






摘要
第一部分吧是讲述如何爬取网页中自己想要的那部分数据,并且将数据有序的存入csv文件中;第二部分是如何批量爬取图片。其中包括一些库的导入、python的语法、正则表达式、数据处理、数据包和网页html的分析等,还有一些报错处理。写得比较杂乱,尽量理清楚。每一部分先放了效果图,然后是详细步骤。
下文的用到的代码上传至百度网盘:链接:https://pan.baidu.com/s/1-lTHwLO5pwmUGpal7f7mnQ
提取码:xwsp
案例一:爬虫的爬取数据(以豆瓣top250为例)
效果图:
包括该电影链接、电影首页图片、电影名称、评分、打分人数、引言
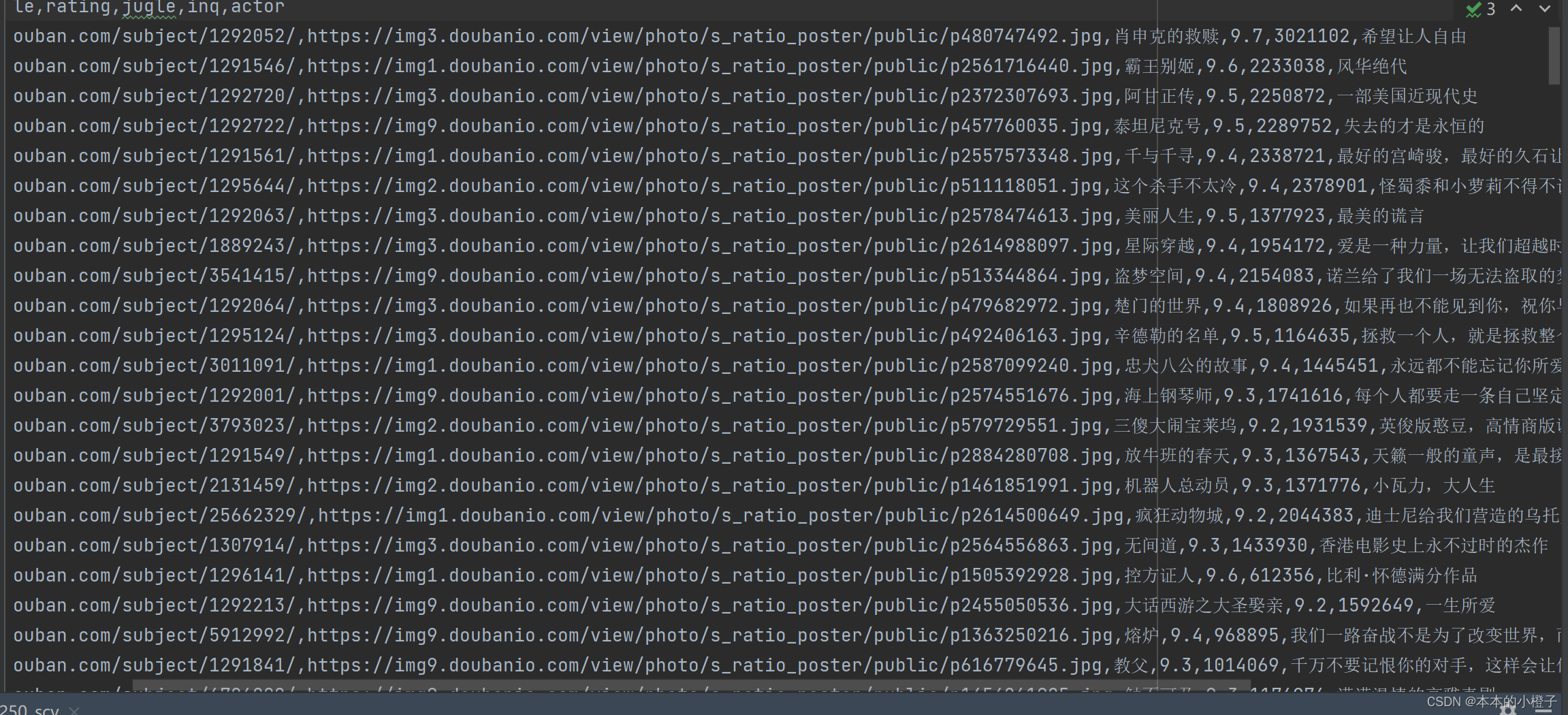
step1:发请求
给网页发送请求,查看返回的http状态码。如果是4××,那么大概率是因为网页拒绝连接,它看出了你是程序访问而不是浏览器;如果是200,那么ok可以成功访问页面。
import requests
response = requests.get(url)
print(response)tips:其中url是自己的要爬取网页的链接
step2:伪装
前一步大概率拒绝连接,那么我们将伪装成浏览器去访问页面,需要加一个headers,其中必须包含User-Agent,有时还需要包含Cookies等信息,按照需求添加。
import requests
