







文章目录
Java8总结
Java 8 新特性简介
-
速度更快
- 修改底层数据结构:如HashMap(数组-链表-红黑树),HashSet,ConcurrentHashMap(CAS算法)
- 修改垃圾回收机制:取消堆中的永久区(PremGen)->回收条件苛刻,使用元空间(MetaSpace)->直接使用物理内存->加载类文件
-
代码更少(增加了新的语法Lambda表达式)
-
强大的Stream API
-
便于并行
-
最大化减少空指针异常 Optional容器类
1 Lambda表达式
Java8中引入了一个新的操作符”->” 该操作符称为箭头操作符或Lambda操作符,箭头操作符将Lambda表达式拆分成两部分:
左侧:Lambda 表达式的参数列表
右侧:Lambda 表达式中所需执行的功能,即 Lambda 体
Lambda表达式需要“函数式接口”的支持
只包含一个抽象方法的接口,称为 函数式接口。
你可以通过 Lambda 表达式来创建该接口的对象。(若 Lambda表达式抛出一个受检异常,那么该异常需要在目标接口的抽象方法上进行声明)。
我们可以在任意函数式接口上使用 @FunctionalInterface 注解,这样做可以检查它是否是一个函数式接口,同时 javadoc 也会包含一条声明,说明这个接口是一个函数式接口。
作为参数传递 Lambda 表达式:为了将 Lambda 表达式作为参数传递,接收 Lambda 表达式的参数类型必须是与该 Lambda 表达式兼容的函数式接口的类型。
语法格式一:无参数,无返回值
()->System.out.println(“Hello Lambda!”);
@Test
public void test1(){
//通过匿名内部类的方式实现接口
Runnable r=new Runnable() {
@Override
public void run() {
System.out.println("Hello World!");
}
};
r.run();
System.out.println("----------------------");
//匿名内部类用代替匿名内部类
Runnable r1=()->System.out.println("Hello Lambda!");
r1.run();
}
语法格式二:有一个参数,并且无返回值
(x)->System.out.println(x);
@Test
public void test2(){
Consumer<String> con=(x)->System.out.println(x);//对Consumer接口中有一个参数的accept方法的实现
con.accept("啦啦啦");
}
语法格式三:若只有一个参数,小括号可以不写
x->System.out.println(x);
语法格式四:有两个以上的参数,有返回值,并且Lambda体中有多条语句
@Test
public void test3(){
Comparator<Integer> com=(x,y)->{
System.out.println("函数式接口");
return Integer.compare(x, y);
};
}
语法格式五:若Lambda体中只有一条语句,大括号和 return 都可以省略不写
@Test
public void test4(){
Comparator<Integer> com=(x,y)->Integer.compare(x, y);
}
语法格式六:Lambda表达式的参数列表的数据类型可以省略不写,因为JVM编译器通过上下文推断出,数据类型,即“类型推断”
(Integer x,Integer y)->Integer.compare(x,y);
总结:
左右遇一括号省
左侧推断类型省
2 强大的 Stream API
Stream 是 Java8 中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。使用Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数据库查询。也可以使用 Stream API 来并行执行操作。简而言之,Stream API 提供了一种高效且易于使用的处理数据的方式。
什么是 Stream
流 (Stream) 到底是什么呢 ?
