






 文章介绍了Redis在主从架构下可能出现的脑裂问题,当网络分区导致两个主节点并存,从而引起数据不一致。通过配置min-replicas-to-write和min-replicas-max-lag参数可以减少脑裂导致的数据丢失,但无法完全避免。文中还详细描述了如何模拟脑裂现象以及哨兵架构的搭建和验证过程。
文章介绍了Redis在主从架构下可能出现的脑裂问题,当网络分区导致两个主节点并存,从而引起数据不一致。通过配置min-replicas-to-write和min-replicas-max-lag参数可以减少脑裂导致的数据丢失,但无法完全避免。文中还详细描述了如何模拟脑裂现象以及哨兵架构的搭建和验证过程。
前言
单纯的主从架构不具有高可用性,主要起到数据备份的作用,当主节点故障时,客户端将不能写入数据,所以当不使用redis集群时,可以使用redis哨兵架构,也可以保证高可用性。哨兵不提供读写服务,只是用来做监测、通知、自动故障转移,如果主节点未按预期工作,哨兵l可以启动故障切换过程,将从节点升级为主节点,客户端将数据写入新的主节点,旧的主节点恢复时,会作为从节点同步新主节点的数据。但是redis哨兵架构也会有脑裂问题,下面我们着重介绍一下什么是脑裂?它是怎么发生的以及解决方案是什么,然后我们使用多台虚拟机模拟脑裂现象,验证解决方案是否真正可用。
什么是脑裂
当主节点与从节点之间的网络通信突然断了,这时将一个从节点选举了主节点,此时出现了两个主节点,那么不同客户端会往这个两个主节点存数据,两个主节点数据不一致,当网络恢复后,原来的主节点变为从节点,从当前主节点复制数据,原来的主节点数据会丢失。
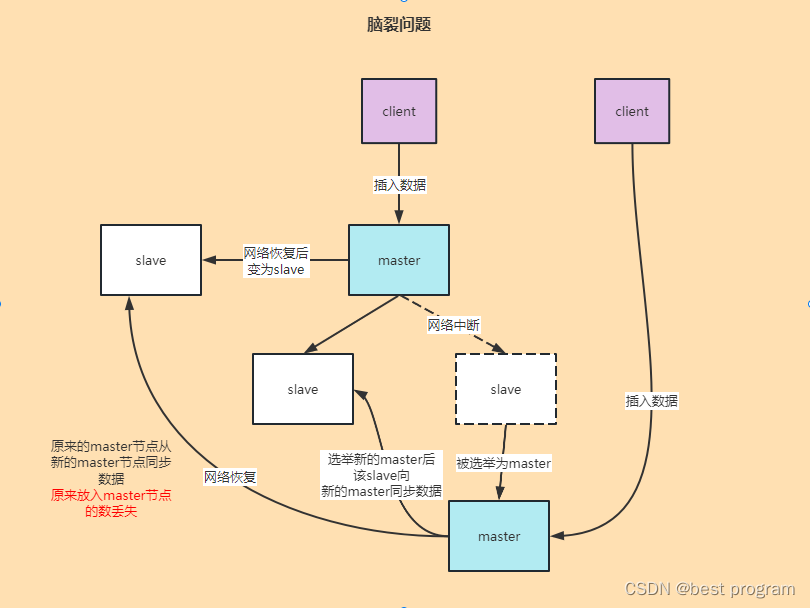
解决办法:
在redis.conf配置文件中开启下面两配置
min-replicas-to-write 1 #最少有一个从节点写数据成功,默认为0,即关闭这种模式
min-replicas-max-lag 10 #从节点向主节点发送ACK最大延迟时间,默认10
写入主节点的同时,需要指定数量的从节点也写成功,客户端才算写成功,所以原来的主从节点网络断了,原来的主节点不能插入数据了,待网络恢复后,将新的主节点数据全量同步给原来的主节点(此时变为从节点了)。
接下来我们模拟一下脑裂问题
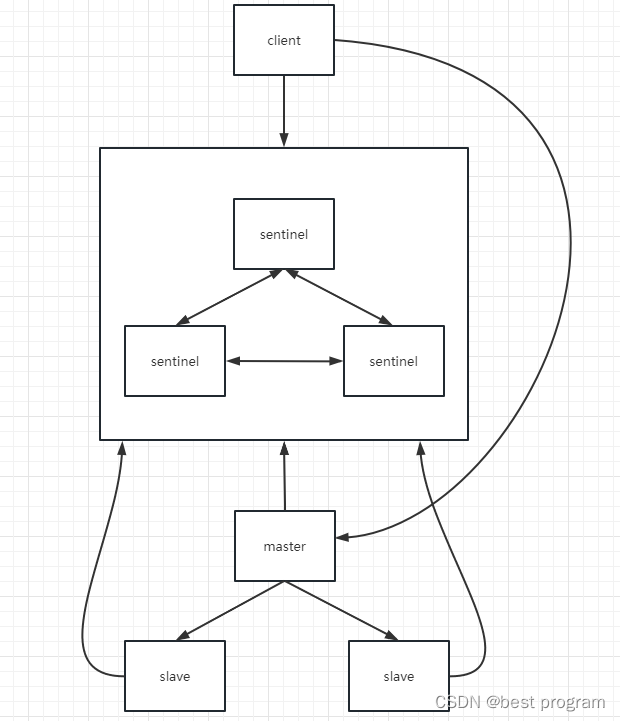
哨兵主从架构
为了验证脑裂问题,我们先搭建一个哨兵主从架构。
准备:
VMware:搭建3台Centos虚拟机
Redis:redis-5.0.14
主从架构
3台虚拟机分别下载安装Redis,在这里就不在赘余。下面分别启动3台Redis服务,首先需要修改redis.conf相关参数
#bind 127.0.0.1 #bing是为了指定哪些IP能访问,内网不需要指定,注释掉
protected-mode no #关闭保护模式,否则只能本地访问,没法搭建主从
port 6379 #指定redis服务端口,默认6379
daemonize yes #yes表示可以守护进程启动
pidfile "/var/run/redis_6379.pid" #守护进程启动时,用来记录pid
logfile "6379.log" #指定日志文件名,默认日志只会在控制台输出,指定日志文件可以保持日志
dir "/usr/local/redis-5.0.14/data" #指定数据存储位置
#其它两台服务port和pidfile要重新指定
port 6380/6381
# 从节额外配置
replicaof 192.168.111.132 6379 # 从6379的redis服务复制数据
replica-read-only yes # 配置从节点只读
启动3台服务Redis,最先启动的为主节点
src/redis-server redis.conf
哨兵
每台服务分别配置一个哨兵,也就是每台服务有一个redis节点和一个哨兵,下面分别启动3个哨兵节点,首先需要修改sentinel.conf相关参数
port 26379 #指定sentinel端口,默认26379
daemonize yes #守护进程启动
pidfile "/var/run/redis-sentinel-26379.pid"
logfile "26379.log"
dir "/usr/local/redis-5.0.14/data"
# quorum是一个数字,指明当有多少个sentinel认为一个master失效时(值一般为:sentinel总数/2 + 1),master才算真正失效
sentinel monitor mymaster 192.168.111.132 6379 2
#其它两个sentinel注意要修改一下端口
- 分别启动三个哨兵
src/redis-sentinel sentinel.conf
启动成功后,sentinel.conf会追加下面的信息
节点192.168.111.132,监控显示主从服务的2个从节点及其它2个哨兵

