型将索引与链码一起使用,请访问Using CouchDB的v1.4版本。
要深入了解CouchDB,请将CouchDB作为状态数据库,有关Fabric ledger的更多信息,请参阅ledger主题。按照下面的教程了解如何在区块链网络中利用CouchDB的详细信息。
在本教程中,我们将使用Marbles示例作为我们的用例来演示如何在Fabric中使用CouchDB,并将Marbles部署到Fabric测试网络中。您应该已经完成了安装示例、二进制文件和Docker镜像的任务。
为什么使用CouchDB?
Fabric支持两种类型的节点数据库。LevelDB是嵌入节点中的默认状态数据库。LevelDB将链码数据存储为简单的键值对,只支持key、key range和复合键查询。CouchDB是一个可选的备用状态数据库,允许您将账本上的数据建模为JSON,并针对数据值而不是键发出丰富的查询。CouchDB还允许您使用链码部署索引,以提高查询效率,并使您能够查询大型数据集。
为了利用CouchDB的优点,即基于内容的JSON查询,您的数据必须以JSON格式建模。在设置网络之前,必须决定是使用LevelDB还是CouchDB。由于数据兼容性问题,不支持将节点从使用LevelDB切换到CouchDB。网络上的所有节点必须使用相同的数据库类型。如果您混合了JSON和二进制数据值,那么仍然可以使用CouchDB,但是只能根据key、key range和组合键查询查询二进制值。
在Hyperledger Fabric中启用CouchDB
CouchDB作为一个独立的数据库进程与节点进程一起运行。在设置、管理和操作方面还有其他注意事项。CouchDB的Docker镜像是可用的,我们建议它与节点服务器运行在同一个服务器上。您将需要为每个节点设置一个CouchDB容器,并通过更改core.yaml中的配置来更新每个对等容器,以指向CouchDB容器。core.yaml文件必须位于环境变量FABRIC_CFG_PATH指定的目录中
- 对于Docker部署,
core.yaml是预先配置的,位于对等容器FABRIC_CFG_PATH文件夹中。但是,当使用Docker环境时,通常通过编辑docker-compose-couch.yaml来覆盖core.yaml来传递环境变量 - 对于本机二进制部署,
core.yaml包含在发布工件发行版中。
编辑core.yaml的stateDatabase部分。指定CouchDB作为stateDatabase并填充相关联的couchDBConfig属性。有关更多信息,请参阅CouchDB配置。
创建索引
为什么索引很重要?
索引允许查询数据库,而不必在每次查询中检查每一行,从而使它们运行得更快、更高效。通常,索引是为频繁出现的查询条件而构建的,这样可以更有效地查询数据。为了利用CouchDB的主要优点(对JSON数据执行丰富查询的能力),不需要索引,但是强烈建议使用索引来提高性能。另外,如果查询中需要排序,CouchDB需要排序字段的索引。
注意:没有索引的富查询可以工作,但可能会在CouchDB日志中抛出一个警告,说明找不到索引。但是,如果富查询包含排序规范,则需要该字段上的索引;否则,查询将失败并引发错误。
为了演示如何建立索引,我们将使用Marbles样本中的数据。在本例中,Marbles数据结构定义为:
type marble struct {
ObjectType string `json:"docType"` //docType is used to distinguish the various types of objects in state database
Name string `json:"name"` //the field tags are needed to keep case from bouncing around
Color string `json:"color"`
Size int `json:"size"`
Owner string `json:"owner"`
}
在此结构中,属性(docType、name、color、size、owner)定义与资产关联的账本数据。docType属性是链码中使用的一种模式,用于区分可能需要单独查询的不同数据类型。使用CouchDB时,建议包含此docType属性以区分chaincode命名空间中的每种类型的文档。(每个链码都表示为自己的CouchDB数据库,也就是说,每个链码都有自己的键名称空间。)
对于Marbles数据结构,docType用于标识此文档/资产是Marbles资产。链码数据库中可能存在其他文档/资产。数据库中的文档可以根据所有这些属性值进行搜索。
定义用于链码查询的索引时,每个索引都必须在其扩展名为*.json的文本文件中定义,并且索引定义的格式必须为CouchDB index json格式。
要定义索引,需要三条信息:
- 字段:这些是经常查询的字段
- 名称:索引的名称
- 类型:在这个环境中总是json
例如,对于名为foo的字段,一个名为foo-index的简单索引。
{
"index": {
"fields": ["foo"]
},
"name" : "foo-index",
"type" : "json"
}
可以选择在索引定义上指定设计文档属性ddoc。设计文档是为包含索引而设计的CouchDB构造。为了提高效率,可以将索引分组到设计文档中,但是CouchDB建议每个设计文档使用一个索引。
小贴士:定义索引时,最好将ddoc属性和值与索引名称一起包含在内。重要的是要包含此属性,以确保以后可以根据需要更新索引。它还使您能够显式指定在查询上使用哪个索引。
以下是来自Marbles示例的另一个索引定义示例,索引名称为indexOwner,使用多个字段docType和owner,并包含ddoc属性:
{
"index":{
"fields":["docType","owner"] // Names of the fields to be queried
},
"ddoc":"indexOwnerDoc", // (optional) Name of the design document in which the index will be created.
"name":"indexOwner",
"type":"json"
}
在上面的示例中,如果设计文档indexOwnerDoc不存在,则在部署索引时会自动创建它。可以使用字段列表中指定的一个或多个属性来构造索引,并且可以指定任何属性组合。一个属性可以存在于同一docType的多个索引中。在下面的示例中,index1仅包含属性所有者,index2包含属性所有者和颜色,index3包括属性所有者、颜色和大小。另外,请注意,遵循CouchDB推荐的实践,每个索引定义都有自己的ddoc值。
{
"index":{
"fields":["owner"] // Names of the fields to be queried
},
"ddoc":"index1Doc", // (optional) Name of the design document in which the index will be created.
