







分布式一致性协议
两阶段提交协议
略
三阶段提交协议
略
Paxos算法
关于paxos的形象理解
转载文章:http://www.lxway.com/4618606.htm
上面这篇文章写的非常好,有助于paxos的理解,摘录如下。驴友相当于proposer,队长相当于acceptor。
假如有一群驴友要决定中秋节去旅游,这群驴友分布在全国各地,假定一共25个人,分别在不同的省,要决定到底去拉萨、昆明、三亚等等哪个地点(会合时间中秋节已经定了,此时需要决定旅游地)。最直接的方式当然就是建一个QQ群,大家都在里面投票,按照少数服从多数的原则。这种方式类似于“共享内存”实现的一致性,实现起来简单,但Paxos算法不是这种场景,因为Paxos算法认为这种方式有一个很大的问题,就是QQ服务器挂掉怎么办?Paxos的原则是容错性一定要很强。所以,Paxos的场景类似于这25个人相互之间只能发短信,需要解决的核心问题是,哪怕任意的一部分人(Paxos的目的其实是少于半数的人)“失联”了,其它人也能够在会合地点上达成一致。好了,怎么设计呢?
这25个人找了另外的5个人(当然这5个人可以从25个人中选,这里为了描述方便,就单拿出另外5个人),比如北京、上海、广州、深圳、成都的5个人,25个人都给他们发短信,告诉自己倾向的旅游地。这5个人相互之间可以并不通信,只接受25个人发过来的短信。这25个人我们称为驴友,那5个人称为队长。
驴友逻辑:
先来看驴友的逻辑。驴友可以给任意5个队长都发短信,发短信的过程分为两个步骤:
第一步(申请阶段):
询问5个队长,试图与队长沟通旅游地。因为每个队长一直会收到不同驴友的短信,不能跟多个驴友一起沟通,在任何时刻只能跟一个驴友沟通,按照什么原则才能做到公平公正公开呢?这些短信都带有发送时间,队长采用的原则是同意与短信发送时间最新的驴友沟通,如果出现了更新的短信,则与短信更新的驴友沟通。总之,作为一个有话语权的人,只有时刻保持倾听最新的呼声,才能做出最明智的选择。在驴友发出短信后,等着队长。某些队长可能会说,你这条短信太老了,我不与你沟通;有些队长则可能返回说,你的短信是我收到的最新的,我同意跟你沟通。对于已经产生决定的这些队长,还得返回自己决定的旅游地。关于队长是怎么决定旅游地的,后面再说。
对于驴友来说,第一步必须至少有半数以上队长都同意沟通了,才能进入下一步。否则,你连沟通的资格都没有,一直在那儿狂发吧。你发的短信更新,你获得沟通权的可能性才更大。。。。。。
因为至少有半数以上队长(也就是3个队长以上)同意,你才能与队长们进行实质性的沟通,也就是进入第二步;而队长在任何时候只能跟1个驴友沟通,所以,在任何时候,不可能出现两个驴友都达到了这个状态。。。当然,你可以通过狂发短信把沟通权抢了。。。。
对于获得沟通权的那个驴友(称为A),那些队长会给他发送他们自己决定的旅游地(也可能都还没有决定)。可以看出,各个队长是自己决定旅游地的,队长之间无需沟通。
第二步(沟通阶段):
这个幸运的驴友收到了队长们给他发的旅游地,可能有几种情况:
第一种情况:跟A沟通的队长们(不一定是全部5个队长,但是半数以上)全部都还没有决定到底去那儿旅游,此时驴友A心花怒放,给这些队长发第二条短信,告诉他们自己希望的旅游地(比如马尔代夫);
可能会收到两种结果:一是半数以上队长都同意了,于是表明A建议的马尔代夫被半数以上队长都同意了,整个决定过程完毕了,其它驴友迟早会知道这个消息的,A先去收拾东西准备去马尔代夫;除此之外,表明失败。可能队长出故障了,比如某个队长在跟女朋友打电话等等,也可能被其它驴友抢占沟通权了(因为队长喜新厌旧嘛,只有要更新的驴友给自己发短信,自己就与新人沟通,A的建议队长不同意)等等。不管怎么说,苦逼的A还得重新从第一步开始,重新给队长们发短信申请。
第二种情况:至少有一个队长已经决定旅游地了,A可能会收到来自不同队长决定的多个旅游地,这些旅游地是不同队长跟不同驴友在不同时间上做出的决定,那么,A会先看一下,是不是有的旅游地已经被半数以上队长同意了(比如3个队长都同意去三亚,1个同意去昆明,另外一个没搭理A),如果出现了这种情况,那就别扯了,说明整个决定过程已经达成一致了,收拾收拾准备去三亚吧,结束了;如果都没有达到半数以上(比如1个同意去昆明,1个同意去三亚,2个同意去拉萨,1个没搭理我),A作为一个高素质驴友,也不按照自己的意愿乱来了(Paxos的关键所在,后者认同前者,否则整个决定过程永无止境),虽然自己原来可能想去马尔代夫等等。就给队长们发第二条短信的时候,告诉他们自己希望的旅游地,就是自己收到的那堆旅游地中最新决定的那个。(比如,去昆明那个是北京那个队长前1分钟决定的,去三亚的决定是上海那个队长1个小时之前做出来的,于是顶昆明)。驴友A的想法是,既然有队长已经做决定了,那我就干脆顶最新那个决定。
从上面的逻辑可以看出,一旦某个时刻有半数以上队长同意了某个地点比如昆明,紧跟着后面的驴友B继续发短信时,如果获得沟通权,因为半数以上队长都同意与B沟通了,说明B收到了来自半数以上队长发过来的消息,B必然会收到至少一个队长给他发的昆明这个结果(否则说明半数以上队长都没有同意昆明这个结果,这显然与前面的假设矛盾),B于是会顶这个最新地点,不会更改,因为后面的驴友都会顶昆明,因此同意昆明的队长越来越多,最终必然达成一致。
队长逻辑
看完了驴友的逻辑,那么队长的逻辑是什么呢?
