







Java集合工具包位于Java.util包下,包含了很多常用的数据结构,如数组、链表、栈、队列、集合、哈希表等。学习Java集合框架下大致可以分为如下五个部分:List列表、Set集合、Map映射、迭代器(Iterator、Enumeration)、工具类(Arrays、Collections)。
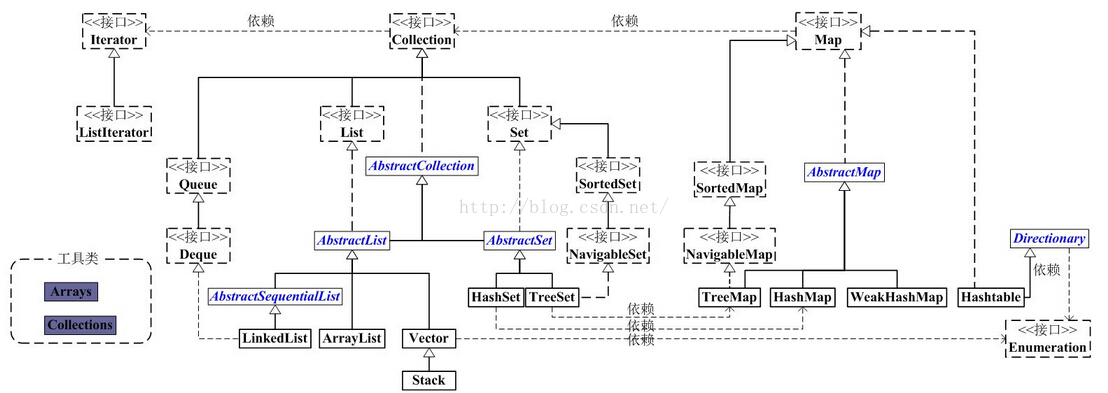
Java集合类的整体框架如下:
从上图中可以看出,集合类主要分为两大类:Collection和Map。
Collection是List、Set等集合高度抽象出来的接口,它包含了这些集合的基本操作,它主要又分为两大部分:List和Set。
List接口通常表示一个列表(数组、队列、链表、栈等),其中的元素可以重复,常用实现类为ArrayList和LinkedList,另外还有不常用的Vector。另外,LinkedList还是实现了Queue接口,因此也可以作为队列使用。
Set接口通常表示一个集合,其中的元素不允许重复(通过hashcode和equals函数保证),常用实现类有HashSet和TreeSet,HashSet是通过Map中的HashMap实现的,而TreeSet是通过Map中的TreeMap实现的。另外,TreeSet还实现了SortedSet接口,因此是有序的集合(集合中的元素要实现Comparable接口,并覆写Compartor函数才行)。 我们看到,抽象类AbstractCollection、AbstractList和AbstractSet分别实现了Collection、List和Set接口,这就是在Java集合框架中用的很多的适配器设计模式,用这些抽象类去实现接口,在抽象类中实现接口中的若干或全部方法,这样下面的一些类只需直接继承该抽象类,并实现自己需要的方法即可,而不用实现接口中的全部抽象方法。
Map是一个映射接口,其中的每个元素都是一个key-value键值对,同样抽象类AbstractMap通过适配器模式实现了Map接口中的大部分函数,TreeMap、HashMap、WeakHashMap等实现类都通过继承AbstractMap来实现,另外,不常用的HashTable直接实现了Map接口,它和Vector都是JDK1.0就引入的集合类。
Iterator是遍历集合的迭代器(不能遍历Map,只用来遍历Collection),Collection的实现类都实现了iterator()函数,它返回一个Iterator对象,用来遍历集合,ListIterator则专门用来遍历List。而 Enumeration则是JDK1.0时引入的,作用与Iterator相同,但它的功能比Iterator要少,它只能再Hashtable、Vector和Stack中使用。
Arrays和Collections是用来操作数组、集合的两个工具类,例如在ArrayList和Vector中大量调用了Arrays.Copyof()方法,而Collections中有很多静态方法可以返回各集合类的synchronized版本,即线程安全的版本,当然了,如果要用线程安全的结合类,首选Concurrent并发包下的对应的集合类。
ArrayList
ArrayList是基于数组实现的,是一个动态数组,其容量能自动增长,其动态增长机制是用底层的C语言动态申请内存实现的。
ArrayList不是线程安全的,只能在单线程环境下,多线程环境下可以考虑用collections.synchronizedList(List l)函数返回一个线程安全的ArrayList类,也可以使用concurrent并发包下的CopyOnWriteArrayList类。
ArrayList实现了Serializable接口,因此它支持序列化,能够通过序列化传输,实现了RandomAccess接口,支持快速随机访问,实际上就是通过下标序号进行快速访问,实现了Cloneable接口,能被克隆。
1、注意其三个不同的构造方法。无参构造方法构造的ArrayList的容量默认为0,带有Collection参数的构造方法,将Collection转化为数组赋给ArrayList的实现数组elementData。
2、注意扩充容量的方法ensureCapacity。ArrayList在每次增加元素(可能是1个,也可能是一组)时,都要调用该方法来确保足够的容量。当容量不足以容纳当前的元素个数时,就设置新的容量为旧的容量的1.5倍加1,如果设置后的新容量还不够,则直接新容量设置为传入的参数(也就是所需的容量),而后用Arrays.copyof()方法将元素拷贝到新的数组(详见下面的第3点)。从中可以看出,当容量不够时,每次增加元素,都要将原来的元素拷贝到一个新的数组中,非常之耗时,也因此建议在事先能确定元素数量的情况下,才使用ArrayList,否则建议使用LinkedList。
3、ArrayList的实现中大量地调用了Arrays.copyof()和System.arraycopy()方法。我们有必要对这两个方法的实现做下深入的了解。
首先来看Arrays.copyof()方法。它有很多个重载的方法,但实现思路都是一样的,我们来看泛型版本的源码:
public static <T> T[] copyOf(T[] original, int newLength) {
return (T[]) copyOf(original, newLength, original.getClass());
}
