







Pytho学习笔记(七)之Linux编程
前言
Linux系统搭建以及相关命令记录
一、Linux系统概述与安装
1.Linux
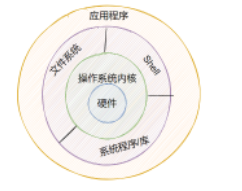
Linux内核
Linux内核是 Linux 操作系统主要组件,也是计算机硬件与其软件之间的交互入口。它负责两者之间的通信,还要尽可能高效地管理资源
Linux Shell
shell是系统的用户界面,提供了用户与内核进行交互操作的一种接口
Linux文件系统
文件系统是文件存放在磁盘等存储设备上的组织方法
Linux应用程序
标准的Linux系统一般都有一套都有称为应用程序的程序集,它包括文本编辑器、编程语言、办公套件等
2.虚拟机VM及虚拟机安装
VM安装成功:
安装Centos
官网地址:http://isoredirect.centos.org/centos/7/isos/x86_64/
创建虚拟机步骤:
1、主页点击创建虚拟机自定义:
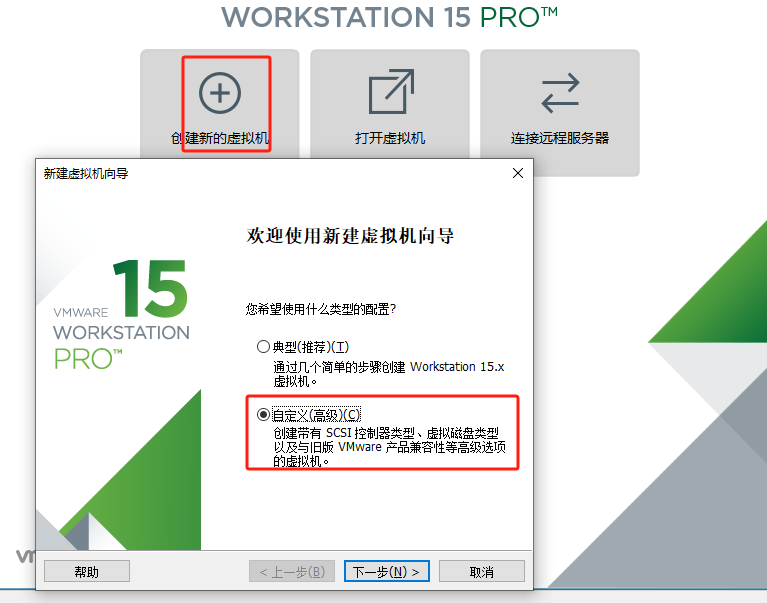
2、硬件兼容性保持默认:
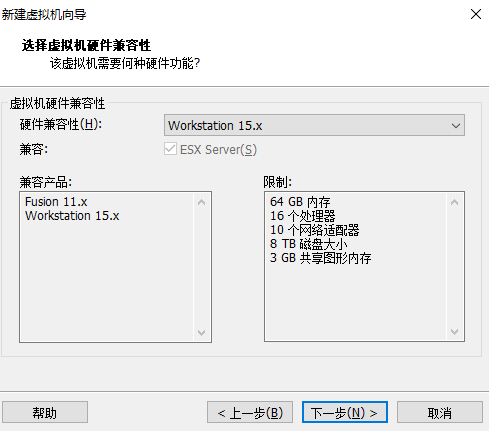
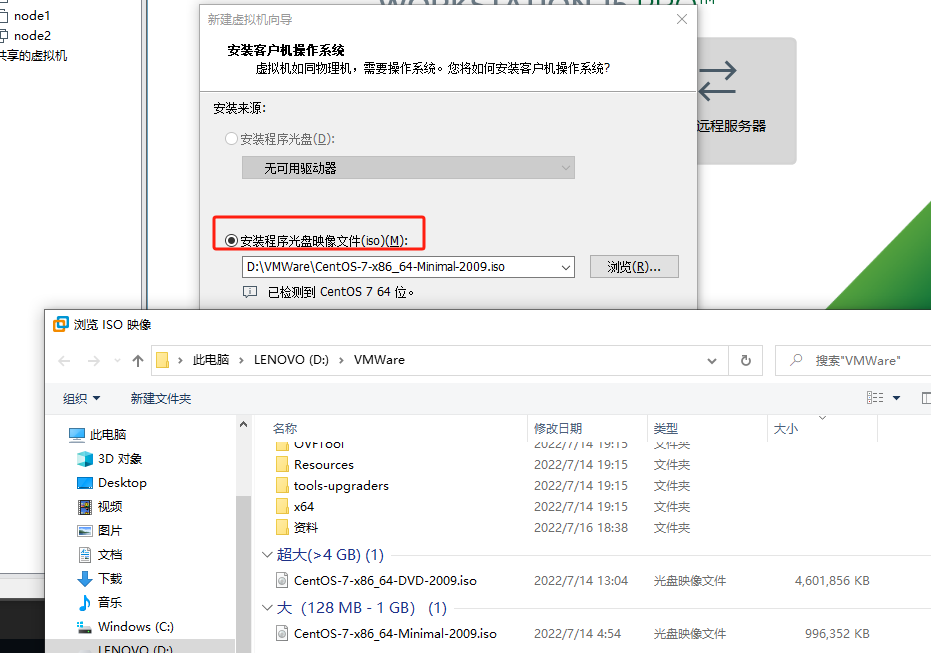
3、找到电脑中下载的磁盘iso文件进行安装:
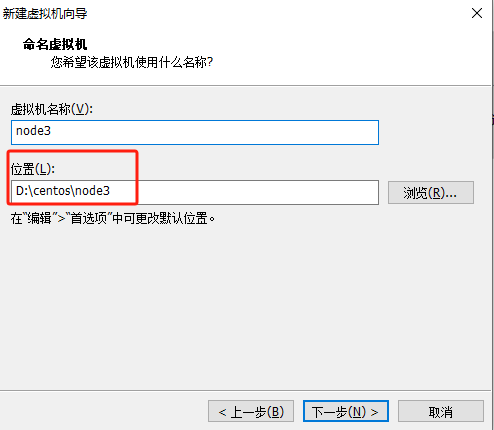
4、给虚拟机命名,并且统一管理
5、虚拟机的内存及网络配置均保持默认:
6、最后一步已完成配置准备创建:
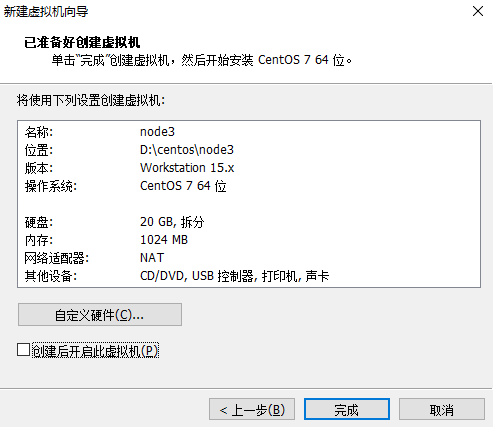
7、创建完成之后,进行虚拟机安装:

8、选择中文后点击继续:
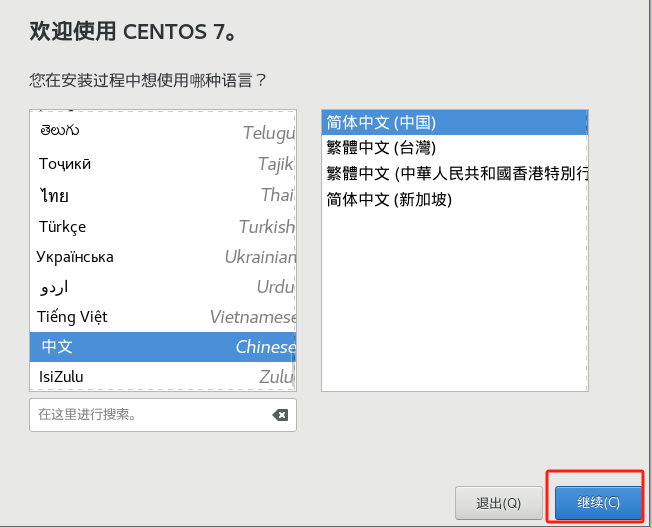
9、系统安装位置需要点击自动分区,无需设置,点击完成即可。

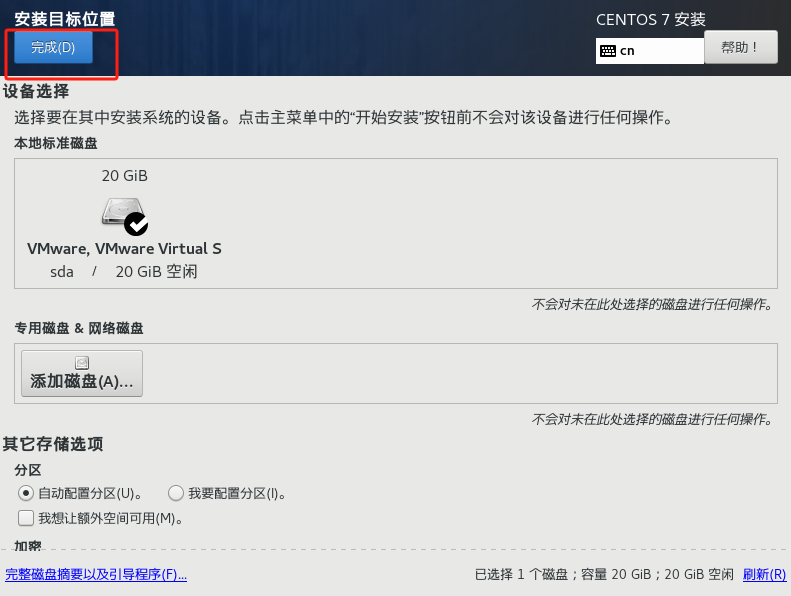
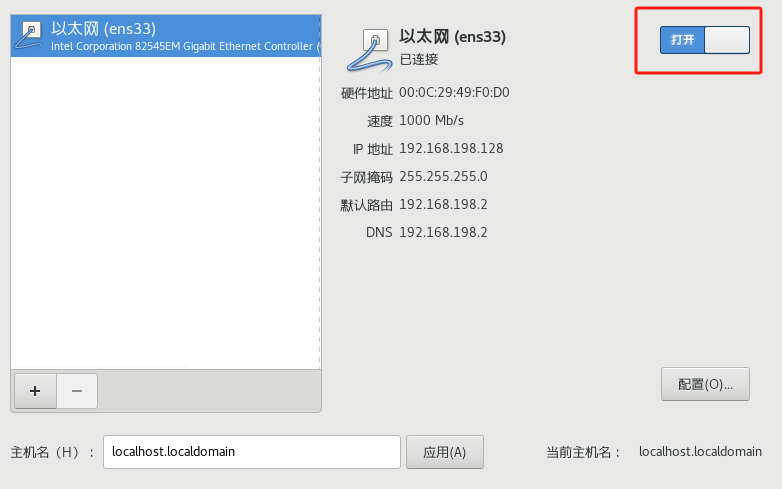
10、设置网络和主机名,将以太网按钮开启,获取ip地址
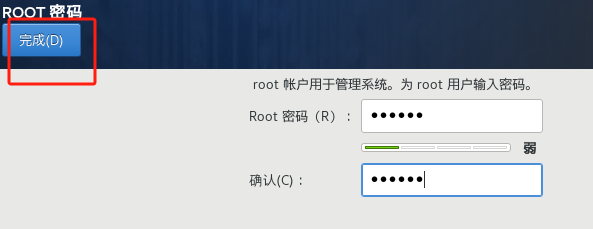
11、设置root密码,类似于超级管理员,创建用户为普通用户,此处设置超级密码为 123456