是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。“集合讲的是数据,流讲的是计算! ”
注意:
①Stream 自己不会存储元素。
②Stream 不会改变源对象。相反,他们会返回一个持有结果的新Stream。
③Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行。
Stream的操作三步骤
-
创建Stream
一个数据源(如:集合、数组),获取一个流 -
中间操作
一个中间操作链,对数据源的数据进行处理 -
终止操作(终端操作)
一个终止操作,执行中间操作链,并产生结果
创建Stream
1.可以通过Collection 系列集合提供的stream()或parallelStream()方法
- default Stream< E> stream() : 返回一个顺序流
- default Stream< E> parallelStream() : 返回一个并行流
2.通过 Arrays 中的静态方法stream()获取数组流
- static < T> Stream< T> stream(T[] array): 返回一个流
重载形式,能够处理对应基本类型的数组:
- public static IntStream stream(int[] array)
- public static LongStream stream(long[] array)
- public static DoubleStream stream(double[] array)
3.通过Stream 类中的静态方法of(),通过显示值创建一个流。它可以接收任意数量的参数。
- public static< T> Stream< T> of(T… values) : 返回一个流
4.创建无限流
可以使用静态方法 Stream.iterate() 和Stream.generate(), 创建无限流。
- 迭代
public static< T> Stream< T> iterate(final T seed, final UnaryOperator< T> f) - 生成
public static< T> Stream< T> generate(Supplier< T> s)
中间操作
多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理!而在终止操作时一次性处理,成为“惰性求值”。
1.筛选与切片
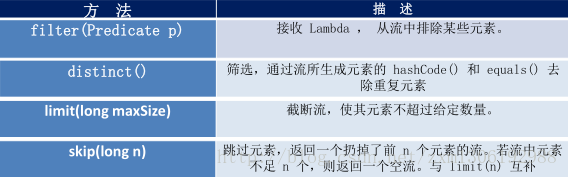
2.映射
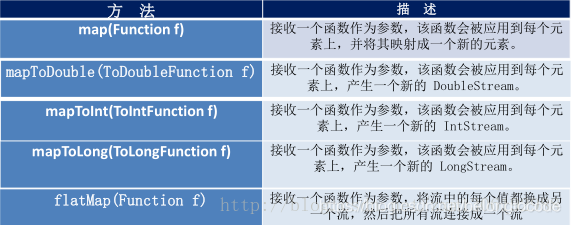
3.排序

终止操作
终止操作会从流水线生成结果。其结果可以是任何不是流的值,例如:List、Integer,甚至是void。
1.查找与匹配
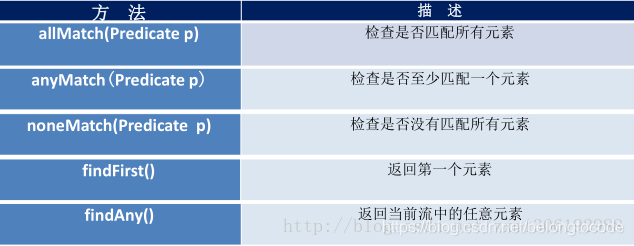

2.归约

备注:map和reduce的连接通常称为map-reduce 模式,因google用它来进行网络搜索而出名。
3.收集

Collector接口中方法的实现决定了如何对流执行收集操作(如收集到List、Set、Map)。但是Collectors实用类提供了很多静态方法,可以方便地创建常见收集器实例,具体方法与实例如下表:


3 并行流与串行流
并行流就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流。
Java 8 中将并行进行了优化,我们可以很容易的对数据进行并行操作。Stream API 可以声明性地通过 parallel() 与 sequential() 在并行流与顺序流之间进行切换。
了解 Fork/Join 框架
Fork/Join 框架:就是在必要的情况下,将一个大任务,进形拆分(fork)成若干个小任务(拆到不可再拆时),再将一个个的小任务运行的结果进行join汇总。
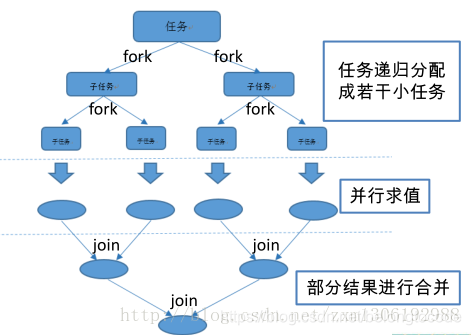
Fork/Join 框架与传统线程池的区别:
采用“工作窃取”模式(work-stealing):
当执行新的任务时,它可以将其拆分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随机线程的队列中偷一个并把它放在自己的队列中。
相对于一般的线程池实现,fork/join框架的优势体现在对其中包含的任务的处理方式上.在一般的线程池中,如果一个线程正在执行的任务由于某些原因无法继续运行,那么该线程会处于等待状态.而在fork/join框架实现中,如果某个子问题由于等待另外一个子问题的完成而无法继续运行.那么处理该子问题的线程会主动寻找其他尚未运行的子问题来执行.这种方式减少了线程的等待时间,提高了性能。
4 Optional类
Optional< T>类(java.util.Optional) 是一个容器类,代表一个值存在或不存在。
原来用null表示一个值不存在,现在 Optional可以更好的表达这个概念。并且可以避免空指针异常。
常用方法:
Optional.of(T t) : 创建一个 Optional 实例
Optional.empty() : 创建一个空的 Optional 实例
Optional.ofNullable(T t):若 t 不为 null,创建 Optional 实例,否则创建空实例
