






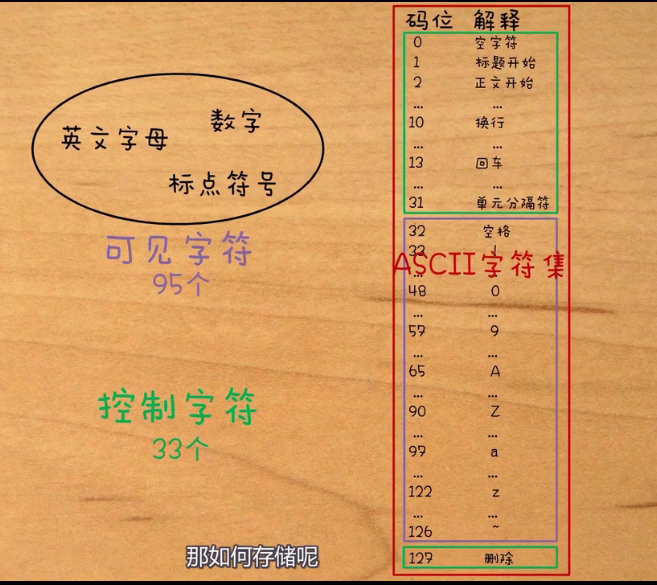
字符编码
ASCII码
字符集
如何把他们国家用到的一些字符存储在计算机里面
可见字符:字母 数字和标点符号
控制字符:肉眼不可见的,但是能对文本进行控制的字符
将可见字符和控制字符按顺序罗列编成0-127
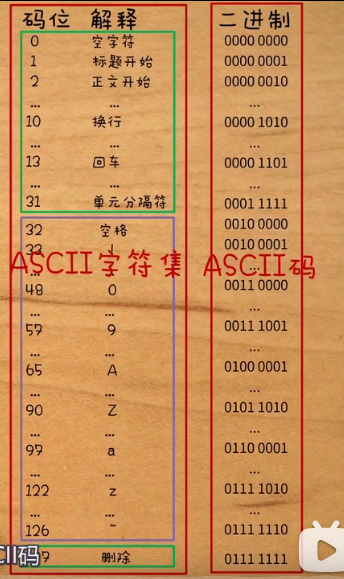
如何存储进计算机
直接将码位转换为二进制信息进行存储
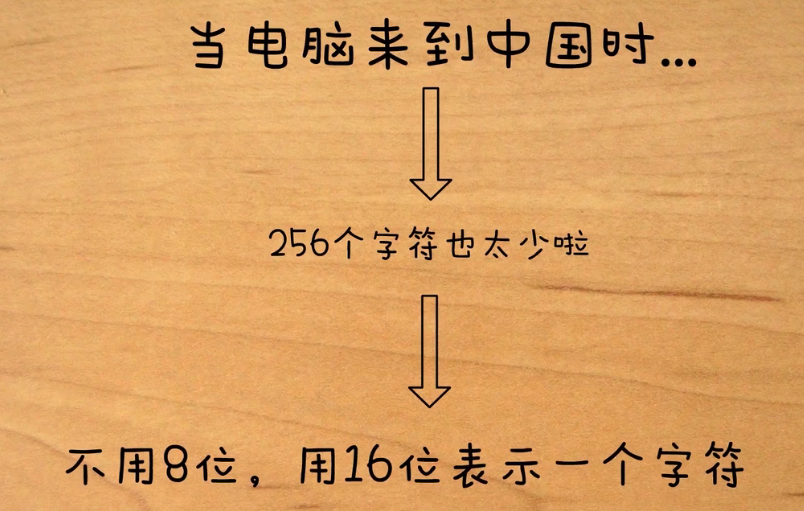
扩展ASCII码集
当欧洲人开始使用计算的时候,将最高位变成了1,新增了128个字符,即扩展ASCII字符集。

GBK字符集:16位
字符编码:对字符进行的编码
那前提得有一个字符集,然后再去编码
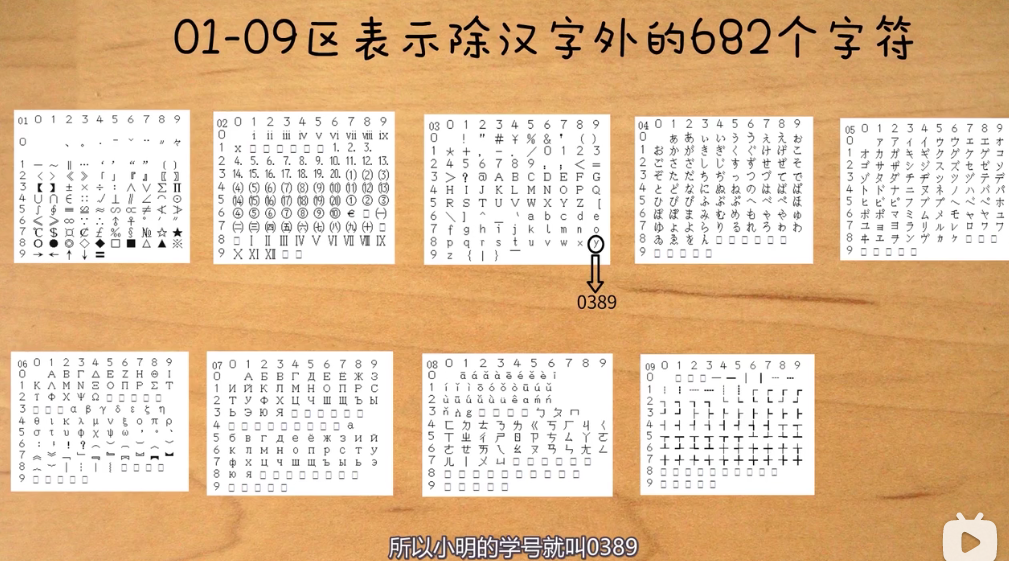