"name":"index1",
"type":"json"
}
{
"index":{
"fields":["owner", "color"] // Names of the fields to be queried
},
"ddoc":"index2Doc", // (optional) Name of the design document in which the index will be created.
"name":"index2",
"type":"json"
}
{
"index":{
"fields":["owner", "color", "size"] // Names of the fields to be queried
},
"ddoc":"index3Doc", // (optional) Name of the design document in which the index will be created.
"name":"index3",
"type":"json"
}
通常,您应该为索引字段建模,以匹配将在查询过滤器和排序中使用的字段。有关以JSON格式构建索引的更多详细信息,请参阅CouchDB文档。
关于索引的最后一句话,Fabric使用一种称为index warming的模式为数据库中的文档编制索引。CouchDB通常在下一个查询之前不会索引新的或更新的文档。Fabric通过在提交每个数据块后请求索引更新来确保索引保持“温暖”。这样可以确保查询的速度很快,因为它们在运行查询之前不必索引文档。此过程使索引保持最新状态,并在每次向状态数据库添加新记录时进行刷新。
将索引添加到链码文件夹
完成索引后,需要将其与链码一起打包以进行部署,方法是将其放在适当的元数据文件夹中。可以使用peer lifecycle chaincode命令安装链码。JSON索引文件必须位于路径META-INF/statedb/couchdb/index下,该路径位于链码所在的目录中。
下面的Marbles示例说明了如何使用链码打包索引。
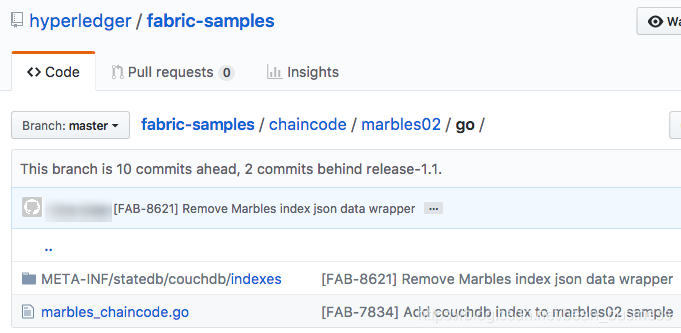
此示例包含一个名为indexOwnerDoc的索引:
{
"index":{
"fields":["docType","owner"]},"ddoc":"indexOwnerDoc", "name":"indexOwner","type":"json"}
启动网络
我们将启动Fabric测试网络,并用它来部署弹珠链。使用以下命令导航到Fabric samples中的test-network目录:
cd fabric-samples/test-network
对于本教程,我们希望从已知的初始状态开始操作。以下命令将终止任何活动或过时的Docker容器,并移除以前生成的构件:
./network.sh down
如果您以前没有看过本教程,那么在我们将其部署到网络之前,您需要提供链码依赖项。运行以下命令:
cd ../chaincode/marbles02/go
GO111MODULE=on go mod vendor
cd ../../../test-network
在test-network目录中,使用CouchDB使用以下命令部署测试网络:
./network.sh up createChannel -s couchdb
这将创建两个使用CouchDB作为状态数据库的fabric普通节点。它还将创建一个排序节点和一个名为mychannel的通道。
安装并定义链码
客户端应用程序通过链码与区块链账本交互。因此,我们需要在每一个执行和背书我们的交易的节点上安装一个链码。然而,在我们可以与我们的链码交互之前,通道成员需要就建立链码管理的链码定义达成一致。在上一节中,我们演示了如何将索引添加到chaincode文件夹,以便将索引与chaincode一起部署。
链码需要打包后才能安装到我们的节点上。我们可以使用peer lifecycle chaincode package命令来打包弹珠链码。
- 启动测试网络后,在CLI中复制并粘贴以下环境变量,以Org1管理员的身份与网络交互。确保您在测试网络目录中。
export PATH=${
PWD}/../bin:${
PWD}:$PATH
export FABRIC_CFG_PATH=${
PWD}/../config/
export CORE_PEER_TLS_ENABLED=true
export CORE_PEER_LOCALMSPID="Org1MSP"
export CORE_PEER_TLS_ROOTCERT_FILE=${
PWD}/organizations/peerOrganizations/org1.example.com/peers/peer0.org1.example.com/tls/ca.crt
export CORE_PEER_MSPCONFIGPATH=${
PWD}/organizations/peerOrganizations/org1.example.com/users/Admin@org1.example.com/msp
export CORE_PEER_ADDRESS=localhost:7051
- 使用以下命令打包弹珠链码:
peer lifecycle chaincode package marbles.tar.gz --path ../chaincode/marbles02/go --lang golang --label marbles_1
此命令将创建一个名为marbles.tar.gz的链码包
- 使用以下命令将链码包安装到节点
peer0.org1.example.com上
peer lifecycle chaincode install marbles.tar.gz
成功的安装命令将返回链码标识符,类似于下面的响应:
2019-04-22 18:47:38.312 UTC [cli.lifecycle.chaincode] submitInstallProposal -> INFO 001 Installed remotely: response:<status:200 payload:"\nJmarbles_1:0907c1f3d3574afca69946e1b6132691d58c2f5c5703df7fc3b692861e92ecd3\022\tmarbles_1" >
2019-04-22 18:47:38.312 UTC [cli.lifecycle.chaincode] submitInstallProposal -> INFO 002 Chaincode code package identifier: marbles_1:0907c1f3d3574afca69946e1b6132691d58c2f5c5703df7fc3b692861e92ecd3
在peer0.org1.example.com上安装链码之后,我们需要批准Org1的链码定义。
- 使用下面的命令查询节点以获取已安装的链代码的包ID。
peer lifecycle chaincode queryinstalled
该命令将返回与install命令相同的包标识符。您将看到类似于以下内容的输出:
Installed chaincodes on peer:
Package ID: marbles_1:60ec9430b221140a45b96b4927d1c3af736c1451f8d432e2a869bdbf417f9787, Label: marbles_1
- 将包ID声明为环境变量。
将peer lifecycle chaincode queryinstalled命令返回的marbles_1包ID粘贴到下面的命令中。对于所有用户,包ID可能不相同,因此您需要使用从控制台返回的包ID来完成此步骤。
export CC_PACKAGE_ID=marbles_1:60ec9430b221140a45b96b4927d1c3af736c1451f8d432e2a869bdbf417f9787
- 使用以下命令批准Org1的Marbles链码定义。
export ORDERER_CA=${
PWD}/organizations/ordererOrganizations/example.com/orderers/orderer.example.com/msp/tlscacerts/tlsca.example.com-cert.pem