headers={
"User-Agent":"×××"
}
response = requests.get(url, headers=headers)
print(response)
tips:其中的User-Agent、Cookies需要填写自己实时抓捕的网络包的值
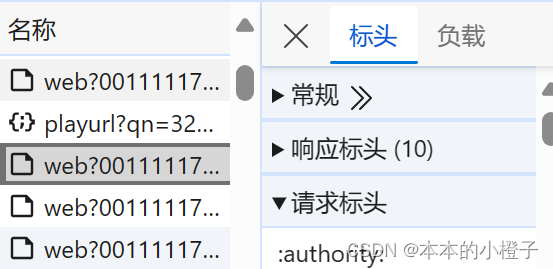
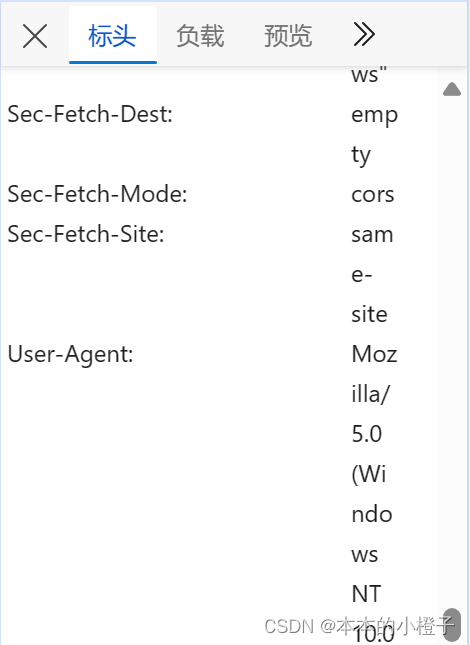
怎么找到User-Agent的值呢?
网页单击鼠标右键——点击“检查”选项——点击菜单栏中的“网络”选项——刷新页面——任意点击获取的一个包的标头的“请求标头”——找到User-Agent选项,复制后面的值放入以上代码×××处

step3:解析
将获取到的html网页进行解析,可以用Beautiful Soup来进行网页解析,也可以用json来解析(bs4我用的比较多,目前不太懂json解析和soup解析的区别,json总是报错,但是json会很方便后面会去学习)
json遇到的错误
报错:requests.exceptions.JSONDecodeError: Expecting value
解决方法:未解决,但不影响本案例
from bs4 import BeautifulSoup
html = response.text
soup = BeautifulSoup(html, "html.parser")