isPresent() : 判断是否包含值
orElse(T t) : 如果调用对象包含值,返回该值,否则返回t
orElseGet(Supplier s) :如果调用对象包含值,返回该值,否则返回 s 获取的值
map(Function f): 如果有值对其处理,并返回处理后的Optional,否则返回 Optional.empty()
flatMap(Function mapper):与 map 类似,要求返回值必须是Optional
5 接口中的默认方法与静态方法
以前接口类中只允许有全局静态常量和抽象方法
1、Java8中允许接口中包含具有具体实现的方法,该方法称为“默认方法”,默认方法使用 default 关键字修饰。
接口默认方法的“类优先”原则:
若一个接口中定义了一个默认方法,而另一个父类或接口中又定义了一个同名的方法时
- 选择父类中的方法。如果一个父类提供了具体的实现,那么接口中具有相同名称和参数的默认方法会被忽略。
- 接口冲突。如果一个父接口提供一个默认方法,而另一个接口也提供了一个具有相同名称和参数列表的方法(不管方法是否是默认方法),那么必须覆盖该方法来解决冲突。
2、Java8 中,接口中允许添加静态方法。
6 重复注解与类型注解
Java8 对注解处理提供了两点改进:可重复的注解及可用于类型的注解。
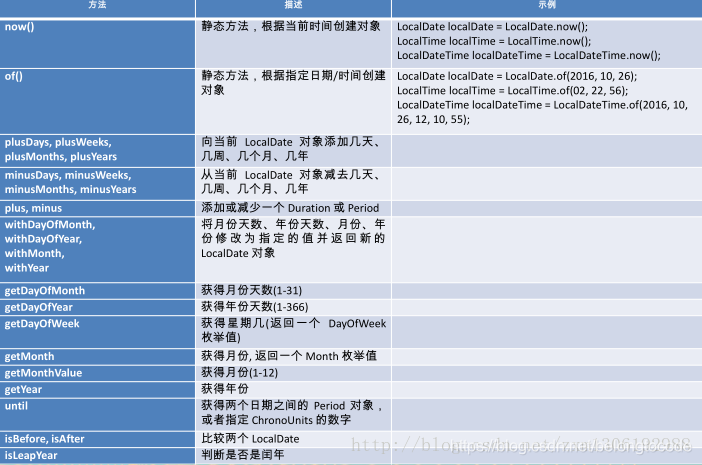
7 新时间日期API
以前的时间API是线程不安全的,是可变的
多线程对日期进行处理要加锁
LocalDate、LocalTime、LocalDateTime 类的实例是不可变的对象,分别表示使用 ISO-8601日历系统的日期、时间、日期和时间。它们提供了简单的日期或时间,并不包含当前的时间信息。也不包含与时区相关的信息。
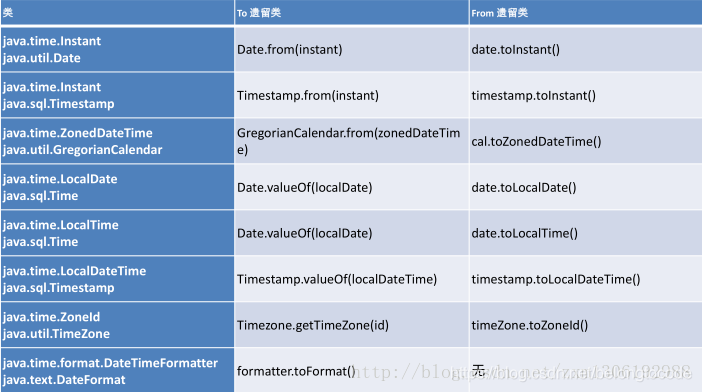
与传统日期处理的转换
8 List、Map变化
可以采用forEach遍历输出
List<String> testList=new ArrayList<>();
testList.add("aa");
testList.add("bb");
testList.forEach(str-> System.out.println(str));
Map<String,String> testMap=new HashMap<>();
testMap.put("11", "aa");
testMap.put("22", "bb");
testMap.forEach((key,value)-> System.out.println(key+": "+value));
Map变化:
putIfAbsent 方法
方法原型 V putIfAbsent(K key, V value) , 如果 key 不存在或相关联的值为 null, 则设置新的 key/value 值。
computeIfPresent 方法
方法原型 V computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction),如果指定的 key 存在并且相关联的 value 不为 null 时,根据旧的 key 和 value 计算 newValue 替换旧值,newValue 为 null 则从 map 中删除该 key; key 不存在或相应的值为 null 时则什么也不做,方法的返回值为最终的 map.get(key)。
computeIfAbsent 方法
方法原型 V computeIfAbsent(K key, Function<? super <, ? extends V> mappingFunction), 与上一个方法相反,如果指定的 key 不存在或相关的 value 为 null 时,设置 key 与关联一个计算出的非 null 值,计算出的值为 null 的话什么也不做(不会去删除相应的 key)。如果 key 存在并且对应 value 为 null 的话什么也不做。同样,方法的返回值也是最终的 map.get(key)。
replace(K key, V value) 方法
只要 key 存在,不管对应值是否为 null,则用传入的 value 替代原来的值。即使传入的 value 是 null 也会用来替代原来的值,而不是删除,注意这对于 value 不能为 null 值的 Map 实现将会造成 NullPointerException。key 不存在不会修改 Map 的内容,返回值总是原始的 map.get(key) 值。
replace(K key, V oldValue, V newValue)
当且仅当 key 存在,并且对应值与 oldValue 不相等,才用 newValue 作为 key 的新相关联值,返回值为是否进行了替换。
replaceAll 方法
方法原型 void replaceAll(BiFunction<? super K, ? super V, ? extends V> function)。它更像一个传统函数型语言的 map 函数,即对于 Map 中的每一个元素应用函数 function, 输入为 key 和 value。
getOrDefault 方法
如果指定的key存在,则返回该key对应的value,
如果不存在,则返回指定的值。
compute 方法