peer lifecycle chaincode approveformyorg -o localhost:7050 --ordererTLSHostnameOverride orderer.example.com --channelID mychannel --name marbles --version 1.0 --signature-policy "OR('Org1MSP.member','Org2MSP.member')" --init-required --package-id $CC_PACKAGE_ID --sequence 1 --tls --cafile $ORDERER_CA
当命令成功完成时,您将看到类似于:
2020-01-07 16:24:20.886 EST [chaincodeCmd] ClientWait -> INFO 001 txid [560cb830efa1272c85d2f41a473483a25f3b12715d55e22a69d55abc46581415] committed with status (VALID) at
我们需要大多数组织在将链码定义提交到通道之前批准它。这意味着我们也需要Org2来批准链码定义。因为我们不需要Org2来背书链码,也没有在任何Org2节点上安装包,所以我们不需要提供packageID作为链码定义的一部分。
- 使用CLI作为Org2管理员进行操作。将以下命令块作为一个组复制并粘贴到节点容器中,然后一次运行它们。
export CORE_PEER_LOCALMSPID="Org2MSP"
export CORE_PEER_TLS_ROOTCERT_FILE=${
PWD}/organizations/peerOrganizations/org2.example.com/peers/peer0.org2.example.com/tls/ca.crt
export CORE_PEER_MSPCONFIGPATH=${
PWD}/organizations/peerOrganizations/org2.example.com/users/Admin@org2.example.com/msp
export CORE_PEER_ADDRESS=localhost:9051
- 使用以下命令批准Org2的链码定义:
peer lifecycle chaincode approveformyorg -o localhost:7050 --ordererTLSHostnameOverride orderer.example.com --channelID mychannel --name marbles --version 1.0 --signature-policy "OR('Org1MSP.member','Org2MSP.member')" --init-required --sequence 1 --tls --cafile $ORDERER_CA
- 我们现在可以使用peer lifecycle chaincode commit命令将链码定义提交到通道:
export ORDERER_CA=${
PWD}/organizations/ordererOrganizations/example.com/orderers/orderer.example.com/msp/tlscacerts/tlsca.example.com-cert.pem
export ORG1_CA=${
PWD}/organizations/peerOrganizations/org1.example.com/peers/peer0.org1.example.com/tls/ca.crt
export ORG2_CA=${
PWD}/organizations/peerOrganizations/org2.example.com/peers/peer0.org2.example.com/tls/ca.crt
peer lifecycle chaincode commit -o localhost:7050 --ordererTLSHostnameOverride orderer.example.com --channelID mychannel --name marbles --version 1.0 --sequence 1 --signature-policy "OR('Org1MSP.member','Org2MSP.member')" --init-required --tls --cafile $ORDERER_CA --peerAddresses localhost:7051 --tlsRootCertFiles $ORG1_CA --peerAddresses localhost:9051 --tlsRootCertFiles $ORG2_CA
当提交交易成功完成时,您应该看到类似于:
2019-04-22 18:57:34.274 UTC [chaincodeCmd] ClientWait -> INFO 001 txid [3da8b0bb8e128b5e1b6e4884359b5583dff823fce2624f975c69df6bce614614] committed with status (VALID) at peer0.org2.example.com:9051
2019-04-22 18:57:34.709 UTC [chaincodeCmd] ClientWait -> INFO 002 txid [3da8b0bb8e128b5e1b6e4884359b5583dff823fce2624f975c69df6bce614614] committed with status (VALID) at peer0.org1.example.com:7051
- 因为弹珠链码包含一个初始化函数,我们需要使用peer chaincode invoke命令来调用
Init(),然后才能使用链码中的其他函数:
peer chaincode invoke -o localhost:7050 --ordererTLSHostnameOverride orderer.example.com --channelID mychannel --name marbles --isInit --tls --cafile $ORDERER_CA --peerAddresses localhost:7051 --tlsRootCertFiles $ORG1_CA -c '{"Args":["Init"]}'
验证索引是否已部署
在节点上安装了链码并将其部署到通道后,索引将被部署到每个节点的CouchDB状态数据库中。您可以通过检查Docker容器中的对等日志来验证CouchDB索引是否已成功创建。
要查看peer Docker容器中的日志,请打开一个新的终端窗口,并运行以下命令以grep确认索引已创建。
docker logs peer0.org1.example.com 2>&1 | grep "CouchDB index"
您将看到如下所示的结果:
[couchdb] CreateIndex -> INFO 0be Created CouchDB index [indexOwner] in state database [mychannel_marbles] using design document [_design/indexOwnerDoc]
注意:如果您在不同于peer0.org1.example.com的节点上安装了Marbles,则可能需要将其替换为安装Marbles的其他节点的名称。
查询CouchDB状态数据库
既然索引已经在JSON文件中定义并与chaincode一起部署,那么chaincode函数可以对CouchDB状态数据库执行JSON查询,因此节点命令可以调用chaincode函数。
在查询中指定索引名称是可选的。如果未指定,并且正在查询的字段已经存在索引,则将自动使用现有索引。
小贴士:在查询中使用use_index关键字显式包含索引名称是一个很好的做法。没有它,CouchDB可能会选择一个不太理想的指数。另外,CouchDB可能根本就不使用索引,而且在测试期间的低容量下您可能没有意识到。只有在更高的数量上,您可能会意识到性能变慢,因为CouchDB没有使用索引,而您假设它是这样的。
在链码中构建查询
您可以使用在链码中定义的查询对账本上的数据执行复杂的富格式查询。marbles02示例包含两个丰富的查询函数:
- queryMarbles -
特别丰富查询的示例。这是一个可以将(选择器)字符串传递到函数中的查询。此查询对于需要在运行时动态构建自己的选择器的客户端应用程序非常有用。有关选择器的更多信息,请参阅CouchDB选择器语法。 - queryMarblesByOwner -