print(soup)
step4:提取
对解析好的文本进行分析,从它的标签入手,由外向里依次抽离去查找所需的数据。可以利用正则表达式来找到适合自己要找数据的匹配模板。
import re
f_link = re.compile(r'<a href="(.*?)">')
datalist=[]
for item in soup.find_all("div",attrs={"class":"item"}):
try:
data = []
item=str(item)
link=re.findall(f_link,item)[0]
data.append(link)
datalist.append(data)
except IndexError:
pass
continue
此处代码所用到的知识点:
1、find_all方法以及re的complie方法
find_all真的很好用,查看网页源代码元素时,很容易看出数据在哪个标签之下,但有时不太能分别所要提取数据的参数有什么共同点,这时就需要打印atters找出共同点;
re.complile方法是re.complie(r'xxxx'),其中xxxx部分就是正则表达式的书写。
举个栗子:我想对豆瓣电影排行榜的标题“对你的想象”、“哥斯拉”等进行提取,目前只能看出来是在<a a/>标签里面,但是没有参数约束会带来其他干扰项
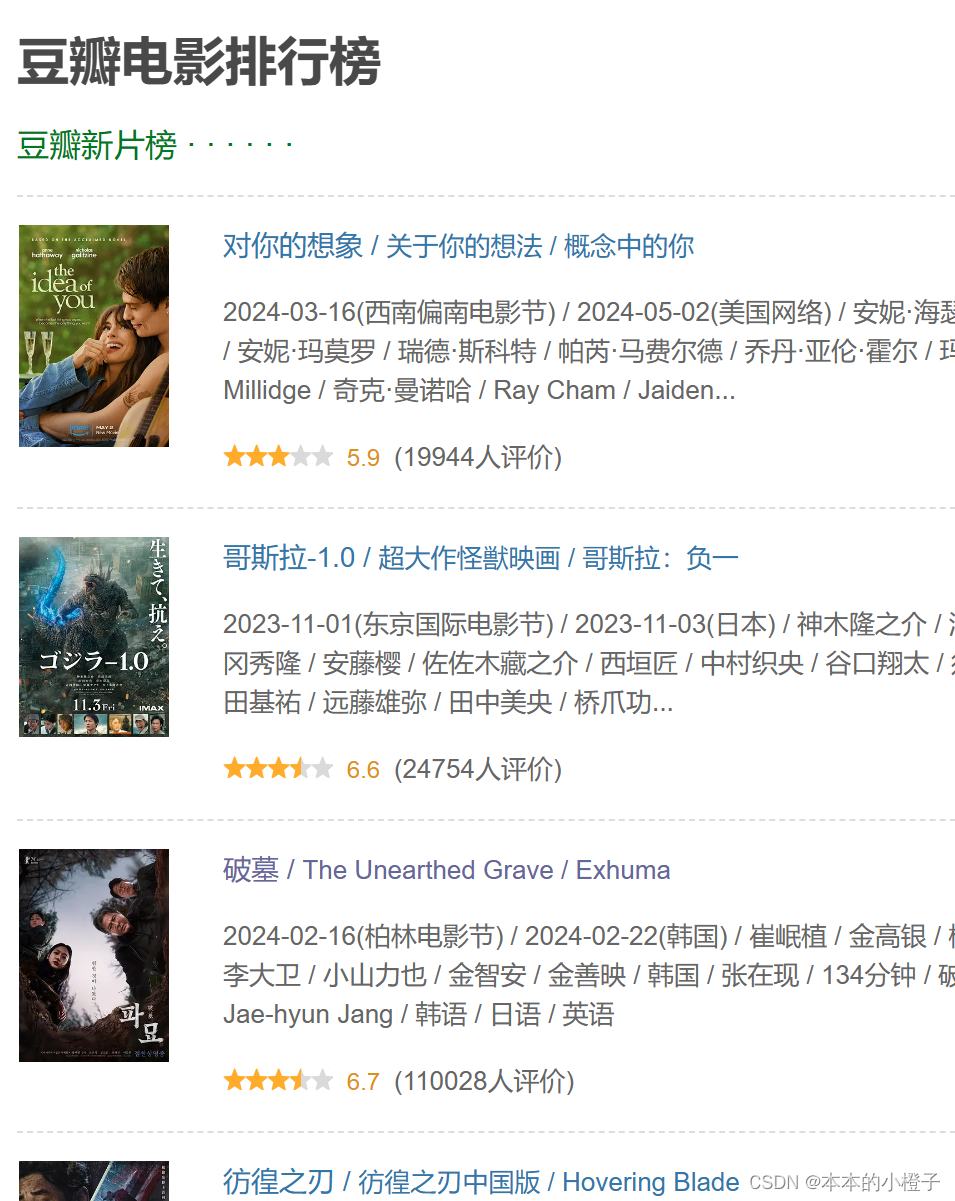

那么我想到了可以直接打印出<a /a>标签中的文本,此时可以看到还有其他多余文本。其中绿框是多余的,红框是目标。
all_title=soup.find_all("a",attrs={"class":""})
for title in all_title:
print(title)
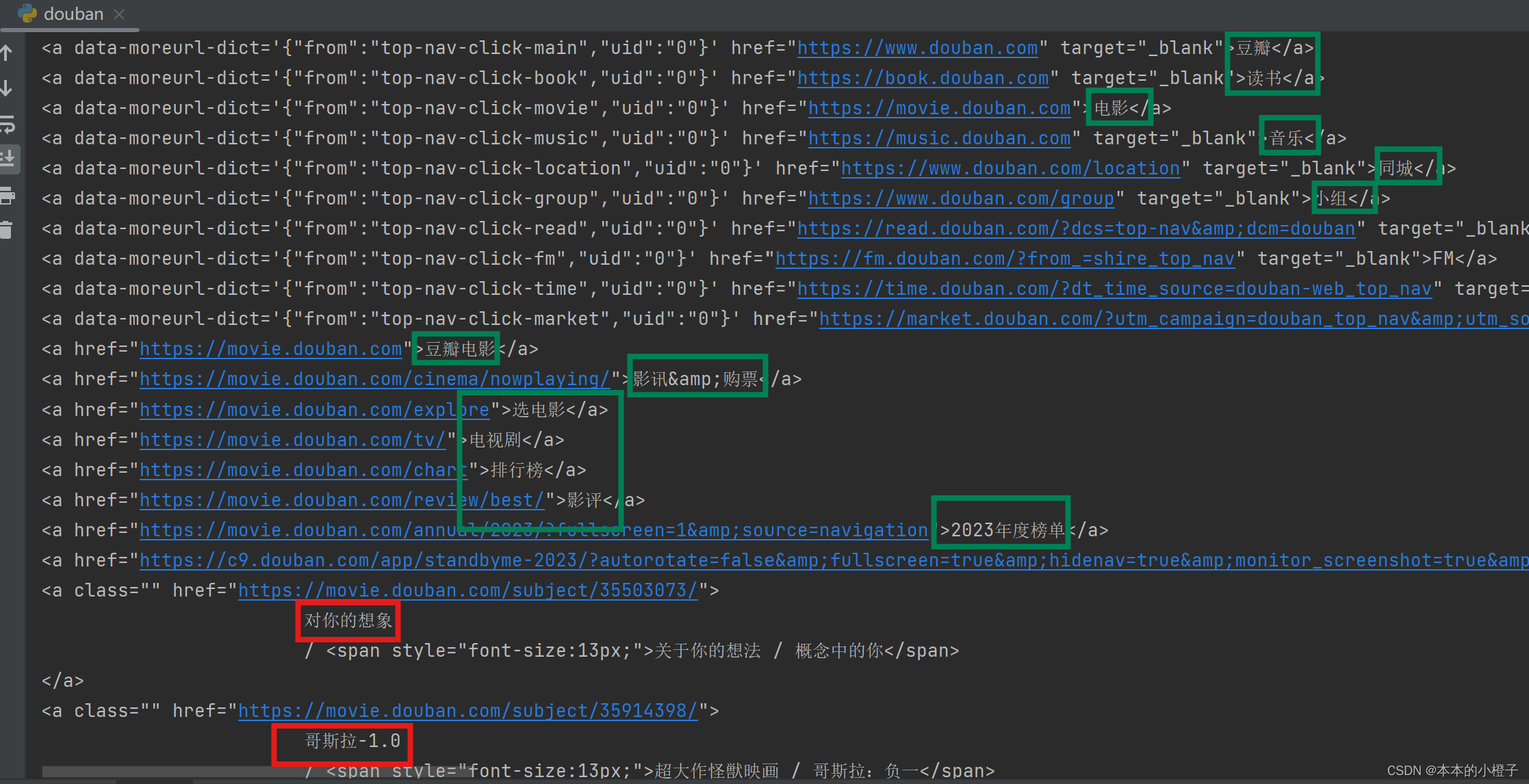
此时我又看不到该标签中的其他参数,但是发现目标标题前都有一行空格个,所以写了一个正则表达式,找出匹配的部分。re.findall(re.compile,text)其中re.compile是指自定义的模板,text是指需要匹配的文本(text必须是字符串),正则表达式的常见形式总结如下:
| \w | 数字字母下划线 |
| (?<=x)<re>(?=y) | 该字符前面挨着的是x,后边连着的是y |
| + | 一次性匹配多个字符 |
详细细教程参考:正则表达式学习笔记(超级详细!!!)| 有用的小知识-CSDN博客
all_title=soup.find_all("a",attrs={"class":""})
all_title = str(all_title)
all_title = re.findall(r'(?<= )\w.+', all_title)