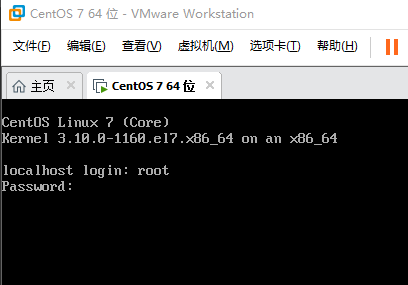
12、安装完成后重启,输入用户名和密码进入虚拟机:
安装过程中可能提示的报错:
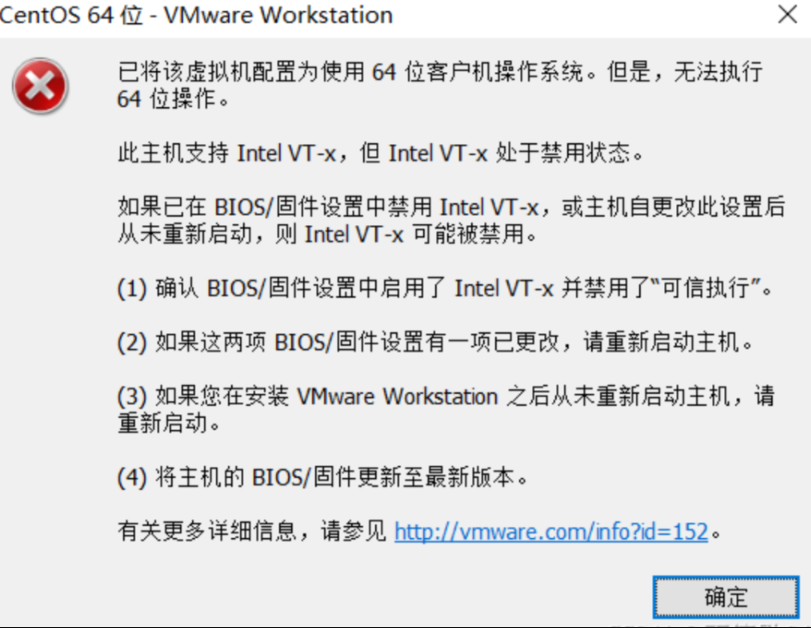
原因是没有开启虚拟化,可能通过任务管理器查看:
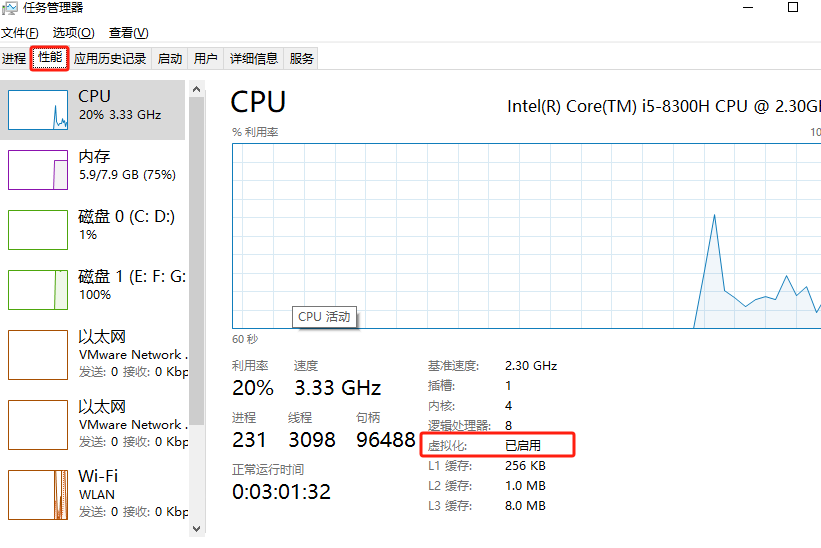
解决方案:bing中搜索 “某某电脑 如何开启虚拟化” 按步骤即可
3.SHELL工具
安装MobaXterm和虚拟机进行连接:
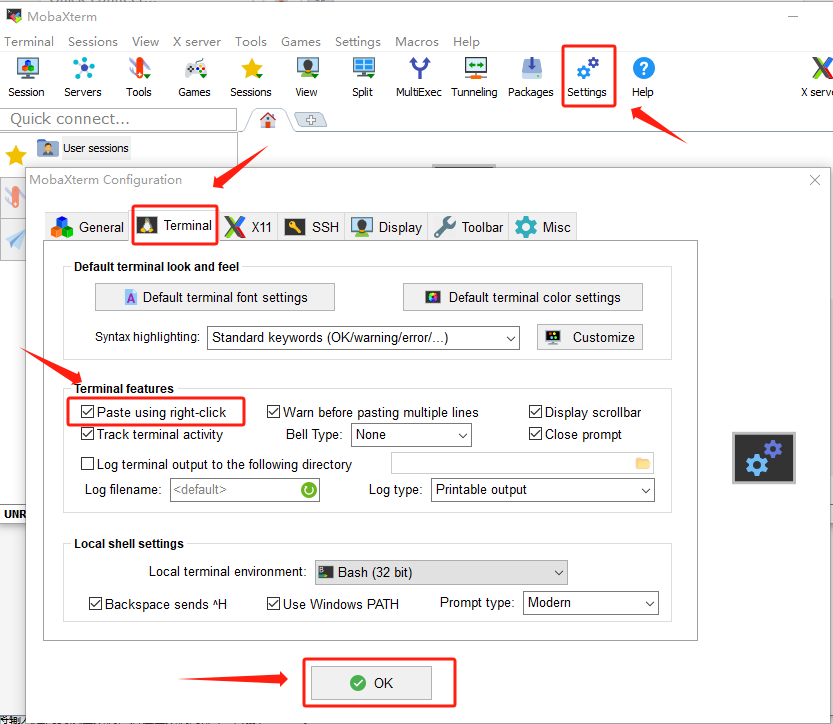
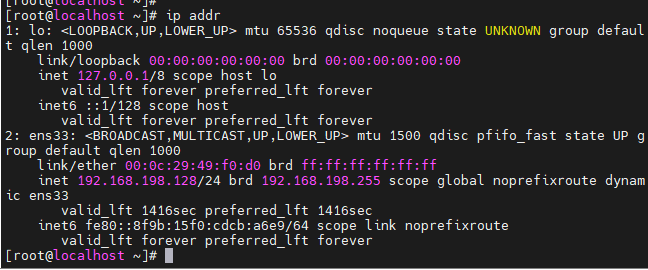
打开虚拟机查看ip地址为192.168.198.128,在moba中建立会话输入ip地址和用户名root
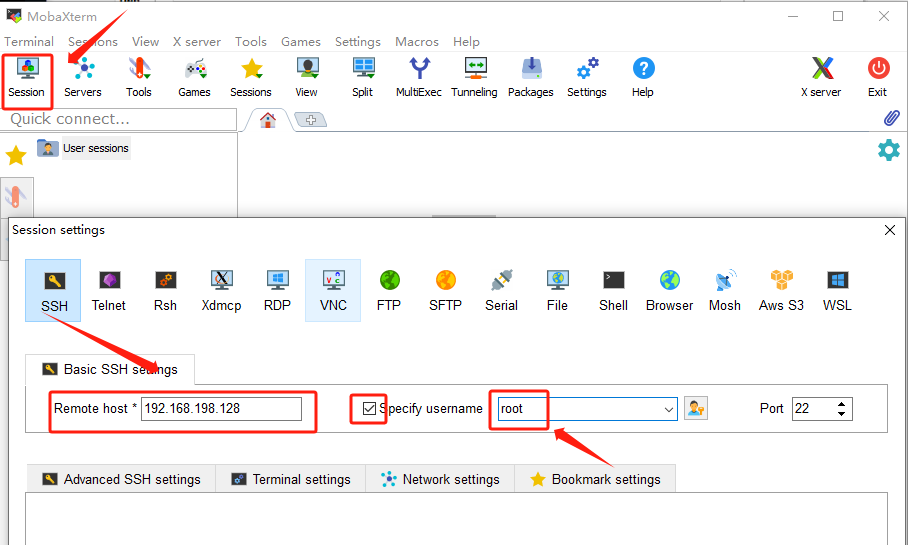
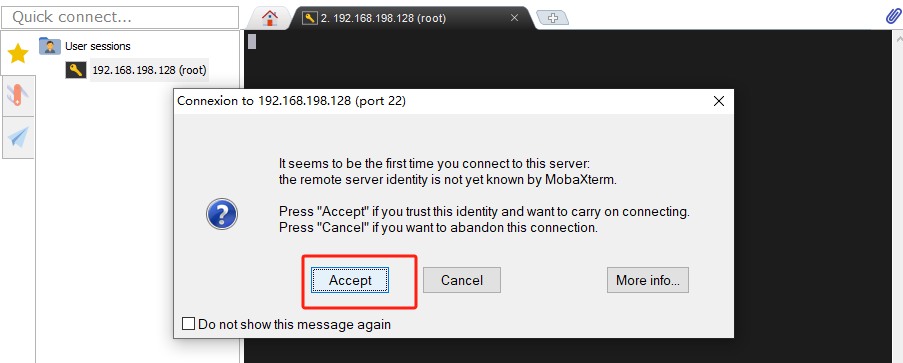
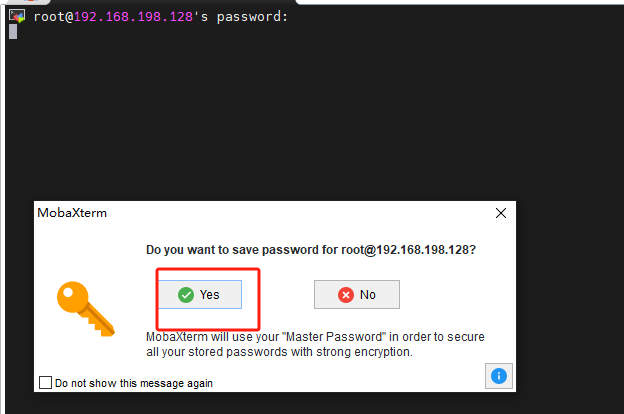
此处输入的密码是moba需要设置的密码,当换电脑设备或者账户时需要重新输入,此处设置为1234567
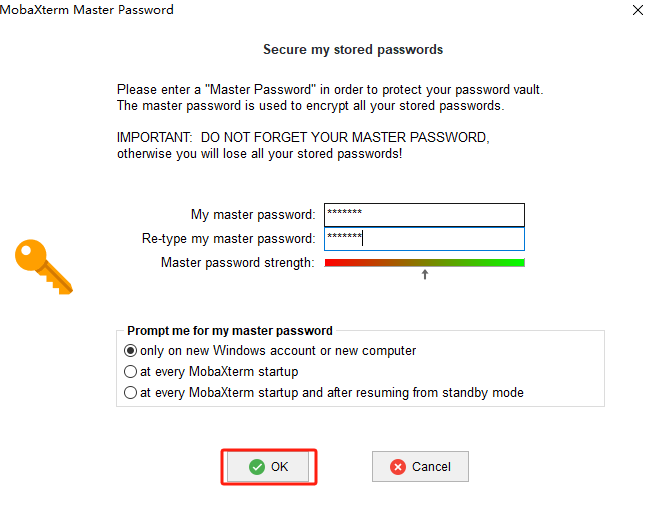
点击ok后即可进去:
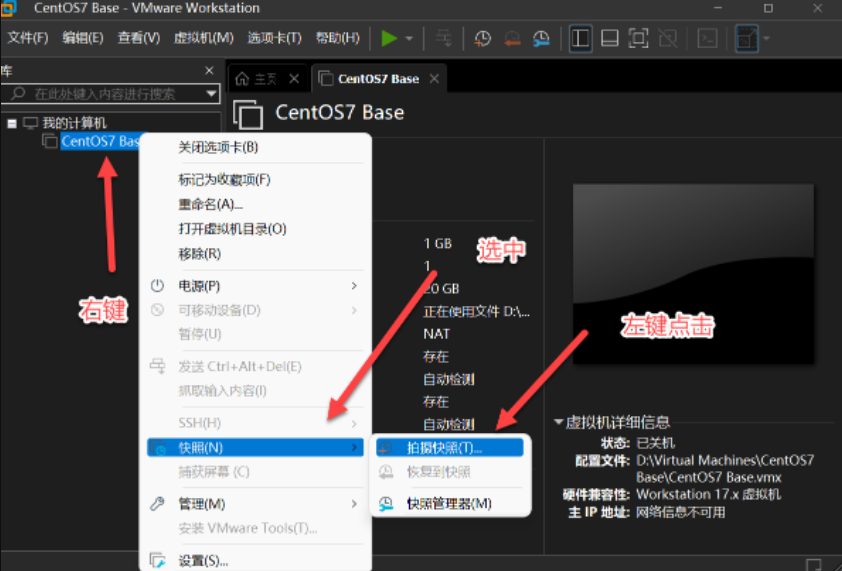
4.VMWare虚拟机快照
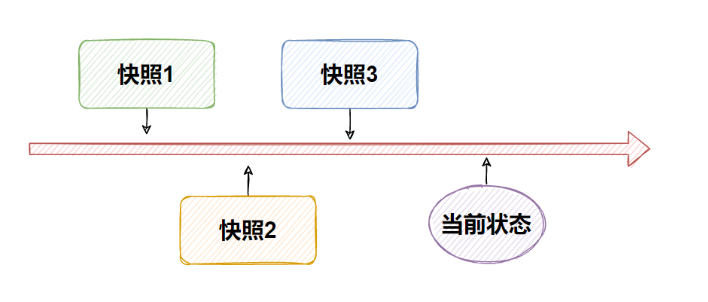
VMware虚拟机支持为虚拟机制作快照,通过快照将当前虚拟机的状态保存下来,在以后可以通过快照恢复虚拟机到保存的状态
快照制作需要虚拟机关机状态下
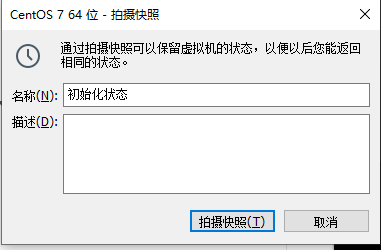
恢复快照:
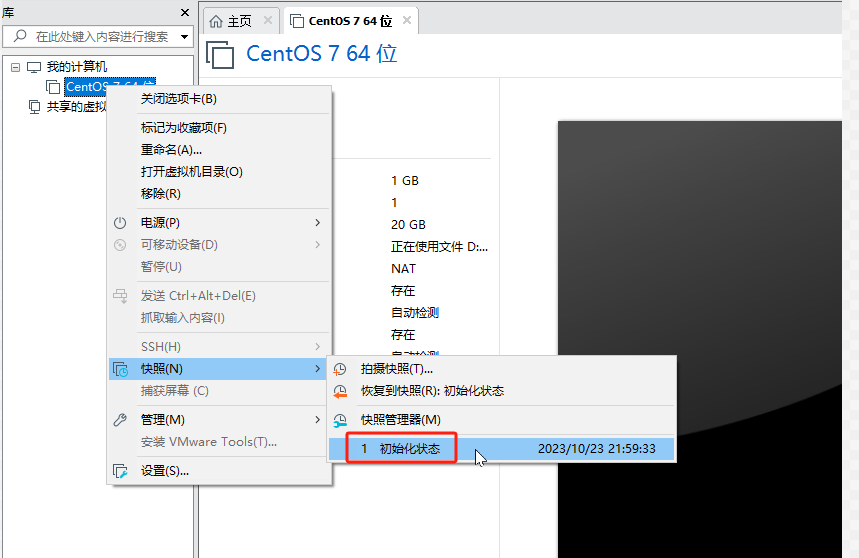
想要回到哪个状态的时候,打开快照管理器,点击“转到”即可。
克隆虚拟机:
二、Linux基本命令
1. 目录结构
Linux的目录结构是一个树型结构,Linux没有盘符这个概念, 只有一个根目录 /(对比Windows下的C、D盘符), 所有文件都在它下面。
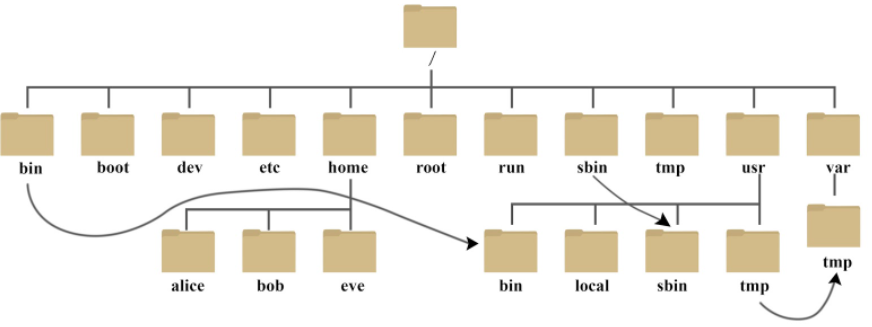
进入根目录查看所有文件:
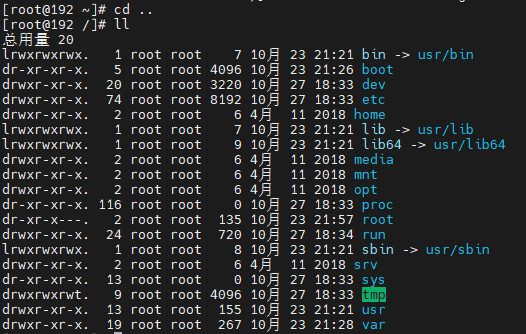
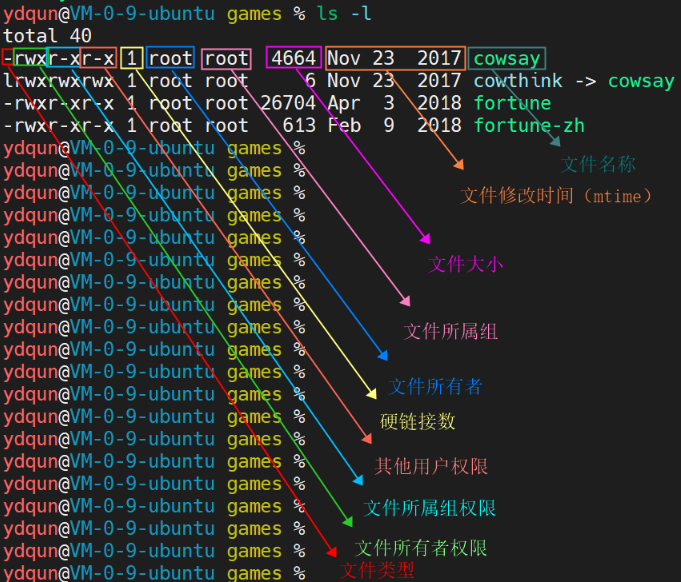
每个标识的含义:
目录的解释
系统启动必须:
- **/boot:**存放的启动Linux 时使用的内核文件,包括连接文件以及镜像文件。
- **/etc:**存放所有的系统需要的配置文件和子目录列表,更改目录下的文件可能会导致系统不能启动。
- /lib:存放基本代码库(比如c++库),其作用类似于Windows里的DLL文件。几乎所有的应用程序都需要用到这些共享库。
- /sys: 这是linux2.6内核的一个很大的变化。该目录下安装了2.6内核中新出现的一个文件系统 sysfs 。sysfs文件系统集成了下面3种文件系统的信息:针对进程信息的proc文件系统、针对设备的devfs文件系统以及针对伪终端的devpts文件系统。该文件系统是内核设备树的一个直观反映。当一个内核对象被创建的时候,对应的文件和目录也在内核对象子系统中。
指令集合:
- **/bin:**存放着最常用的程序和指令
- **/sbin:**只有系统管理员能使用的程序和指令。
外部文件管理:
- /dev :Device(设备)的缩写, 存放的是Linux的外部设备。注意:在Linux中访问设备和访问文件的方式是相同的。
- /media:类windows的其他设备,例如U盘、光驱等等,识别后linux会把设备放到这个目录下。
- /mnt:临时挂载别的文件系统的,我们可以将光驱挂载在/mnt/上,然后进入该目录就可以查看光驱里的内容了。
临时文件:
- /run:是一个临时文件系统,存储系统启动以来的信息。当系统重启时,这个目录下的文件应该被删掉或清除。如果你的系统上有 /var/run目录,应该让它指向 run。
- /lost+found:一般情况下为空的,系统非法关机后,这里就存放一些文件。
- /tmp:这个目录是用来存放一些临时文件的。
账户:
- /root:系统管理员的用户主目录。
- /home:用户的主目录,以用户的账号命名的。
- /usr:用户的很多应用程序和文件都放在这个目录下,类似于windows下的program files目录。
- /usr/bin:系统用户使用的应用程序与指令。
- /usr/sbin:超级用户使用的比较高级的管理程序和系统守护程序。
- /usr/src:内核源代码默认的放置目录。
运行过程中要用:
- /var:存放经常修改的数据,比如程序运行的日志文件(/var/log 目录下)。
- /proc:管理内存空间!虚拟的目录,是系统内存的映射,我们可以直接访问这个目录来,获取系统信息。这个目录的内容不在硬盘上而是在内存里,我们也可以直接修改里面的某些文件来做修改。
扩展用的:
- /opt:默认是空的,我们安装额外软件可以放在这个里面。
- /srv:存放服务启动后需要提取的数据(不用服务器就是空)
特殊的:
- . :代表当前的目录,也可以使用 ./ 来表示;
- … :代表上一层目录,也可以 …/ 来代表;
- ~ : 代表登录用户的家目录
- root: /root
- user: /home/user
- / : 代表系统的根目录
2. 绝对路径和相对路径
路径指的是在文件系统中访问文件或目录时需要经过的路线:
- 绝对路径: 路径的写法,由根目录 / 写起,例如: /etc/ssh 这个目录
- 相对路径: 路径的写法,不是由 / 写起,例如由 /etc/ssh 要到 /etc/ssl 底下时,可以写成: cd …/ssl
# /etc/ssh 到 /etc/python
../python
# /etc/ssh 到 /usr
../../usr
# /etc/ssh 到 /home/user/test
../../home/user/test
# /etc/ssh 到 /etc
../
# /etc 到 /etc/ssh
./ssh 或者 ssh
3. 命令基础
在Linux中,无论是什么命令,有什么用途,命令都有通用的格式:
command [-options] [parameter]
- command: 命令本身
- options:[可选,非必填] 命令的一些选项,可以通过选项控制命令的行为细节
- parameter:[可选,非必填] 命令的参数值
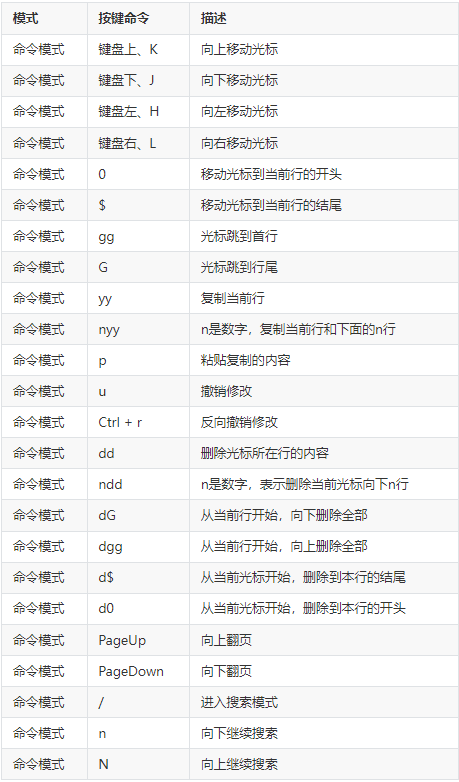
3.1 ls命令
ls命令用于显示指定工作目录下内容,语法细节如下:
ls [-alrtAFR] [name…]
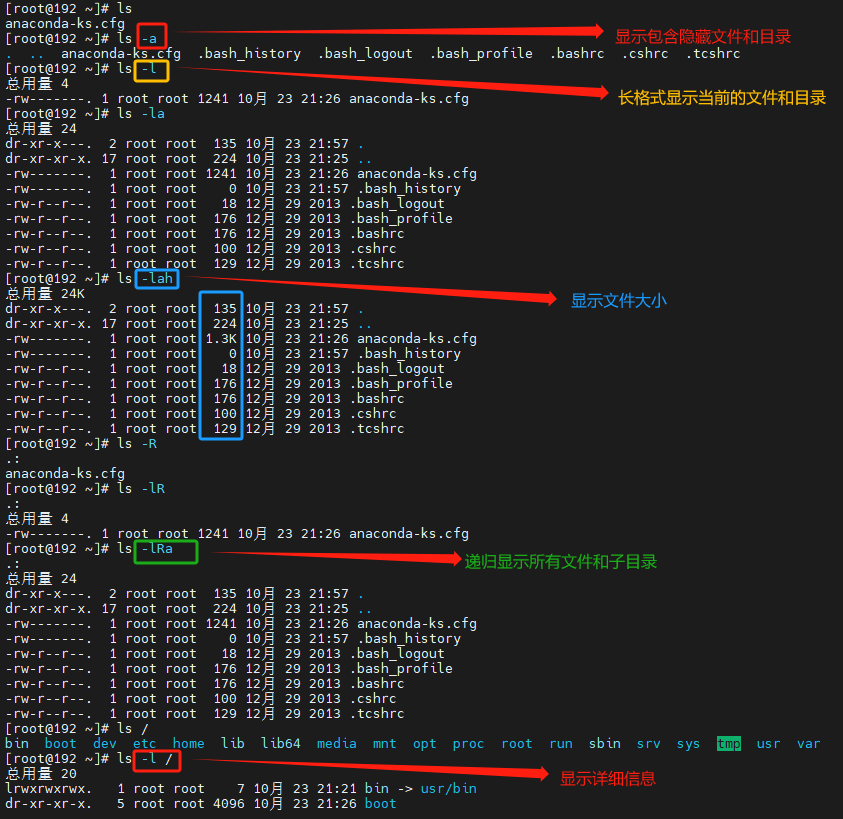
- -a 显示所有文件及目录 (. 开头的隐藏文件也会列出)
- -d 只列出目录(不递归列出目录内的文件)
- -l 以长格式显示文件和目录信息,包括权限、所有者、大小、创建时间等。
- -r 倒序显示文件和目录。
- -t 将按照修改时间排序,最新的文件在最前面。
- -A 同 -a ,但不列出 “.” (目前目录) 及 “…” (父目录)
- -F 在列出的文件名称后加一符号;例如可执行档则加 “*”, 目录则加 “/”
- -R 递归显示目录中的所有文件和子目录。
ls -l # 以长格式显示当前目录中的文件和目录
ls -a # 显示当前目录中的所有文件和目录,包括隐藏文件
ls -lh # 以人类可读的方式显示当前目录中的文件和目录大小
ls -t # 按照修改时间排序显示当前目录中的文件和目录
ls -R # 递归显示当前目录中的所有文件和子目录
ls -l /etc/passwd # 显示/etc/passwd文件的详细信息
4. 获取命令帮助
主要就是help 参数、man命令两种方式。
命令的配置
要查看命令的详细手册,man(manual手册),语法如下:
man command
默认显示的是英文。如果想要改成中文,需要系统是中文的,具体命令是如下:
[root@node1 ~]# echo $LANG
zh_CN.UTF-8 # 中文
en_US.UTF-8 # 英文
修改成中文
[root@node1 ~]# LANG=“zh_CN.UTF-8”
上面修改方式是临时的,重启后,会还原原来的样子
彻底解决方案:
修改 /etc/locale.conf文件,设置内容为LANG=zh_CN.UTF-8
安装中文包
[root@node1 ~]# yum install man-pages-zh-CN -y
命令的使用
- j/enter 向下一行
- k 向上一行
- f/空格/PG Down 按页向下翻
- b/Page UP 向上翻页
- p 直接翻到首页
- 查找按 / 要查找的内容
- n查找下一个
- N 上一个
- q 退出
扩展使用
man命令后可以有一个数字,可以了解或者是直接查询相关的资料
man [数字][参数]
1 用户命令(/bin,/usr/bin,/usr/local/bin)
2 系统调用
3 库函数
4 特殊文件(设备文件)
5 文件格式(配置文件的语法)
6 游戏
7 杂项(Miscellaneous)
8 管理命令(/sbin,/usr/sbin,/usr/local/sbin)
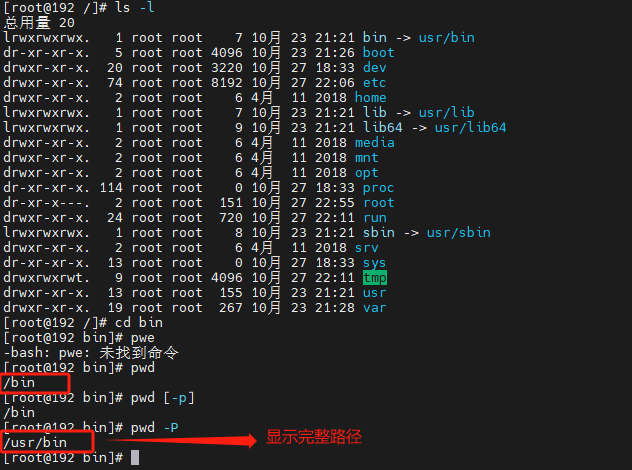
5. cd与pwd命令的使用
cd
当Linux终端(命令行)打开的时候,会默认以用户的HOME目录作为当前的工作目录,可以通过cd命令,更改当前所在的工作目录,cd (change directory): 切换目录, 用来变换工作目录的命令:
cd [路径]
pwd
pwd (print work directory):显示目前所在目录的命令
[root@www ~]# pwd [-P]
-p 会不以链接档的数据显示,而是显示正确的完整路径
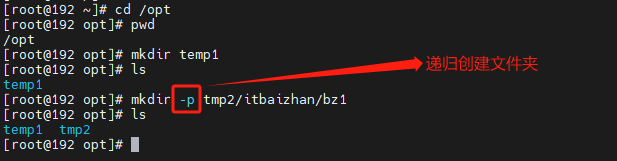
6.mkdir与rmdir的使用
mkdir
mkdir(make directory):创建一个新的目录
mkdir [-p] 目录名称
-p :直接将所需要的目录(包含上一级目录)递归创建起来
rmdir
rmdir(remove directory):删除一个空的目录
rmdir [-p] 目录名称
-p :从该目录起,一次删除多级空目录,把路径写全