参数化查询的示例,其中查询逻辑被刻到链码中。在本例中,函数接受一个参数,即Marbles所有者。然后,它使用JSON查询语法在状态数据库中查询与docType“marble”和所有者id相匹配的JSON文档。
使用peer命令运行查询
在没有客户端应用程序的情况下,我们可以使用peer命令来测试链码中定义的查询。我们将定制peer chaincode query命令,以使用Marbles索引indexOwner,并使用queryMarbles函数查询“tom”拥有的所有Marbles。
在查询数据库之前,我们应该添加一些数据。以Org1身份运行以下命令以创建“tom”拥有的Marbles:
export CORE_PEER_LOCALMSPID="Org1MSP"
export CORE_PEER_TLS_ROOTCERT_FILE=${
PWD}/organizations/peerOrganizations/org1.example.com/peers/peer0.org1.example.com/tls/ca.crt
export CORE_PEER_MSPCONFIGPATH=${
PWD}/organizations/peerOrganizations/org1.example.com/users/Admin@org1.example.com/msp
export CORE_PEER_ADDRESS=localhost:7051
peer chaincode invoke -o localhost:7050 --ordererTLSHostnameOverride orderer.example.com --tls --cafile ${
PWD}/organizations/ordererOrganizations/example.com/orderers/orderer.example.com/msp/tlscacerts/tlsca.example.com-cert.pem -C mychannel -n marbles -c '{"Args":["initMarble","marble1","blue","35","tom"]}'
在初始化链码时部署索引后,链码查询将自动使用该索引。CouchDB可以根据所查询的字段来确定使用哪个索引。如果查询条件存在索引,则将使用该索引。但是,建议的方法是在查询中指定use_index关键字。下面的peer命令是一个示例,说明如何通过包含use_index关键字在选择器语法中显式指定索引:
// Rich Query with index name explicitly specified:
peer chaincode query -C mychannel -n marbles -c '{"Args":["queryMarbles", "{\"selector\":{\"docType\":\"marble\",\"owner\":\"tom\"}, \"use_index\":[\"_design/indexOwnerDoc\", \"indexOwner\"]}"]}'
深入研究上面的查询命令,有三个感兴趣的参数:
- queryMarbles
弹珠链码中函数的名称。注意一个shimshim.ChaincodeStubInterface用于访问和修改账本。getQueryResultForQueryString()将查询字符串传递给shim API getQueryResult()。
func (t *SimpleChaincode) queryMarbles(stub shim.ChaincodeStubInterface, args []string) pb.Response {
// 0
// "queryString"
if len(args) < 1 {
return shim.Error("Incorrect number of arguments. Expecting 1")
}
queryString := args[0]
queryResults, err := getQueryResultForQueryString(stub, queryString)
if err != nil {
return shim.Error(err.Error())
}
return shim.Success(queryResults)
}
-
{"selector":{"docType":"marble","owner":"tom"}
这是一个ad hoc selector字符串的示例,它查找类型为marble的所有文档,其中owner属性的值为tom。 -
"use_index":["_design/indexOwnerDoc", "indexOwner"]
指定设计文档名称indexOwnerDoc和索引名称indexOwner。在本例中,选择器查询显式包含索引名称,该名称通过使用use_index关键字指定。回顾上面的索引定义Create an index,它包含一个设计文档“ddoc”:“indexOwnerDoc”。对于CouchDB,如果您计划在查询中显式地包含索引名称,那么索引定义必须包含ddoc值,以便可以使用use_index关键字引用它。
查询成功运行,并利用索引得到以下结果:
Query Result: [{
"Key":"marble1", "Record":{
"color":"blue","docType":"marble","name":"marble1","owner":"tom","size":35}}]
对查询和索引使用最佳实践
使用索引的查询将更快地完成,而不必扫描couchDB中的完整数据库。理解索引将允许您编写查询以获得更好的性能,并帮助您的应用程序处理网络上的大量数据或块。
计划用链码安装的索引也很重要。对于支持大多数查询的链码,您应该只安装几个索引。添加过多的索引或在索引中使用过多的字段会降低网络的性能。这是因为索引是在每个块被提交后更新的。通过“索引预热”需要更新的索引越多,完成交易所需的时间就越长。
本节中的示例将有助于演示查询如何使用索引以及哪种类型的查询具有最佳性能。编写查询时请记住以下几点:
- 索引中的所有字段也必须位于要使用的索引的查询的选择器或排序部分中。
- 更复杂的查询将具有更低的性能,并且不太可能使用索引。
- 您应该尽量避免使用会导致全表扫描或全索引扫描的运算符,如
$or、$in和$regex。
在本教程的上一节中,您针对弹珠链码发出了以下查询:
// Example one: query fully supported by the index
peer chaincode query -C $CHANNEL_NAME -n marbles -c '{"Args":["queryMarbles", "{\"selector\":{\"docType\":\"marble\",\"owner\":\"tom\"}, \"use_index\":[\"indexOwnerDoc\", \"indexOwner\"]}"]}'
索引上安装了弹珠索引:
{
"index":{
"fields":["docType","owner"]},"ddoc":"indexOwnerDoc", "name":"indexOwner","type":"json"}
请注意,查询中的两个字段docType和owner都包含在索引中,使其成为一个完全受支持的查询。因此,此查询将能够使用索引中的数据,而不必搜索整个数据库。完全支持的查询(如此查询)将比链码中的其他查询更快地返回。
如果向上面的查询添加额外的字段,它仍将使用索引。但是,查询还必须扫描索引数据中的额外字段,从而导致更长的响应时间。例如,下面的查询仍将使用索引,但返回时间将比上一个示例长。
// Example two: query fully supported by the index with additional data
peer chaincode query -C $CHANNEL_NAME -n marbles -c '{"Args":["queryMarbles", "{\"selector\":{\"docType\":\"marble\",\"owner\":\"tom\",\"color\":\"red\"}, \"use_index\":[\"/indexOwnerDoc\", \"indexOwner\"]}"]}'
如果查询不包括索引中的所有字段,则必须扫描整个数据库。例如,下面的查询搜索所有者,而不指定所属项的类型。由于ownerIndexDoc同时包含owner和docType字段,因此此查询将无法使用索引。