for title in all_title:
print(title)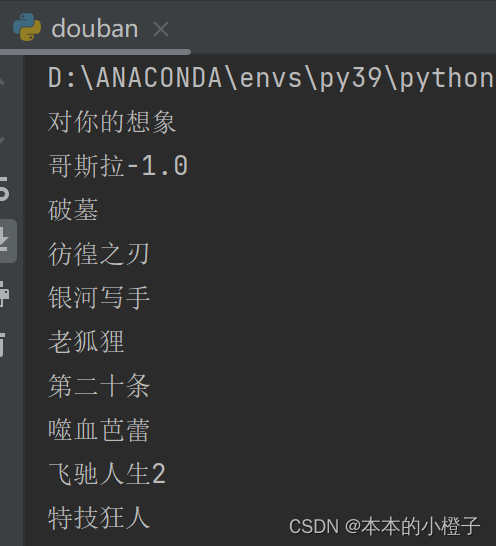
过了几天,发现了另一种更简便的方法,我找到<a /a>标签的所有参数值打印看了一下,惊奇的发现了它的参数class的值
all_titles=soup.find_all("a")
for i in all_titles:
print(i.attrs)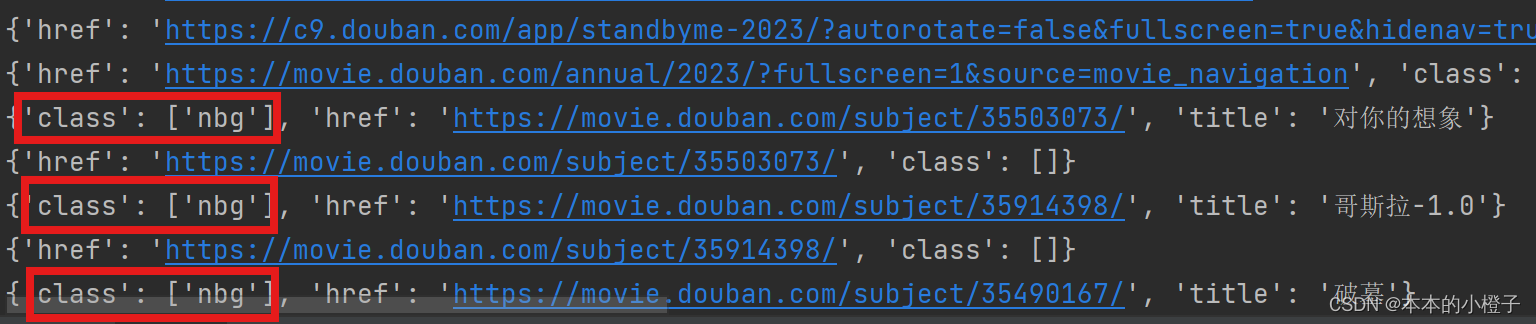
这个时候我在尝试给find_all方法加上参数,并且只打印文本部分,文本部分的参数是'title'
all_titles=soup.find_all("a",class_='nbg')
for i in all_titles:
print(i.attrs['title'])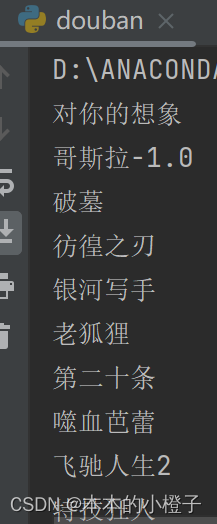
2、try...except...异常捕捉
爬取数据时经常遇到的情况就是IndexError,一方面可能是下标越界,数组定义不够大;另一方面可能是爬取到空元素,列表元素为空(更常见),此时只需要利用异常pass跳过就好了。
3、列表的用法:新建、添加新元素
lst=[]
lst.append()
双层嵌套列表
感觉我用到的列表操作都比较简单,后面还得好好研究一下列表、字典和元组的应用!!!