方法原型 V compute(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction), 它是 computeIfAbsent 与 computeIfPresent 的结合体。也就是既不管 key 存不存在,也不管 key 对应的值是否为 null, compute 死活都要设置与 key 相关联的值,或者计算出的值为 null 时删除相应的 key, 返回值为最终的 map.get(key)。
merge 方法
方法原型 V merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFucntion),这是至今来说比较神秘的一个方法,尚未使用到它。如果指定的 key 不存在,或相应的值为 null 时,则设置 value 为相关联的值。否则根据 key 对应的旧值和 value 计算出新的值 newValue,newValue 为 null 时,删除该key, 否则设置 key 对应的值为 newValue。方法的返回值也是最终的 map.get(key) 值。
Map.Entry comparingByKey 和 comparingByValue 方法
另外介绍一下 Map.Entry 新加的两个排序方法,它们分别有无参与带 Comparator 参数可嵌套使用的两个版本。comparingByKey(), comparingByKey(Comparator<? super K> cmp), comparingByValue() 和 comparingByValue(Comparator<? super V> cmp)。
Java8 Stream排序
很多情况下sql不好解决的多表查询,临时表分组,排序,尽量用java8新特性stream进行处理
使用java8新特性,下面先来点基础的
List<类> list; 代表某集合
//1、返回 对象集合以类属性一升序排序
list.stream().sorted(Comparator.comparing(类::属性一));
//2、返回 对象集合以类属性一降序排序 注意两种写法
//2.1、先以属性一升序,结果进行属性一降序
list.stream().sorted(Comparator.comparing(类::属性一).reversed());
//2.2、以属性一降序
list.stream().sorted(Comparator.comparing(类::属性一,Comparator.reverseOrder()));
//3、返回 对象集合以类属性一升序 属性二升序
list.stream().sorted(Comparator.comparing(类::属性一).thenComparing(类::属性二));
//4、返回 对象集合以类属性一降序 属性二升序 注意两种写法
//4.1、先以属性一升序,升序结果进行属性一降序,再进行属性二升序
list.stream().sorted(Comparator.comparing(类::属性一).reversed().thenComparing(类::属性二));
//4.2、先以属性一降序,再进行属性二升序
list.stream().sorted(Comparator.comparing(类::属性一,Comparator.reverseOrder()).thenComparing(类::属性二));
//5、返回 对象集合以类属性一降序 属性二降序 注意两种写法
//5.1、先以属性一升序,升序结果进行属性一降序,再进行属性二降序
list.stream().sorted(Comparator.comparing(类::属性一).reversed().thenComparing(类::属性二,Comparator.reverseOrder()));
//5.2、先以属性一降序,再进行属性二降序
list.stream().sorted(Comparator.comparing(类::属性一,Comparator.reverseOrder()).thenComparing(类::属性二,Comparator.reverseOrder()));
//6、返回 对象集合以类属性一升序 属性二降序 注意两种写法
//6.1、先以属性一升序,升序结果进行属性一降序,再进行属性二升序,结果进行属性一降序属性二降序
list.stream().sorted(Comparator.comparing(类::属性一).reversed().thenComparing(类::属性二).reversed());
//6.2、先以属性一升序,再进行属性二降序<br><br><br>
list.stream().sorted(Comparator.comparing(类::属性一).thenComparing(类::属性二,Comparator.reverseOrder()));
通过以上例子我们可以发现
-
Comparator.comparing(类::属性一).reversed();
-
Comparator.comparing(类::属性一,Comparator.reverseOrder());
两种排序是完全不一样的,一定要区分开来
1 、是得到排序结果后再排序,2、是直接进行排序,很多人会混淆导致理解出错,2更好理解,建议使用2
Java8 时间计算
1.Period类