很明显调用了另一个copyof方法,该方法有三个参数,最后一个参数指明要转换的数据的类型,其源码如下:
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
这里可以很明显地看出,该方法实际上是在其内部又创建了一个长度为newlength的数组,调用System.arraycopy()方法,将原来数组中的元素复制到了新的数组中。
下面来看System.arraycopy()方法。该方法被标记了native,调用了系统的C/C++代码,在JDK中是看不到的,但在openJDK中可以看到其源码。该函数实际上最终调用了C语言的memmove()函数,因此它可以保证同一个数组内元素的正确复制和移动,比一般的复制方法的实现效率要高很多,很适合用来批量处理数组。Java强烈推荐在复制大量数组元素时用该方法,以取得更高的效率。
4. 注意ArrayList的两个转化为静态数组的toArray方法。
第一个,Object[] toArray()方法。该方法有可能会抛出java.lang.ClassCastException异常,如果直接用向下转型的方法,将整个ArrayList集合转变为指定类型的Array数组,便会抛出该异常,而如果转化为Array数组时不向下转型,而是将每个元素向下转型,则不会抛出该异常,显然对数组中的元素一个个进行向下转型,效率不高,且不太方便。
第二个, T[] toArray(T[] a)方法。该方法可以直接将ArrayList转换得到的Array进行整体向下转型(转型其实是在该方法的源码中实现的),且从该方法的源码中可以看出,参数a的大小不足时,内部会调用Arrays.copyOf方法,该方法内部创建一个新的数组返回,因此对该方法的常用形式如下:
public static Integer[] vectorToArray2(ArrayList<Integer> v) {
Integer[] newText = (Integer[])v.toArray(new Integer[0]);
return newText;
}
5.ArrayList基于数组实现,可以通过下标索引直接查找到指定位置的元素,因此查找效率高,但每次插入或删除元素,就要大量地移动元素,插入删除元素的效率低。
6.在查找给定元素索引值等的方法中,源码都将该元素的值分为null和不为null两种情况处理,ArrayList中允许元素为null。
LinkedList
LinkedList是基于双向循环链表(从源码中可以很容易看出)实现的,除了可以当作链表来操作外,它还可以当作栈,队列和双端队列来使用。
LinkedList同样是非线程安全的,只在单线程下适合使用。
LinkedList实现了Serializable接口,因此它支持序列化,能够通过序列化传输,实现了Cloneable接口,能被克隆。
1、从源码中很明显可以看出,LinkedList的实现是基于双向循环链表的,且头结点中不存放数据,如下图:
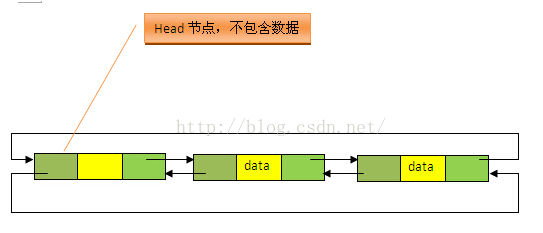
2、注意两个不同的构造方法。无参构造方法直接建立一个仅包含head节点(voidLink)的空链表,包含Collection的构造方法,先调用无参构造方法建立一个空链表,然后将Collection中的数据加入到链表的尾部后面。
3、在查找和删除某元素时,源码中都划分为该元素为null和不为null两种情况来处理,LinkedList中允许元素为null。
4、LinkedList是基于链表实现的,因此不存在容量不足的问题,所以这里没有扩容的方法。
5、注意源码中的public E get(int location) 方法。该方法返回双向链表中指定位置处的节点,而链表中是没有下标索引的,要指定位置出的元素,就要遍历该链表,从源码的实现中,我们看到这里有一个加速动作。源码中先将index与长度size的一半比较,如果indexsize/2,就只从位置size往前遍历到位置index处。这样可以减少一部分不必要的遍历,从而提高一定的效率(实际上效率还是很低)。
6、同过内部类LinkIterator、ReverseLinkIterator进行正向或反向遍历
7、LinkedList是基于链表实现的,因此插入删除效率高,查找效率低(虽然有一个加速动作)。
8、要注意源码中还实现了栈和队列的操作方法,因此也可以作为栈、队列和双端队列来使用。
HashMap
HashMap是基于哈希表实现的,每一个元素都是一个key-value对,其内部通过单链表解决冲突问题,容量不足(超过了阈值)时,同样会自动增长。
HashMap是非线程安全的,只是用于单线程环境下,多线程环境下可以采用concurrent并发包下的concurrentHashMap。
HashMap实现了Serializable接口,因此它支持序列化,实现了Cloneable接口,能被克隆。
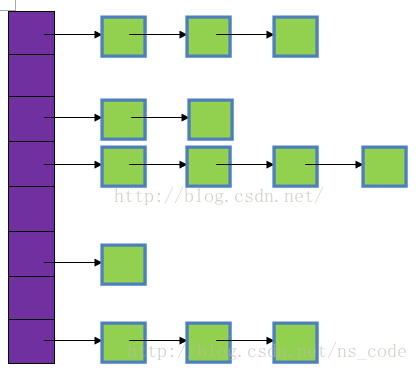
1、首先要清楚HashMap的存储结构,如下图所示:
图中,紫色部分即代表哈希表,也称为哈希数组,数组的每个元素都是一个单链表的头节点,链表是用来解决冲突的,如果不同的key映射到了数组的同一位置处,就将其放入单链表中。
2、首先看链表中节点的数据结构:
// HashMapEntry是单向链表。
// 它是 “HashMap链式存储法”对应的链表。
// 它实现了Entry 接口,即实现getKey(), getValue(), setValue(V value), equals(Object o), hashCode()这些函数