7.cat_tac_more_less查看文件内容
cat 适合查文本内容较少的
cat 由第一行开始显示文件内容
cat [-AbEnTv]
-A :相当于 -vET 的整合选项,可列出一些特殊字符而不是空白而已;
-b :列出行号,仅针对非空白行做行号显示,空白行不标行号!
-E :将结尾的断行字节 $ 显示出来;
-n :列印出行号,连同空白行也会有行号,与 -b 的选项不同;
-T :将 [tab] 按键以 ^I 显示出来;
-v :列出一些看不出来的特殊字符
tac
tac与cat命令刚好相反,文件内容从最后一行开始显示
more 适合查文本内容多的
一页一页翻动,看完就结束了,自动退出
more path
按键可以按:
空白键 (space) :代表向下翻一页
Enter :代表向下翻『一行』
/字串 :代表在这个显示的内容当中,向下搜寻『字串』这个关键字
q :代表立刻离开 more ,不再显示该文件内容
b :代表往回翻页
less
一页一页翻动,看完还可以回翻
less path
按键可以按:
空白键 :向下翻动一页;
pagedown :向下翻动一页;
pageup :向上翻动一页;
/字串 :向下搜寻『字串』的功能;
?字串 :向上搜寻『字串』的功能;
n :重复前一个搜寻 (与 / 或 ? 有关!)
N :反向的重复前一个搜寻 (与 / 或 ? 有关!)
q :离开 less 这个程序;
head 适合查看文件部分内容
取出文件前面几行,默认显示前10行
head [-n number] 文件
-n :后面接数字,代表显示几行的意思
tail
取出文件后面几行
tail [-n number] 文件
-n :后面接数字,代表显示几行的意思
-f :表示持续侦测后面所接的档名,要等到按下ctrl + c 才会结束tail的侦测
echo “” >> [文本]
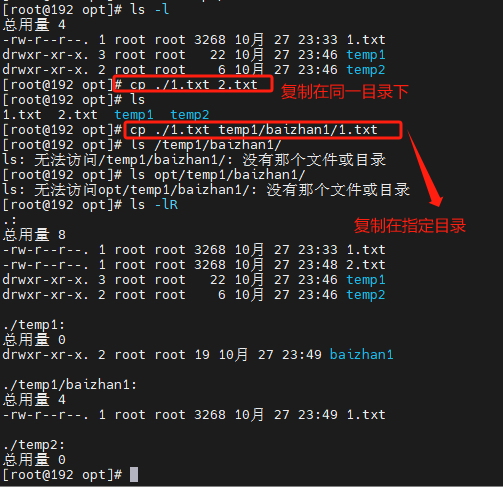
8.cp_mv_rm命令 ——操作文件与文件夹
cp
cp(copy) 即拷贝文件和目录
cp [-adfilprsu] 来源档(source) 目标档(destination)
-a:相当于 -pdr 的意思,至于 pdr 请参考下列说明;(常用)
-d:若来源档为链接档的属性(link file),则复制链接档属性而非文件本身;
-f:为强制(force)的意思,若目标文件已经存在且无法开启,则移除后再尝试一次;
-i:若目标档(destination)已经存在时,在覆盖时会先询问动作的进行(常用)
-l:进行硬式链接(hard link)的链接档创建,而非复制文件本身;
-p:连同文件的属性一起复制过去,而非使用默认属性(备份常用);
-r:递归持续复制,用于目录的复制行为;(常用)
-s:复制成为符号链接档 (symbolic link),亦即『捷径』文件
mv
mv(move) 移动文件与目录,或修改名称
mv [-fiu] 源文件/夹 目录文件/夹
-f :force 强制的意思,如果目标文件已经存在,不会询问而直接覆盖;
-i :若目标文件 (destination) 已经存在时,就会询问是否覆盖!
-u :若目标文件已经存在,且 source 比较新,才会升级 (update)

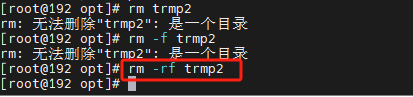
rm
rm (remove) 移除文件或目录
rm [-fir] 文件或目录
-f :就是 force 的意思,忽略不存在的文件,不会出现警告信息;
-i :互动模式,在删除前会询问使用者是否动作
-r :递归删除,最常用在目录的删除
注意
千万不要用root管理员用户执行:rm -rf / 效果等同于在Windows上执行C盘格式化
**通配符 ***
符号* 表示通配符,即匹配任意内容(包含空)
temp*,表示匹配任何以temp开头的内容
*temp,表示匹配任何以temp结尾的内容
temp,表示匹配任何包含temp的内容

9.which_find查找命令
which
which命令用于查找命令文件,在哪个目录
which 命令

find
在Linux系统中,我们可以通过find命令去搜索指定的文件
find 搜索的路径 -name “被查找的文件名”

10.grep_wc_管道符的使用
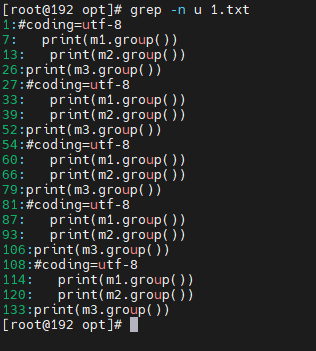
grep
grep(global regular expression print)是一种常用的文本搜索工具,用于在文本或文件中查找特定的字符串。
grep [-abcEFGhHilLnqrsvVwxy] pattern files
pattern - 表示要查找的字符串或正则表达式
files - 表示要查找的文件名,可以同时查找多个文件
-i:忽略大小写进行匹配。
-v:反向查找,只打印不匹配的行。
-n:显示匹配行的行号。
-r:递归查找子目录中的文件。
-l:只打印匹配的文件名。
-c:只打印匹配的行数。
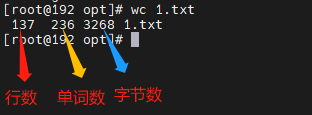
wc
wc命令可以计算文件的Byte数、字数、或是列数
wc [-clw][–help][–version][文件…]
-c/–bytes或-m/–chars 只显示Bytes数。
-l或–lines 显示行数。
-w或–words 只显示字数。
–help 在线帮助。
–version 显示版本信息。
管道符 |
管道符号| 通过将前一个命令的输出直接传递给后一个命令作为输入,从而构建起用于多个命令的连接方式
例如:
在当前目录下查找所有以.txt结尾的文件名并输出到终端的功能
ls | grep .txt
列出目录/etc中以pass开头的文件或目录名
ls /etc | grep ^pass
查看当前目录下文件tmp.txt,将结果传递来 grep 过滤出包含66 ,将结果传递来 grep 过滤出包含 1 的数据
cat tmp.txt |grep 66 | grep 1
应用场景:
- 数据处理:Linux管道符可以方便地用于对文件或文本进行处理
- 系统管理:Linux系统管理员经常使用管道符来执行多个命令以达到管理系统的目的
- 网络通信:在网络编程领域,管道符也被广泛应用
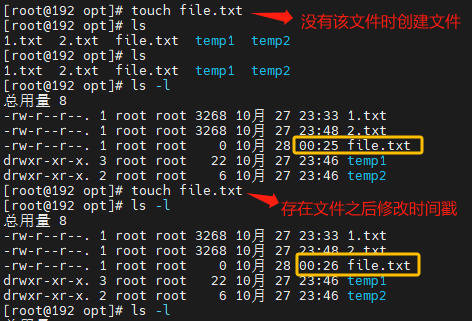
11.touch、echo的使用
touch
touch 命令在 Linux 操作系统中用于创建文件或修改文件的时间戳
如果指定的文件不存在,则会创建一个新的空白文件
touch 文件路径
常见用法
创建新文件
创建名为 file.txt 的新文件
touch file.txt
更改文件时间戳
更新名为 file.txt 文件的修改时间戳
touch file.txt
创建多个文件
创建三个名为 file1.txt、file2.txt 和 file3.txt 的文件
touch file1.txt file2.txt file3.txt
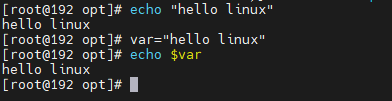
echo
echo 用于在终端上输出一些文本信息
echo [option] string
常见用法
输出字符串(最基本的用法)
在终端上输出 Hello, Linux 字符串
echo “Hello,Linux”
显示 Shell变量
命令将在终端上输出 Hello, Linux。
myvar=“Hello, Linux”
echo $myvar
输出到文件
可以使用重定向符号 > 将 echo 命令的输出保存到一个文件中,将 Hello,Linux! 并将其保存到一个名为 myfile.txt 的文件中
echo “Hello, Linux!” > myfile.txt
12.重定向符
重定向符包括 >, <, >>, << 等符号
常用用法
“>”:将命令的标准输出重定向到一个文件中,例如:
ls -l > file.txt
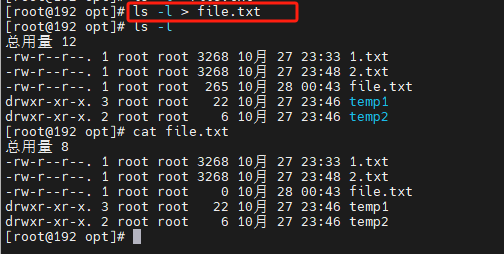
这个命令将列出当前目录下的文件,并将结果输出到一个名为 file.txt 的文件中。如果该文件不存在,则会创建它;如果存在,则会覆盖原有内容
“>>”:将命令的标准输出追加到一个文件中,例如:
echo “Hello, World!” >> file.txt
这个命令将在 file.txt 文件的末尾添加一行文本。如果该文件不存在,则会创建它
“<”:使用一个文件的内容作为命令的标准输入,例如:
sort < file.txt
这个命令将读取 file.txt 文件中的内容,并将其传递给 sort 命令,该命令对输入进行排序
“<<”:将一个字符串作为命令的标准输入,例如:
grep ‘hello’ << EOF
Hello, World!
Goodbye, World!
EOF
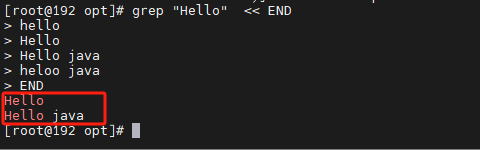
这个命令将使用 grep 命令来查找包含 hello 字符串的行。字符串 EOF 用于指定输入的结束,之间的文本将作为标准输入
注意:
重定向符号还可以结合管道符一起使用
ls -l | grep “.txt” > filelist.txt
这个命令将列出当前目录下的所有文件,并将其中包含 .txt 字符串的文件名保存到一个名为 filelist.txt 的文件中
13.VIM介绍和使用
13.1编辑器的三种模式
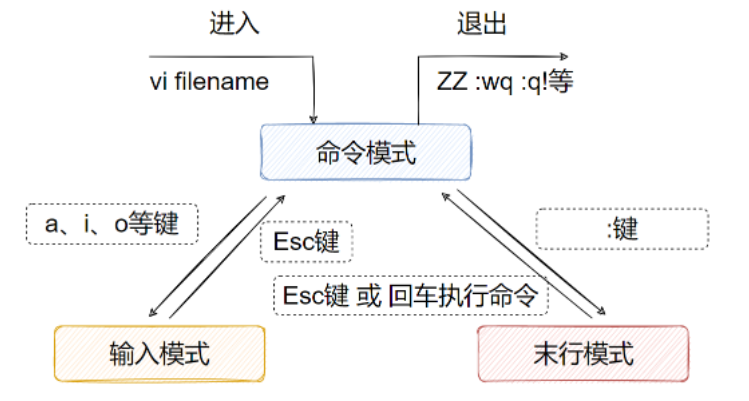
命令模式(Command mode)
命令模式下,所敲的按键编辑器都理解为命令,以命令驱动执行不同的功能,此模型下,不能自由进行文本编辑
输入模式(Insert mode)
也就是所谓的编辑模式、插入模式,此模式下,可以对文件内容进行自由编辑
末行模式(Last line mode)
通常用于文件的保存、退出,此模型下,不能自由进行文本编辑
13.2基本使用
打开文件
VIM命令若是没有,可以使用yum install vim -y安装
vim filename: 打开文件,并定位第1行
vim filename +# :打开文件,并定位于第#行
vim filename +:打开文件,定位至最后一行
vim filename +/PATTERN : 打开文件,定位至第一次被PATTERN匹配到的行的行首
注意
如果文件路径表示的文件不存在,那么此命令会用于编辑新文件
如果文件路径表示的文件存在,那么此命令用于编辑已有文件
打开文件后,默认是命令模式
编辑模式
在命令模式下,可以通过以下按键命令进入编辑模式
| 模式 | 按键命令 | 描述 |
|---|---|---|
| 命令模式 | i | 在当前光标的位置,进入编辑模式 |
| 命令模式 | l | 在当前行的开头,进入编辑模式 |
| 命令模式 | a | 在当前光标位置之后,进入编辑模式 |
| 命令模式 | A | 在当前行的结尾,进入编辑模式 |
| 命令模式 | o | 在当前光标下一行,进入编辑模式 |
| 命令模式 | O | 在当前光标上一行,进入编辑模式 |
关闭文件
| 模式 | 按键命令 | 描述 |
|---|---|---|
| 命令模式 | ZZ | 保存并退出 |
| 命令模式 | :q | 退出。没有动过文件 |
| 命令模式 | :wq | 保存并退出。动过了,不后悔 |
| 命令模式 | :q! | 退出。动过了,后悔了 |
| 命令模式 | :w | 保存,不退出 |
在编辑模式与末行模式通过Esc返回到命令模式
13.3 扩展使用
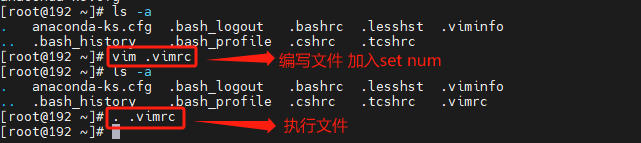
末行模式

