







数据丢失和如何保障数据不丢失
数据丢失的情况:
producer端
1、设置acks=all
acks=0:producer把消息发送出去了,就确认发送成功了,但是如果此时leader分区宕机了,根本没有接收这条消息,或者还没有写入日志,导致数据丢失
acks=1:producer把消息发送出去了,leader分区收到并写入日志,,就确认发送成功了,但是如果此时leader分区宕机了,根本没有把这条消息同步给follower分区,follower分区后续继续选举了一个新的leader分区,新leader分区并没有这条新数据,导致数据丢失
acks=all:当leader分区收到并写入日志,及同步给follower分区之后,再确认消息发送成功
2、producer: 异步批量发送
一般情况下,为了提高吞吐量,发消息会实行异步批量发送,

这样做有一个风险,当buffer里面有很多数据的时候,此时producer宕机了,会把buffer里面的数据给丢失了,导致数据丢失
保障不丢失措施:
1、把异步改成同步
kafkaTemplate.send("testTopic",gson.toJson(message));改成:
Future future = kafkaTemplate.send("testTopic",gson.toJson(message));
future.get();2、不要使用producer.send(msg),而要使用producer.send(msg, callback)。在callback回调函数 中可以把发送失败的消息给保存下来,进行下一次发送
3、设置retries ,当网络发生抖动,配置了retries > 0的producer能够自动重试消息发送,避免消息丢失。
broker端:
- 设置副本数>1,如果副本数=1,则就算acks=all ,也可以会造成数据丢失
- unclean.leader.election.enable 设置为 true,选举从ISR列表中选举
comsumer端:
自动提交是当消费者poll过来了,就自动提交offset给broker,如果此时消费者接收到了数据,并没有做处理的时候,突然消费者当前的机器宕机了,导致还没对这条数据做处理(保存数据库或者其他计算),最终丢失了
1、设置enable.auto.commit=false 在处理完这条数据后,手动提交offset
2、设置auto-offset-reset 为 earliest
这个参数指定了在没有偏移量可提交时(比如消费者第l次启动时)或者请求的偏移量在broker上不存在时(比如数据被删了),消费者会做些什么。
这个参数有两种配置。一种是earliest:消费者会从分区的开始位置读取数据,不管偏移量是否有效,这样会导致消费者读取大量的重复数据,但可以保证最少的数据丢失。一种是latest(默认),如果选择了这种配置, 消费者会从分区的末尾开始读取数据,这样可以减少重复处理消息,但很有可能会错过一些消息。
消息的有序性
1、kafka的特性是只支持partition有序,之前在生产者讲分区选择的时候,可以指定key的方式发送数据 ,可以用业务id,作为key,达到业务上的有序
2、如果业务需要部分数据有序,除了只建立一个分区外,则可以在消费端添加缓存,根据消息先后顺序的字段进行判断,如果A,B两条数据,如果非要B在A之后执行,则如果先pull消息B,则业务逻辑判断,A是否被消费,如果未被消费,则把B放进缓存,则pull消息A过来的时候,消费去缓存中看有没有B,如有,则消费B
重复消费
1、 比如消费者手动提交的时候,处理完这条消息,但是在进行手动提交的时候,突然宕机了,并没有修改broker中的offset值
2、当有人估计把broker中保存offset的topic给删掉的时候,我们没法知道当前分区的offset 是什么,只有从头再读一遍,会造成大量重复消息
3、在自动提交情况下,消费者提交offset不是消费一条就进行提交的,而是按一定的时间周期进行提交的(auto_commit_interval_ms 参数进行设置),如果正好在这个时间之内,服务器宕机了,就导致offset没有更新,当消费者启动的时候,会重复消费之前的数据
解决办法是:
1、本地保存处理完消息的offset 值,每条消息都带有一个offset,在表设计的时候,可以topic 分区 offset三维度区设计
2、消费数据的幂等性,可以定义消息的唯一属性,如果数据库存在唯一性的消息就不进行处理或者更新处理
消息堆积
修改副本数
在server.properties中配置:
# 自动创建主题 auto.create.topics.enable=true # 默认主题的分区数 num.partitions=3 # 默认分区副本 default.replication.factor=3
kafka数据文件过多,经常导致磁盘占满的问题
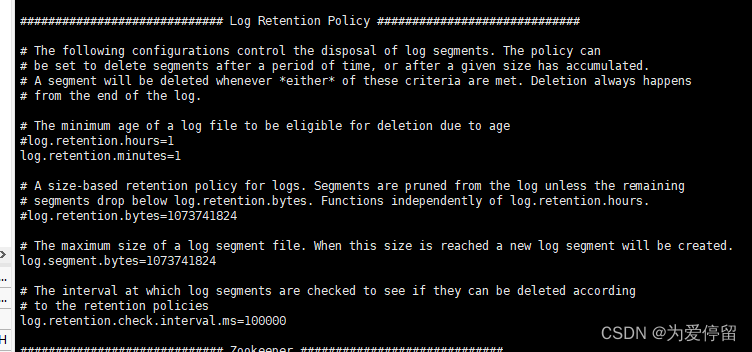
其中只要调整两个参数就可以了:
1、log.retention.hours=168默认是7天,保存已消费的数据的时间
2、log.retention.check.interval.ms=300000 默认是间隔5分钟,把标记删除的消息物理删除
当消费速度不高或者7天内有大量数据推到kafka,则上述配置就有可能把本地磁盘占满,则需要修改保存数据的周期,如:
log.retention.minutes=10
log.retention.check.interval.ms=100000
就是就会去把在集群中已经逗留10分钟以上,且已消费的消息标记成已删除,100s周期性的会把标记已删除的日志数据物理删除
如下:已消费的数据
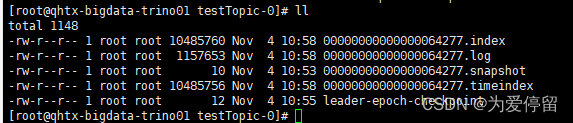
把已消费的数据标记成已删除
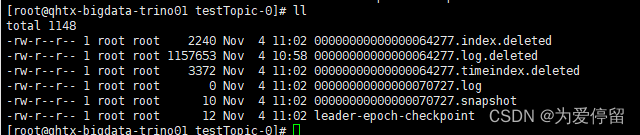
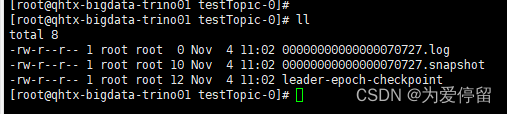
物理删除已标记删除的数据,释放空间















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