主要是Period类方法getYears(),getMonths()和getDays()来计算.
示例:
package insping;
import java.time.LocalDate;
import java.time.Month;
import java.time.Period;
public class Test {
public static void main(String[] args) {
LocalDate today = LocalDate.now();
System.out.println("Today : " + today);
LocalDate birthDate = LocalDate.of(1993, Month.OCTOBER, 19);
System.out.println("BirthDate : " + birthDate);
Period p = Period.between(birthDate, today);
System.out.printf("年龄 : %d 年 %d 月 %d 日", p.getYears(), p.getMonths(), p.getDays());
}
}
结果:
Today : 2017-06-16
BirthDate : 1993-10-19
年龄 : 23 年 7 月 28 日
2.Duration
提供了使用基于时间的值(如秒,纳秒)测量时间量的方法。
示例:
package insping;
import java.time.Duration;
import java.time.Instant;
public class Test {
public static void main(String[] args) {
Instant inst1 = Instant.now();
System.out.println("Inst1 : " + inst1);
Instant inst2 = inst1.plus(Duration.ofSeconds(10));
System.out.println("Inst2 : " + inst2);
System.out.println("Difference in milliseconds : " + Duration.between(inst1, inst2).toMillis());
System.out.println("Difference in seconds : " + Duration.between(inst1, inst2).getSeconds());
}
}
结果:
Inst1 : 2017-06-16T07:46:45.085Z
Inst2 : 2017-06-16T07:46:55.085Z
Difference in milliseconds : 10000
Difference in seconds : 10
3.ChronoUnit类
ChronoUnit类可用于在单个时间单位内测量一段时间,例如天数或秒。
以下是使用between()方法来查找两个日期之间的区别的示例。
package insping;
import java.time.LocalDate;
import java.time.Month;
import java.time.temporal.ChronoUnit;
public class Test {
public static void main(String[] args) {
LocalDate startDate = LocalDate.of(1993, Month.OCTOBER, 19);
System.out.println("开始时间 : " + startDate);
LocalDate endDate = LocalDate.of(2017, Month.JUNE, 16);
System.out.println("结束时间 : " + endDate);
long daysDiff = ChronoUnit.DAYS.between(startDate, endDate);
System.out.println("两天之间的差在天数 : " + daysDiff);
}
}
结果:
开始时间 : 1993-10-19
结束时间 : 2017-06-16
两天之间的差在天数 : 8641
4.until()
1、LocalDate提供了until()方法,计算了两个日期之间的年、月和日的周期
示例代码:
LocalDate localDate1 = LocalDate.parse("2017-08-28");
LocalDate LocalDate2 = LocalDate.parse("2018-09-30");
int years = localDate1.until(LocalDate2).getYears();
int months = localDate1.until(LocalDate2).getMonths();
int days = localDate1.until(LocalDate2).getDays();
System.out.println("间隔:"+years + " years," + months + " months and " + days + " days");