永久增加vim中的行号,可以通过修改 ~/.vimrc文件,增加代码
set number
命令模式
14.cut命令
用来从一行文本中提取特定列、字段和字符等信息。
cut [option] [args] filename
- s:不显示没有分隔符的行
- d:指定分隔符对源文件的行进行分割
- f:选定显示哪些列
- m-n: m列到n列
- -n: 第一列到n列
- m-: 第m列到最后一列
- n: 第n列
- x,y,z: 获取第x,y,z列
常用用法
提取指定列
cut -f 1 filename
使用分隔符提取字段
cut -d ‘,’ -f 2 filename
指定字段范围
cut -d ‘,’ -f 2-4 filename
显示1,3,7列
cut -d ‘,’ -f 1,3,7 filename
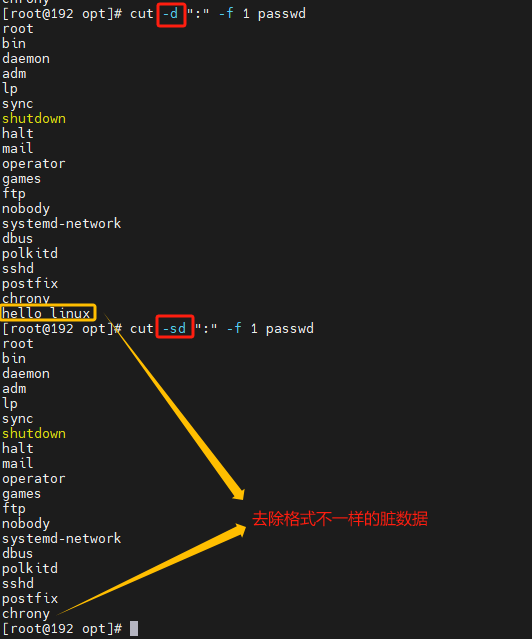
如果有的行没有分隔符,则输出会包含脏数据
cut -sd -d ‘,’ -f -10 filename
将多个文件合并到一起,并从这些文件中提取信息,则可以使用以下命令
cat file1.txt file2.txt | cut -d ‘,’ -f 1,3
15.sort命令
sort 命令是一种非常实用的文本处理工具,它可以用来对文本文件进行排序
sort [options] [file]
选项
-n : 按数值排序
-r : 倒序 reverse
-t : 自定义分隔符
-k : 选择排序列
-f : 忽略大小写
常用用法
演示文本内容
a b 1
dfdsa fdsa 15
fds fds 6
fdsa fdsa 8
fda s 9
aa dd 10
h h 11
默认字典序排序
sort sort.txt
指定字段分隔符,按照第2个字段的字典序排序
sort -t ’ ’ -k 2 sort.txt
指定字段分隔符,按照第3个字段字典序排序
sort -t ’ ’ -k 3 sort.txt
指定字段分隔符,按照第3个字段的数值序排序
sort -t ’ ’ -nk 3 sort.txt
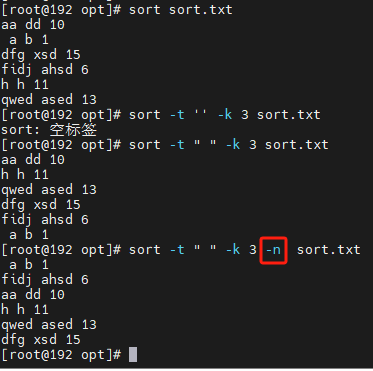
指定字段分隔符,按照第3个字段的值数值倒序
sort -t ’ ’ -nrk 3 sort.txt
排序完,输出到文件
sort -t ’ ’ -nrk 3 sort.txt > newfile
16.sed命令
sed 可以用于对文本进行替换、删除、插入等操作。
sed [选项] [脚本命令] 文件名
选项:
- i : 此选项会直接修改源文件,要慎用
脚本命令:
- d:删除符合条件的行
- a\string:在指定的行后追加新行,内容为string
- i\string:在指定行前添加新行,内容是string
- s/string1/string2/:查找并替换,默认只替换每行第一次模式匹配到的字符串
- g:行内全局替换
- i: 忽略大小写
- /regex/: 匹配某个数据
- p:打印结果
- w filename:输出到指定的文件
案例
Authentication improvements when using an HTTP proxy server.
Support for POSIX-style 8 filesystem extended attributes. filesystem
YARN’s REST APIs now support write/modify operations.
# 第一行下插入一行
[root@node1 ~]# sed "1a\hello world" sed.txt
# 直接修改文件
[root@node1 ~]# sed -i "1a\hello world" sed.txt
# 删除第2行
[root@node1 ~]# sed -i "2d" sed.txt
# 删除文档中的每一行
[root@node1 ~]# sed "d" sed.txt
# 将 filesystem 替换为 FS
[root@node1 ~]# sed "s/filesystem/FS/" sed.txt
# 忽略大小写
[root@node1 ~]# sed "s/filesystem/FS/i" sed.txt
# 不仅忽略大小写还要行内全局替换
[root@node1 ~]# sed "s/filesystem/FS/gi" sed.txt
#原来的内容要打印,匹配的行要打印,找到的行会打印两次
[root@node1 ~]# sed "/[0-9]/p" sed.txt
#匹配行中包含0-9 任意一个字符的行,只打印找到的行
[root@node1 ~]# sed -n "/[0-9]/p" sed.txt
# 匹配行中包含PATH的行,只打印找到的行
[root@node1 ~]# sed -n "/support/p" sed.txt
# 匹配行中包含PATH的行,将找到的行的内容写入到指定的文件中
[root@node1 ~]# sed -n "/support/w support.log" sed.txt
[root@node1 ~]# cat path.log

17.awk命令
awk 常用于对文本文件进行分析、过滤和格式化。
awk [-F “:”] ‘pattern {action}’ filename
pattern:指定需要匹配的模式或条件,可以使用正则表达式或特定的内置变量
action:指定匹配成功后需要执行的操作,通常为输出或编辑指定的文本
filename:指定需要处理的文本文件名,如果不指定则默认从标准输入读取
内置变量
awk 命令提供了许多内置变量,可以用于获取特定行或列的信息:
- NF:表示当前行的有多少列。
- NR:表示当前处理的是文件中的第几行。
- $0:代表整个当前行。
- $1:代表当前行的第一个字段,依次类推。
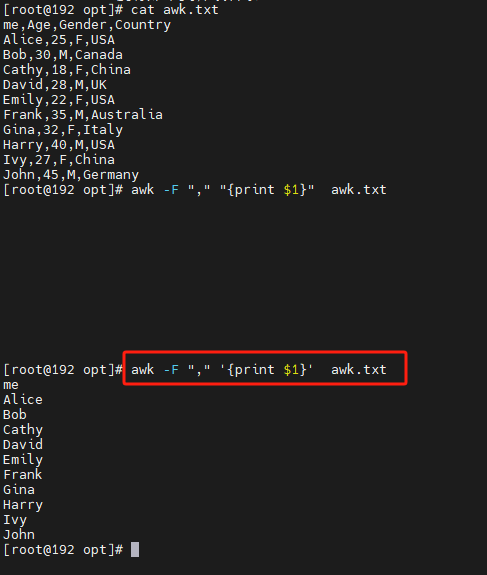
例如,下面的命令会输出 file.txt 文件中每一行的第一个字段:
awk ‘{print $1}’ file.txt
Awk 操作符
awk 命令支持一些操作符,可以对文本进行过滤和格式化。以下是常用的一些操作符:
- “~”:匹配正则表达式。
- “!~”:不匹配正则表达式。
- “==”:等于。
- “!=”:不等于。
- “<”:小于。
- “>”:大于。
- “<=”:小于等于。
- “>=”:大于等于。
例如,下面的命令会输出 file.txt 文件中包含字符串 “Linux” 且第二个字段大于 20 的行:
awk ‘/Linux/ && $2 > 20 {print}’ file.txt
在示例中, && 表示逻辑与操作符,该命令只有当两个条件都被满足时,才会进行输出行的操作。
Awk 内置函数
awk 命令还提供了许多内置函数,可以用于对文本进行处理。以下是一些常用的内置函数:
- length(string):返回指定字符串的长度。
- substr(string, start, length):返回指定字符串的子串。
- index(string, search):查找指定字符串中第一个匹配搜索字符串的位置。
- toupper(string):将指定字符串转换成大写字母。
- tolower(string):将指定字符串转换成小写字母。
例如,下面的命令会将 file.txt 文件中每一行的第一个字段转换成大写字母:
awk ‘{print toupper($1)}’ file.txt
在示例中,toupper() 函数将第一个字段中的所有字符转换为大写字母,并通过 print 命令进行输出。
案例
Name,Age,Gender,Country
Alice,25,F,USA
Bob,30,M,Canada
Cathy,18,F,China
David,28,M,UK
Emily,22,F,USA
Frank,35,M,Australia
Gina,32,F,Italy
Harry,40,M,USA
Ivy,27,F,China
John,45,M,Germany
# 输出第一列,即姓名
awk -F"," '{print $1}' file.txt
# 输出每个人的名字和国家,以逗号分隔
awk -F"," '{print $1,$4}' file.txt
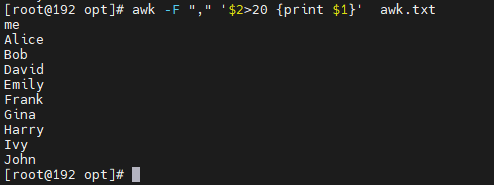
# 输出年龄小于20的人的名字和国家
awk -F"," '$2<20 {print $1, $4}' file.txt
# 输出中国和美国出生的人的姓名和年龄
awk -F"," '$4 ~/China|USA/ {print $1, $2}' file.txt
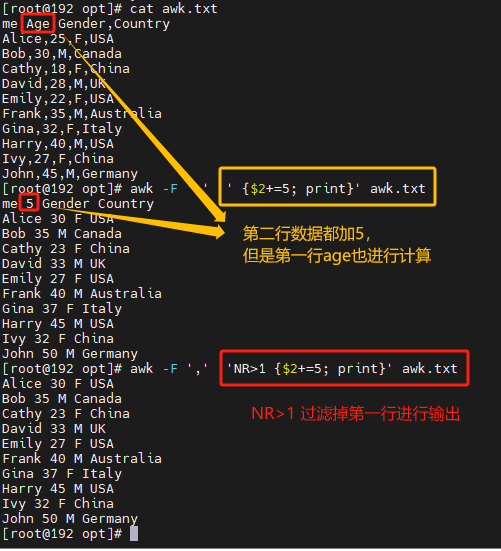
# 将所有人的年龄增加 5 岁后进行输出,并将输出结果保存到文件中
awk -F"," '{$2+=5; print}' file.txt > newfi
awk -F"," 'NR>1 {$2+=5; print}' file.txt > newfile.txt
三、用户和权限
1. 用户和用户组
在Linux中,每个文件和目录都有一个所有者和属组,用于控制对它们的访问权限
Linux用户
无论是Windows、MacOS、Linux均采用多用户的管理模式进行权限管理;
Linux 系统支持多个用户在同一时间内登陆,不同用户可以执行不同的任务,并且互不影响;
不同用户具有不同的权限,毎个用户在权限允许的范围内完成不同的任务。
提示
在Linux系统中,拥有最大权限的账户名为:root(超级管理员);
而普通用户在许多地方的权限是受限的;
每个用户在自己家目录下,拥有最高权限;
Linux用户组
用户组是一组用户的集合,由管理员定义
目的就是更方便地管理和授予权限。同一用户组内的所有成员都具有相同的访问权,这些访问权取决于组的权限设置
用户与用户组的关系
在Linux中,每个用户都至少属于一个用户组,但也可以同时属于多个用户组
这些用户组定义了用户的访问权限,决定着用户可以执行哪些操作、访问哪些目录和文件等
2. 用户管理
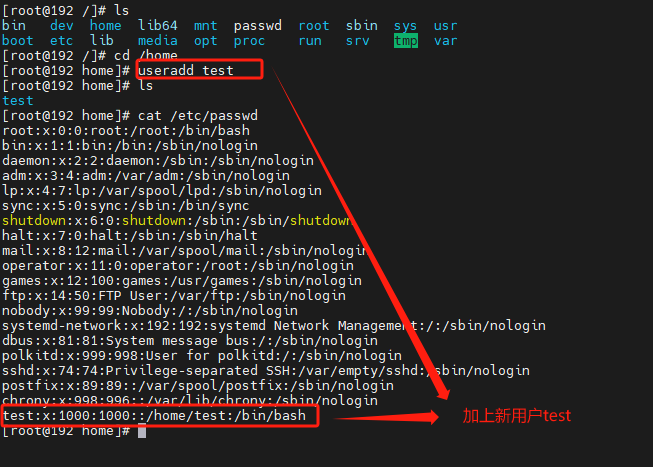
添加用户
useradd [选项] 用户名
选项说明:
-c comment 指定一段注释性描述。
-d 目录 指定用户主目录,如果此目录不存在,则同时使用-m选项,可以创建主目录。
-g 用户组 指定用户所属的用户组。
参数描述:
用户名:指定新账号的登录名
删除用户
userdel [-r] 用户名
选项说明:
-r,删除用户的HOME目录,不使用-r,删除用户时,HOME目录保留

查看用户信息
显示系统中所有现有的用户账户。
cat /etc/passwd
3. su、exit、sudo
超级用户与普通用户
在Linux系统中,拥有最大权限的账户名为:root(超级管理员)
普通用户的权限,一般在其HOME目录内是不受限的
一旦出了HOME目录,大多数地方,普通用户仅有只读和执行权限,无修改权限
su和exit命令
su命令就是用于账户切换的系统命令,其来源英文单词:Switch User
su [-l] 用户名
-l : 符号是可选的,表示是否在切换用户后加载环境变量
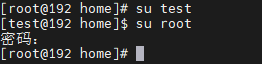
切换用户后,可以通过exit命令退回上一个用户,也可以使用快捷键:ctrl + d;
使用普通用户,切换到其它用户需要输入密码,如切换到root用户,使用root用户切换到其它用户,无需密码,可以直接切换。
sudo命令
在我们得知root密码的时候,可以通过su命令切换到root得到最大权限,但是不建议长期使用root用户,避免带来系统损坏。
也可以使用sudo命令,为普通的命令授权,临时以root身份执行
sudo 命令
在其它命令之前,带上sudo,即可为这一条命令临时赋予root授权,但是并不是所有的用户,都有权利使用sudo,我们需要为普通用户配置sudo认证。
为普通用户配置sudo认证
切换到root用户,执行visudo命令,会自动通过vi编辑器打开:/etc/sudoers
在文件的最后添加
用户名 ALL=(ALL) NOPASSWD:ALL
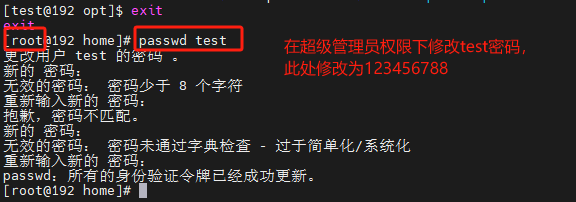
显示还是没有办法创建文件
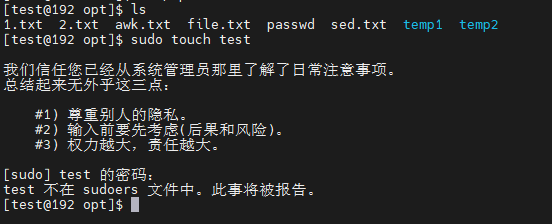
在/etc/sudoers文件里加入命令

在test的用户权限下可以创建文件:

其中最后的NOPASSWD:ALL 表示使用sudo命令,无需输入密码
4.id与whoami 查看权限
id命令
id <用户名>
终端会输出当前用户的身份信息,其中包括uid和gid字段,分别表示用户ID和组ID。如果uid为0,则说明该用户是管理员
id 用户名,一般是管理员使用
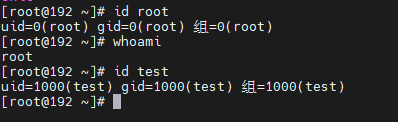
whoami命令
whoami命令可以查看当前用户的用户名,但是不能直接判断该用户是否为管理员
whoami
**命令行的提示符号 # 或者
∗
∗
命令行提示符中的
** 命令行提示符中的
∗∗命令行提示符中的和#符号通常用来表示不同的用户或权限等级
但并不能直接判断当前用户是为管理员
$:该符号一般出现在非特权用户的命令提示符中,表示当前用户没有超级用户(root)的权限
#:该符号一般出现在超级用户(root)的命令提示符中,表示当前用户拥有最高权限
5.用户组管理
用户组是一组用户的集合,由管理员定义:
目的就是更方便地管理和授予权限。同一用户组内的所有成员都具有相同的访问权,这些访问权取决于组的权限设置
要在Linux中管理用户组,需要以root用户身份登录系统。
查看用户组
cat /etc/group
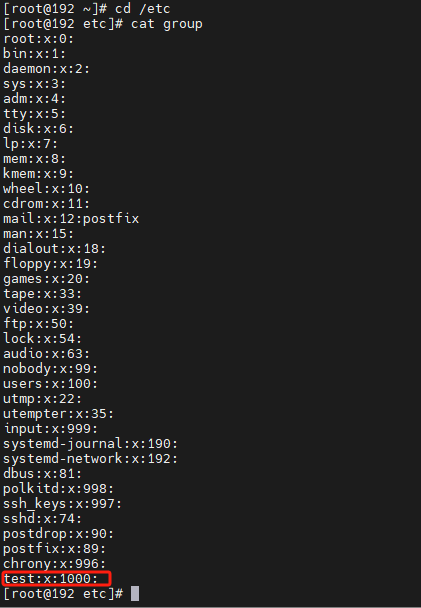
创建用户组
groupadd 用户组名
删除用户组
groupdel 用户组名
用户修改组
将用户添加到一个附加组中
usermod -aG 用户组名 用户名
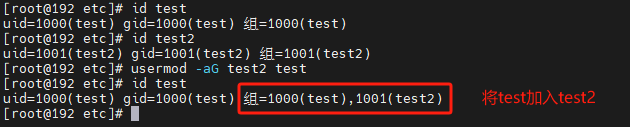
将用户设置为指定组
usermod -G 用户组名 用户名