使用分区管理的方式去设计字符集

具体的分区设计
-
规定每个字符的码位
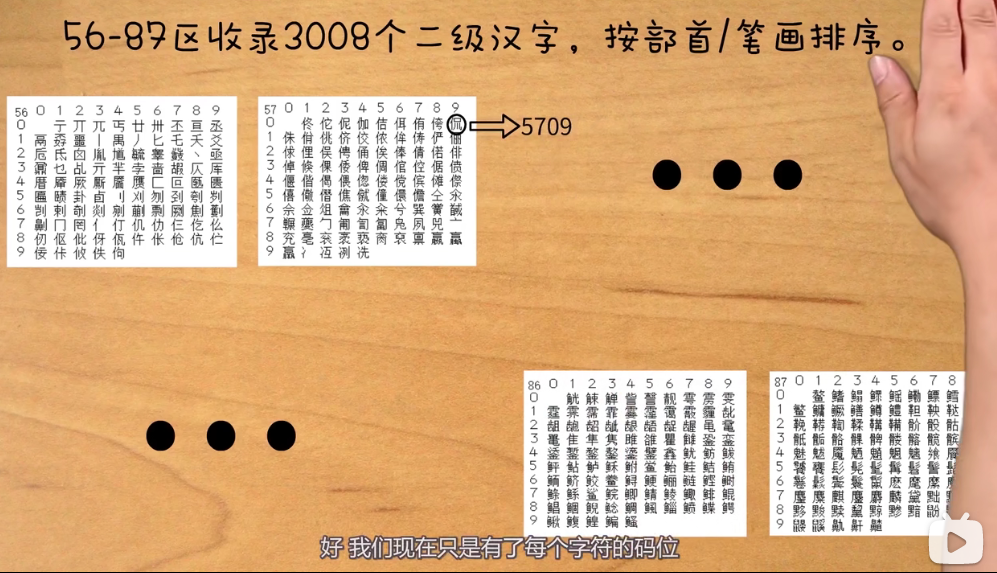
-
如何存储
-
将前2位和后2位分开,分别转换成16进制
-
然后分别加上0xA0,组合起来得到最后的码位

+A0的原因
因为A0=160,加上A0后高8位和低8位都是大于127的
使得计算机能够正确地区分GB2312和ASCII:
-
如果小于127,就是ASCII码;
-
如果碰到2个连续大于127的,就是GB;代表这2个组合成一个GB
GBK:只要碰到一个大于127的,就表示一个汉字的开始

unicode
诞生目的:把世界上所有的字符都放在一起
用32位,即4个字节来表示一个字符,基本上涵盖世界上所有的字符了
缺点
需要的存储空间大

utf-8
每次传送8位数据,可变长的编码方式