step5:保存
将获取的大量数据存放到xxx.csv、xxx.exl或xxx.txt等不同类型的文件中去
import csv
with open('./douban_top250.csv', 'w',encoding='utf-8', newline='') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=['link', 'imgsrc', 'title', 'rating','jugle', 'inq','actor'])
writer.writeheader()
writer = csv.writer(csvfile)
for row in datalist:
writer.writerow(row)
此处代码所用到的知识点:
1、文件的保存、打开
csv_file = open('xxx.csv', 'w', newline='', encoding='utf-8')
...
csv_file.close()参数的意义:第一个是文件名;第二个是操作模式(读/写);第三个是换行方式、第四个是编码
tips:打开文件的两种方式,一种是open(),最后必须clsoe()一下;另一种是with open,不用close()
2、csv如何写入表头,如何将数据一行一行写入
写入csv文件的的表头
writer = csv.DictWriter(csvfile, fieldnames=['xxx1','xxx2','xxx3'])
writer.writeheader()datalist是存放在大列表中的若干个小列表的数据,此时就要把大列表中的数据按照小列表一行逐行写入
writer = csv.writer(csvfile)
for row in datalist:
writer.writerow(row)step6:翻页
豆瓣top250有10页,按前面的方法,只能爬取当前第一页,所以要设置翻页
首先观察网页的url,有很多网页由于是get请求方法,所以能够再url上直接获得参数
下面分别是第一页、第二页的url,可以看到start不同,再找几个发现规律,每往后翻一页start+25


所以写出以下代码让start为按照一定规律变化的参数,从而实现所以页面的爬取:
for start_num in range(0,250,25):
url=f"https://movie.douban.com/top250?start={start_num}"
soup = get_html(url)案例二:爬虫爬取批量图片(以爬取b站综艺界面的图片为例)
效果图:
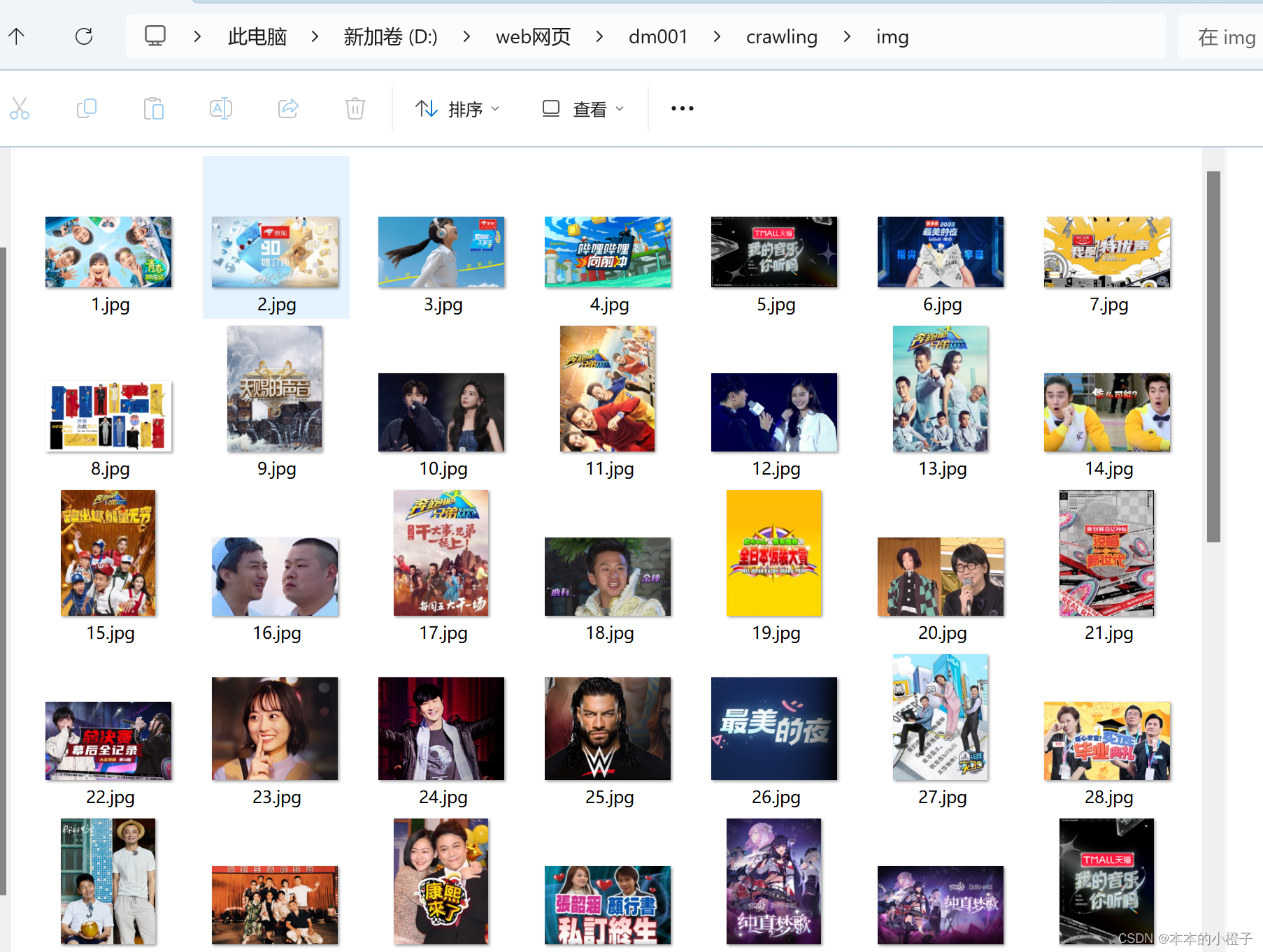
step1~step3:同案例一
step4:提取
这次的数据分析不是用re,而是用find_all方法来提取需要数据
all_picture=soup.find_all("img",attrs={"class":"img"})
