







React组件命名推荐的方式是哪个?
通过引用而不是使用来命名组件displayName。
使用displayName命名组件:
export default React.createClass({
displayName: 'TodoApp', // ...})
React推荐的方法:
export default class TodoApp extends React.Component {
// ...}
mobox 和 redux 有什么区别?
(1)共同点
- 为了解决状态管理混乱,无法有效同步的问题统一维护管理应用状态;
- 某一状态只有一个可信数据来源(通常命名为store,指状态容器);
- 操作更新状态方式统一,并且可控(通常以action方式提供更新状态的途径);
- 支持将store与React组件连接,如react-redux,mobx- react;
(2)区别 Redux更多的是遵循Flux模式的一种实现,是一个 JavaScript库,它关注点主要是以下几方面∶
-
Action∶ 一个JavaScript对象,描述动作相关信息,主要包含type属性和payload属性∶
o type∶ action 类型; o payload∶ 负载数据; -
Reducer∶ 定义应用状态如何响应不同动作(action),如何更新状态;
-
Store∶ 管理action和reducer及其关系的对象,主要提供以下功能∶
o 维护应用状态并支持访问状态(getState()); o 支持监听action的分发,更新状态(dispatch(action)); o 支持订阅store的变更(subscribe(listener)); -
异步流∶ 由于Redux所有对store状态的变更,都应该通过action触发,异步任务(通常都是业务或获取数据任务)也不例外,而为了不将业务或数据相关的任务混入React组件中,就需要使用其他框架配合管理异步任务流程,如redux-thunk,redux-saga等;
Mobx是一个透明函数响应式编程的状态管理库,它使得状态管理简单可伸缩∶
- Action∶定义改变状态的动作函数,包括如何变更状态;
- Store∶ 集中管理模块状态(State)和动作(action)
- Derivation(衍生)∶ 从应用状态中派生而出,且没有任何其他影响的数据
对比总结:
- redux将数据保存在单一的store中,mobx将数据保存在分散的多个store中
- redux使用plain object保存数据,需要手动处理变化后的操作;mobx适用observable保存数据,数据变化后自动处理响应的操作
- redux使用不可变状态,这意味着状态是只读的,不能直接去修改它,而是应该返回一个新的状态,同时使用纯函数;mobx中的状态是可变的,可以直接对其进行修改
- mobx相对来说比较简单,在其中有很多的抽象,mobx更多的使用面向对象的编程思维;redux会比较复杂,因为其中的函数式编程思想掌握起来不是那么容易,同时需要借助一系列的中间件来处理异步和副作用
- mobx中有更多的抽象和封装,调试会比较困难,同时结果也难以预测;而redux提供能够进行时间回溯的开发工具,同时其纯函数以及更少的抽象,让调试变得更加的容易
shouldComponentUpdate有什么用?为什么它很重要?
组件状态数据或者属性数据发生更新的时候,组件会进入存在期,视图会渲染更新。在生命周期方法 should ComponentUpdate中,允许选择退出某些组件(和它们的子组件)的和解过程。
