






Tesseract是一个开源的光学字符识别 (OCR) 引擎,它可以将图像中的文字转换为计算机可读的文本。支持多种语言和书面语言,并且可以在命令行
中执行。它是一一个流行的开源OCR工具,可以在许多不同的操作系统上运行。Tess4J是一个基于Tesseract 0CR字的Java接口,可以用来识别图像中的文本,说白了,就是封装了它的API,让Java可以直接调用。
训练数据:
Tesseract OCR库通过训练数据来学习不同语言和字体的特征,以便更好地识别图片中的文字。在安装Tesseract OCR库时,通常会生成一个包含多个子文件夹的训练数据文件夹,其中每个子文件夹都包含了特定语言或字体的训练数据。
语言模型下载:https://gitcode.net/search?utf8=%E2%9C%93&snippets=false&scope=&repository_ref=&search=tesseract(gitcode) java使用Tess4J实现OCR图片文字识别_java ocr-CSDN博客(参考这篇文章,里面有下载的内容百度网盘 (可以查看人家博客
java使用Tess4J实现OCR图片文字识别_java ocr-CSDN博客))
tess4 jar包
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>5.2.1</version>
</dependency>
1.使用自带的训练模型
程序
public class ocr {
@Test
public void OcrTest(){
//指定图片位置
String path="E:\\idea\\ocr\\Ocr_test\\1.png";
File file = new File(path);
//指定语言模型位置
String languagePath = "E:\\idea\\ocr\\tessdata";