// Example three: query not supported by the index
peer chaincode query -C $CHANNEL_NAME -n marbles -c '{"Args":["queryMarbles", "{\"selector\":{\"owner\":\"tom\"}, \"use_index\":[\"indexOwnerDoc\", \"indexOwner\"]}"]}'
一般来说,更复杂的查询将具有较长的响应时间,并且受索引支持的可能性也更低。诸如$or、$in和$regex等运算符通常会导致查询扫描完整索引或根本不使用索引。
例如,下面的查询包含一个$or术语,它将搜索tom拥有的每个Marbles和每个项目。
// Example four: query with $or supported by the index
peer chaincode query -C $CHANNEL_NAME -n marbles -c '{"Args":["queryMarbles", "{\"selector\":{"\$or\":[{\"docType\:\"marble\"},{\"owner\":\"tom\"}]}, \"use_index\":[\"indexOwnerDoc\", \"indexOwner\"]}"]}'
此查询仍将使用索引,因为它搜索indexOwnerDoc中包含的字段。但是,查询中的$or条件要求扫描索引中的所有项,从而导致响应时间更长。
下面是索引不支持的复杂查询的示例。
// Example five: Query with $or not supported by the index
peer chaincode query -C $CHANNEL_NAME -n marbles -c '{"Args":["queryMarbles", "{\"selector\":{"\$or\":[{\"docType\":\"marble\",\"owner\":\"tom\"},{"\color\":"\yellow\"}]}, \"use_index\":[\"indexOwnerDoc\", \"indexOwner\"]}"]}'
该查询将搜索tom拥有的所有Marbles或任何其他黄色项目。此查询将不使用索引,因为它需要搜索整个表以满足$or条件。根据账本上的数据量,此查询将需要很长时间才能响应或可能超时。
虽然查询遵循最佳实践很重要,但使用索引并不是收集大量数据的解决方案。区块链数据结构经过优化以验证和确认交易,不适用于数据分析或报告。如果要将仪表板构建为应用程序的一部分或分析网络中的数据,最佳做法是查询从节点复制数据的链外数据库。这将允许您理解区块链上的数据,而不会降低网络性能或中断交易。
您可以使用应用程序中的块或链码事件将交易数据写入链外数据库或分析引擎。对于接收到的每个块,块侦听器应用程序将遍历块交易,并使用来自每个有效交易的rwset的键/值写入来构建数据存储。基于节点通道的事件服务提供可重放的事件,以确保下游数据存储的完整性。有关如何使用事件侦听器将数据写入外部数据库的示例,请访问Fabric示例中的链外数据示例。
分页查询CouchDB状态数据库
当CouchDB查询返回大的结果集时,可以使用一组APIs,这些APIs可以由链码调用来对结果列表进行分页。分页提供了一种机制,通过指定pagesize和起始点(一个指示结果集开始位置的bookmark)来划分结果集。客户端应用程序反复调用执行查询的链码,直到不再返回任何结果。有关更多信息,请参阅有关使用CouchDB分页的主题。
我们将使用Marbles示例函数queryMarblesWithPagination来演示如何在链码和客户端应用程序中实现分页。
- 带分页的查询标记 -
带有分页的特别富查询的示例。这是一个查询,其中可以将(选择器)字符串传递到与上述示例类似的函数中。在本例中,查询中还包括pageSize和bookmark。
为了演示分页,需要更多的数据。本例假设您已经从上面添加了marble1。在节点容器中运行以下命令以创建“tom”拥有的四个弹珠,以创建“tom”拥有的总共五个弹珠:
export CORE_PEER_LOCALMSPID="Org1MSP"
export CORE_PEER_TLS_ROOTCERT_FILE=${
PWD}/organizations/peerOrganizations/org1.example.com/peers/peer0.org1.example.com/tls/ca.crt
export CORE_PEER_MSPCONFIGPATH=${
PWD}/organizations/peerOrganizations/org1.example.com/users/Admin@org1.example.com/msp
export CORE_PEER_ADDRESS=localhost:7051
peer chaincode invoke -o localhost:7050 --ordererTLSHostnameOverride orderer.example.com --tls --cafile ${
PWD}/organizations/ordererOrganizations/example.com/orderers/orderer.example.com/msp/tlscacerts/tlsca.example.com-cert.pem -C mychannel -n marbles -c '{"Args":["initMarble","marble2","yellow","35","tom"]}'
peer chaincode invoke -o localhost:7050 --ordererTLSHostnameOverride orderer.example.com --tls --cafile ${
PWD}/organizations/ordererOrganizations/example.com/orderers/orderer.example.com/msp/tlscacerts/tlsca.example.com-cert.pem -C mychannel -n marbles -c '{"Args":["initMarble","marble3","green","20","tom"]}'
peer chaincode invoke -o localhost:7050 --ordererTLSHostnameOverride orderer.example.com --tls --cafile ${
PWD}/organizations/ordererOrganizations/example.com/orderers/orderer.example.com/msp/tlscacerts/tlsca.example.com-cert.pem -C mychannel -n marbles -c '{"Args":["initMarble","marble4","purple","20","tom"]}'
peer chaincode invoke -o localhost:7050 --ordererTLSHostnameOverride orderer.example.com --tls --cafile ${
PWD}/organizations/ordererOrganizations/example.com/orderers/orderer.example.com/msp/tlscacerts/tlsca.example.com-cert.pem -C mychannel -n marbles -c '{"Args":["initMarble","marble5","blue","40","tom"]}'
除了上例中查询的参数外,queryMarblesWithPagination还添加了pagesize和bookmark。PageSize指定每个查询要返回的记录数。bookmark是一个“锚”,告诉couchDB从哪里开始页面。(每个结果页都返回一个唯一的书签。)
queryMarblesWithPagination
弹珠链码中函数的名称。注意一个shimshim.ChaincodeStubInterface用于访问和修改账本。getQueryResultForQueryStringWithPagination()将查询字符串与pagesize和bookmark一起传递给shim APIGetQueryResultWithPagination()。