static class HashMapEntry<K, V> implements Entry<K, V> {
final K key;
V value;
final int hash;
HashMapEntry<K, V> next;
HashMapEntry(K key, V value, int hash, HashMapEntry<K, V> next) {
this.key = key;
this.value = value;
this.hash = hash;
this.next = next;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V value) {
V oldValue = this.value;
this.value = value;
return oldValue;
}
@Override public final boolean equals(Object o) {
if (!(o instanceof Entry)) {
return false;
}
Entry<?, ?> e = (Entry<?, ?>) o;
return Objects.equal(e.getKey(), key)
&& Objects.equal(e.getValue(), value);
}
@Override public final int hashCode() {
return (key == null ? 0 : key.hashCode()) ^
(value == null ? 0 : value.hashCode());
}
@Override public final String toString() {
return key + "=" + value;
}
}
它的结构元素除了key、value、hash外,还有next,next指向下一个节点。另外,这里覆写了equals和hashCode方法来保证键值对的独一无二。
3、HashMap共有四个构造方法。构造方法中提到了两个很重要的参数:初始容量和加载因子。
这两个参数是影响HashMap性能的重要参数,其中容量表示哈希表中槽的数量(即哈希数组的长度),初始容量是创建哈希表时的容量(从构造函数中可以看出,如果不指明,则默认为4),加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度,当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 resize 操作(即扩容)。
下面说下加载因子(DEFAULT_LOAD_FACTOR),如果加载因子越大,对空间的利用更充分,但是查找效率会降低(链表长度会越来越长);如果加载因子太小,那么表中的数据将过于稀疏(很多空间还没用,就开始扩容了),对空间造成严重浪费。如果我们在构造方法中不指定,则系统默认加载因子为0.75,这是一个比较理想的值,一般情况下我们是无需修改的。
另外,无论我们指定的容量为多少,构造方法都会将实际容量设为不小于指定容量的2的次方的一个数,且最大值不能超过2的30次方。
4、HashMap中key和value都允许为null。
5、要重点分析下HashMap中用的最多的两个方法put和get。先从比较简单的get方法着手,源码如下:
// 获取key对应的value
public V get(Object key) {
if (key == null) {
HashMapEntry<K, V> e = entryForNullKey;
return e == null ? null : e.value;
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
for (HashMapEntry<K, V> e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
return e.value;
}
}
return null;
}
首先,如果key为null,则直接从哈希表的第一个位置table[0]对应的链表上查找。记住,key为null的键值对永远都放在以table[0]为头结点的链表中,当然不一定是存放在头结点table[0]中。
如果key不为null,则先求的key的hash值,根据hash值找到在table中的索引,在该索引对应的单链表中查找是否有键值对的key与目标key相等,有就返回对应的value,没有则返回null。
put方法稍微复杂些,代码如下:
@Override public V put(K key, V value) {
if (key == null) {
return putValueForNullKey(value);
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
int index = hash & (tab.length - 1);
for (HashMapEntry<K, V> e = tab[index]; e != null; e = e.next) {
if (e.hash == hash && key.equals(e.key)) {
preModify(e);
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
