









文章目录
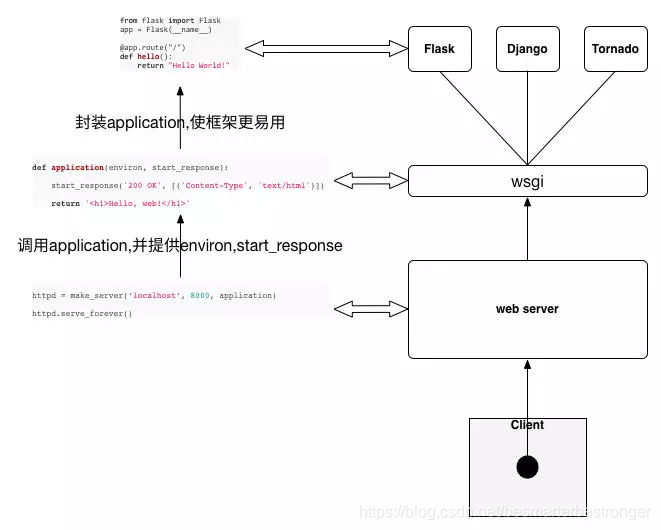
客户端-web服务器-WSGI-web框架之间的逻辑关系,如下图所示,下图来自 flask源码分析
1. 第一步
myflask.py
# myflask.py
from flask import Flask
app = Flask(__name__) #生成app实例
@app.route('/')
def index():
return 'Hello World'
if __name__ == '__main__':
app.run()
然后就从这个简单的例子来分析flask的逻辑。
上面的脚本中创建了一个Flask类的实例,这个实例就是flask的应用实例(app实例)。
def run(self, host=None, port=None, debug=None,
load_dotenv=True, **options):
"""在本地开发服务器上运行application,生产环境中不要使用run(),因为run()并不能满足生产服务器的安全和效率的需求。
:param host: 监听的主机名,若设为'0.0.0.0',则可从外部访问。默认为'127.0.0.1'或 config中``SERVER_NAME`` 配置的值。
:param port: web服务器的端口,默认``5000`` 或 config中``SERVER_NAME`` 配置的值。
:param debug: 若指定了该关键字参数,则表示启用或禁用debug模式。
:param load_dotenv: 加载最近的.env和.flaskenv文件来设置环境变量。
:param options: 另外一些传递给Werkzeug服务器的参数。
"""
# Change this into a no-op if the server is invoked from the
# command line. Have a look at cli.py for more information.
if os.environ.get('FLASK_RUN_FROM_CLI') == 'true':
from .debughelpers import explain_ignored_app_run
explain_ignored_app_run()
return
if get_load_dotenv(load_dotenv):
cli.load_dotenv()
# if set, let env vars override previous values
if 'FLASK_ENV' in os.environ:
self.env = get_env()
self.debug = get_debug_flag()
elif 'FLASK_DEBUG' in os.environ:
self.debug = get_debug_flag()
# debug passed to method overrides all other sources
if debug is not None:
self.debug = bool(debug)
_host = '127.0.0.1'
_port = 5000
server_name = self.config.get('SERVER_NAME')
sn_host, sn_port = None, None
if server_name:
sn_host, _, sn_port = server_name.partition(':')
host = host or sn_host or _host
port = int(port or sn_port or _port)
options.setdefault('use_reloader', self.debug)
options.setdefault('use_debugger', self.debug)
options.setdefault('threaded', True)
cli.show_server_banner(self.env, self.debug, self.name, False)
from werkzeug.serving import run_simple
try:
run_simple(host, port, self, **options)
finally:
# reset the first request information if the development server
# reset normally. This makes it possible to restart the server
# without reloader and that stuff from an interactive shell.
self._got_first_request = False

def run_simple(
hostname,
port,
application,
use_reloader=False,
use_debugger=False,
use_evalex=True,
extra_files=None,
reloader_interval=1,
reloader_type="auto",
threaded=False,
processes=1,
request_handler=None,
static_files=None,
passthrough_errors=False,
ssl_context=None,
):
"""Start a WSGI application. Optional features include a reloader,
multithreading and fork support.
This function has a command-line interface too::
python -m werkzeug.serving --help
:param hostname: The host to bind to, for example ``'localhost'``.
If the value is a path that starts with ``unix://`` it will bind
to a Unix socket instead of a TCP socket..
:param port: The port for the server. eg: ``8080``
:param application: the WSGI application to execute
:param use_reloader: should the server automatically restart the python
process if modules were changed?