func (t *SimpleChaincode) queryMarblesWithPagination(stub shim.ChaincodeStubInterface, args []string) pb.Response {
// 0
// "queryString"
if len(args) < 3 {
return shim.Error("Incorrect number of arguments. Expecting 3")
}
queryString := args[0]
//return type of ParseInt is int64
pageSize, err := strconv.ParseInt(args[1], 10, 32)
if err != nil {
return shim.Error(err.Error())
}
bookmark := args[2]
queryResults, err := getQueryResultForQueryStringWithPagination(stub, queryString, int32(pageSize), bookmark)
if err != nil {
return shim.Error(err.Error())
}
return shim.Success(queryResults)
}
下面的示例是一个peer命令,它使用pageSize 3调用queryMarblesWithPagination,但没有指定书签。
小贴士:当没有指定书签时,查询从记录的“第一”页开始。
// Rich Query with index name explicitly specified and a page size of 3:
peer chaincode query -C $CHANNEL_NAME -n marbles -c '{"Args":["queryMarblesWithPagination", "{\"selector\":{\"docType\":\"marble\",\"owner\":\"tom\"}, \"use_index\":[\"_design/indexOwnerDoc\", \"indexOwner\"]}","3",""]}'
收到以下响应(为清楚起见,添加了回车符),五个弹珠中的三个返回,因为pagsize设置为3:
[{
"Key":"marble1", "Record":{
"color":"blue","docType":"marble","name":"marble1","owner":"tom","size":35}},
{
"Key":"marble2", "Record":{
"color":"yellow","docType":"marble","name":"marble2","owner":"tom","size":35}},
{
"Key":"marble3", "Record":{
"color":"green","docType":"marble","name":"marble3","owner":"tom","size":20}}]
[{
"ResponseMetadata":{
"RecordsCount":"3",
"Bookmark":"g1AAAABLeJzLYWBgYMpgSmHgKy5JLCrJTq2MT8lPzkzJBYqz5yYWJeWkGoOkOWDSOSANIFk2iCyIyVySn5uVBQAGEhRz"}}]
注意:CouchDB为每个查询惟一地生成书签,并表示结果集中的占位符。在查询的后续迭代中传递返回的书签以检索下一组结果。
下面是一个peer命令,用于调用pageSize为3的queryMarblesWithPagination。请注意,这次查询包含了从上一个查询返回的书签。
peer chaincode query -C $CHANNEL_NAME -n marbles -c '{"Args":["queryMarblesWithPagination", "{\"selector\":{\"docType\":\"marble\",\"owner\":\"tom\"}, \"use_index\":[\"_design/indexOwnerDoc\", \"indexOwner\"]}","3","g1AAAABLeJzLYWBgYMpgSmHgKy5JLCrJTq2MT8lPzkzJBYqz5yYWJeWkGoOkOWDSOSANIFk2iCyIyVySn5uVBQAGEhRz"]}'
收到以下响应(为清楚起见,添加回车符)。检索最后两条记录:
[{
"Key":"marble4", "Record":{
"color":"purple","docType":"marble","name":"marble4","owner":"tom","size":20}},
{
"Key":"marble5", "Record":{
"color":"blue","docType":"marble","name":"marble5","owner":"tom","size":40}}]
[{
"ResponseMetadata":{
"RecordsCount":"2",
"Bookmark":"g1AAAABLeJzLYWBgYMpgSmHgKy5JLCrJTq2MT8lPzkzJBYqz5yYWJeWkmoKkOWDSOSANIFk2iCyIyVySn5uVBQAGYhR1"}}]
最后一个命令是一个peer命令,它使用pageSize为3的queryMarblesWithPagination调用前一个查询中的书签。
peer chaincode query -C $CHANNEL_NAME -n marbles -c '{"Args":["queryMarblesWithPagination", "{\"selector\":{\"docType\":\"marble\",\"owner\":\"tom\"}, \"use_index\":[\"_design/indexOwnerDoc\", \"indexOwner\"]}","3","g1AAAABLeJzLYWBgYMpgSmHgKy5JLCrJTq2MT8lPzkzJBYqz5yYWJeWkmoKkOWDSOSANIFk2iCyIyVySn5uVBQAGYhR1"]}'
收到以下响应(为清楚起见,添加回车符)。不返回任何记录,表明已检索到所有页面:
[]
[{
"ResponseMetadata":{
"RecordsCount":"0",
"Bookmark":"g1AAAABLeJzLYWBgYMpgSmHgKy5JLCrJTq2MT8lPzkzJBYqz5yYWJeWkmoKkOWDSOSANIFk2iCyIyVySn5uVBQAGYhR1"}}]
有关客户机应用程序如何使用分页遍历结果集的示例,请在Marbles Samples中搜索getQueryResultForQueryStringWithPagination函数。
更新索引
随着时间的推移,可能需要更新索引。安装的链码的后续版本中可能存在相同的索引。为了更新索引,原始索引定义必须包含设计文档ddoc属性和索引名称。要更新索引定义,请使用相同的索引名称,但要更改索引定义。只需编辑索引JSON文件并在索引中添加或删除字段。Fabric只支持索引类型JSON。不支持更改索引类型。当链码定义提交到通道时,更新的索引定义被重新部署到节点的状态数据库。对索引名称或ddoc属性的更改将导致创建一个新索引,并且原始索引在CouchDB中保持不变,直到将其删除。
注意:如果状态数据库有大量的数据,则重新构建索引将需要一些时间,在此期间,链码调用问题查询可能会失败或超时。
迭代索引定义
如果您可以在开发环境中访问节点的CouchDB状态数据库,则可以迭代地测试各种索引,以支持链码查询。但对链码的任何更改都需要重新部署。使用CouchDB-Fauxton接口或命令行curl实用程序来创建和更新索引。
注意:Fauxton接口是一个用于创建、更新和将索引部署到CouchDB的web UI。如果你想试试这个界面,这里有一个faxton版本的Marbles索引格式示例。如果您已经使用CouchDB部署了测试网络,那么可以通过打开浏览器并导航到来加载Fauxton接口http://localhost:5984/_utils。
或者,如果您不喜欢使用Fauxton UI,下面是一个curl命令的示例,该命令可用于在数据库mychannel_marbles上创建索引:
// Index for docType, owner.