这种计算场景适合于计算某两个日期间的完整间隔时间,比如两日期间间隔的几年几个月零几天,但是如果就计算两个日期间间隔多少天,使用date1.until(date2).getDays()就不适合了,如果是第二种,则下面的方法适合。
2、LocalDate提供了until(Temporal endExclusive, TemporalUnit unit),计算两个日期间距离:
示例代码:
LocalDate start = LocalDate.parse("2018-08-28");
LocalDate end = LocalDate.parse("2018-09-30");
long year = start.until(end, ChronoUnit.YEARS);
long month = start.until(end, ChronoUnit.MONTHS);
long days = start.until(end, ChronoUnit.DAYS);
System.out.println("间隔:" + year + "年");
System.out.println("间隔:" + month + "月");
System.out.println("间隔:" + days + "天");
运行结果:
间隔:0年
间隔:1月
间隔:33天
Java8两个List集合计算
取交集、并集、差集、去重并集
import java.util.ArrayList;
import java.util.List;
import static java.util.stream.Collectors.toList;
public class Test {
public static void main(String[] args) {
List<String> list1 = new ArrayList<String>();
list1.add("1");
list1.add("2");
list1.add("3");
list1.add("5");
list1.add("6");
List<String> list2 = new ArrayList<String>();
list2.add("2");
list2.add("3");
list2.add("7");
list2.add("8");
// 交集
List<String> intersection = list1.stream().filter(item -> list2.contains(item)).collect(toList());
System.out.println("---交集 intersection---");
intersection.parallelStream().forEach(System.out :: println);
// 差集 (list1 - list2)
List<String> reduce1 = list1.stream().filter(item -> !list2.contains(item)).collect(toList());
System.out.println("---差集 reduce1 (list1 - list2)---");
reduce1.parallelStream().forEach(System.out :: println);
// 差集 (list2 - list1)
List<String> reduce2 = list2.stream().filter(item -> !list1.contains(item)).collect(toList());
System.out.println("---差集 reduce2 (list2 - list1)---");
reduce2.parallelStream().forEach(System.out :: println);
// 并集
List<String> listAll = list1.parallelStream().collect(toList());
List<String> listAll2 = list2.parallelStream().collect(toList());
listAll.addAll(listAll2);
System.out.println("---并集 listAll---");
listAll.parallelStream().forEachOrdered(System.out :: println);
// 去重并集
List<String> listAllDistinct = listAll.stream().distinct().collect(toList());
System.out.println("---得到去重并集 listAllDistinct---");
listAllDistinct.parallelStream().forEachOrdered(System.out :: println);
System.out.println("---原来的List1---");
list1.parallelStream().forEachOrdered(System.out :: println);
System.out.println("---原来的List2---");
list2.parallelStream().forEachOrdered(System.out :: println);
}
}
Java8 Stream根据对象属性去重