和解的最终目标是根据新的状态,以最有效的方式更新用户界面。如果我们知道用户界面的某一部分不会改变,那么没有理由让 React弄清楚它是否应该更新渲染。通过在 shouldComponentUpdate方法中返回 false, React将让当前组件及其所有子组件保持与当前组件状态相同。
对React SSR的理解
服务端渲染是数据与模版组成的html,即 HTML = 数据 + 模版。将组件或页面通过服务器生成html字符串,再发送到浏览器,最后将静态标记"混合"为客户端上完全交互的应用程序。页面没使用服务渲染,当请求页面时,返回的body里为空,之后执行js将html结构注入到body里,结合css显示出来;
SSR的优势:
- 对SEO友好
- 所有的模版、图片等资源都存在服务器端
- 一个html返回所有数据
- 减少HTTP请求
- 响应快、用户体验好、首屏渲染快
1)更利于SEO
不同爬虫工作原理类似,只会爬取源码,不会执行网站的任何脚本使用了React或者其它MVVM框架之后,页面大多数DOM元素都是在客户端根据js动态生成,可供爬虫抓取分析的内容大大减少。另外,浏览器爬虫不会等待我们的数据完成之后再去抓取页面数据。服务端渲染返回给客户端的是已经获取了异步数据并执行JavaScript脚本的最终HTML,网络爬中就可以抓取到完整页面的信息。
2)更利于首屏渲染
首屏的渲染是node发送过来的html字符串,并不依赖于js文件了,这就会使用户更快的看到页面的内容。尤其是针对大型单页应用,打包后文件体积比较大,普通客户端渲染加载所有所需文件时间较长,首页就会有一个很长的白屏等待时间。
SSR的局限:
1)服务端压力较大
本来是通过客户端完成渲染,现在统一到服务端node服务去做。尤其是高并发访问的情况,会大量占用服务端CPU资源;
2)开发条件受限
在服务端渲染中,只会执行到componentDidMount之前的生命周期钩子,因此项目引用的第三方的库也不可用其它生命周期钩子,这对引用库的选择产生了很大的限制;
3)学习成本相对较高 除了对webpack、MVVM框架要熟悉,还需要掌握node、 Koa2等相关技术。相对于客户端渲染,项目构建、部署过程更加复杂。
时间耗时比较:
1)数据请求
由服务端请求首屏数据,而不是客户端请求首屏数据,这是"快"的一个主要原因。服务端在内网进行请求,数据响应速度快。客户端在不同网络环境进行数据请求,且外网http请求开销大,导致时间差
-
客户端数据请求
-
服务端数据请求
2)html渲染 服务端渲染是先向后端服务器请求数据,然后生成完整首屏 html返回给浏览器;而客户端渲染是等js代码下载、加载、解析完成后再请求数据渲染,等待的过程页面是什么都没有的,就是用户看到的白屏。就是服务端渲染不需要等待js代码下载完成并请求数据,就可以返回一个已有完整数据的首屏页面。
-
非ssr html渲染
-
ssr html渲染
React 的工作原理
React 会创建一个虚拟 DOM(virtual DOM)。当一个组件中的状态改变时,React 首先会通过 “diffing” 算法来标记虚拟 DOM 中的改变,第二步是调节(reconciliation),会用 diff 的结果来更新 DOM。
React-Router如何获取URL的参数和历史对象?
(1)获取URL的参数
- get传值
路由配置还是普通的配置,如:'admin',传参方式如:'admin?id='1111''。通过this.props.location.search获取url获取到一个字符串'?id='1111' 可以用url,qs,querystring,浏览器提供的api URLSearchParams对象或者自己封装的方法去解析出id的值。