编码规则(要牢记):
-
单字节的字符,以0开头,后面7位来表示该字符的unicode码点
-
n字节的字符,第一个字节,前面n位设为1,第n+1位设为0,后面的字节都是以10开头,那空余的二进制位就用该字符的unicode码点填充,由后往前填充
https://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
https://blog.csdn.net/hezh1994/article/details/78899683
utf-16
基本平面内的字符就用2个字节来表示;
首先用码点减去0x10000算出超出的部分,然后用这个结果除以0x400得到它的高十位,最后+0xDB00得到最后的辅助平面内字符的高位,也就是高位的2个字节;
那么低位同理,取出超出部分的低10位+0xDC00,就得到了低位的2个字节;
H = Math.floor((c-0x10000) / 0x400)+0xD800
L = (c - 0x10000) % 0x400 + 0xDC00
base64编码
数字、大写字母、小写字母
-
原数据 -> ASCII码 -> 16进制
-
二进制形式
-
对二进制重新分割成6位的,用相应的十进制对照base64编码表
末尾不足的用0补齐,所以末尾会出现1个或2个=
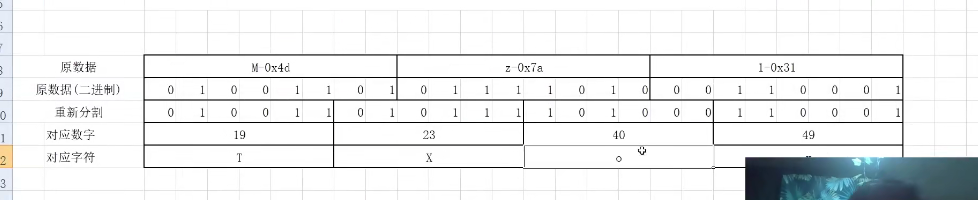

大部分是以不可见字符的形式存在的,而base64将数据转换成可见的字符的形式,用于http的传输。
https://blog.csdn.net/qq_20545367/article/details/79538530
https://www.qqxiuzi.cn/bianma/base64.htm
使用场景
