Nosql
redis 主从复制(读写分离)
- 具体操作
- 在redis的路径下找到sentinel.conf
- 修改配置文件

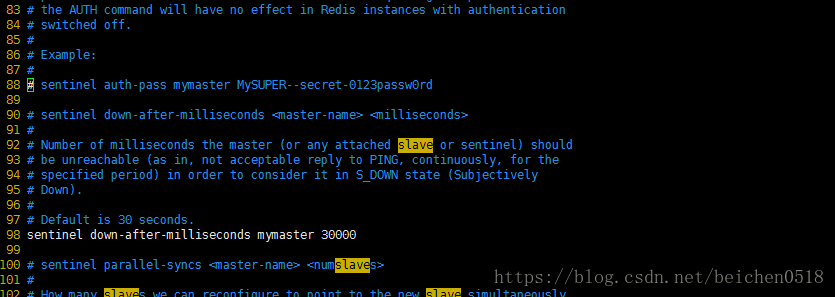
- 第69行设置主人的ip 和端口 以及选举是晋升主人需要的票数
- 第71行设置主人的密码,以便哨兵和主人保持连接
- 第98行设置主人崩溃多长时间后重选主人
- 启动哨兵
- redis sentinel.conf –sentinel
- 在实际工作,会有一个负载均衡器,一个负载均衡器下面有多个节点,而一组主从复制的redis,只是其中的一个节点,我们在程序中连接redis是连接负载均衡器的地址。这样我们就不用担心,更换master时更换地址
- 负载均衡
- 硬件:F5/A10
- 软件:
- Nginx + 负载均衡算法
- LVS
- 避免单点故障
- 负载均衡+双活
- Keepalived:就相当于Redis的Sentinel
from hashlib import sha1
from urllib.parse import urljoin
import pickle
import re
import requests
import zlib
from bs4 import BeautifulSoup
from redis import Redis
def main():
base_url = 'https://www.zhihu.com/'
seed_url = urljoin(base_url, 'explore')
client = Redis(host='1.2.3.4', port=6379, password='1qaz2wsx')
headers = {'user-agent': 'Baiduspider'}
resp = requests.get(seed_url, headers=headers)
soup = BeautifulSoup(resp.text, 'lxml')
href_regex = re.compile(r'^/question')
hasher_proto = sha1()
for a_tag in soup.find_all('a', {'href': href_regex}):
href = a_tag.attrs['href']
full_url = urljoin(base_url, href)
hasher = hasher_proto.copy()
hasher.update(full_url.encode('utf-8'))
field_key = hasher.hexdigest()
if not client.hexists('zhihu', field_key):
html_page = requests.get(full_url, headers=headers).text
zipped_page = zlib.compress(pickle.dumps(html_page))
client.hset('zhihu', field_key, zipped_page)
print('Total %d question pages found.' % client.hlen('zhihu'))
client.expire('zhihu', 500)
if __name__ == '__main__':
main()
推送服务
- PC端 - websocket / SockJS / STOMP
- 移动端 - 第三方平台(极光、百度、小米、友盟)
Mongodb
"""
# mongodb基本操作
- use 数据库名
- db.student.find()
- db.student.insert({})
- db.student.find({'age':{'gt':25, 'lt':30}}) 找到年龄大于25小于30的
前面是筛选条件,后面是要添加或修改的内容,如果有这个键,就修改,没有就添加
- db.student.update({'_id': 12},{'$set':{'tel': 1233}})
"""
import pymongo
def main():
client = pymongo.MongoClient(host='47.98.172.171', port=27017)
db = client.zhihu
print(client)
pages_cache = db.webpages
page_id = pages_cache.insert_one({'url': 'http:www.baidu.com'})
print(page_id.inserted_id)
pages_cache.insert_many([
{'_id': 1, 'url': 'http://www.baidu.com ',
'content': 'shit'},
{'_id': 2, 'url': 'http://www.qq.com ',
'content': 'another shit'},
{'_id': 3, 'url': 'http://www.qfedu.com ',
'content': 'biggest shit'}
])
print(pages_cache.update({'_id': 5}, {'$set': {'content': 'hello, world!'}}, upsert=True))
print(pages_cache.find().count())
for doc in pages_cache.find().sort('_id'):
print(doc)
pages_cache.insert_one({
'url': 'http://www.baidu.com',
'content': 'bull shit!',
'owner': {
'name': 'Lee Yanhong',
'age': 50,
'idcard': '110220196804091203'
}
})
if __name__ == '__main__':
main()






















 585
585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