6.文件权限的查看
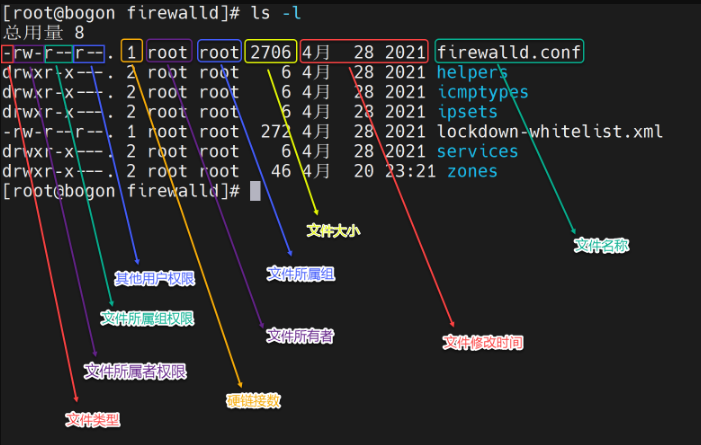

文件的类型
- 表示文件
d 表示文件夹
l 表示链接
权限说明
- r 读
- 文件:查看文件内容
- 文件夹:查看文件夹内容,如ls命令
- w 写
- 文件:修改此文件
- 文件夹:在文件夹内:创建、删除、改名等操作
- x 执行
- 文件:可以将文件作为程序执行
- 文件夹:可以更改工作目录到此文件夹,即cd进入
- "- "无权限
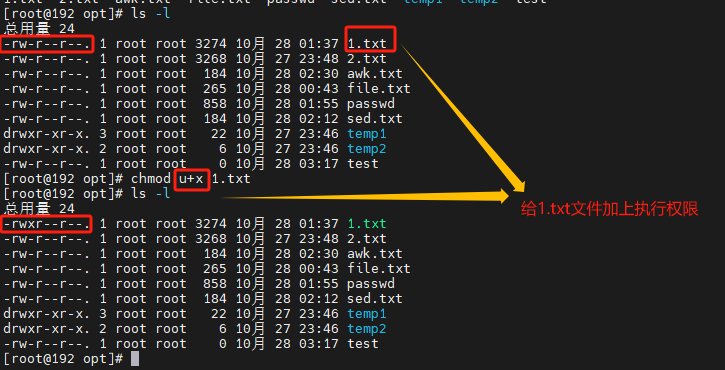
7.chmod命令 修改权限控制
chmod命令是用来修改文件或目录权限的命令
通常,只有文件、文件夹的所属用户,或者有root权限的用户才能使用
通过chmod命令来对以下三种权限进行设置和变更
- 文件所有者(Owner)拥有读、写、执行权限(rwx)
- 同组用户(Group)拥有读、写、执行权限(rwx)
- 其他用户(Others)拥有读、写、执行权限(rwx)
chmod命令的使用方法如下:
chmod [选项] 模式 文件名/文件夹
选项:-R,表示递归修改
模式:修改的权限
文件名/文件夹: 指定的目标文件或文件夹
模式
通过符号:
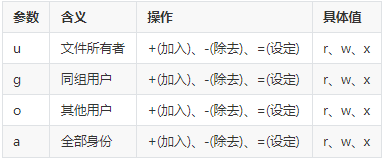
# 不考虑之前的权限(=),直接使用设定的方式:
chmod u=rwx,g=rx,o=rx test
# 还以省略为如下:
chmod u=rwx,go=rx test
#原有基础上修改(+,-)
chmod a-x test
#省略:
chmod +x test
通过数字:
权限用3位数字代表,第一位数字表示文件所有者,第二位数字表示同组用户,第三位表示其他用户
r记为4,w记为2,x记为1,:
0:无任何权限 , —
1:只有x权限, --x
2:只有w权限,-w-
3:有w,x权限,-wx
4:只有r,r–
5:r-x
6:rw-
7:rwx
# 修改权限为rwxr-x---:
chmod 750 test
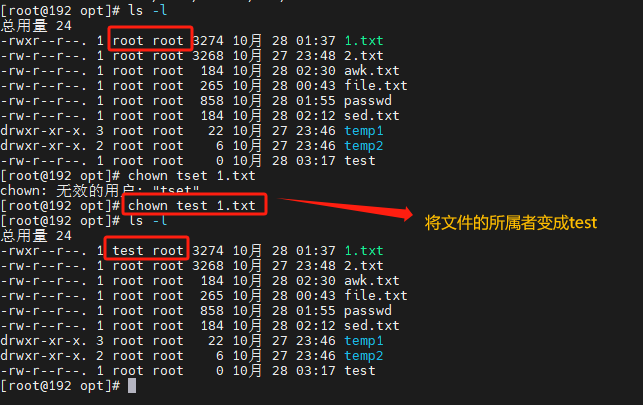
8.修改文件所属者chown
chown是更改文件或者目录所有者的命令,可以将文件或目录的所有权转移到另一用户或组;
通常,只有文件、文件夹的所属用户,或者有root权限的用户才能使用。
chown命令的基本语法如下:
chown [选项] 用户名:组名 文件名
用户名和组名: 可以是任何有效的Linux用户或组名称
文件名: 是要修改其所有权的文件或目录名称
选项
-R:递归地更改文件夹及其子文件夹中的所有文件所有者
# 将hello.txt所属用户修改为root
chown root hello.txt
# 将hello.txt所属用户组修改为root
chown :root hello.txt
# 将hello.txt所属用户修改为root,用户组修改为python
chown root:python hello.txt
# 将文件夹test的所属用户修改为root并对文件夹内全部内容应用同样规则
chown -R root test
四、Linux使用操作
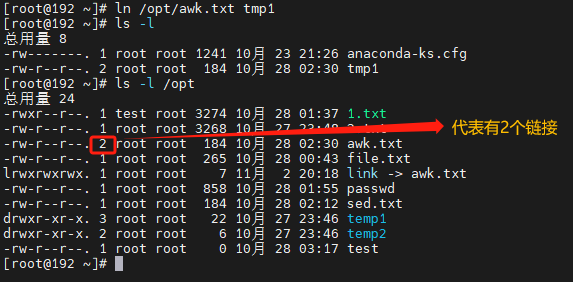
1.创建链接
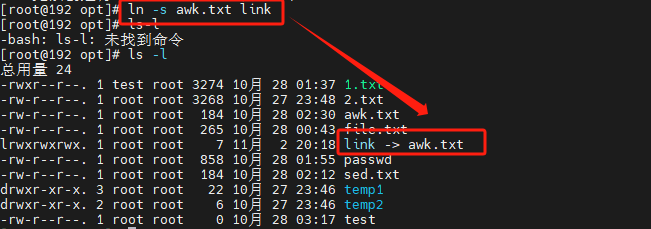
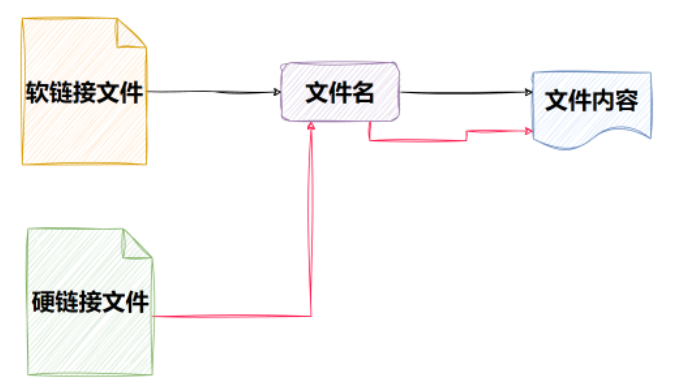
在Linux中,可以给文件创建链接。链接的意思可以理解是快捷方式,它指向另一个文件或目录。
软链接
软连接(也叫符号链接)是一种特殊类型的文件,它指向另一个文件或目录.
语法
ln -s 原文件路径 符号链接
# 在当前目录下创建一个名为link_to_file的软链接,指向/home/user/file1
ln -s /home/user/file1 link_to_file
硬链接
硬链接也是一种链接方式,它允许一个文件有多个名称,但是它们都指向文件系统中同一个数据块(类似于文件地址)。
**如果原始文件被删除了,硬链接仍然可以继续使用,**因为它们仍然指向同一组数据块。
语法
ln 原文件路径 符号链接
# 当前目录下创建一个名为hard_link_to_file的硬链接,指向/home/user/file1
ln /home/user/file1 hard_link_to_file
2.管理服务 systemctl
Linux系统很多软件(内置或第三方)均支持使用systemctl命令控制:启动、停止、开机自启
能够被systemctl管理的软件,一般也称之为:服务
语法:
systemctl [操作] 服务名
操作:
- start 开启服务
- stop 停止服务
- status 查看当前服务状态
- enable 开启开机自启动
- disable 关闭开机自启动
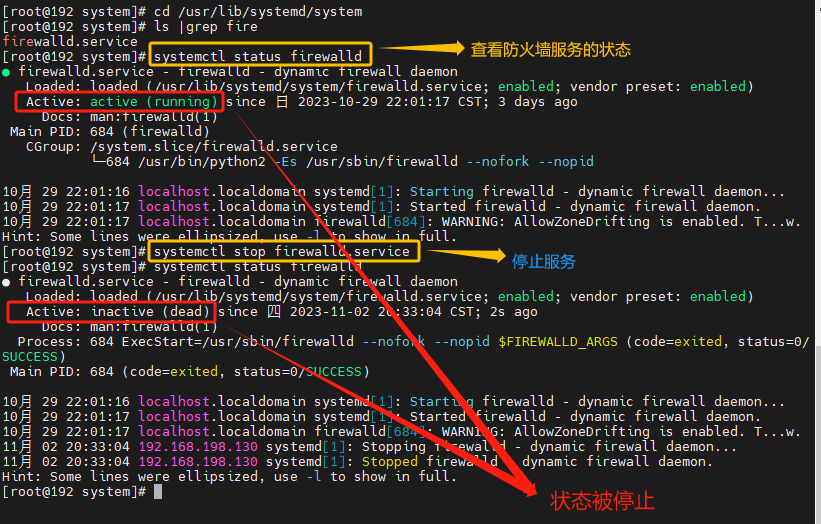
系统内置的服务比较多,比如:
- NetworkManager,主网络服务
- network,副网络服务
- firewalld,防火墙服务
- sshd,ssh服务
查看可以使用的服务
ls /usr/lib/systemd/system/
3.日期与时区
date命令
通过date命令可以在命令行中查看系统的时间
语法
date [选项] [+格式化字符串]
选项
" -d "按照给定的字符串显示日期,一般用于日期计算
格式化字符串:通过特定的字符串标记,来控制显示的日期格式
- %Y 年
- %y 年份后两位数字 (00…99)
- %m 月份 (01…12)
- %d 日 (01…31)
- %H 小时 (00…23)
- %M 分钟 (00…59)
- %S 秒 (00…60)
- %s 自 1970-01-01 00:00:00 UTC 到现在的秒数
举例
# 查看当前时间
date
# 按照指定格式显示日期
date "+%Y-%m-%d %H:%M:%S"
# 日期的加减 year month day hour minute second
date -d "+1 day" "+%Y-%m-%d"
date -d "-1 day" "+%Y-%m-%d"
date -d "+1 month" "+%Y-%m-%d"
date -d "+1 year" "+%Y-%m-%d"
修改Linux时区
时间在不同时区,是不同的,因此有时,可能因为时区不同,导致时间显示不符合心意,因此需要修改时区,要有root管理员的权限。
方法:
将系统自带的localtime文件删除,并将**/usr/share/zoneinfo/Asia/Shanghai**文件链接为localtime文件即可

rm -f /etc/localtime
sudo ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
查看当前硬件时间
注意:hwclock 所有命令需要使用root 权限

将系统时间同步到硬件时间
hwclock -w
将硬件时间同步到系统时间
hwclock -s
4.IP地址与主机机名
IP地址
IP地址主要有2个版本,V4版本和V6版本(V6很少用)
IPv4版本的地址格式是:a.b.c.d,其中abcd表示0~255的数字,如192.168.66.101就是一个标准的IP地址
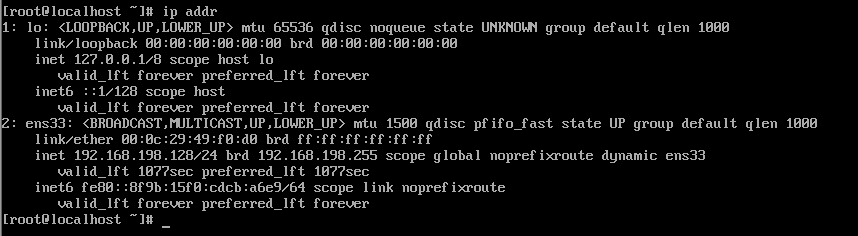
可以通过命令:ip addr 查看本机的ip地址
特殊IP地址
除了标准的IP地址以外,还有几个特殊的IP地址:
- 127.0.0.1,这个IP地址用于指代本机
- 0.0.0.0,特殊IP地址
- 可以用于指代本机
- 可以在端口绑定中用来确定绑定关系
- 在一些IP地址限制中,表示所有IP的意思,如放行规则设置为0.0.0.0,表示允许任意IP访问
主机名
每一台电脑除了对外联络地址(IP地址)以外,也可以有一个名字,称之为主机名
无论是Windows、Mac、Linux系统,都可以给系统设置主机名
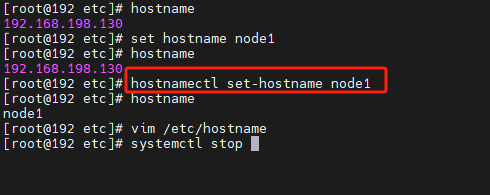
修改主机名
通过命令
hostnamectl set-hostname 新的主机名
通过修改文件
vim /etc/hostname
有时即使设置了,也不是自己设置的名字,原因有2种:
- 设置好没有重启
- Linux在初始化系统时,会先判断主机名,如果主机名是localhost或localhost.localdomain,则会获取主机IP地址并执行DNS逆向解析,将解析到的结果赋值给HOSTNAME
解决方案
#修改/etc/hosts文件,追加内容
# ip 主机名
192.168.66.101 myname
#修改/etc/sysconfig/network文件中HOSTNAME的值
NETWORKING=yes
HOSTNAME=myname
#重启服务器