:param use_debugger: should the werkzeug debugging system be used?
:param use_evalex: should the exception evaluation feature be enabled?
:param extra_files: a list of files the reloader should watch
additionally to the modules. For example configuration
files.
:param reloader_interval: the interval for the reloader in seconds.
:param reloader_type: the type of reloader to use. The default is
auto detection. Valid values are ``'stat'`` and
``'watchdog'``. See :ref:`reloader` for more
information.
:param threaded: should the process handle each request in a separate
thread?
:param processes: if greater than 1 then handle each request in a new process
up to this maximum number of concurrent processes.
:param request_handler: optional parameter that can be used to replace
the default one. You can use this to replace it
with a different
:class:`~BaseHTTPServer.BaseHTTPRequestHandler`
subclass.
:param static_files: a list or dict of paths for static files. This works
exactly like :class:`SharedDataMiddleware`, it's actually
just wrapping the application in that middleware before
serving.
:param passthrough_errors: set this to `True` to disable the error catching.
This means that the server will die on errors but
it can be useful to hook debuggers in (pdb etc.)
:param ssl_context: an SSL context for the connection. Either an
:class:`ssl.SSLContext`, a tuple in the form
``(cert_file, pkey_file)``, the string ``'adhoc'`` if
the server should automatically create one, or ``None``
to disable SSL (which is the default).
"""
if not isinstance(port, int):
raise TypeError("port must be an integer")
if use_debugger:
from .debug import DebuggedApplication
application = DebuggedApplication(application, use_evalex)
if static_files:
from .middleware.shared_data import SharedDataMiddleware
application = SharedDataMiddleware(application, static_files)
def log_startup(sock):
display_hostname = hostname if hostname not in ("", "*") else "localhost"
quit_msg = "(Press CTRL+C to quit)"
if sock.family == af_unix:
_log("info", " * Running on %s %s", display_hostname, quit_msg)
else:
if ":" in display_hostname:
display_hostname = "[%s]" % display_hostname
port = sock.getsockname()[1]
_log(
"info",
" * Running on %s://%s:%d/ %s",
"http" if ssl_context is None else "https",
display_hostname,
port,
quit_msg,
)
def inner():
try:
fd = int(os.environ["WERKZEUG_SERVER_FD"])
except (LookupError, ValueError):
fd = None
srv = make_server(
hostname,
port,
application,
threaded,
processes,
request_handler,
passthrough_errors,
ssl_context,
fd=fd,
)
if fd is None:
log_startup(srv.socket)
srv.serve_forever()
if use_reloader:
# If we're not running already in the subprocess that is the
# reloader we want to open up a socket early to make sure the
# port is actually available.
if not is_running_from_reloader():
if port == 0 and not can_open_by_fd:
raise ValueError(
"Cannot bind to a random port with enabled "
"reloader if the Python interpreter does "
"not support socket opening by fd."
)
# Create and destroy a socket so that any exceptions are
# raised before we spawn a separate Python interpreter and
# lose this ability.
address_family = select_address_family(hostname, port)
server_address = get_sockaddr(hostname, port, address_family)
s = socket.socket(address_family, socket.SOCK_STREAM)
s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
s.bind(server_address)
if hasattr(s, "set_inheritable"):
s.set_inheritable(True)
# If we can open the socket by file descriptor, then we can just
# reuse this one and our socket will survive the restarts.
if can_open_by_fd:
os.environ["WERKZEUG_SERVER_FD"] = str(s.fileno())
s.listen(LISTEN_QUEUE)
log_startup(s)
else:
s.close()
if address_family == af_unix:
_log("info", "Unlinking %s" % server_address)
os.unlink(server_address)