// No entry for (non-null) key is present; create one
modCount++;
if (size++ > threshold) {
tab = doubleCapacity();
index = hash & (tab.length - 1);
}
addNewEntry(key, value, hash, index);
return null;
}
如果key为null,则将其添加到table[0]对应的链表中,putForNullKey的源码如下:
private V putValueForNullKey(V value) {
HashMapEntry<K, V> entry = entryForNullKey;
if (entry == null) {
addNewEntryForNullKey(value);
size++;
modCount++;
return null;
} else {
preModify(entry);
V oldValue = entry.value;
entry.value = value;
return oldValue;
}
}
如果key不为null,则同样先求出key的hash值,根据hash值得出在table中的索引,而后遍历对应的单链表,如果单链表中存在与目标key相等的键值对,则将新的value覆盖旧的value,比将旧的value返回,如果找不到与目标key相等的键值对,或者该单链表为空,则将该键值对插入到改单链表的头结点位置(每次新插入的节点都是放在头结点的位置),该操作是有addNewEntry方法实现的,它的源码如下:
void addNewEntry(K key, V value, int hash, int index) {
table[index] = new HashMapEntry<K, V>(key, value, hash, table[index]);
}
注意这里的构造方法,该方法也说明,每次put键值对的时候,总是将新的该键值对放在table[bucketIndex]处(即头结点处)。
另外注意put方法最后判断中的代码,每次加入键值对时,都要判断当前已用的槽的数目是否大于等于阀值(容量*加载因子),如果大于等于,则进行扩容(doubleCapacity),将容量扩为原来容量的2倍。
6、关于扩容。上面我们看到了扩容的方法,doubleCapacity方法,它的源码如下:
private HashMapEntry<K, V>[] doubleCapacity() {
HashMapEntry<K, V>[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
return oldTable;
}
int newCapacity = oldCapacity * 2;
HashMapEntry<K, V>[] newTable = makeTable(newCapacity);
if (size == 0) {
return newTable;
}
for (int j = 0; j < oldCapacity; j++) {
/*
* Rehash the bucket using the minimum number of field writes.
* This is the most subtle and delicate code in the class.
*/
HashMapEntry<K, V> e = oldTable[j];
if (e == null) {
continue;
}
int highBit = e.hash & oldCapacity;
HashMapEntry<K, V> broken = null;
newTable[j | highBit] = e;
for (HashMapEntry<K, V> n = e.next; n != null; e = n, n = n.next) {
int nextHighBit = n.hash & oldCapacity;
if (nextHighBit != highBit) {
if (broken == null)
newTable[j | nextHighBit] = n;
else
broken.next = n;
broken = e;
highBit = nextHighBit;
}
}
if (broken != null)
broken.next = null;
}
return newTable;
}
很明显,扩容是一个相当耗时的操作,因为它需要重新计算这些元素在新的数组中的位置并进行复制处理。因此,我们在用HashMap的时,最好能提前预估下HashMap中元素的个数,这样有助于提高HashMap的性能。
7、注意containsKey方法和containsValue方法。前者直接可以通过key的哈希值将搜索范围定位到指定索引对应的链表,而后者要对哈希数组的每个链表进行搜索。
8、我们重点来分析下求hash值和索引值的方法,这两个方法便是HashMap设计的最为核心的部分,二者结合能保证哈希表中的元素尽可能均匀地散列。
计算哈希值的方法如下:
private static int secondaryHash(int h) {
// Spread bits to regularize both segment and index locations,
// using variant of single-word Wang/Jenkins hash.