-
发送邮件时的附件,邮件的smtp协议:对图片和二进制文件进行编码,对方接收到后再使用base64进行解码
-
http请求的header里面是不能有特殊字符的,否则没办法解析。所以遇到特殊字符就需要进行base64编码让浏览器可以解析。
-
图片中的使用。src为一个base64编码。在任何一个地方都可以跑起来,不需要任何依赖。(但是大图片不建议)
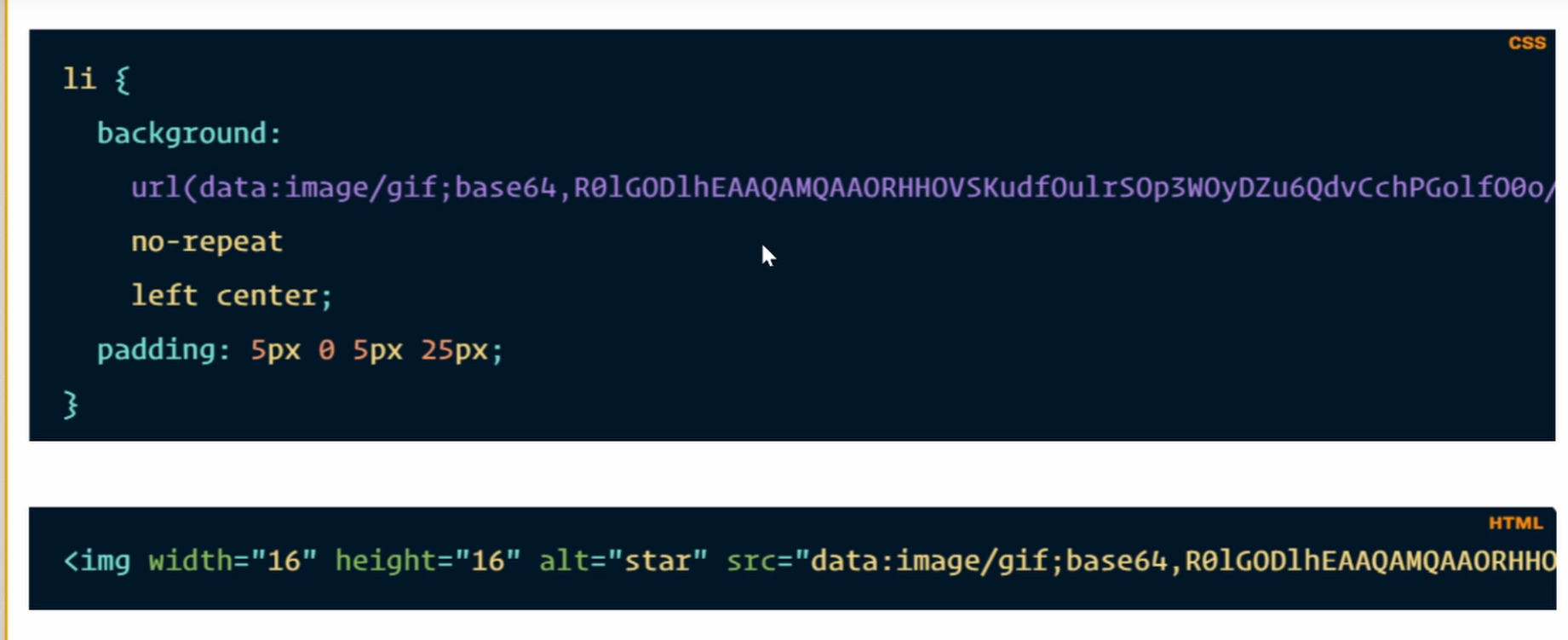
组成:大小写、数字0-9、+、/、=(表示空白)
base64面试
和加密的区别
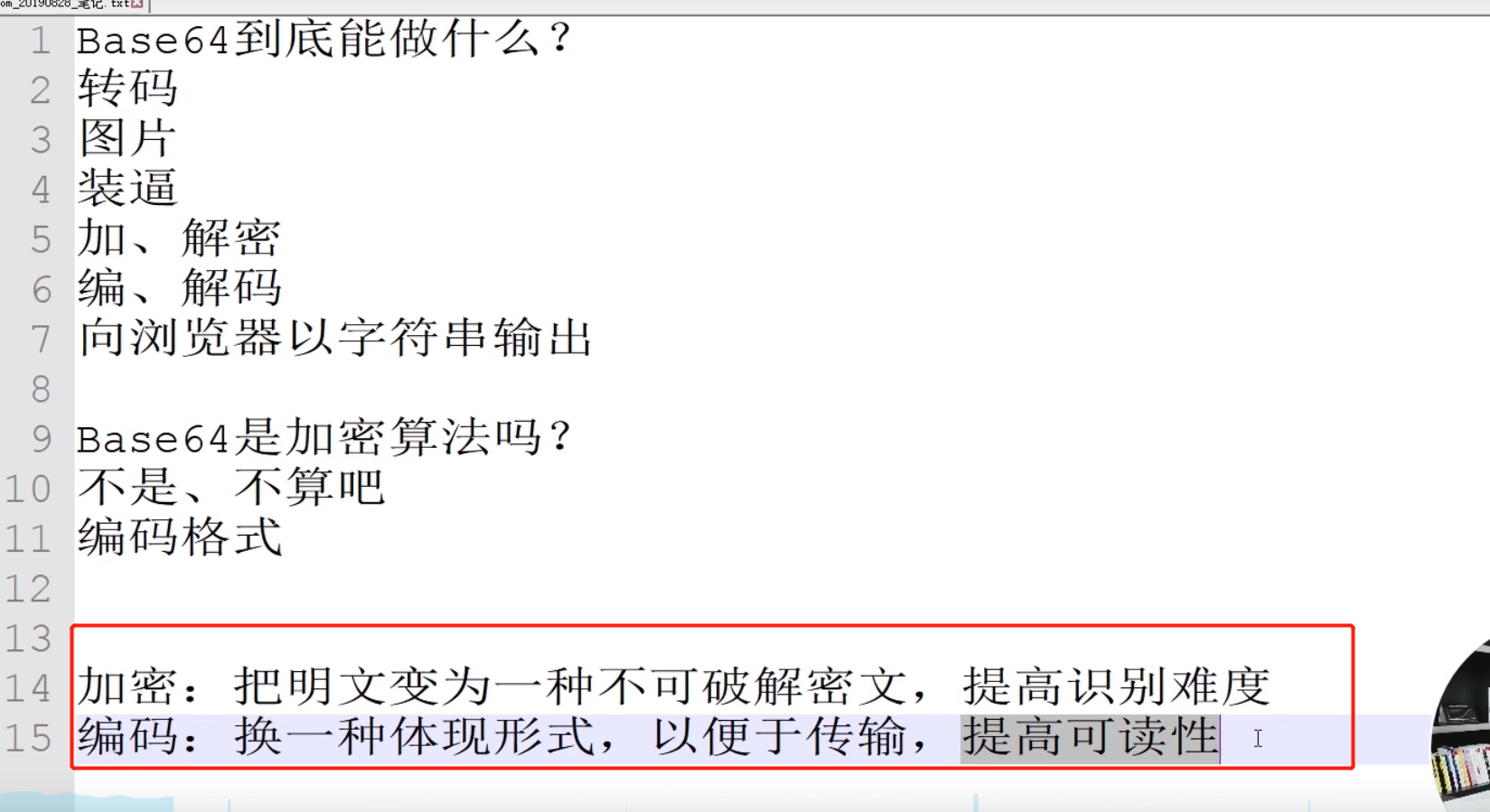
加密和编码的根本区别?
编码:换一种表达方式,使其更易于传输,提高可读性
加密:把明文变成一种不可破解的密文,提高识别难度(降低可读性)
什么情况下
对url的特殊字符进行转码