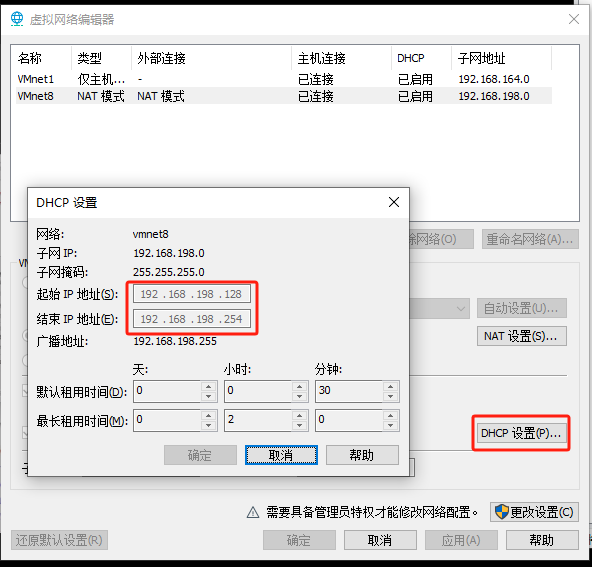
5.固定IP地址
找到可以使用的IP地址范围
设置IP
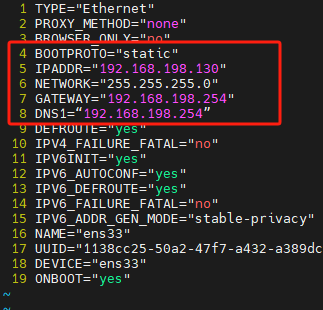
编辑/etc/sysconfig/network-scripts/ifcfg-ens33文件,修改关键内容为:
BOOTPROTO=“static”
IPADDR=“192.168.247.129”
NETMASK=“255.255.255.0”
GATEWAY=“192.168.247.2”
DNS1=“192.168.247.2”
重启网卡服务即可
systemctl restart network
注意:进入的编辑的文件根据网卡的名字变动:
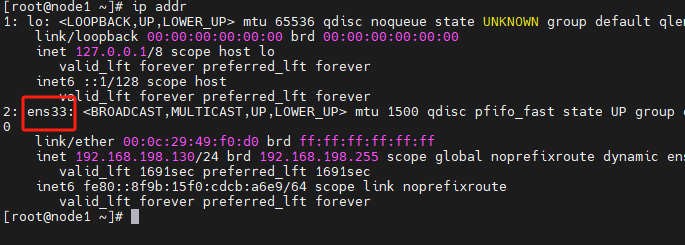
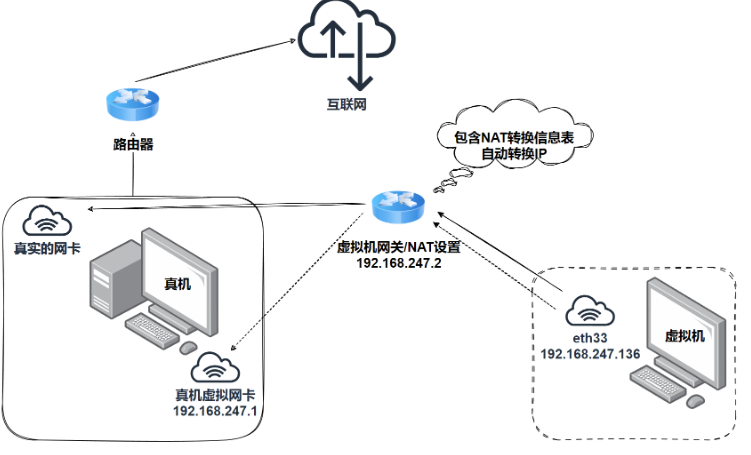
NAT模式的原理
6.进程的管理 ps
程序运行在计算机操作系统中,由操作系统进行管理。为了管理正在运行的程序,每个程序在运行时都被注册到操作系统中,形成进程。
每个进程都有一个独特的进程ID(进程号),用来区别不同的进程。进程ID通常是唯一的,而且在同一时间内不会被其他进程使用。当操作系统需要对某个进程进行操作时,可以通过进程ID来定位到该进程,并进行相应的管理和控制。
操作系统通过监控进程的运行状态,保证各个进程能够共享CPU、内存等资源,实现多任务的并发执行,提高计算机的效率和利用率。同时,操作系统还可以通过调度算法来控制进程的执行顺序,保证系统的稳定性和可靠性。
语法
ps [options] [–help]
参数:
ps 的参数非常多, 在此仅列出几个常用的参数并大略介绍含义
- -A 列出所有的进程
- -w 显示加宽可以显示较多的资讯
- -au 显示较详细的资讯
- -aux 显示所有包含其他使用者的进程
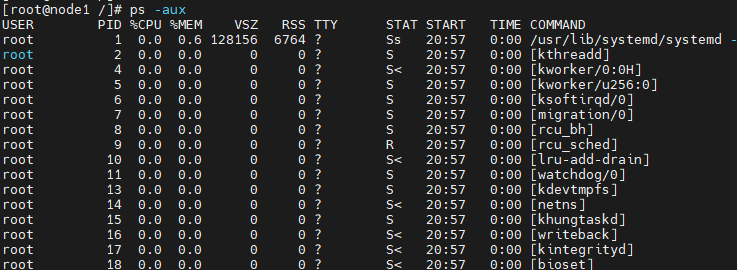
内容信息
查找制定进程
因为列的数据太多,因此需要筛选数据,这时就可以使用 管道与grep来进行过滤
ps -aux |grep python
因为是字符串数据过滤,所以任何数据都可以用来过滤
关闭进程
在Linux中,可以通过kill命令关闭进程
kill -9 进程ID
-9,表示强制关闭进程
7.端口的查看 netstat
在Linux系统中,端口号是一个16位的整数,取值范围是0~65535
- 公认端口:1~1023,通常用于一些系统内置或知名程序的预留使用
- 如SSH服务的22端口,
- HTTPS服务的443端口
- 非特殊需要,不要占用这个范围的端口
- 注册端口:1024~49151,通常可以随意使用,用于松散的绑定一些程序\服务
- 动态端口:49152~65535,通常不会固定绑定程序,而是当程序对外进行网络链接时,用于临时使用
如果要使用某个服务,需要先打开相应的端口:
netstat [选项]
参数说明:
-a或–all 显示所有连线中的Socket。
-A<网络类型>或–<网络类型> 列出该网络类型连线中的相关地址。
-c或–continuous 持续列出网络状态。
-C或–cache 显示路由器配置的快取信息。
-e或–extend 显示网络其他相关信息。
-F或–fib 显示路由缓存。
-g或–groups 显示多重广播功能群组组员名单。
-h或–help 在线帮助。
-i或–interfaces 显示网络界面信息表单。
-l或–listening 显示监控中的服务器的Socket。
-M或–masquerade 显示伪装的网络连线。
-n或–numeric 直接使用IP地址,而不通过域名服务器。
-N或–netlink或–symbolic 显示网络硬件外围设备的符号连接名称。
-o或–timers 显示计时器。
-p或–programs 显示正在使用Socket的程序识别码和程序名称。
-r或–route 显示Routing Table。
-s或–statistics 显示网络工作信息统计表。
-t或–tcp 显示TCP传输协议的连线状况。
-u或–udp 显示UDP传输协议的连线状况。
-v或–verbose 显示指令执行过程。
-V或–version 显示版本信息。
-w或–raw 显示RAW传输协议的连线状况。
-x或–unix 此参数的效果和指定"-A unix"参数相同。
–ip或–inet 此参数的效果和指定"-A inet"参数相同。
如果不能使用,可以先安装下命令:
yum -y install net-tools
如果想要快速找到数据,可以结合管道与grep筛选
netstat -nptl | grep 端口号
安装时出现报错:
Error downloading packages: net-tools-2.0-0.25.20131004git.el7.x86_64: [Errno 256] No more mirrors to try.
已加载插件:fastestmirror
Loading mirror speeds from cached hostfile
Could not retrieve mirrorlist http://mirrorlist.centos.org/?release=7&arch=x86_64&repo=os&infra=stock error was
14: curl#6 - "Could not resolve host: mirrorlist.centos.org; 未知的错误"
One of the configured repositories failed (未知),
and yum doesn't have enough cached data to continue. At this point the only
safe thing yum can do is fail. There are a few ways to work "fix" this:
1. Contact the upstream for the repository and get them to fix the problem.
2. Reconfigure the baseurl/etc. for the repository, to point to a working
upstream. This is most often useful if you are using a newer
distribution release than is supported by the repository (and the
packages for the previous distribution release still work).
3. Run the command with the repository temporarily disabled
yum --disablerepo=<repoid> ...
4. Disable the repository permanently, so yum won't use it by default. Yum
will then just ignore the repository until you permanently enable it
again or use --enablerepo for temporary usage:
yum-config-manager --disable <repoid>
or
subscription-manager repos --disable=<repoid>
5. Configure the failing repository to be skipped, if it is unavailable.
Note that yum will try to contact the repo. when it runs most commands,
so will have to try and fail each time (and thus. yum will be be much
slower). If it is a very temporary problem though, this is often a nice
compromise:
yum-config-manager --save --setopt=<repoid>.skip_if_unavailable=true
Cannot find a valid baseurl for repo: base/7/x86_64
发现ping网络不可达:
将电脑网卡改成自动获取(192.168.198.1)后可以正常下载,但是moba却连接不上去:
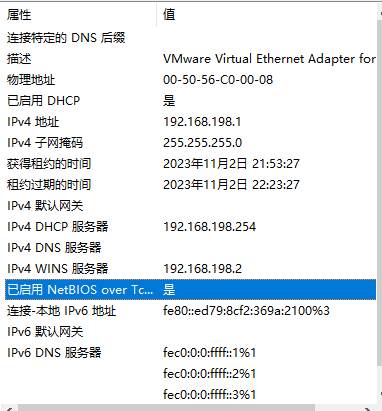
查看虚拟机出现一个网卡有两个ip地址可能冲突了:
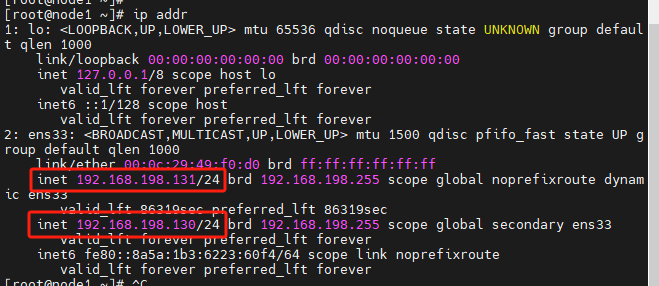
用命令删除后观察看下:
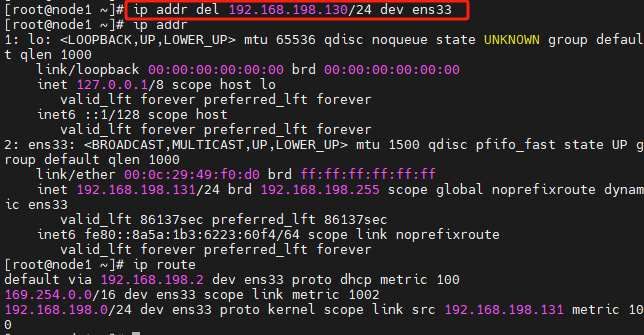
8.查看系统资源使用情况 top
在Linux中,为了更好的管理系统,需要可以了解服务器运行状态,可以通过top命令查看CPU、内存使用情况,类似Windows的任务管理器,默认每5秒刷新一次,语法:直接输入top即可,按q或ctrl + c退出。
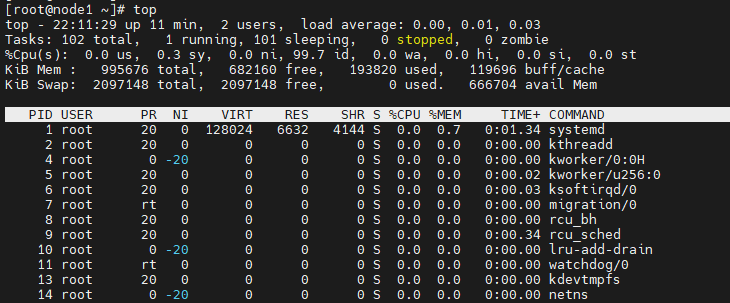
参数说明:
d : 改变显示的更新速度,或是在交谈式指令列( interactive command)按 s
q : 没有任何延迟的显示速度,如果使用者是有 superuser 的权限,则 top 将会以最高的优先序执行
c : 切换显示模式,共有两种模式,一是只显示执行档的名称,另一种是显示完整的路径与名称
S : 累积模式,会将己完成或消失的子进程 ( dead child process ) 的 CPU time 累积起来
s : 安全模式,将交谈式指令取消, 避免潜在的危机
i : 不显示任何闲置 (idle) 或无用 (zombie) 的进程
n : 更新的次数,完成后将会退出 top
b : 批次档模式,搭配 “n” 参数一起使用,可以用来将 top 的结果输出到档案内
系统状态

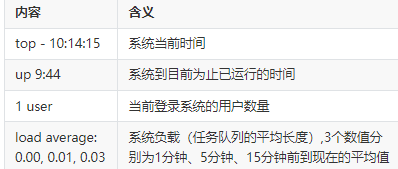
top给出的系统运行时间,反应了当前系统存活多久,对于某些应用而言,
系统需要保证7*24小时的高可用性,这个字段信息就能很好的衡量系统的高可用性。
Task 进程状态

所有启动的进程数、正在运行的进程数、挂起的进程数、停止的进程数、僵尸进程数
提示
在linux操作系统中,一般有以下5种状态的进程信息:
- D:不可中断睡眠态(通常出现在IO阻塞)
- R:运行态
- S:睡眠态
- T:已停止
- z:僵尸态
CPU 状态

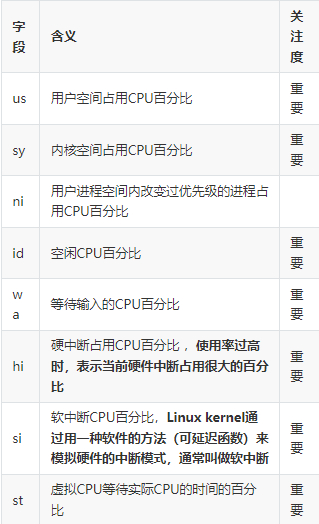
Mem内存信息(物理内存)

物理内存总量、空闲物理内存、已经使用的物理内存、内核缓存内存量
说明
buffer和cache的作用是所用I/O系统调用的时间,比如读写等;
一般一个系统而言,如果cache的值很大,说明cache住的文件多;
如果频繁访问文件都能被命中,很明显会比读取磁盘调用快,磁盘的IO必定会减小;
提示
cache的命中率很关键,如果频繁访问的文件不能被命中,对于cache而言是个比较的大的资源浪费;
此时应考虑drop cache并提升对应的cache的命中率。
Swap交换内存(虚拟内存)

交换区总量、空闲交换区总量、已使用交互区总量、缓冲的交换区总量
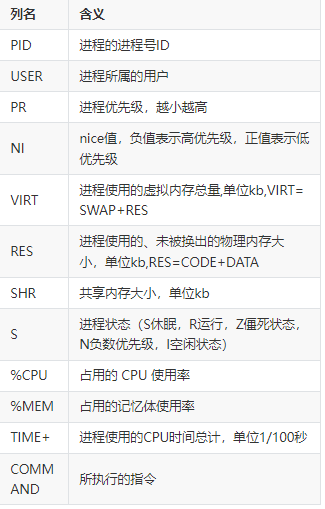
进程信息

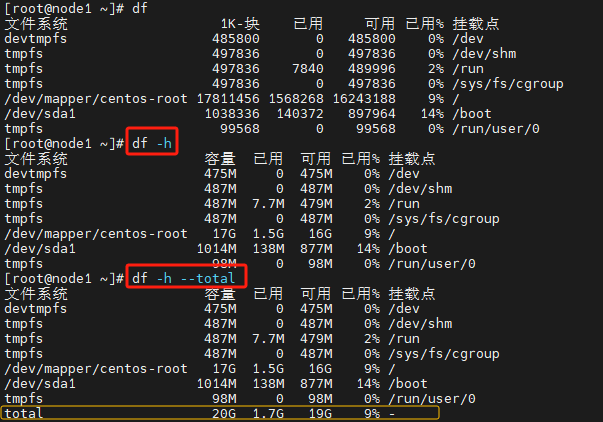
9.查看磁盘使用情况 df
Linux df(英文全拼:disk free) 命令用于显示目前在 Linux 系统上的文件系统磁盘使用情况统计。
df [选项]…
-a, --all 包含所有的具有 0 Blocks 的文件系统
–block-size={SIZE} 使用 {SIZE} 大小的 Blocks
-h, --human-readable 使用人类可读的格式(预设值是不加这个选项的…)
-H, --si 很像 -h, 但是用 1000 为单位而不是用 1024
-i, --inodes 列出 inode 资讯,不列出已使用 block
-k, --kilobytes 就像是 --block-size=1024
-l, --local 限制列出的文件结构
-m, --megabytes 就像 --block-size=1048576
–no-sync 取得资讯前不 sync (预设值)
-P, --portability 使用 POSIX 输出格式
–sync 在取得资讯前 sync
-t, --type=TYPE 限制列出文件系统的 TYPE
-T, --print-type 显示文件系统的形式
-x, --exclude-type=TYPE 限制列出文件系统不要显示 TYPE
-v (忽略)
–help 显示这个帮手并且离开
–version 输出版本资讯并且离开
# 显示文件系统的磁盘使用情况统计
df
# 显示所有的信息,包含一个额外的行,汇总的每一列
df --total
# 显示文件系统的磁盘使用情况统计,加上单位
df -h
10.环境变量的使用
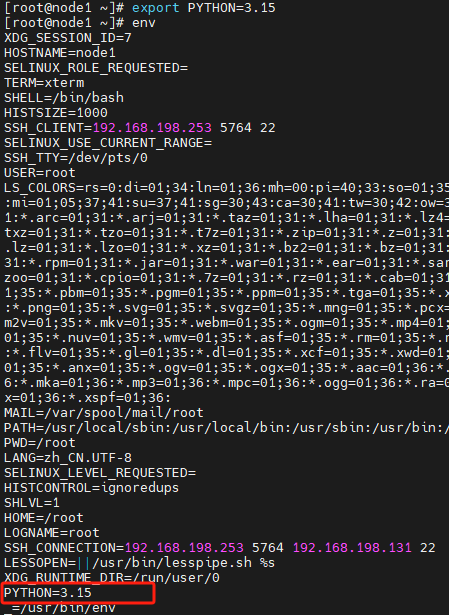
环境变量是一种在操作系统(Windows、Mac、Linux)中存储的特殊字符串值,它们可以用于配置操作系统和应用程序的行为。Linux系统中有许多环境变量,包括PATH、HOME、LANG等。环境变量是一种KeyValue型结构。在Linux中,可以通过env命令查看当前系统中记录的环境变量。
环境变量:PATH
在Linux系统中,环境变量PATH是一个非常重要的变量。它是由一组用冒号(:)隔开的路径组成的字符串,这些路径告诉操作系统去哪里查找可执行文件
当我们在终端输入一个命令时,Linux会按照PATH变量中指定的路径顺序依次查找,直到找到对应的可执行文件为止。如果最终没有找到对应的可执行文件,就会提示“command not found”的错误信息
修改环境变量方式
在Linux中,设置环境变量的方式有多种,下面列举了2种常见的设置环境变量的方式:
- 直接使用export命令设置环境变量
export MY_VAR=my_value
此方法设置的环境变量只会在当前终端窗口中生效,关闭后失效
- 在/.bashrc或/.bash_profile文件中添加环境变量
例如,在~/.bashrc文件末尾添加以下内容:MY_VAR=my_value
此方法设置的环境变量会在每次启动bash时自动加载,并对所有子进程可见
.bashrc与.bash_profile都是Bash shell的配置文件,它们位于用户主目录下,区别在于:
.bashrc 当用户打开一个新的终端窗口时,Bash shell就会读取并执行这些命令。通常,在.bashrc文件中设置一些环境变量、别名、函数等
.bash_profile只会在用户首次登录系统时被读取和执行一次。通常,.bash_profile文件用来设置一些与用户账户相关的环境变量和别名等信息
配置环境变量,通过source 配置文件,进行立刻生效,或者重新开启shell窗口。