# Do not use relative imports, otherwise "python -m werkzeug.serving"
# breaks.
from ._reloader import run_with_reloader
run_with_reloader(inner, extra_files, reloader_interval, reloader_type)
else:
inner()
def run_wsgi(self):
if self.headers.get("Expect", "").lower().strip() == "100-continue":
self.wfile.write(b"HTTP/1.1 100 Continue\r\n\r\n")
self.environ = environ = self.make_environ()
headers_set = []
headers_sent = []
def write(data):
assert headers_set, "write() before start_response"
if not headers_sent:
status, response_headers = headers_sent[:] = headers_set
try:
code, msg = status.split(None, 1)
except ValueError:
code, msg = status, ""
code = int(code)
self.send_response(code, msg)
header_keys = set()
for key, value in response_headers:
self.send_header(key, value)
key = key.lower()
header_keys.add(key)
if not (
"content-length" in header_keys
or environ["REQUEST_METHOD"] == "HEAD"
or code < 200
or code in (204, 304)
):
self.close_connection = True
self.send_header("Connection", "close")
if "server" not in header_keys:
self.send_header("Server", self.version_string())
if "date" not in header_keys:
self.send_header("Date", self.date_time_string())
self.end_headers()
assert isinstance(data, bytes), "applications must write bytes"
self.wfile.write(data)
self.wfile.flush()
def start_response(status, response_headers, exc_info=None):
if exc_info:
try:
if headers_sent:
reraise(*exc_info)
finally:
exc_info = None
elif headers_set:
raise AssertionError("Headers already set")
headers_set[:] = [status, response_headers]
return write
def execute(app):
application_iter = app(environ, start_response)
try:
for data in application_iter:
write(data)
if not headers_sent:
write(b"")
finally:
if hasattr(application_iter, "close"):
application_iter.close()
application_iter = None
try:
execute(self.server.app)
except (_ConnectionError, socket.timeout) as e:
self.connection_dropped(e, environ)
except Exception:
if self.server.passthrough_errors:
raise
from .debug.tbtools import get_current_traceback
traceback = get_current_traceback(ignore_system_exceptions=True)
try:
# if we haven't yet sent the headers but they are set
# we roll back to be able to set them again.
if not headers_sent:
del headers_set[:]
execute(InternalServerError())
except Exception:
pass
self.server.log("error", "Error on request:\n%s", traceback.plaintext)
2. 第二步
在Flask类的源码中,有一段代码是如下这样的:
def wsgi_app(self, environ, start_response):
"""实际的WSGI应用。 这不是在__call __()中实现的,因此可以应用中间件而不会丢失对app对象的引用。举例子:
app = MyMiddleware(app) # 不要这样使用
app.wsgi_app = MyMiddleware(app.wsgi_app) # 应该这样使用
"param environ: A WSGI environment.
:param start_response: 接收状态码,headers的list,异常上下文参数的一个response可调用对象
"""
# 根据environ获得请求上下文,请求上下文包含request请求的所有相关信息。
# 请求上下文是在请求之前创建的,并且推到请求上下文栈中,(_request_ctx_stack),在请求结束后从该栈中弹出。
# ctx是RequestContext()实例对象,其具有属性request(由request_class()获得,是wrapper.Request()的实例)
# 也就是说通过request_context(environ)的到了请求上下文,请求上下文中包含了request对象。
ctx = self.request_context(environ)
error = None
try:
try:
ctx.push() # 推送请求上下文,推送至_request_ctx_stack
response = self.full_dispatch_request() # 分派request请求,对请求进行预处理、错误处理等。
except Exception as e:
error = e
response = self.handle_exception(e)
except:
error = sys.exc_info()[1]
raise
return response(environ, start_response) # 返回flask框架的最终response对象给WSGI服务器
finally:
if self.should_ignore_error(error):
error = None
ctx.auto_pop(error)
def __call__(self, environ, start_response):
"""WSGI服务器调用Flask应用对象作为WSGI应用。通过wsgi_app包装应用中间件来实现。
The WSGI server calls the Flask application object as the
WSGI application. This calls :meth:`wsgi_app` which can be
wrapped to applying middleware."""