作为图片的src,不需要依赖一个路径,易于传输

算法原理
即编码规则。
获取当前系统的编码规则
cmd->chcp
936: GB2312
65001: utf-8
https://www.cnblogs.com/xpws/p/3625177.html
例子:网页上引入一张图片
-
一般我们会通过http地址
-
byte[] -> base64Encoder.encode
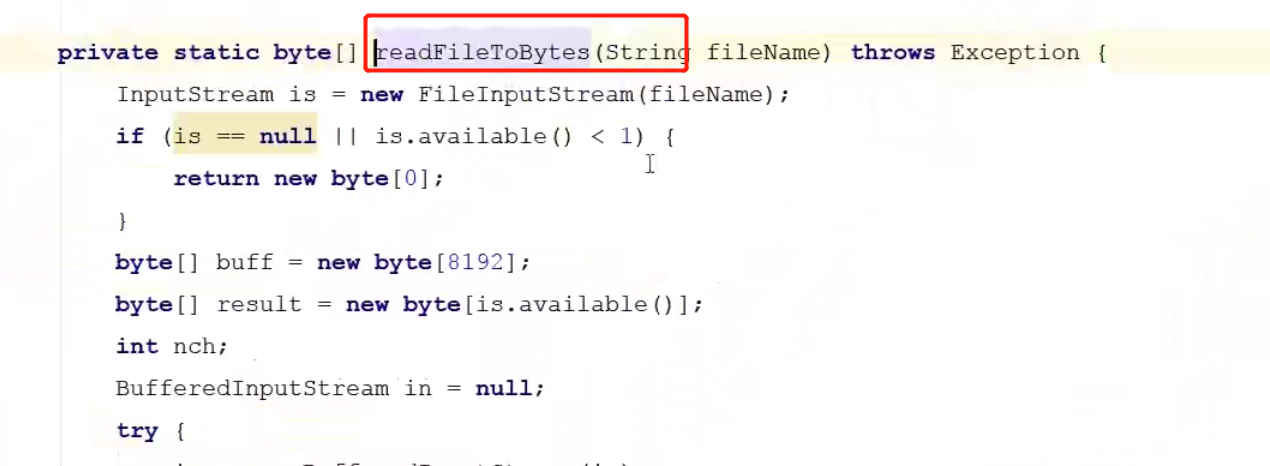
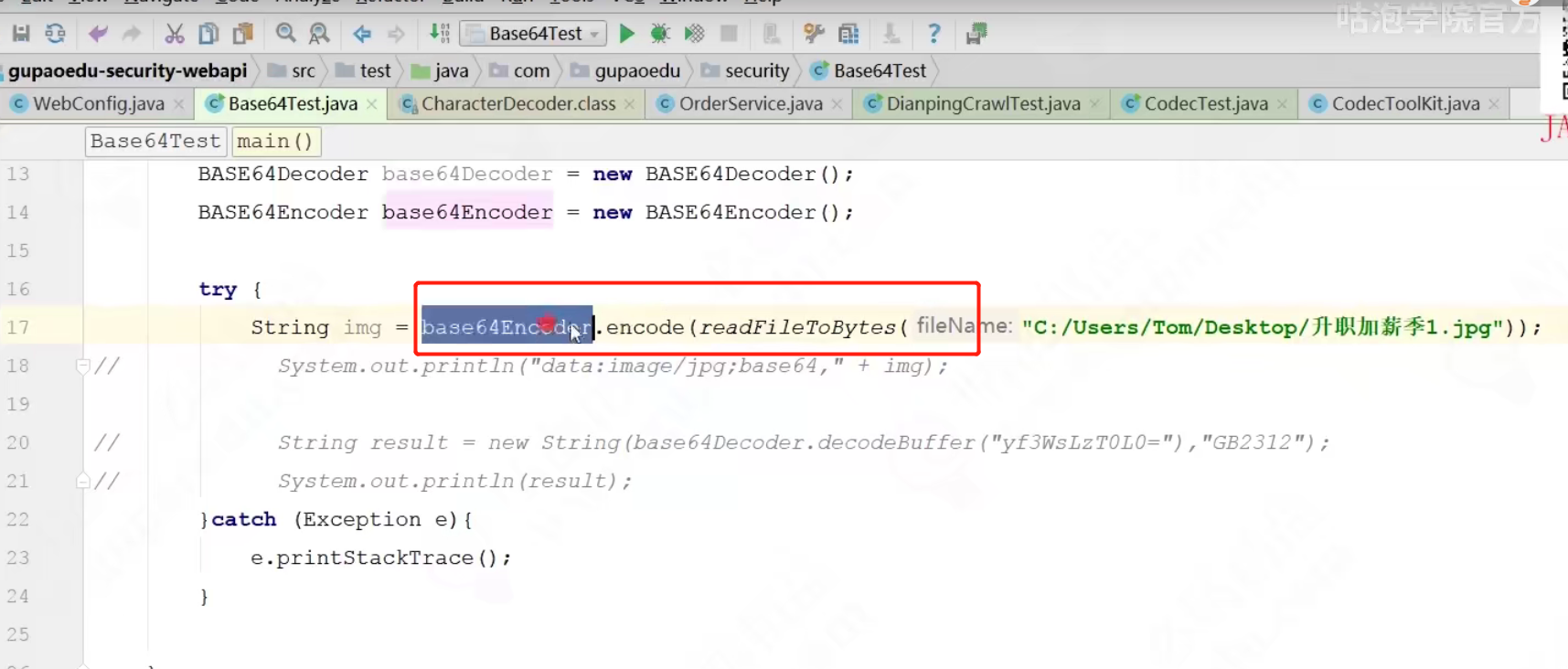
协议表示 data:img/jpg;base64,xxx















 1951
1951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