队长的逻辑比较简单。
第一步(申请阶段)
在申请阶段,队长只会选择与最新发申请短信的驴友沟通,队长知道自己接收到最新短信的时间,对于更老的短信,队长不会搭理;队长同意沟通了的话,会把自己决定的旅游地(或者还没决定这一信息)发给驴友。
第二步(沟通阶段)
在沟通阶段,驴友C会把自己希望的旅游地发过来(同时会附加上自己申请短信的时间,比如3分钟前),所以队长要检查一下,如果这个时间(3分钟前)确实是当前自己最新接收到申请短信的时间(说明这段时间没有驴友要跟自己沟通),那么,队长就同意驴友C的这个旅游地了(比如昆明,哪怕自己1个小时前已经做过去三亚的决定,谁让C更新呢,于是更新为昆明);如果不是最新的,说明这3分钟内又有其它驴友D跟自己申请了,因为自己是个喜新厌旧的家伙,同意与D沟通了,所以驴友C的决定自己不会同意,等着D一会儿要发过来的决定吧。
总结:
- acceptor,喜新厌旧,永远仅和编号大的进入第二阶段,并且在第二阶段编号大的proposor可以改变acceptor之前已经确定的值
- proposor,后者认同前者。当有超过半数的acceptor确定了相同的值,proposor直接采用这个值。如果没有超过半数,则取最新更新的值,重新提交
- 超过半数,少数服从多数,这个其实非常关键,proposor向acceptor发送prepare和accept消息,其实不用等待所有acceptor的回应,只要超过半数回应则可,这样即便有1/2个acceptor出现故障(只要还剩下超过半数以上),则流程可以继续下去,不会发生堵塞情况。
一致性问题的理解
关于Paxos说的一致性,个人理解是指冗余副本(或状态等,但都是因为存在冗余)的一致性。这与关系型数据库中ACID的一致性说的不是一个东西。在关系数据库里,可以连副本都没有,何谈副本的一致性?按照经典定义,ACID中的C指的是在一个事务中,事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。那么,什么又是一致性状态呢,这跟业务约束有关系,比如经典的转账事务,事务处理完毕后,不能出现一个账户钱被扣了,另一个账户的钱没有增加的情况,如果两者加起来的钱还是等于转账前的钱,那么就是一致性状态。
CAP原则里面所说的一致 性,个人认为是指副本一致性,与Paxos里面的一致性接近。都是处理“因为冗余数据的存在而需要保证多个副本保持一致”的问题,NoSQL放弃的强一致 性也是指副本一致性,最终一致性也是指副本达到完全相同存在一定延时。
zookeeper一致性协议:zab
ZooKeeper为高可用的一致性协调框架,使用的是ZAB协议作为数据一致性的算法,ZAB(ZooKeeper Atomic Broadcast )全称为:原子消息广播协议。zab协议中,可以看到paxos和两阶段提交协议的影子,下面详细论述zab协议。
3个角色
leader、follower、learner,follower参与leader的选举,learner不参与leader的选举,仅从leader同步数据。
读操作可以从任何一个节点获取,当然不一定获取到最新的,写操作,client如果连接到follower上,会被重定向到leader,写操作都是通过leader节点完成的。
3个阶段
选举leader,成为leader的node条件
- 选
epoch最大的
epoch相等,选 zxid 最大的
epoch和zxid都相等,选择serverid最大的(serverid是我们配置zoo.cfg中的myid)
节点在选举开始都默认投票给自己,当接收其他节点的选票时,会根据上面的条件更改自己的选票并重新发送选票给其他节点,当有一个节点的得票超过半数,该节点会设置自己的状态为 leading,其他节点会设置自己的状态为 following。
同步数据,当leader选举出来之后,follower则从leader同步数据。注意两个点。
- 由于leader是具有最大zxid的节点,所以其应该是在上一个leader崩溃之后,具有最新数据的节点。
- 一个事务有两个阶段,proposor和commit,follower需要根据leader的最新数据,commit leader已经commit,而自己未commit的数据,同时删除那些leader未commit的数据。
消息广播,可以理解为少数服从多数的两阶段提交协议,这个阶段其实可以看成是只有一个proposor的paxos协议。
3个状态
ZAB协议中存在着三种状态,每个节点都属于以下三种中的一种:
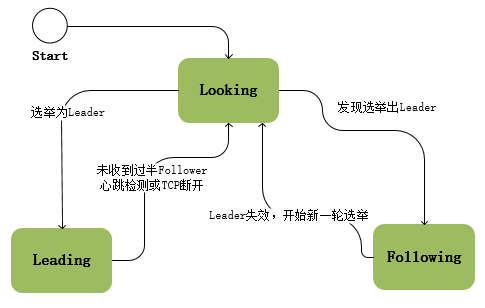
- Looking:系统刚启动时或者Leader崩溃后正处于选举状态
- Following:Follower节点所处的状态,Follower与Leader处于数据同步阶段;
- Leading:Leader所处状态,当前集群中有一个Leader为主进程;
ZooKeeper启动时所有节点初始状态为Looking,这时集群会尝试选举出一个Leader节点,选举出的Leader节点切换为Leading状态;当节点发现集群中已经选举出Leader则该节点会切换到Following状态,然后和Leader节点保持同步;当Follower节点与Leader失去联系时Follower节点则会切换到Looking状态,开始新一轮选举;当leader节点未收到过半follower心跳检测或tcp断开,leader节点转换为looking状态。在ZooKeeper的整个生命周期中每个节点都会在Looking、Following、Leading状态间不断转换;
quorum
集群中超过半数的节点集合,在paxos和zab协议中,经常会用到超过半数的方法,超过半数同意,则可以选举出leader,超过半数同意,则可以完成事务提交。
一个主要的目的就是防止少于半数的节点出现故障,block业务流程,反向说,只要有一半以上的节点工作正常,整个集群的工作就是正常的。
再考虑另一个场景,整个zookeeper集群部署在2个机房,共5个节点,3个在机房1,2个在机房2,一旦两个机房之间网络出现故障,就会造成脑裂、数据不一致的问题,但是超过半数则可以解决这个问题,位于机房2的2个节点,由于无法与机房1通信,则无法产生leader,而机房1由于可以达到超过半数(3个)节点的同意,可以选举出leader,所以机房1可以正常对外提供服务,当机房间网络恢复正常,机房2由于发现已经存在leader,则将角色变更为follower,主动从leader同步遗失数据,则可以继续正常对外提供数据。
zxid
在 ZAB 协议的事务编号 Zxid 设计中,Zxid 是一个 64 位的数字,其中低 32 位是一个简单的单调递增的计数器,针对客户端每一个事务请求,计数器加 1;而高 32 位则代表 Leader 周期 epoch 的编号,每次当选的新的 Leader 服务器,就会从这个 Leader 服务器上取出其本地日志中最大事务的ZXID,并从中读取 epoch 值,然后加 1,以此作为新的 epoch,并将低 32 位从 0 开始计数。epoch:可以理解为当前集群所处的年代或者周期,每个 leader 就像皇帝,都有自己的年号,所以每次改朝换代,leader 变更之后,都会在前一个年代的基础上加 1。这样就算旧的 leader 崩溃恢复之后,也没有人听他的了,因为 follower 只听从当前年代的 leader 的命令。
zab paxos 2pc的对比
zab和paxos对比,paxos由于有多个proposor,所以存在活锁的问题,但是zab仅有一个leader充当proposor的角色,解决了活锁的问题,同时引入leader选举,解决了单点的问题
zab和2pc的对比,两阶段提交协议,有其无法解决的缺点,如block、单点、数据不一致,
- block解决,zab可以看成是一个少数服从多数的两阶段提交协议。通过超过一半节点通过,就可以完成事务的提交,有少量节点down掉,不影响整体流程,不会像2pc一直block某个节点的ack。zab如果一段时间后,超过半数的节点没有ack,才会有问题,这个时候则需要重新选举leader
- 单点故障的解决,通过引入leader选举,当leader挂掉,会重新选举新的leader
- 数据不一致的解决,2pc由于脑裂的问题,会导致数据不一致,而zab其实就是单个proposor的paxos协议,paxos本身就是为了解决一致性问题设计的,所以也不存在一致性的问题。
参考文章
http://blog.xiaohansong.com/2016/08/25/zab/?utm_source=tuicool&utm_medium=referral
《从PAXOS到ZOOKEEPER分布式一致性原理与实践》
http://www.lxway.com/4618606.htm















 3018
3018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