// Example curl command line to define index in the CouchDB channel_chaincode database
curl -i -X POST -H "Content-Type: application/json" -d
"{
\"index\":{
\"fields\":[\"docType\",\"owner\"]},
\"name\":\"indexOwner\",
\"ddoc\":\"indexOwnerDoc\",
\"type\":\"json\"}" http://hostname:port/mychannel_marbles/_index
如果您使用的是配置有CouchDB的测试网络,请替换端口:localhost:5984。
删除索引
Fabric工具不管理索引删除。如果需要删除索引,可以手动对数据库发出curl命令,或者使用Fauxton接口删除它。
删除索引的curl命令的格式为:
curl -X DELETE http://localhost:5984/{
database_name}/_index/{
design_doc}/json/{
index_name} -H "accept: */*" -H "Host: localhost:5984"
要删除本教程中使用的索引,curl命令将是:
curl -X DELETE http://localhost:5984/mychannel_marbles/_index/indexOwnerDoc/json/indexOwner -H "accept: */*" -H "Host: localhost:5984"
向通道添加组织
请确保您已下载了安装示例、二进制文件和Docker镜像以及符合本文档版本(可在左侧目录底部找到)的先决条件中列出的相应镜像和二进制文件。
本教程通过向应用程序通道添加一个新的组织Org3来扩展Fabric测试网络。
虽然我们将重点关注向频道添加新组织,但您可以使用类似的过程来进行其他频道配置更新(例如,更新修改策略或更改批处理大小)。要了解更多有关通道配置更新的过程和可能性,请查看更新通道配置)。同样值得注意的是,这里演示的通道配置更新通常由组织管理员(而不是链码或应用程序开发人员)负责。
设置环境
我们将从您的本地克隆fabric-samples中的test-network子目录的根目录进行操作。现在转到那个目录。
cd fabric-samples/test-network
首先,使用network.sh整理脚本。此命令将杀死任何活动或过时的Docker容器,并删除以前生成的构件。为了执行通道配置更新任务,绝不需要关闭Fabric网络。但是,为了本教程的目的,我们希望从已知的初始状态开始操作。因此,让我们运行以下命令来清理以前的任何环境:
./network.sh down
现在,您可以使用该脚本启动带有一个名为mychannel的通道的测试网络:
./network.sh up createChannel
如果命令成功,您可以在日志中看到以下消息:
========= Channel successfully joined ===========
现在您已经在您的机器上运行了测试网络的干净版本,我们可以开始向我们创建的频道添加一个新的org的过程。首先,我们将使用一个脚本将Org3添加到通道中,以确认流程是否正常工作。然后,我们将通过更新通道配置逐步完成添加Org3的过程。
把Org3带到通道
你应该在网络目录下测试。要使用脚本,只需发出以下命令:
cd addOrg3
./addOrg3.sh up
这里的输出很值得一读。您将看到Org3加密材料正在生成,Org3组织定义正在创建,然后通道配置正在更新、签名,然后提交到通道。
如果一切顺利,您将收到以下信息:
========= Finished adding Org3 to your test network! =========
既然我们已经确认可以将Org3添加到我们的频道中,那么我们就可以通过这些步骤来更新脚本在幕后完成的频道配置。
手动将Org3带入通道
如果您刚刚使用addOrg3.sh脚本,则需要关闭网络。以下命令将关闭所有正在运行的组件并删除所有组织的加密材料:
./addOrg3.sh down
网络关闭后,重新启动:
cd ..