写一个自定义的方法:distinctByKey()
主要采用map的putIfAbsent
putIfAbsent 方法
- 传统的put方法,只要key存在,value值就会被覆盖,注意put方法返回的是put之前的值,如果无put之前的值返回null
- putIfAbsent方法,只有在key不存在或者key为null的时候,value值才会被覆盖
public <T> Predicate<T> distinctByKey(Function<? super T, Object> keyExtractor) {
Map<Object, Boolean> seen = new ConcurrentHashMap<>();
return t -> seen.putIfAbsent(keyExtractor.apply(t), Boolean.TRUE) == null;
}
根据id去重:
List<TestListToMap> list1 = list.stream().filter(distinctByKey(l ->l.getId())).collect(Collectors.toList());
Java8 stream()与parallelStream(),for性能分析
- 当循环遍历中不需要进行数据库操作时,使用stream()或普通循环来遍历(根据实际业务情况来选择用哪个)。
- 当循环遍历中(多次循环,百次以上)需要进行数据库操作时,使用parallelStream()来遍历,但是要注意多线程安全。
- parallelStream()平均耗时是三者中最低的(针对非数据库操作),但是会有一个问题,因为使用parallelStream()要开放多线程和进行多线程间的切换,会消耗额外的资源,而且parallelStream()不是线程安全的,要进行额外的同步加锁操作。所以遍历时没有进行数据库操作的话,还是使用stream()和普通遍历吧。
Java8 parallelStream()使用不当引发的血案
众所周知,java8的新特性中出了lambda表达式之外最受人关注的还有stream一系列的api。
parallelStream是stream中的一个很受开发者喜欢的api,喜欢的同时,如果你使用不当也会造成一些在你看来莫名其妙的问题。
下面我就跟大家说一下在我是如何使用不当遇到那个让我感到奇怪的问题。
问题场景描述
1、我们的系统中使用了一个会话管理器的东西,就是利用ThreadLocal来制造了一个线程变量,存放每次请求的会话线程的线程变量。
2、有一个程序变量需要遍历取值,并且需要对其中的值和线程变量的值来做业务判断,进行处理.
3、之前使用Stream进行流操作,未发生任何异常.
问题发生情况描述
想使用parallelStream提升遍历性能,就将stream改成了parallelStream.
这时候重启调试之后,请求这个api,总是发生空指针的异常.
问题定位
1、因为使用了lambda表达式,所以控制台只是提示parallelStream的遍历这一行报错(这也是使用lambda的不便之处,调错没有之前方便)
2、使用debug一步步跟随调试,发现错误定位在了会话管理器获取线程变量这一行
问题思考
1、之前在使用stream这个API的时候没有发生问题,便思考到了是parallelStream的原因使得程序产生了问题.
2、那么parallelStream怎么会影响我们的会话管理器取得线程变量呢.
问题解决
1、查看parallelStream的源码

2、parallelStream是创建一个并行的Stream,而且他的并行操作是不具备线程传播性的,所以在使用会话管理器的时候是无法获取值的.
问题总结
parallelStream是一把双刃利器,他的并行操作可以在很多时候作为提升效率的一把利刃。但是使用的时候仍需要注意一些东西,以免伤到自己。
参考文章:
https://www.cnblogs.com/kuanglongblogs/p/11230250.html
https://www.cnblogs.com/snidget/p/11615321.html
https://blog.csdn.net/zls_1029/article/details/82930583
https://blog.csdn.net/weixin_33941350/article/details/91477207
https://blog.csdn.net/k15014428090/article/details/89963686
https://blog.csdn.net/csonst1017/article/details/86715772
https://www.jianshu.com/p/5a49b10f3cfd
Java8总结性文章:
https://blog.csdn.net/zxm1306192988/article/details/73744378
https://www.cnblogs.com/shenlanzhizun/articles/6027042.html
Java8Stream 分组分区:
https://segmentfault.com/a/1190000016586700















 17万+
17万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











