







DeepSeek V3 是由杭州深度求索公司开发的一款高性能、低成本的开源大语言模型(LLM),于2024年12月26日正式发布并同步开源。该模型基于自研的MoE(混合专家)架构,拥有6710亿参数,激活参数为370亿,并在14.8万亿高质量token上进行了预训练。其主要特点包括高效推理能力、多领域的卓越表现以及极低的训练成本。
技术特性
-
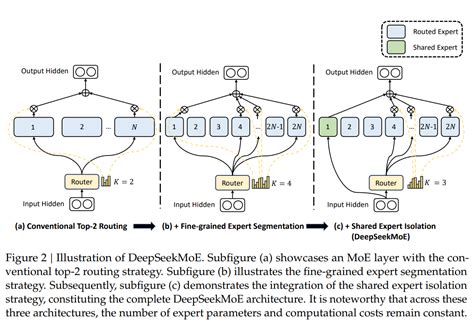
架构与参数
DeepSeek V3采用MoE架构,激活参数为370亿,总参数量达到6710亿。其混合专家架构通过将问题划分为多个子区域,从而提升模型的推理效率和性能。
-
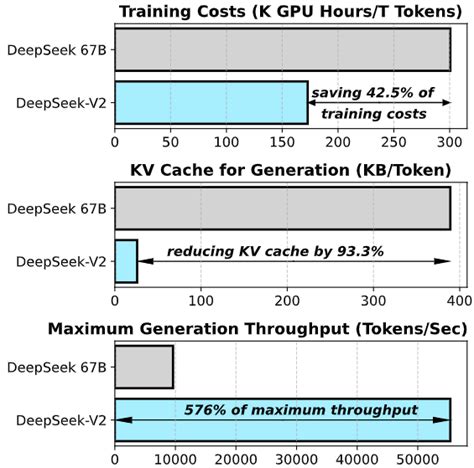
训练成本与效率
DeepSeek V3的训练成本非常低,仅消耗了不到280万GPU小时,总成本为557.6万美元,相比其他顶尖模型如Llama 3-405B和Claude 3.5 Sonnet,成本显著降低。
-
推理性能
模型生成速度高达每秒60吞吐量(TPS),是前代版本DeepSeek V2的三倍。此外,其在多种任务中表现出色,例如文本生成、代码完成、数学推理等。 -
多模态支持
尽管DeepSeek V3在多模态输入输出方面尚不支持,但其在图像识别、语音处理等领域仍具备一定潜力。
性能表现
-
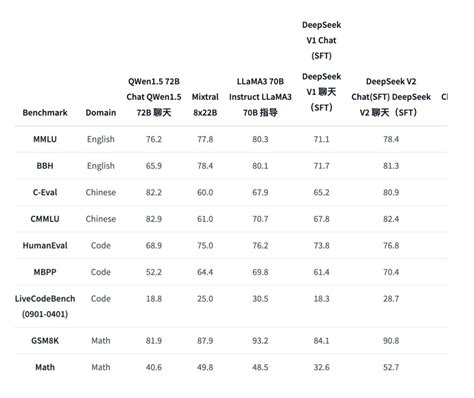
跨领域评测
DeepSeek V3在多个基准测试中超越了国内外其他开源模型,例如Qwen2-75B、Llama 3-1.4B等。在数学能力方面,其表现甚至超过了美国数学竞赛和全国高中数学联赛题库中的题目。
-
具体领域优势
- 知识类任务:如MMLU、GPQA等,DeepSeek V3的表现接近Claude 3.5 Sonnet-1022。
- 代码生成:在Codeforces等算法类场景中大幅领先其他非o1模型,在工程类代码场景中仅次于Claude 3.5 Sonnet。
- 中文能力:在教育类测评如C-E
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