./network.sh up createChannel
这将使您的网络恢复到执行addOrg3.sh脚本之前的状态。
现在我们准备手动将Org3添加到通道中。作为第一步,我们需要生成Org3的加密材料。
生成Org3加密材料
在另一个终端中,从test-network切换到addOrg3子目录。
cd addOrg3
首先,我们将为Org3节点创建证书和密钥,以及一个应用程序和管理员用户。因为我们正在更新一个示例通道,所以我们将使用cryptogen工具而不是使用证书颁发机构。以下命令使用cryptogen读取org3-crypto.yaml文件并在新的org3.example.com文件夹中生成Org3加密材料:
../../bin/cryptogen generate --config=org3-crypto.yaml --output="../organizations"
您可以在test-network/organizations/peerOrganizations目录中找到生成的Org3加密材料以及Org1和Org2的证书和密钥。
一旦我们创建了Org3加密材料,我们就可以使用configtxgen工具打印出Org3组织定义。我们将在命令前面告诉工具在当前目录中查找configtx.yaml它需要摄取的文件。
export FABRIC_CFG_PATH=$PWD
../../bin/configtxgen -printOrg Org3MSP > ../organizations/peerOrganizations/org3.example.com/org3.json
上面的命令创建一个JSON文件org3.JSON,并将其写入test-network/organizations/peerOrganizations/org3.example.com文件夹。组织定义包含Org3的策略定义,以及以base64格式编码的三个重要证书:
- CA根证书,用于建立组织的信任根
- TLS根证书,gossip协议使用它来标识Org3以进行块分发和服务发现
- 管理员用户证书(以后将需要它作为Org3的管理员)
我们将通过将此组织定义附加到通道配置来向通道添加Org3。
打开Org3组件
在我们创建了Org3证书材料之后,我们现在可以启动Org3节点。从addOrg3目录发出以下命令:
docker-compose -f docker/docker-compose-org3.yaml up -d
如果命令成功,您将看到Org3节点的创建和一个名为Org3CLI的Fabric tools容器实例:
Creating peer0.org3.example.com ... done
Creating Org3cli ... done
这个Docker-Compose文件被配置为跨越我们的初始网络,因此Org3节点和Org3CLI可以与测试网络的现有普通节点和排序节点进行解析。我们将使用Org3CLI容器与网络通信,并发出peer命令,将Org3添加到通道中。
准备CLI环境
更新过程使用配置转换器工具configtxlator。这个工具提供了一个独立于SDK的无状态restapi。此外,它还提供了一个CLI工具,可用于简化结构网络中的配置任务。该工具允许在不同的等价数据表示/格式之间进行轻松的转换(在本例中,是protobufs和JSON之间)。此外,该工具可以根据两个通道配置之间的差异计算配置更新交易。
使用以下命令执行到Org3CLI容器:
docker exec -it Org3cli bash
此容器已与organizations文件夹一起安装,使我们能够访问所有组织和排序节点组织的加密材料和TLS证书。我们可以使用环境变量作为Org1、Org2或Org3的管理员来操作Org3CLI容器。首先,我们需要为orderer TLS证书和通道名称设置环境变量:
export ORDERER_CA=/opt/gopath/src/github.com/hyperledger/fabric/peer/organizations/ordererOrganizations/example.com/orderers/orderer.example.com/msp/tlscacerts/tlsca.example.com-cert.pem
export CHANNEL_NAME=mychannel
检查以确保变量设置正确:
echo $ORDERER_CA && echo $CHANNEL_NAME
注意:如果出于任何原因需要重新启动Org3CLI容器,还需要重新导出两个环境变量:order_CA和CHANNEL_NAME。
获取配置
现在我们有了Org3CLI容器,其中包含两个关键的环境变量ORDERER_CA和CHANNEL_NAME已导出。让我们去获取通道的最新配置块mychannel。
我们之所以必须获取最新版本的配置,是因为通道配置元素是版本控制的。版本控制很重要,有几个原因。它可以防止配置更改被重复或重放(例如,使用旧的CRL恢复到通道配置会带来安全风险)。它还有助于确保并发性(如果你想从你的渠道中删除一个组织,例如,在添加了一个新的组织之后,版本控制将有助于防止你同时删除两个组织,而不仅仅是你想删除的组织)。
因为Org3还不是通道的成员,我们需要作为另一个组织的管理员来获取通道配置。因为Org1是通道的成员,所以Org1管理员有权从排序服务获取通道配置。发出以下命令以作为Org1管理员操作。
# you can issue all of these commands at once
export CORE_PEER_LOCALMSPID="Org1MSP"
export CORE_PEER_TLS_ROOTCERT_FILE=/opt/gopath/src/github.com/hyperledger/fabric/peer/organizations/peerOrganizations/org1.example.com/peers/peer0.org1.example.com/tls/ca.crt
export CORE_PEER_MSPCONFIGPATH=/opt/gopath/src/github.com/hyperledger/fabric/peer/organizations/peerOrganizations/org1.example.com/users/Admin@org1.example.com/msp
export CORE_PEER_ADDRESS=peer0.org1.example.com:7051
我们现在可以发出命令来获取最新的配置块:
peer channel fetch config config_block.pb -o orderer.example.com:7050 -c $CHANNEL_NAME --tls --cafile $ORDERER_CA
此命令将二进制protobuf通道配置块保存到config_block.pb。请注意,名称和文件扩展名的选择是任意的。但是,建议遵循一个既标识所表示对象类型又标识其编码(protobuf或JSON)的约定。
发出peer channel fetch命令时,日志中将显示以下输出:
2017-11-07 17:17:57.383 UTC [channelCmd] readBlock -> DEBU 011 Received block: 2
这告诉我们,mychannel的最新配置块实际上是block 2,而不是genesis块。默认情况下,peer channel fetch config命令返回目标通道的最新配置块,在本例中是第三个块。这是因为测试网络脚本network.sh,在两个单独的通道更新交易中为我们的两个组织(Org1和Org2)定义了锚节点。因此,我们有以下配置顺序:
- 区块0:genesis区块
- 区块1:Org1锚节点更新
- 区块2:Org2锚节点更新
将配置转换为JSON并对其进行精简
现在我们将使用configtxlator工具将这个通道配置块解码为JSON格式(可以由人类读取和修改)。我们还必须去掉所有与我们想要进行的更改无关的头、元数据、创建者签名等。我们通过jq工具实现这一点:
configtxlator proto_decode --input config_block.pb --type common.Block | jq .data.data[0].payload.data.config > config.json
这个命令留给我们一个精简的JSON对象-config.json–这将作为配置更新的基线。
花点时间在您选择的文本编辑器(或浏览器)中打开此文件。即使您完成了本教程,它仍然值得研究,因为它揭示了底层配置结构和其他类型的通道更新。我们将在更新信道配置中更详细地讨论它们。
添加Org3加密材料
无论您尝试进行何种配置更新,到目前为止所采取的步骤都将几乎相同。我们选择在本教程中添加一个org,因为这是您可以尝试的最复杂的通道配置更新之一。
我们将再次使用
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2022
2022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