节点192.168.111.133,监控显示主从服务的2个从节点及其它2个哨兵

节点192.168.111.134,监控显示主从服务的2个从节点及其它2个哨兵

当主从节点发生变化时,这些信息也会发生相应变化。
- 演示一下哨兵架构是否成功
在3个redis服务分别登录客户端
src/redis-cli -p 6379/6380/6881
主节点6379写入数据成功
从节点6380读取数据成功

从节点6381读取数据成功
假如往从节点6380写数据

报错,所以从节点只能读数据,不能写数据
主从架构搭建成功!!
- 那么我们再验证一下哨兵是否正常
假如我们把master节点停掉,看看是否会重新选取一个新的master节点
可以通过sentinel.conf查看,6379变成了从节点,6380变成了主节点

6380写数据成功

6379写数据失败,说明变成了从节点

从上面可以看出哨兵能够正常运转
模拟脑裂
重点来了,我们模拟一下脑裂问题
基于上面哨兵架构的验证情况,现在6380为主节点,其它两个为从节点。我们将6380这台虚拟机进行断网操作,选中虚拟机-》右键-》设置-》网络适配器,如下图,将已连接取消。
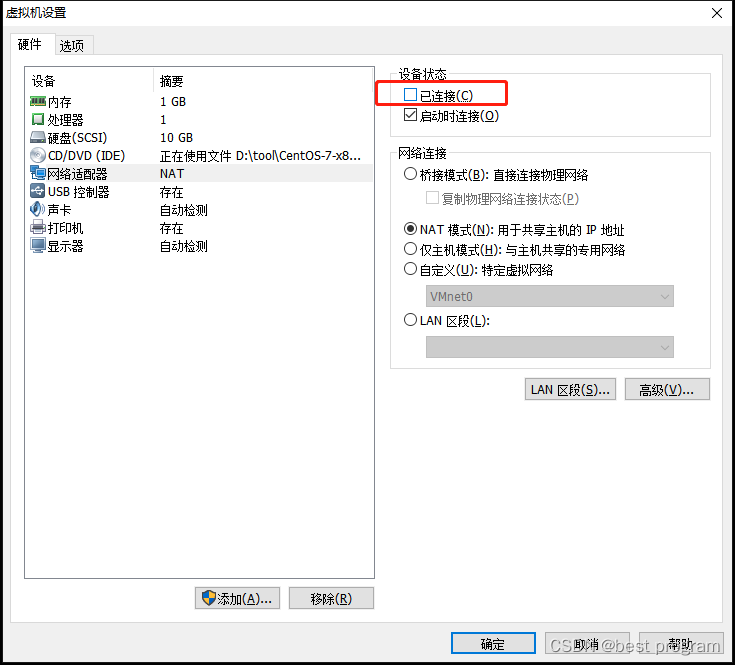
断网后,6380仍然可以作为主节点写入数据

查看sentinel,发现现在主节点已经变为6379了

6379也可以成功写入数据,这时同时有两个主节点可以写入数据,那么脑裂问题出现了

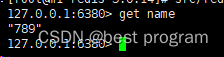
网络重新连接后,6380变成了从节点,数据被6379覆盖,name由235变成了789,235数据丢失
解决脑裂
现在主节点为6379,我们将6379的redis.conf中配置如下
min-replicas-to-write 1 #最少有一个从节点写数据成功
min-replicas-max-lag 10 #从节点向主节点发送ACK最大延迟时间
按照上面的步骤,我们把6379断网,可以看出向6379写入失败,脑裂问题解决

注意
min-replicas-to-write和min-replicas-max-lag必须同时满足才能禁止写入数据,如果min-replicas-max-lag=10,理论上讲仍有10s内有数据写入的话仍然能写入成功,造成数据丢失,那有人说那岂不是越小越好,如果设置1s,那就得要求主节点1秒内把数据同步给从节点,这显示是不太合理的,因为万一遇到从节点卡顿或者网络稍微有点延迟,那就会造成写入数据失败,严重影响了高可用。
所以说脑裂的解决是处在一个平衡点上,尽量降低数据丢失,不能完全防止数据丢失。

















 1081
1081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