Tesseract instance = new Tesseract();
// 设置训练库位置
instance.setDatapath(languagePath);
// chi_sim 中文 eng 英文
instance.setLanguage("chi_sim");
String result= "123";
try {
//进行解析
result = instance.doOCR(file);
} catch (TesseractException e) {
throw new RuntimeException(e);
}
System.out.println("result:"+result);
}
}

2.使用自定义训练模型 下载 jTessBoxEditor2.0工具,用于调整图片上文字的内容和位置 https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/ 安装包解压后打开“jTessBoxEditor.jar”,或者双击该目录下的“train.bat”脚本文件 选择Tools->Merge TIFF 进行要识别的图片进行合并
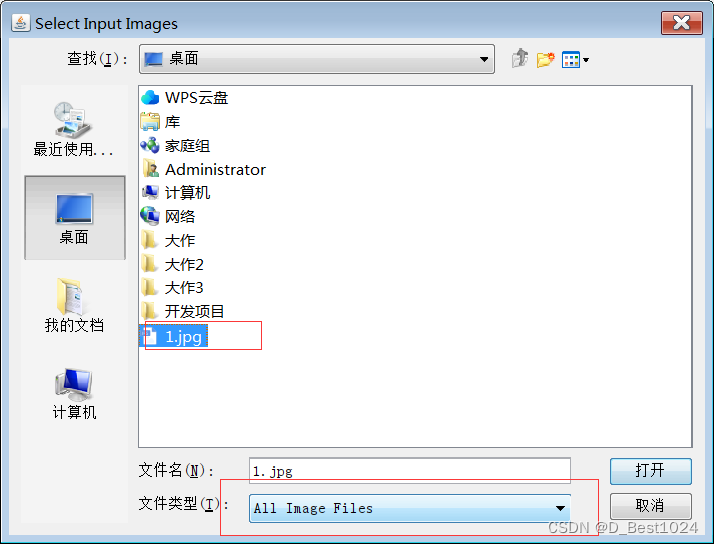
将所有的图片进行合并成一个盒子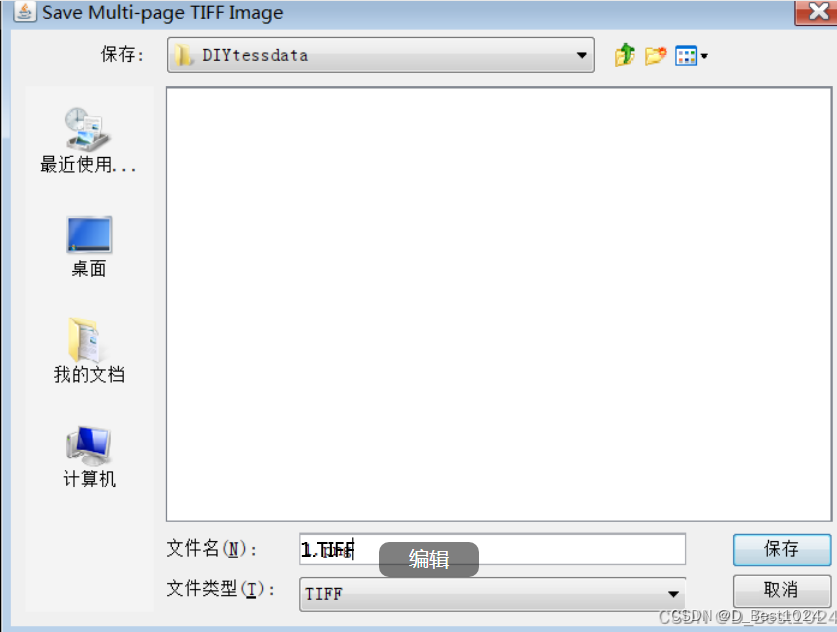
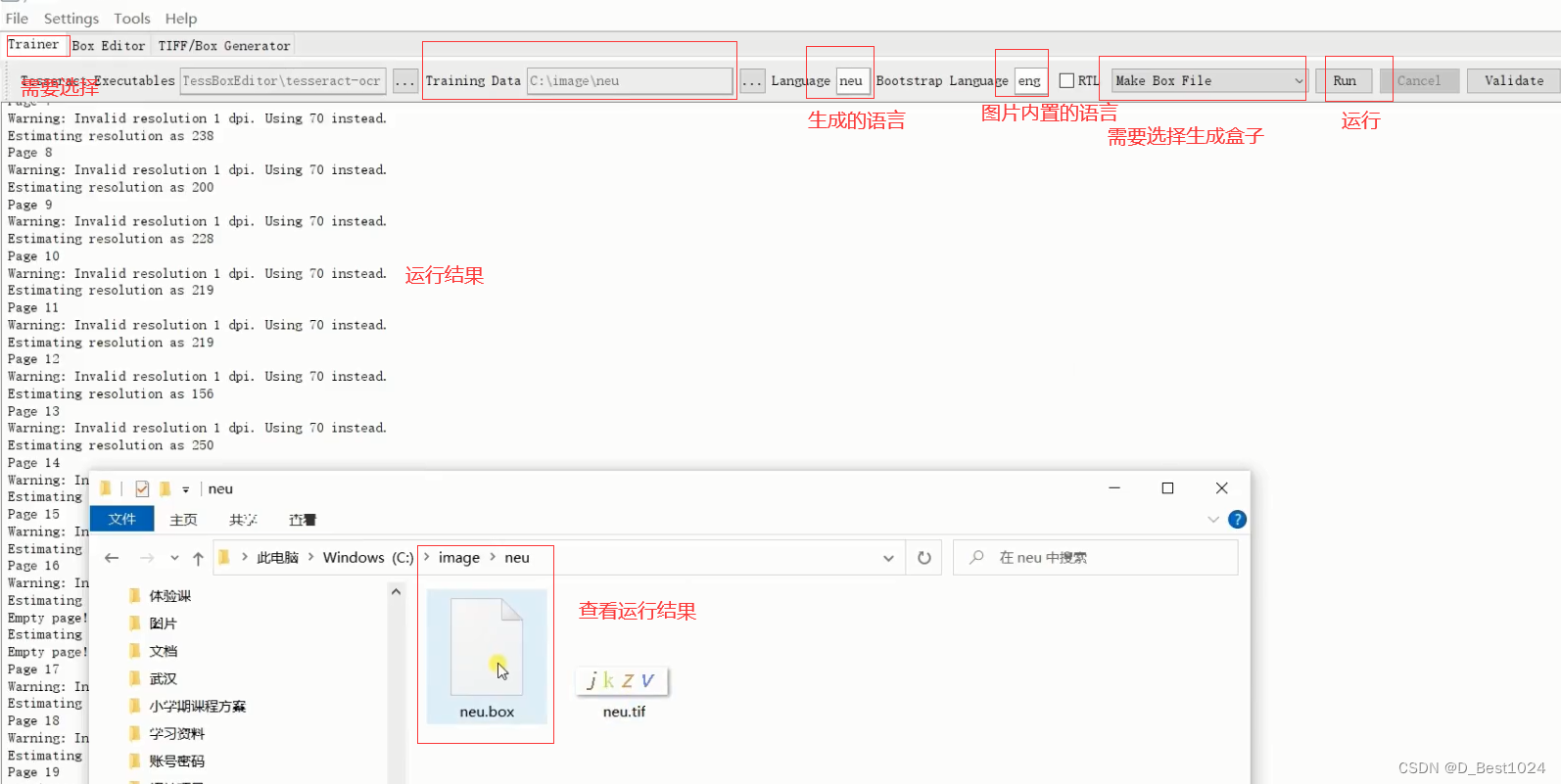
选择生成的盒子调整识别内容
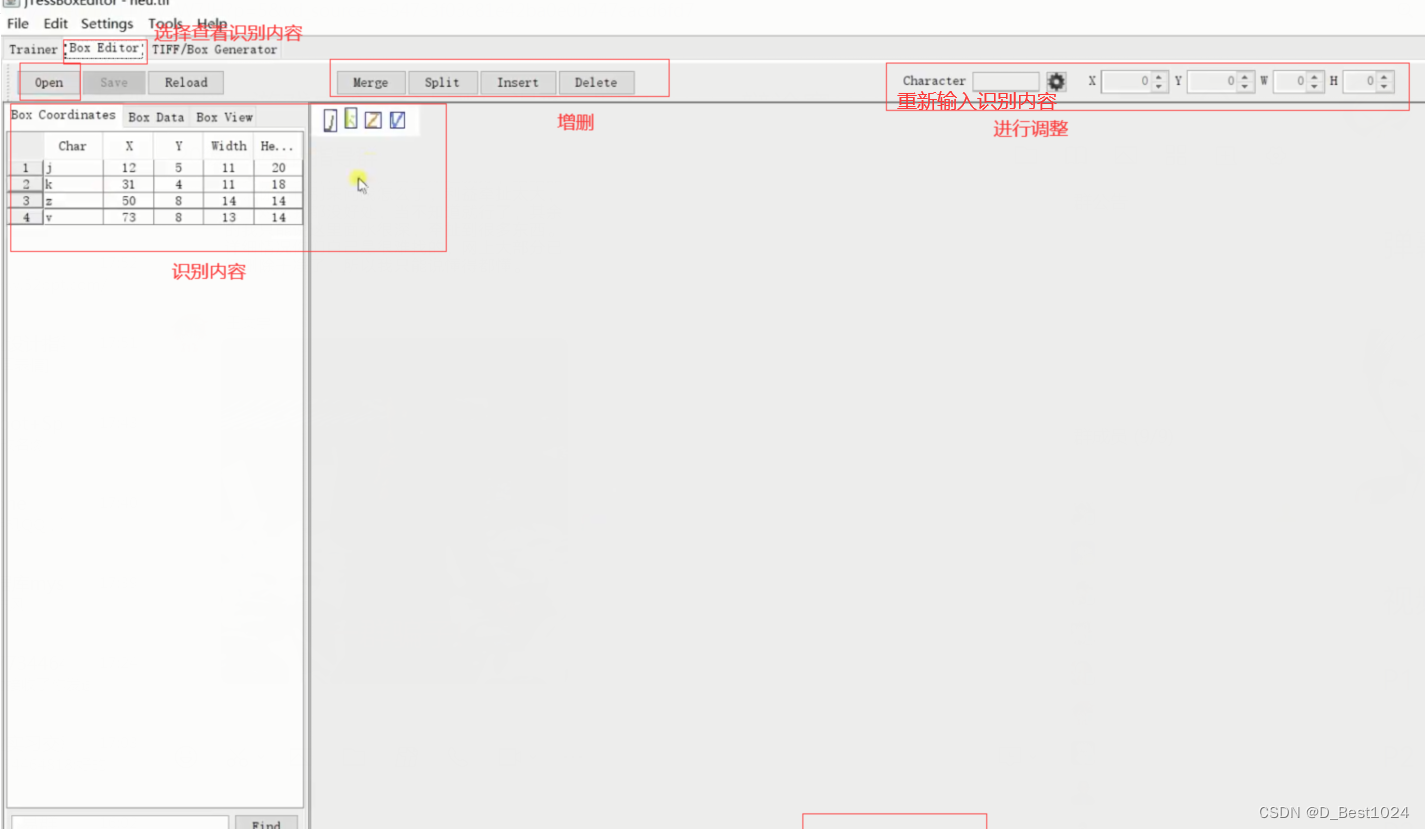
进行生成自定义语言库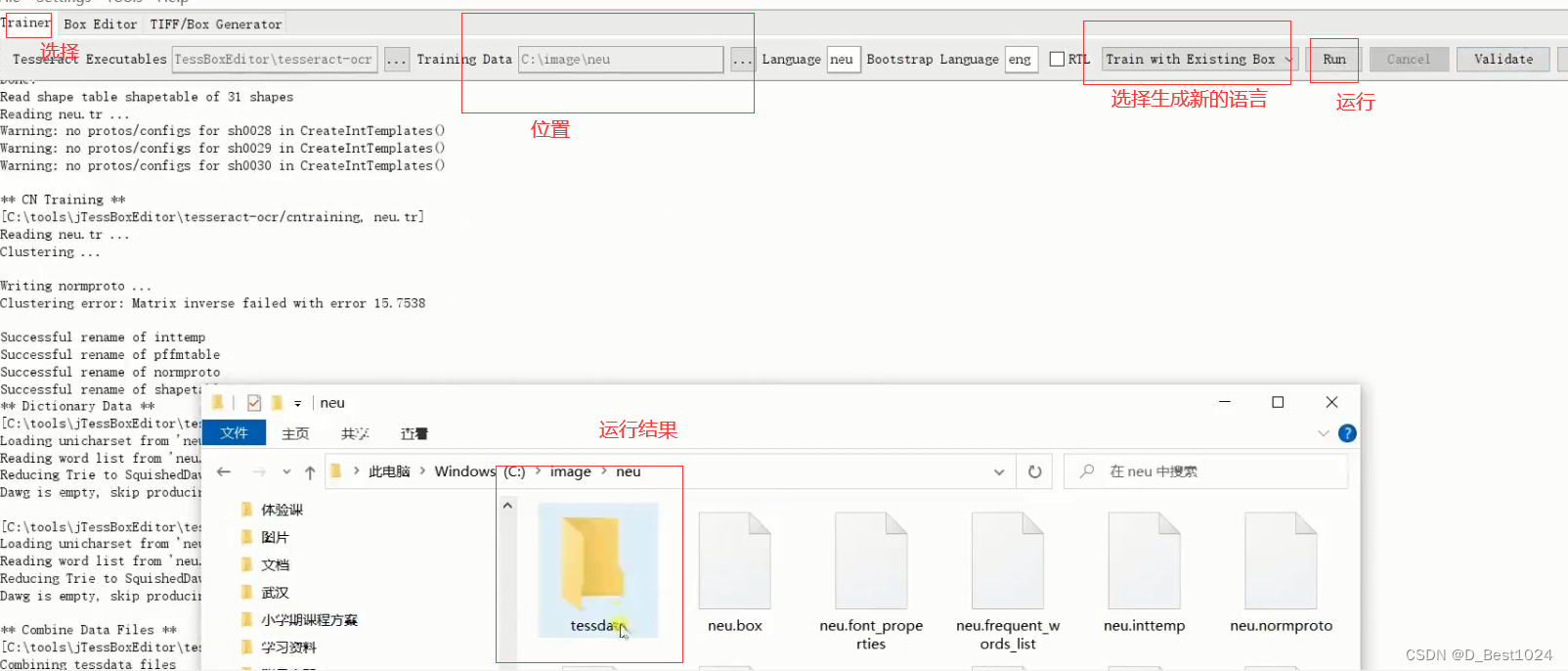















 1114
1114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