return self.wsgi_app(environ, start_response)
大家也都知道,在类中定义的__call__()方法会使得类的实例能像函数一样执行。之所以是这样是因为:
WSGI接口中有一个非常明确的标准,
每个Python Web应用必须是可调用callable的对象且返回一个iterator,并实现了app(environ, start_response) 的接口,server 会调用 application,并传给它两个参数:environ 包含了请求的所有信息,start_response 是 application 处理完之后需要调用的函数,参数是状态码、响应头部还有错误信息。
用尽洪荒之力学习Flask源码
所以从上面的源码中能够得出下面的流程图。

3. 第三步
在wsgi_app()主要调用了两个方法:
- request_context()
request_context()方法的返回值是一个请求上下文对象,它具有许多属性如request、flashes、session等属性,它的request属性是request_class()的一个实例,所以这个方法得到的就是包含request请求所有相关信息的一个请求上下文对象。
- full_dispatch_request()
分派request请求,并进行request预处理、后处理以及HTTP exception捕获和错误处理。这个request请求就是从上面的请求上下文对象中得到的。flask会将创建的请求上下文对象加入到_request_ctx_stack(请求上下文栈)中。要使用请求上下文时,直接从这个栈中去取。详情见 flask请求和应用上下文
源代码如下:
def request_context(self, environ):
"""
创建一个请求上下文对象(~flask.ctx.RequestContext的实例)。
:param environ: a WSGI environment
"""
return RequestContext(self, environ)
def full_dispatch_request(self):
"""分派request请求,并进行request预处理、后处理以及HTTP exception捕获和错误处理。
"""
self.try_trigger_before_first_request_functions() # 请求之前调用
try:
request_started.send(self) # socket部分操作
rv = self.preprocess_request() # 请求被分派之前调用
if rv is None:
rv = self.dispatch_request() # 分派请求
except Exception as e:
rv = self.handle_user_exception(e)
return self.finalize_request(rv) #
4. 第四步
从上面full_dispatch_request()方法的源码中就能看出,在full_dispatch_request()方法中,Flask实例先后调用了方法:
- self.try_trigger_before_first_request_functions()。
- self.preprocess_request()
- self.dispatch_request()
- self.finalize_request()
处理逻辑如图所示:

4.1 触发before_first_request()
判断此app是否时第一次request请求,是则直接返回;不是则调用before_first_request_funcs中的函数。
def try_trigger_before_first_request_functions(self):
"""在每次请求之前被调用,确保执行属性before_first_request_funcs中的函数,并将self._got_first_request属性的值设为True,表示已经开始第一次请求了。
"""
if self._got_first_request:
return
with self._before_request_lock:
if self._got_first_request:
return
for func in self.before_first_request_funcs:
func()
self._got_first_request = True
4.2 调用before_request_func中的函数
从请求上下文栈(_request_ctx_stack)中获取request,根据request中的信息,调用before_request_func中的一些函数。
def preprocess_request(self):
"""request请求被派发之前调用此方法。调用url_value_preprocessors字典和before_request_funcs字典中的一些函数。
"""
# 从请求上下文栈中拿到栈顶的request请求的蓝图
bp = _request_ctx_stack.top.request.blueprint
funcs = self.url_value_preprocessors.get(None, ())
if bp is not None and bp in self.url_value_preprocessors:
funcs = chain(funcs, self.url_value_preprocessors[bp])
# 获取到所有需要调用的函数,依次调用他们
for func in funcs:
func(request.endpoint, request.view_args)
funcs = self.before_request_funcs.get(None, ())
if bp is not None and bp in self.before_request_funcs:
funcs = chain(funcs, self.before_request_funcs[bp])
# self.before_request_funcs中存的是在request请求开始之前需要调用的函数,这写函数是通过self.before_request()添加进来的
# 获取到所有需要调用的函数,依次调用他们,返回第一个不为None的返回值
for func in funcs:
rv = func()
if rv is not None:
return rv
4.3 分派request,得到视图函数返回值
从请求上下文栈(_request_ctx_stack)中获取request,根据request中的信息,找到URL对应的视图函数,获得视图函数的返回值。
def dispatch_request(self):
"""分派请求。匹配URL并返回视图函数的返回值。该返回值不一定是response对象。如果要将返回值转换为response对象,需要调用make_response()。
"""
# _request_ctx_stack是请求上下文栈,top是获得栈顶元素,因为该栈中存的都是RequestContetxt()类的实例(具有reqeust属性,为self.reqeust_class)
# 也就是说这里的req是一个request对象
req = _request_ctx_stack.top.request
if req.routing_exception is not None:
self.raise_routing_exception(req)
# url_rule是request对象中的一个属性,它的值是由url_adapter(url适配器)得到的.
rule = req.url_rule
# rule是一个字典,从该字典从获取值
if getattr(rule, 'provide_automatic_options', False) \
and req.method == 'OPTIONS':
return self.make_default_options_response()
# otherwise dispatch to the handler for that endpoint
# 从rule中获取端点(视图函数名),根据端点找到视图函数,将请求分派给对应的视图函数,并调用视图函数
return self.view_functions[rule.endpoint](**req.view_args)
4.4 对视图函数返回值进行处理
4.3中已经获得了视图函数的返回值,但是这个返回值并不一定是response_class的实例对象(也就是我们平常说的response对象),所以在这一步中需要将返回值转换成response对象。
def finalize_request(self, rv, from_error_handler=False):
"""将视图函数的return的返回值转换成response对象,并调用后处理函数(postprocessing functions)。分派正常request请求和error handlers时都会调用这个函数。因为都需要返回response对象。
from_error_handler为True的话,在处理response时出现的错误都会记录下来。
"""
response = self.make_response(rv) # 转换成response对象
try:
response = self.process_response(response) # 在response对象传递到WSGI服务器之前修改response对象,调用after_request_functions字典中的函数
request_finished.send(self, response=response)
except Exception:
if not from_error_handler:
raise
self.logger.exception('Request finalizing failed with an '
'error while handling an error')
return response
def make_response(self, rv):
"""将视图函数的返回值转换成response_class的一个实例对象
:param rv: 视图函数的返回值,视图函数必须返回response对象或None。
视图函数的返回值可以是以下几种。
``str`` (``unicode`` in Python 2)
A response object is created with the string encoded to UTF-8
as the body.