11.网络请求 ping命令的使用
ping命令用于测试主机之间的网络连接,可以用于检测网络连接是否正常,路由是否被正确配置,主机是否正在运行等。
ping <选项> <主机名或IP地址>
常用选项说明:
-c <次数>:设置ping的次数,默认是无限制的
-i <间隔秒数>:设置ping的间隔时间,默认是1秒
-t:一直ping,直到Ctrl+C停止
-w <超时秒数>:设置ping的超时时间,默认是无限制的
-q:静音模式,只输出最终的统计信息
-v:详细输出模式,会输出来回的ICMP包信息
-n:使用IP地址而不是主机名
-4或-6:强制使用IPv4或IPv6
# ping www.baidu.com 5次
ping -c 5 www.baidu.com
# 每3秒ping一次ip地址
ping -i 3 -n 192.168.0.1
# 一直ping,通过Ctrl+C停止
ping -t www.bing.com
# 设置ping超时时间为5秒
ping -w 5 192.168.0.1
注意
有部分服务器,已经停止了ping服务。
所以ping不通,不一定服务器不通,可以使用其它命令再测试
13.网络请求 下载数据wget与curl
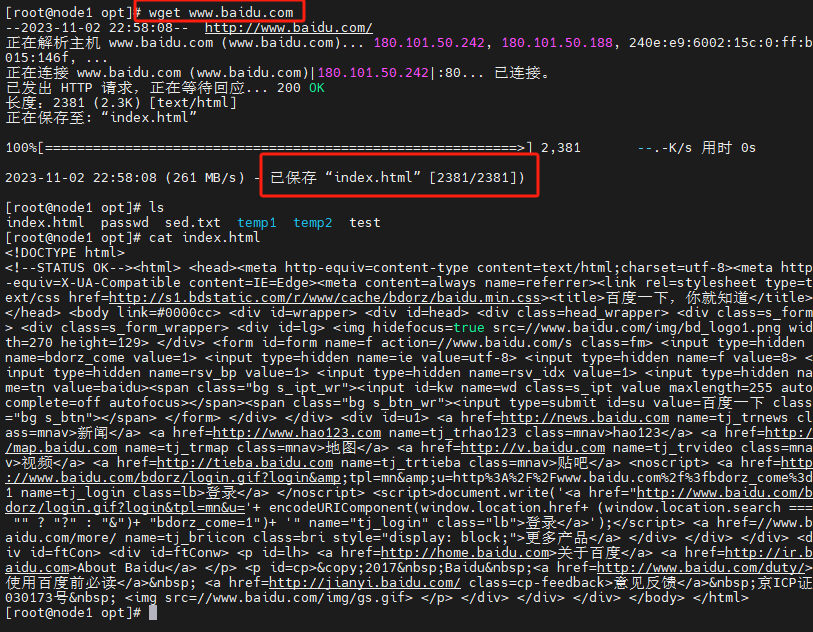
wget
wget是一个强大的命令行下载工具,可以非交互式地从web服务器上下载文件。它支持HTTP、HTTPS和FTP协议,可以使用代理,支持断点续传等功能。
wget命令用于在Linux中通过网络下载文件
安装
yum -y install wget
它的基本语法如下:
wget [选项]… [URL]…
常用选项说明:
-b:后台下载模式
-c:继续之前的下载任务
-q:安静模式,不打印进度条等信息
-O <文件>:将下载的数据写入指定的文件中
-t <次数>:设置重试次数,默认是20
-w <秒数>:设置两次尝试之间等待的秒数,默认是0秒
-nv:不详细显示下载进度
-np:不检查/$HOME/.netrc认证
-r:递归下载整个网站
-l <级数>:指定递归下载的级数,默认是5层
-A <后缀>:只下载指定后缀的文件
-R <后缀>:排除下载指定后缀的文件
-nd:不创建父目录
-x:不创建父目录例子:
# 下载文件并命名为test.txt
wget -O test.txt https://www.baidu.com
# 后台下载文件
wget -b https://linux.org/ftp/linux/kernel/v1.0/linux-1.0.tar.gz
注意
无论下载是否完成,都会生成要下载的文件,如果下载未完成,请及时清理未完成的不可用文件。
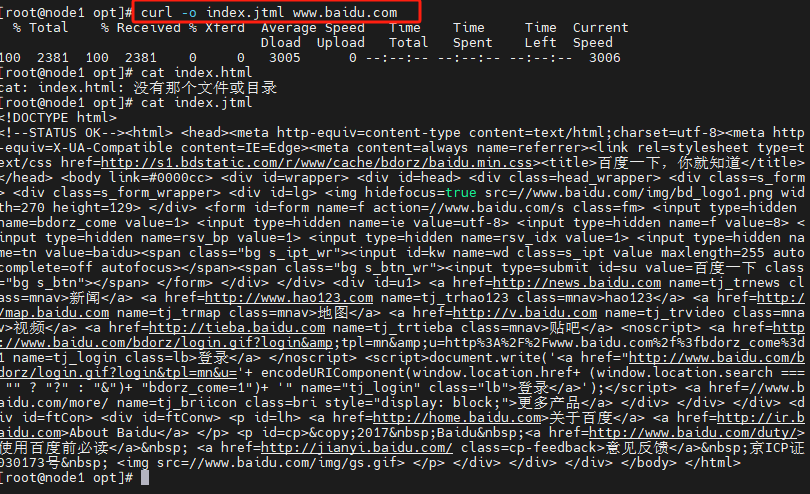
curl
在Linux中,curl是一个功能强大的命令行工具,可以下载/上传数据,支持多种协议(HTTP、FTP、POP3等)。
它常被用来测试网站接口、下载文件等
它的基本语法如下:
curl [选项] [URL]
常用选项说明:
-d/–data :POST方式传送数据
-o/–output :将输出写到文件中
# 使用指定的User-Agent字符串
curl -A 'Mozilla/5.0' https://www.example.com
# 保存cookie到文件
curl -c cookies.txt https://www.example.com
# 上传文件
curl -T file.txt https://www.example.com
# 使用代理连接
curl -x http://user:password@proxyserver:8080 https://www.example.com
14.压缩与解压 tar命令
压缩格式
- zip格式:Linux、Windows、MacOS常用
- rar:Windows系统常用
- 7zip:Windows系统常用
- tar:Linux、MacOS常用
- gzip:Linux、MacOS常用
tar命令介绍
Linux和Mac系统常用有2种压缩格式,后缀名分别是:
- .tar,称之为tarball,归档文件,仅将文件封装成一个.tar文件,未压缩文件体积
- .gz,也常见为.tar.gz,使用gzip算法进行压缩,从而大幅减小压缩后的文件体积
针对这两种格式,使用tar命令均可以进行压缩和解压缩的操作
语法
tar [选项] [压缩文件] [被压缩的文件1,被压缩的文件2,被压缩的文件3…]
选项
-c,创建压缩文件,用于压缩模式
-v,显示压缩、解压过程,用于查看进度
-x,解压模式
-f,要创建的文件,或要解压的文件
-z,gzip模式,不使用-z就是普通的tarball格式
-C,选择解压的目的地,用于解压模式
注意
-f,必须在选项组合体的最后一位
-z,建议在开头位置
-C,选项单独使用,和解压所需的其它参数分开
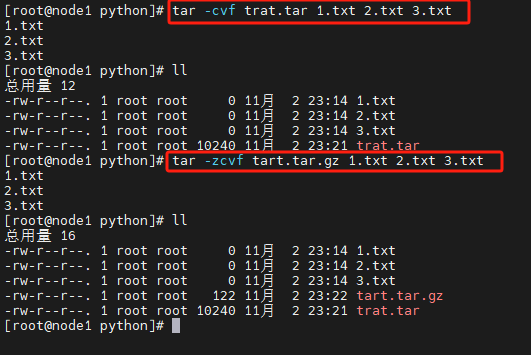
tar 命令压缩
# 将1.txt 2.txt 3.txt 压缩到test.tar文件内
tar -cvf test.tar 1.txt 2.txt 3.txt
# 将1.txt 2.txt 3.txt 压缩到test.tar.gz文件内,使用gzip模式
tar -zcvf test.tar.gz 1.txt 2.txt 3.txt
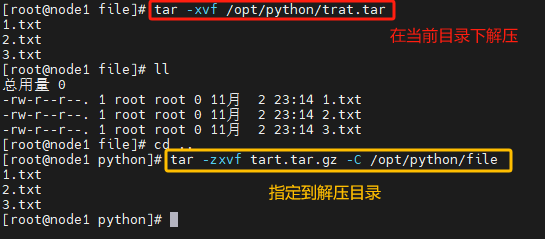
tar 命令解压缩
# 解压test.tar,将文件解压至当前目录
tar -xvf test.tar
# 解压test.tar,将文件解压至当前目录
tar -xvf test.tar -C /home/bz
# 以Gzip模式解压test.tar.gz,将文件解压至指定目录
tar -zxvf test.tar -C /home/bz
15.压缩命令zip与unzip的使用
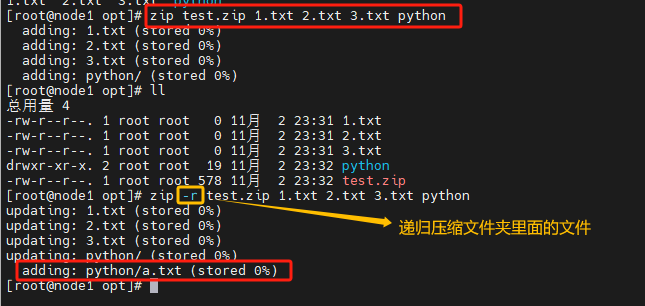
zip命令
在Linux中,可以使用zip命令,压缩文件为zip压缩包
语法
zip [选项] [压缩的文件名] [被压缩的文件1,被压缩的文件2,被压缩的文件3…]
选项
-r,递归压缩
# 将a.txt b.txt c.txt 压缩到test.zip文件内
zip test.zip a.txt b.txt c.txt
# 将test文件夹和a.txt文件,压缩到test.zip文件内
zip -r test.zip test a.txt
安装
yum -y install zip
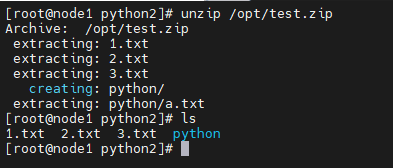
unzip命令
在Linux中,可以使用unzip命令,压缩文件为zip压缩包
语法:unzip [选项] [压缩的文件名]
选项
-d,指定要解压到哪个位置
# 将test.zip解压到当前目录
unzip test.zip
# 将test.zip解压到指定文件夹内
unzip test.zip -d /opt
安装
yum -y install unzip
16.Linux中软件安装
操作系统安装软件有许多种方式,一般分为:
下载安装包
rpm(Red Hat/Centos)、deb(Debian/Ubuntu)、源码编译安装
应用商店
Linux操作系统中有许多软件应用商店:
- Ubuntu软件中心(有界面)
- Deepin 应用商店(有界面)
- yum命令 软件包管理器(Centos、Fedora、RedHat)
- apt-get命令 软件包管理器(Ubuntu、Debian)
17.yum软件包管理器
Yum(全称为 Yellowdog Updater, Modified)是一个在Fedora和Red Hat Enterprise Linux等Linux发行版中,以自动化的方式管理软件包的一款工具。
它可以下载、安装、升级和删除RPM软件包,并自动处理依赖关系。
注意
yum命令需要root权限,可以su切换到root,或使用sudo提权
yum命令需要联网
语法
yum [选项] [操作] [软件名]
选项:
-y,自动确认,无需手动确认安装或卸载过程
操作:
search 搜索安装列表中,有没有需要的安装包
install 安装rpm软件包
remove 卸载
update 更新
check-update 检查是否有可用的更新rpm软件包
list 列出系统中已经安装的和可以安装的包
# 列出系统中已经安装的和可以安装的包
yum list
# yum search在yum源搜索指定的包
yum search wget
# 安装wget
yum -y install wget
# 卸载wget
yum -y remove wget
apt 或者 apt-get 在 Ubuntu系统用于安装软件
使用方式与yum命令只差一个单词的区别,别的都一样
Yum切换数据源
数据源
Yum数据源是指yum软件包管理器用于查找可安装软件包的服务器仓库,在Linux系统中,默认情况下已经配置了一些官方的Yum数据源,可以直接使用,但是,由于网络状况、服务器负载等原因,有时候我们需要切换到其他的Yum数据源进行软件包的下载和安装。
可选的数据源
- 清华大学开源软件镜像站 https://mirror.tuna.tsinghua.edu.cn/help/centos/
- CentOS镜像使用帮助 (163.com) https://mirrors.163.com/.help/centos.html
- 阿里云镜像
https://developer.aliyun.com/mirror/centos?spm=a2c6h.13651102.0.0.3e221b11JLb1zR
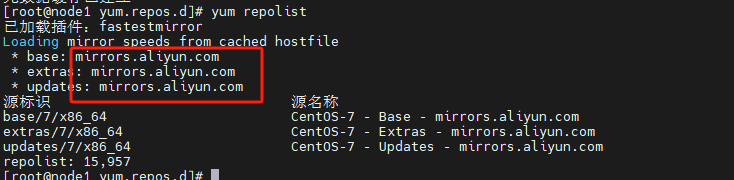
涉及的命令
yum [操作]
repolist 查看yum源
clean all 清除yum的所有缓存
makecache 生成新的缓存
18.安装软件 编译方式介绍
在Linux中编译安装软件通常需要执行以下几个步骤:
- 下载源代码包
- 可以从软件的官网、github等网下载
- 解压源代码包
- 进入软件包源代码目录
- 在解压后得到的目录中,通常会有一个README文件、INSTALL、SETUP文件,其中描述了如何编译和安装软件
- 执行configure脚本
- 大多数软件包都包含了一个configure脚本,用于检测系统环境,并生成Makefile文件,Makefile文件包含了编译和安装软件所需的所有信息,执行./configure命令即可
- 执行make命令
- make命令将根据Makefile文件中的指示开始编译软件,这些指示告诉系统如何将源代码转换为可运行的软件
- 执行make install命令
- 这个命令将按照Makefile文件中指定的位置将已编译好的二进制文件、库文件、文档等安装到系统中
注意
一些软件可能会要求,安装一些依赖库或开发工具,以便能够成功编译软件包
往往需要安装的软件,gcc、zlib
yum -y install gcc
19.安装软件 openssl
OpenSSL是一个开源的软件库,实现了安全套接字层 (SSL) 和传输层安全 (TLS) 协议
它是用 C 语言编写的,并在多个操作系统和平台上运行
OpenSSL 提供了一个广泛的功能集,包括:
- SSL/TLS 安全协议支持:OpenSSL 可以为客户端和服务器提供 SSL/TLS 安全通信。
- SSL/TLS 是一种通过加密和认证保护数据通信安全的标准协议
- 密码学支持:OpenSSL 实现了许多密码学算法,包括对称加密、非对称加密、哈希函数等,可以用于数据加密、数字签名和其他安全应用
- 证书管理:OpenSSL 可以生成和管理数字证书,这些证书可用于 SSL/TLS 通信和身份验证 X.509 证书认证机构 (CA)功能:OpenSSL 集成了 CA 功能,可以创建自己的证书颁发机构并颁发数字证书
- 远程命令执行:OpenSSL 可以在不同计算机之间建立安全连接,并使用 SSL/TLS 加密和认证执行远程命令
- 应用程序接口(API)和工具:OpenSSL 提供了 API,使应用程序能够使用 SSL/TLS
和其他安全通信功能。该库还包含一些命令行工具,可用于测试和诊断 SSL/TLS 连接以及执行其他安全任务
总之,OpenSSL 是一个多功能、灵活且广泛使用的软件库
下载源代码包
网站地址:https://www.openssl.org/source/
下载地址:https://www.openssl.org/source/openssl-1.1.1t.tar.gz
解压源代码包
tar -xzvf openssl-1.1.1t.tar.gz
进入软件包源代码目录
cd openssl-1.1.1t
执行configure脚本
./config
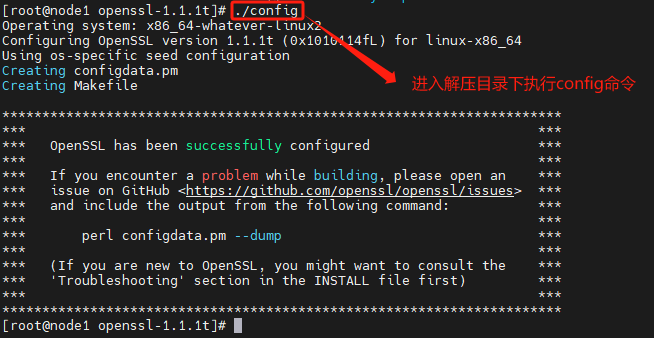
执行make install命令
make && make install
配置链接
ln -s /usr/local/lib64/libssl.so.1.1 /usr/lib64/libssl.so.1.1
ln -s /usr/local/lib64/libcrypto.so.1.1 /usr/lib64/libcrypto.so.1.1
注意
因为要编译软件,并且是C语言编写的,因此需要gcc模块,
安装方式:
yum -y install gcc
检查安装是否成功
openssl version

20.Python安装
下载源代码包
地址:https://www.python.org/downloads/
# 安装下载文件工具
yum install wget -y
# 下载文件
wget https://www.python.org/ftp/python/3.9.4/Python-3.9.4.tgz
解压源代码包
tar -xvf Python-3.9.4.tgz
进入软件包源代码目录
cd Python-3.9.4
注意有的时候某些软件安装前需要有必备软件,如python需要有openssl才可以执行
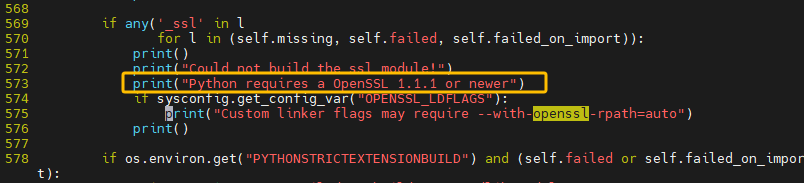
安装依赖库或开发工具
yum -y install zlib* libffi-devel bzip2-devel xz-devel
执行configure脚本
./configure prefix=/usr/local/python3 --enable-optimizations
#目的是为了编译
执行make install命令
make install
配置环境变量
# 修改环境变量文件
vim ~/.bash_profile
# 将python的路径,增加PATH中
PATH=$PATH:/usr/local/python3/bin/
# 执行文件
. ~/.bash_profile
检查安装是否成功
python3 -V
21.MySQL安装和配置
更新yum源
https://mirror.tuna.tsinghua.edu.cn/help/mysql/
新建 /etc/yum.repos.d/mysql-community.repo,内容如下:
[mysql-connectors-community]
name=MySQL Connectors Community
baseurl=https://mirrors.tuna.tsinghua.edu.cn/mysql/yum/mysql-connectors-community-el7-$basearch/
enabled=1
gpgcheck=1
gpgkey=https://repo.mysql.com/RPM-GPG-KEY-mysql
[mysql-tools-community]
name=MySQL Tools Community
baseurl=https://mirrors.tuna.tsinghua.edu.cn/mysql/yum/mysql-tools-community-el7-$basearch/
enabled=1
gpgcheck=1
gpgkey=https://repo.mysql.com/RPM-GPG-KEY-mysql
[mysql-5.7-community]
name=MySQL 5.7 Community Server
baseurl=https://mirrors.tuna.tsinghua.edu.cn/mysql/yum/mysql-5.7-community-el7-$basearch/
enabled=1
gpgcheck=1
gpgkey=https://repo.mysql.com/RPM-GPG-KEY-mysql
安装数据库
yum -y install mysql-community-server
提示如下错误:
Failing package is: mysql-community-libs-compat-5.7.37-1.el7.x86_64 GPG Keys are configured as: file:///etc/pki/rpm-gpg/RPM-GPG-KEY-mysql
原因是:GPG对于包的源key的验证没有通过
解决方案
使用如下命令安装:
yum -y install mysql-community-server --nogpgcheck