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
它只是一个数学公式,JDK这样设计对hash值的计算,自然有它的好处,至于为什么这样设计,我们这里不去追究,只要明白一点,用的位的操作使hash值的计算效率很高。
由hash值找到对应索引的方法如下:
tab[hash & (tab.length - 1)]
这个我们要重点说下,我们一般对哈希表的散列很自然地会想到用hash值对length取模(即除法散列法),Hashtable中也是这样实现的,这种方法基本能保证元素在哈希表中散列的比较均匀,但取模会用到除法运算,效率很低,HashMap中则通过h&(length-1)的方法来代替取模,同样实现了均匀的散列,但效率要高很多,这也是HashMap对Hashtable的一个改进。
9、接下来,我们分析下为什么哈希表的容量一定要是2的整数次幂。首先,length为2的整数次幂的话,h&(length-1)就相当于对length取模,这样便保证了散列的均匀,同时也提升了效率;其次,length为2的整数次幂的话,为偶数,这样length-1为奇数,奇数的最后一位是1,这样便保证了h&(length-1)的最后一位可能为0,也可能为1(这取决于h的值),即与后的结果可能为偶数,也可能为奇数,这样便可以保证散列的均匀性,而如果length为奇数的话,很明显length-1为偶数,它的最后一位是0,这样h&(length-1)的最后一位肯定为0,即只能为偶数,这样任何hash值都只会被散列到数组的偶数下标位置上,这便浪费了近一半的空间,因此,length取2的整数次幂,是为了使不同hash值发生碰撞的概率较小,这样就能使元素在哈希表中均匀地散列。
Hashtable
HashTable同样是基于哈希表实现的,同样每个元素都是key-value对,其内部也是通过单链表解决冲突问题,容量不足(超过了阈值)时,同样会自动增长。
Hashtable也是JDK1.0引入的类,是线程安全的,能用于多线程环境中。
Hashtable同样实现了Serializable接口,它支持序列化,实现了Cloneable接口,能被克隆。
针对Hashtable,我们同样给出几点比较重要的总结,但要结合与HashMap的比较来总结。
1、二者的存储结构和解决冲突的方法都是相同的。
2、HashTable在不指定容量的情况下的默认容量为4,Hashtable也要求底层数组的容量一定要为2的整数次幂。
private static final int MINIMUM_CAPACITY = 4;
capacity = Collections.roundUpToPowerOfTwo(capacity);
3、Hashtable中key和value都不允许为null,而HashMap中key和value都允许为null(key只能有一个为null,而value则可以有多个为null)。但是如果在Hashtable中有类似put(null,null)的操作,编译同样可以通过,因为key和value都是Object类型,但运行时会抛出NullPointerException异常,这是JDK的规范规定的。我们来看下ContainsKey方法和ContainsValue的源码:
// 判断Hashtable是否包含“值(value)”
public boolean contains(Object value) {
return containsValue(value);
}
public synchronized boolean containsValue(Object value) {
if (value == null) {
throw new NullPointerException("value == null");
}
HashtableEntry[] tab = table;
int len = tab.length;
for (int i = 0; i < len; i++) {
for (HashtableEntry e = tab[i]; e != null; e = e.next) {
if (value.equals(e.value)) {
return true;
}
}
}
return false;
}
// 判断Hashtable是否包含key
public synchronized boolean containsKey(Object key) {
int hash = Collections.secondaryHash(key);
HashtableEntry<K, V>[] tab = table;
for (HashtableEntry<K, V> e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
return true;
}
}
return false;
}
很明显,如果value为null,会直接抛出NullPointerException异常,但源码中并没有对key是否为null判断,有点小不解!不过NullPointerException属于RuntimeException异常,是可以由JVM自动抛出的,也许对key的值在JVM中有所限制吧。
4、 Hashtable扩容时(doubleCapacity),将同样是容量变为原来的2倍。
5、Hashtable计算hash值,同样是利用了int hash = Collections.secondaryHash(key),获取index也是用tab[hash & (tab.length - 1)],跟HashMap是一样的。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