``bytes`` (``str`` in Python 2)
A response object is created with the bytes as the body.
``tuple``
Either ``(body, status, headers)``, ``(body, status)``, or
``(body, headers)``, where ``body`` is any of the other types
allowed here, ``status`` is a string or an integer, and
``headers`` is a dictionary or a list of ``(key, value)``
tuples. If ``body`` is a :attr:`response_class` instance,
``status`` overwrites the exiting value and ``headers`` are
extended.
:attr:`response_class`
The object is returned unchanged.
other :class:`~werkzeug.wrappers.Response` class
The object is coerced to :attr:`response_class`.
:func:`callable`
The function is called as a WSGI application. The result is
used to create a response object.
"""
status = headers = None
# unpack tuple returns
# 如果视图函数的返回值是元组的话就解包。
if isinstance(rv, tuple):
len_rv = len(rv)
# a 3-tuple is unpacked directly
# 解包长度为3的元组
if len_rv == 3:
rv, status, headers = rv
# decide if a 2-tuple has status or headers
# 解包长度为2的元组,根据第二的元素的类型来判断它是状态码还是headers
elif len_rv == 2:
if isinstance(rv[1], (Headers, dict, tuple, list)):
rv, headers = rv
else:
rv, status = rv
# other sized tuples are not allowed
else:
raise TypeError(
'The view function did not return a valid response tuple.'
' The tuple must have the form (body, status, headers),'
' (body, status), or (body, headers).'
)
# the body must not be None
if rv is None:
raise TypeError(
'The view function did not return a valid response. The'
' function either returned None or ended without a return'
' statement.'
)
# make sure the body is an instance of the response class
if not isinstance(rv, self.response_class):
if isinstance(rv, (text_type, bytes, bytearray)):
# let the response class set the status and headers instead of
# waiting to do it manually, so that the class can handle any
# special logic
rv = self.response_class(rv, status=status, headers=headers)
status = headers = None
else:
# evaluate a WSGI callable, or coerce a different response
# class to the correct type
try:
rv = self.response_class.force_type(rv, request.environ)
except TypeError as e:
new_error = TypeError(
'{e}\nThe view function did not return a valid'
' response. The return type must be a string, tuple,'
' Response instance, or WSGI callable, but it was a'
' {rv.__class__.__name__}.'.format(e=e, rv=rv)
)
reraise(TypeError, new_error, sys.exc_info()[2])
# prefer the status if it was provided
if status is not None:
if isinstance(status, (text_type, bytes, bytearray)):
rv.status = status
else:
rv.status_code = status
# extend existing headers with provided headers
if headers:
rv.headers.extend(headers)
return rv
最终wsgi_app()中的返回值就是这里的rv了。
5. 总结
用网上我觉得比较好的图片作为总结吧,图片来自 用尽洪荒之力学习Flask源码,这就flask监听和处理http请求的基本逻辑了。

此图来自于 Flask源码解读 — 浅谈Flask基本工作流程

其中的environ都是WSGI传过来的。
- environ: 一个包含全部HTTP请求信息的字典,由WSGI Server解包HTTP请求生成。
- start_response: 一个WSGI Server提供的函数,调用可以发送响应的状态码和HTTP报文头, 函数在返回前必须调用一次start_response()。
最后为甚么还要response(environ, start_response)呢?
response其实是flask.wrapper中的Response类的实例对象,而能够这样使用这个实例对象,表明这个类或者其父类中一定有__call__()方法。
经过一番查找之后发现是werkzeug\wrappers\base_response.py中BaseResponse类的__call__()方法造成的。
需要从environ中获得headers等信息,具体好像是flask/app.py中有些方法(例如make_response()),对headers等信息已经做了修改,所以在往回传的时候需要带上这部分信息。
6. 参考文献
[1] 用尽洪荒之力学习Flask源码
[2] Flask源码解读 — 浅谈Flask基本工作流程
[3] flask请求和应用上下文
[4] flask源码分析















 857
857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