lst_pic=[]
for pic in all_picture:
pic=pic['src']
lst_pic.append(pic)
for i,pic in enumerate(lst_pic):
lst_pic[i]='https:'+pic
return lst_pic
此处代码所用到的知识点:
1、enumerate()
在for循环中,有两个参数是要动态变化的,第一个是从头至尾遍历列表、字典等数据结构,第二个是从某个数字开始往后遍历直至第一个参数全部遍历完(其实作用就是给第一个列表中的各个元素一个编号)。举个栗子,interation是上述列表lst_pic,start默认从0开始(可以省略),这样一来就能给所有lst_pic中的元素改为合法url
for i item enumerate(iteration, start):
print(i,item)参考文章:enumerate函数详解-CSDN博客
2、为什么要在爬取的src前加http?
如果直接将图片的src当成图片链接去保存,可能会造成url无效报错。
报错:requests.exceptions.MissingSchema: Invalid URL
解决方案:url格式不合法,那么找出原因,是因为缺少前面的”http://“协议,依次加上就好
step5:保存
将爬取到的图片放到指定的文件夹下,并且要动态更新文件名,这样才能避免文件覆盖
dir_path = 'D:\web网页\dm001\crawling\img'
i=1
if not os.path.exists(dir_path):
os.makedirs(dir_path)
for pic in lst_pic:
img_path=os.path.join(dir_path,str(i)+'.jpg')
i+=1
res=requests.get(pic)
res_img=res.content
with open(img_path,'wb') as f:
f.write(res_img)此处代码所用到的知识点:
1、os模块的用法
os.path.exists(dir_path)判断该路径下的目录是否存在
os.makedirs(dir_path)如果该路径下的目录不存在,那么就自动创建一个(也可以手动在指定目录下新建)
os.path.join('xx1','xx2','xx3')拼接路径(字符串格式的)
参考文章:os.path.join()函数用法详解-CSDN博客
2、为什么图片保存的名称要有变量?
如果图片名称一模一样,那么图片爬取时就会不停的覆盖上一张图片,最终目录下只有一张图片,所以要不断改变图片名称
下一篇内容:
1、庆余年评论区的词云制作的总结
2、对于没有写清楚的内容再进行修改















 995
995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