- 动态路由传值
路由需要配置成动态路由:如path='/admin/:id',传参方式,如'admin/111'。通过this.props.match.params.id 取得url中的动态路由id部分的值,除此之外还可以通过useParams(Hooks)来获取
- 通过query或state传值
传参方式如:在Link组件的to属性中可以传递对象{pathname:'/admin',query:'111',state:'111'};。通过this.props.location.state或this.props.location.query来获取即可,传递的参数可以是对象、数组等,但是存在缺点就是只要刷新页面,参数就会丢失。
(2)获取历史对象
- 如果React >= 16.8 时可以使用 React Router中提供的Hooks
import {
useHistory } from "react-router-dom";
let history = useHistory();
2.使用this.props.history获取历史对象
let history = this.props.history;
参考 前端进阶面试题详细解答
React的虚拟DOM和Diff算法的内部实现
传统 diff 算法的时间复杂度是 O(n^3),这在前端 render 中是不可接受的。为了降低时间复杂度,react 的 diff 算法做了一些妥协,放弃了最优解,最终将时间复杂度降低到了 O(n)。
那么 react diff 算法做了哪些妥协呢?,参考如下:
- tree diff:只对比同一层的 dom 节点,忽略 dom 节点的跨层级移动
如下图,react 只会对相同颜色方框内的 DOM 节点进行比较,即同一个父节点下的所有子节点。当发现节点不存在时,则该节点及其子节点会被完全删除掉,不会用于进一步的比较。
这样只需要对树进行一次遍历,便能完成整个 DOM 树的比较。
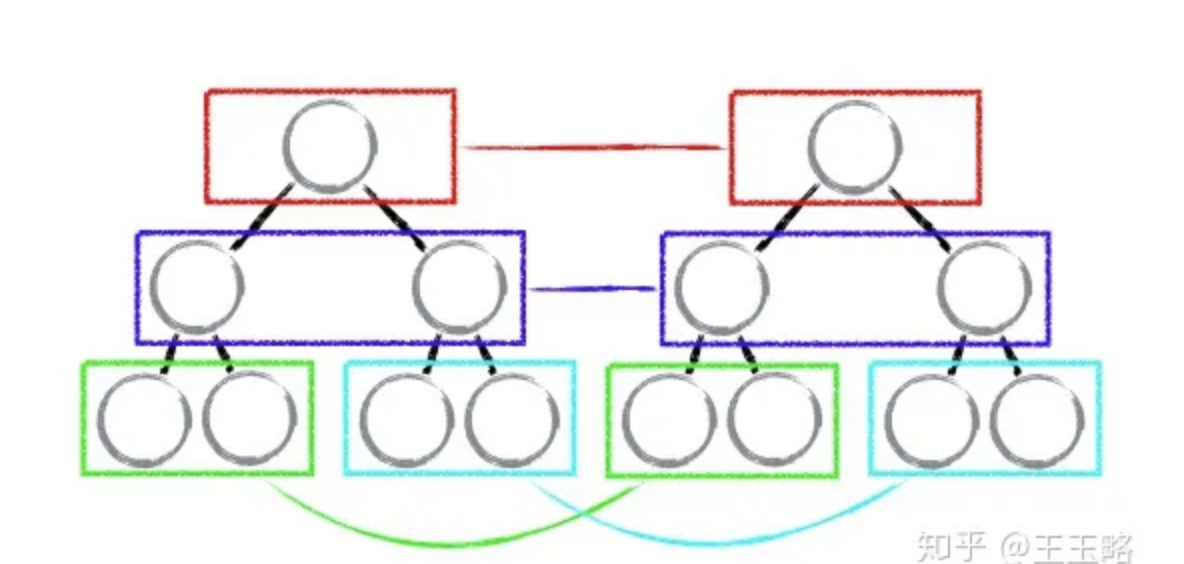
这就意味着,如果 dom 节点发生了跨层级移动,react 会删除旧的节点,生成新的节点,而不会复用。
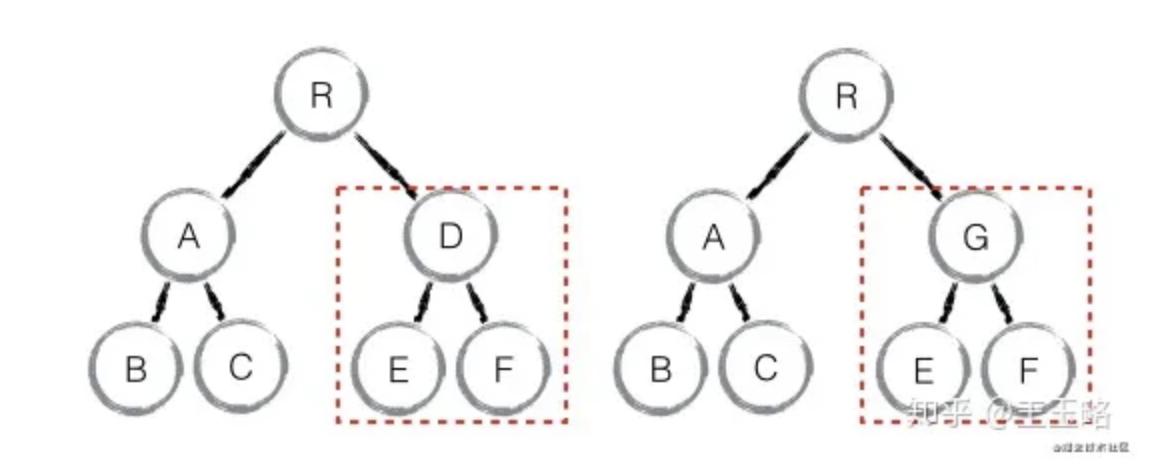
- component diff:如果不是同一类型的组件,会删除旧的组件,创建新的组件
- element diff:对于同一层级的一组子节点,需要通过唯一 id 进行来区分
- 如果没有 id 来进行区分,一旦有插入动作,会导致插入位置之后的列表全部重新渲染
- 这也是为什么渲染列表时为什么要使用唯一的 key。
如何使用4.0版本的 React Router?
React Router 4.0版本中对 hashHistory做了迁移,执行包安装命令 npm install react-router-dom后,按照如下代码进行使用即可。
import {
HashRouter, Route, Redirect, Switch } from " react-router-dom";
class App extends Component {
render() {
return (
<div>
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 7261
7261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