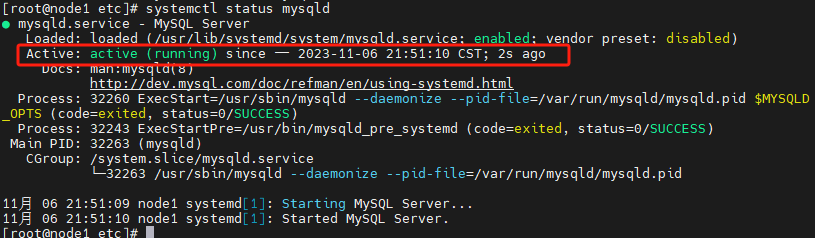
启动MySQL服务
systemctl start mysqld
找到登录的临时密码
此时MySQL已经开始正常运行,不过要想进入MySQL还得先找出此时root用户的密码,通过如下命令可以在日志文件中找出密码:
cat /var/log/mysqld.log | grep password
[root@nodel1 ~]# cat /var/log/mysqld.log | grep password
2023-11-02T16:56:50.866960Z 1 [Note] A temporary password is generated for root@localhost: tIjpUQy_x6Ms
复制粘贴上边的密码进入数据库
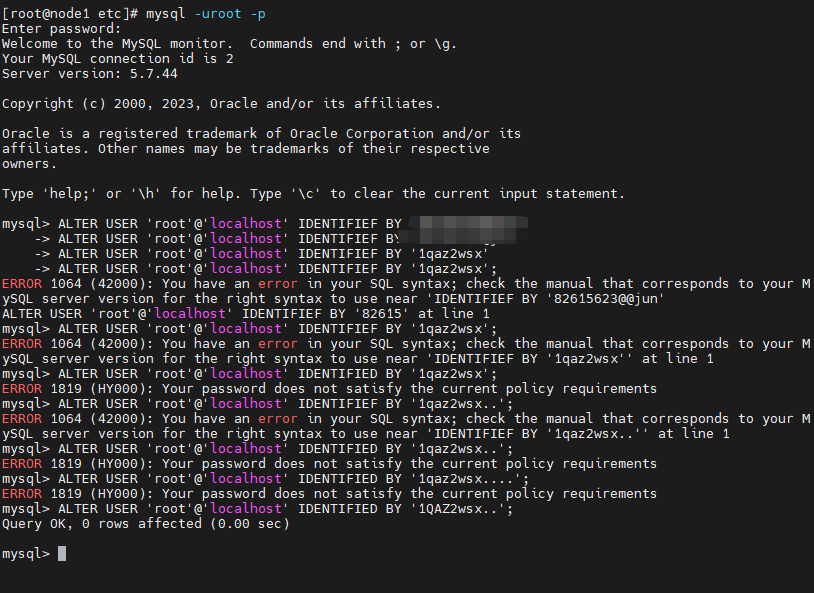
mysql -uroot -p
注意:
输入初始密码,登录进去后,此时不能做任何事情
因为MySQL默认必须修改密码之后才能操作
修改密码
ALTER USER ‘root’@‘localhost’ IDENTIFIED BY ‘123456’;
提示如下错误:
ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
原因是:密码太简单,不允许
解决方案:修改密码策略,因为密码太复杂不方便后期做实验
修改密码策略
使用命令修改密码策略两种方式:
mysql> set global validate_password_policy=0;
Query OK, 0 rows affected (0.00 sec)
mysql> set global validate_password_policy=LOW;
Query OK, 0 rows affected (0.00 sec)
mysql> SET GLOBAL validate_password_length=6;
Query OK, 0 rows affected (0.00 sec)
注:执行完初始化命令后需要输入数据库root用户密码
注:密码策略分四种
1、OFF(关闭) 2、LOW(低) 3、MEDIUM(中) 4、STRONG(强)
修改密码
ALTER USER ‘root’@‘localhost’ IDENTIFIED BY ‘123456’;
此处修改密码为root/1QAZ2wsx…
开启远程连接
use mysql;
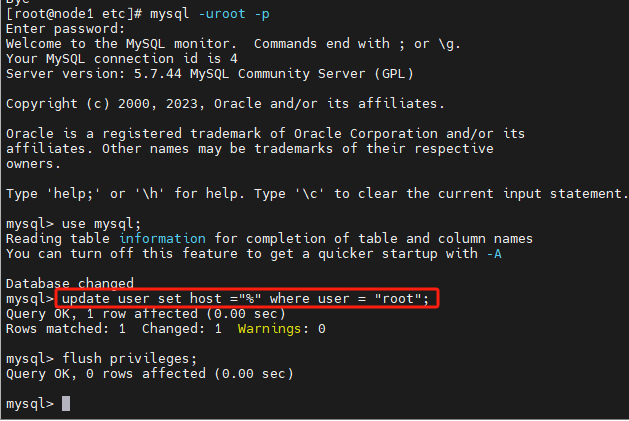
update user set host ="%" where user = "root";
# 刷新信息
flush privileges;
五、ShellScript脚本编程
1.Shell介绍
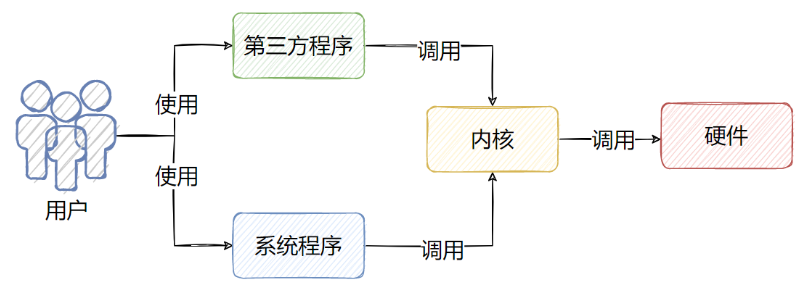
Shell 是一个用 C 语言编写的程序,它是用户使用 Linux 的桥梁。Shell 既是一种命令语言,又是一种程序设计语言。Shell 是指一种应用程序,这个应用程序提供了一个界面,用户通过这个界面访问操作系统内核的服务。
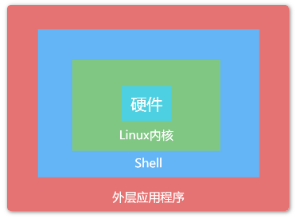
Shell的分类
在linux中有很多类型的shell,不同的shell具备不同的功能,shell还决定了脚本中函数的语法,Linux中默认的shell是/bash/shell( 重 点\默认 ),流行的还有/bin/sh、/bin/bash、/usr/bin/sh、/usr/bin/bash、/bin/tcsh、/bin/csh。
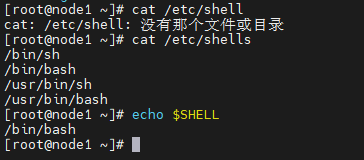
查看流行shell
cat /etc/shells
当前系统使用的Shell
echo $SHELL
2.入门
文件命名规范
文件名**.sh** 。 .sh是linux下bash shell 的默认后缀
Shell解析器
指定告知系统当前这个脚本要使用的shell解释器
#!/bin/bash
第一个Shell程序“Hello World”
在根目录下创建一个"scripts"文件夹,用来存储文件
mkdir scripts
创建Shell文件
touch hello.sh
编辑Shell文件
#!/bin/bash
echo “Hello World”
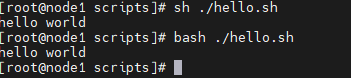
执行脚本
bash ./hello.sh
sh ./hello.sh
更简单的执行方式,因为我们知道当前就在bash下面,所以可以直接执行文件
./hello.sh
此时报错:-bash: ./hello.sh: Permission denied,这是因为没有权限:
ll hello.sh # -rw-r–r–. 1 root root 31 Jun 21 05:41 hello.sh
接下来给予权限
chmod +x hello.sh
此时你会发现,文件变了颜色,所有可执行文件都会变成绿色,执行文件
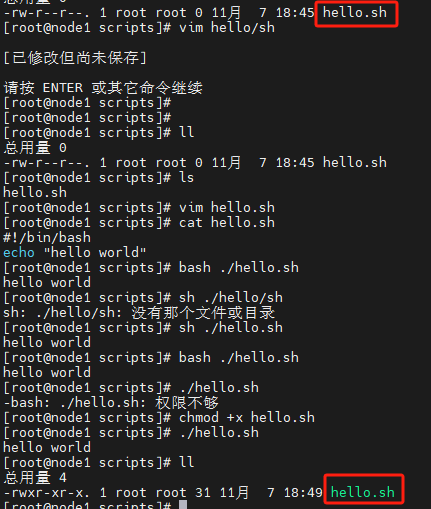
扩展执行方案:
source 文件.sh
. 文件.sh
3. Shell变量
3.1 系统预定义变量
运行Shell文件的区别
bash ./hello.sh 和 sh ./hello.sh
source hello.sh 和 . hello.sh
两种运行的方式差异性在于,第一种是在子bash环境下运行,而第二种是在当前bash环境下运行,我们通过运行type source可以看到 source is a shell builtin (source 是 shell 内嵌)
我们执行ps -f可以查看当前bash环境,创建一个子bash,继续通过ps -f查看,在当前子bash环境下,你依然可以运行shell文件
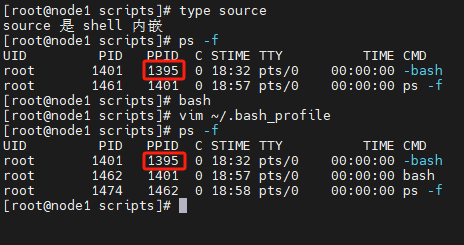
从结果上来看,两者好像没有什么区别,但是如果引入更多知识,例如变量:如果子shell中设置的当前变量,父shell是可不见的
变量简介
变量本质上其实是在内存中开辟一个空间用来临时存储数据,例如:age = 20
全局变量和局部变量的区别
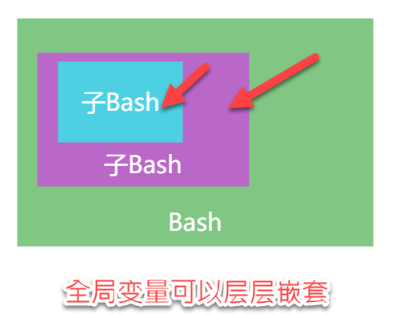
全局变量:层层嵌套的子bash依然可以访问
局部变量:只在当前的bash中可以访问,子bash和父bash都不能访问
常用系统变量
$HOME 、$PWD 、$SHELL 、$USER
查看当前所有的全局系统变量env
查看当前所有的变量set(包含全局和局部的,系统的,用户的)
3.2 用户自定义变量
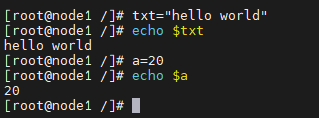
基本语法:定义变量:变量名=变量值
规则
- 等号前后不能有空格
- 在声明变量的时候是不需要添加$符号,但是使用时候需要添加
- 如果定义的是一个字符串,需要将值添加双引号或者单引号
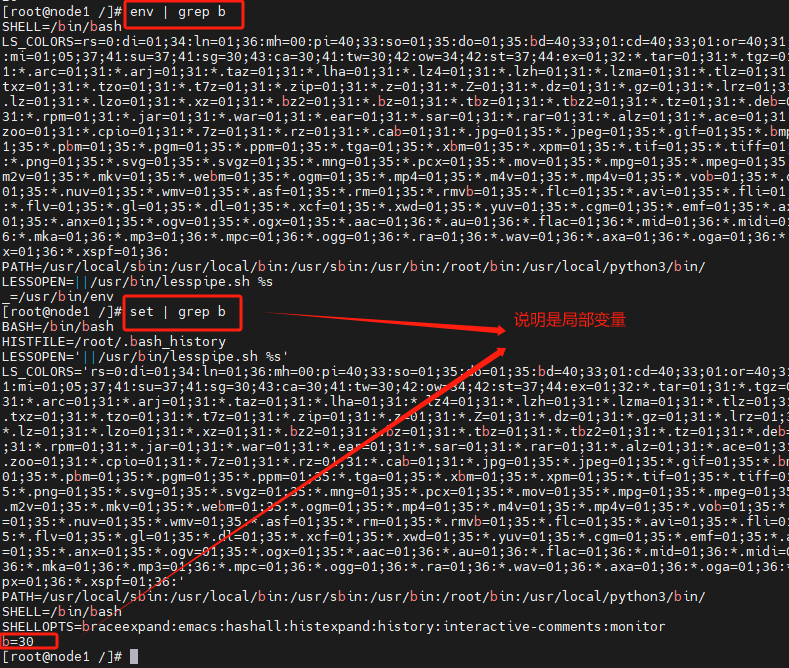
查看定义的变量是全局还是局部
全局:env | grep 变量名
局部:set | grep 变量名
当然,你可以进入子bash中去尝试输出变量,无法输出则是局部变量,可以输出则是全局变量
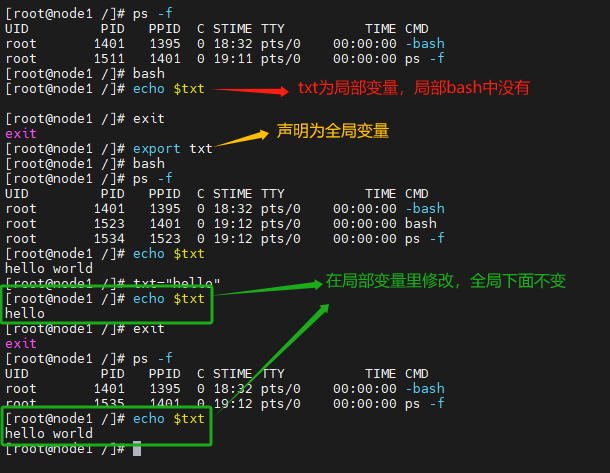
全局变量
如何定义一个全局变量呢?需要先声明一个局部变量,然后再通过export导出为一个全局变量
export 变量名
在子bash中修改全局变量,只会再当前环境中生效,不会影响父bash环境,哪怕是你增加export也依然不会影响到父bash环境
Shell脚本中使用变量
我们可以在hello.sh的脚本中去调用全局和局部变量
#!/bin/bash
echo $txt
在shell脚本中使用变量,同样遵循全局和局部变量的规则
3.3 只读变量和撤销变量
自定义变量注意事项:
- 变量命名规范:字母、数字和下划线组成,其中数字不能开头
- 自定义变量一般都是小写的
- 在shell中,变量是没有类型的,或者我们理解为全部都是字符串类型
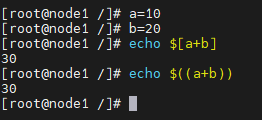
- 如果变量的值需要做数值运算,可以使用
(
(
1
+
1
)
)
或者
((1+1))或者
((1+1))或者[1+1]的形式
只读变量
在shell中,只读变量相当于是常量,定义之后不允许修改。定义规则
readonly 变量名=值
撤销变量
变量定义之后是可以撤销的,使用unset 变量名就可以撤销了
变量是可以撤销的,但是只读变量是不可以撤销的
3.4 特殊变量
在Shell中,存在一些特殊变量,他们具有特殊的意义
$n
$n代表接受参数,n是数字,代表在执行脚本时候传递的参数数量,例如$1-
9
代表第一个到第九个参数,十以上的数字,可以使用大括号包裹,例如
9代表第一个到第九个参数,十以上的数字,可以使用大括号包裹,例如
9代表第一个到第九个参数,十以上的数字,可以使用大括号包裹,例如{10}。比较特殊的是$0,代表当前脚本名称
#!/bin/bash
echo '======$n====='
echo 1st:$1
echo 2st:$2
echo 3st:$3
echo $0
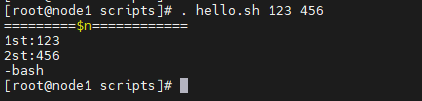
$#
$#获取输入参数的个数,一般用于循环中,判断参数的个数是否正确,加强脚本的健壮性
#!/bin/bash
echo '=====$#====='
echo 1st:$1
echo 2st:$2
echo 3st:$3
echo $#
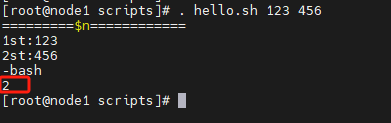
∗
和
*和
∗和@
∗
和
*和
∗和@非常相似,都代表命令行所有的参数,但是
∗
把参数看成是一个整体,例如
123456
。而
*把参数看成是一个整体,例如123 456。而
∗把参数看成是一个整体,例如123456。而@把每个参数区分对待,例如[123,456] 注意:在没有循环遍历时候,两者效果一致
#!/bin/bash
echo '=====$n====='
echo 1st:$1
echo 2st:$2
echo 3st:$3
echo '=====$*====='
echo $*
echo '=====$@====='
echo $@
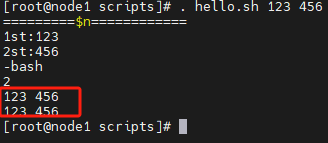
$?
$?最后一次执行命令的状态,如果是结果是0,证明上面执行的命令都是正确的,如果结果不是0(具体是哪个数字,有命令自己决定),则证明上面命令不正确了
[root@localhost scripts]# vim hello.sh
[root@localhost scripts]# echo $?
0
[root@localhost scripts]# hello.sh
-bash: hello.sh: command not found
[root@localhost scripts]# echo $?
127
[root@localhost scripts]#
4.运算符
在Shell中,还存在expr表达式,可以用于做运算
在Shell中,运算需要使用$((a+b))或者$[a+b]的形式
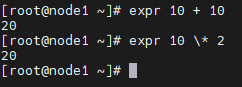
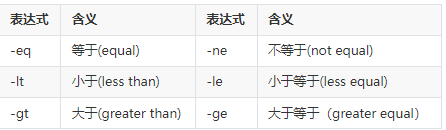
表达式 expr
expr 10 + 10
expr 10 - 10
expr 10 \* 10
运算符前后要添加空格
如何要赋值给一个变量,需要命令替换
a=$(expr 10 + 10)
a=`expr 10 + 10`

$((a+b))或者$[a+b]
$((10+10))
$[10+10]
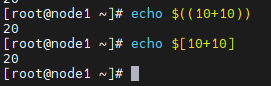
实例:计算 (5+4) * 10 的值
s=$[(5+5)*10]
脚本中操作
创建add.sh,在执行的时候,通过传递参数的形式实现加法效果
#!/bin/bash
sum=$[$1 + $2]
echo sum=$sum
5.条件判断
基本语法
test 表达式
[ 表达式 ] 注意:中括号前后需要有空格
[root@localhost scripts]# a=10
[root@localhost scripts]# echo $a
10
[root@localhost scripts]# test $a = 10
[root@localhost scripts]# echo $?
0
[root@localhost scripts]# test $a = 11
[root@localhost scripts]# echo $?
1
[root@localhost scripts]# [ $a = 10 ]
[root@localhost scripts]# echo $?
0
[root@localhost scripts]# [ $a = 11 ]
[root@localhost scripts]# echo $?
1
[root@localhost scripts]# [ $a=11 ]
[root@localhost scripts]# echo $?
0
[root@localhost scripts]# [ ]
[root@localhost scripts]# echo $?
1
[root@localhost scripts]# [ $a != 11 ]
[root@localhost scripts]# echo $?
0
[root@localhost scripts]# echo $a
10
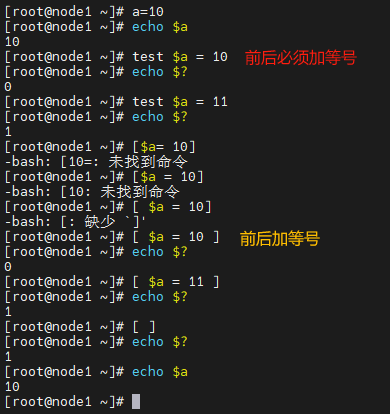
两个值比较
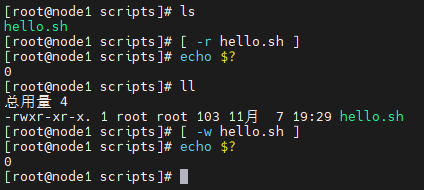
文件权限判断
- -r 有读的权限(read)
- -w 有写的权限(write)
- -x 有执行的权限(execute)
文件类型判断
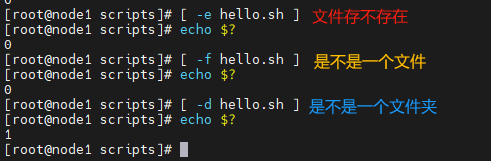
- -e 文件存在(existence)
- -f 文件存在并且是一个文件类型(file)
- -d 文件存在并且是一个目录类型(directory)
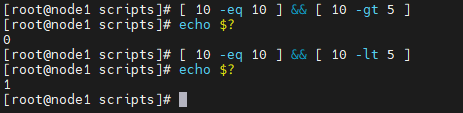
多条件判断
- && 与的关系,两者都成立
- || 或的关系,两者有一个成立
&& 表示前一个条命令执行成功之后,在执行第二个条件
|| 表示前一个条命令执行失败之后,再执行第二个条件
由此,我们可以衍生出来,类似三元运算符的形式
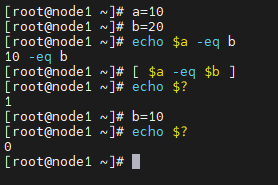
示例 [ $a -eq $b ] && echo “$a=$b” || echo “$a!=$b”
6.流程控制
if判断
基本语法
if [ 条件判断 ]; then
语句
fi
if [ 条件判断 ]
then
语句
fi

示例
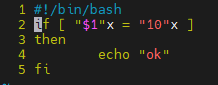
if [ $a = 10 ];then echo 'OK'; fi
#!/bin/bash
if [ $a = 10]
then
echo "ok"
fi
if [ $a = 10 -a $b = 10 ];then echo "ok";fi

if [ 条件判断 ]
then
语句
else
语句
fi
#!/bin/bash
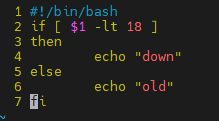
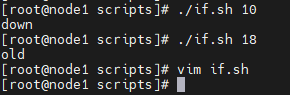
if [ $1 -lt 18 ]
then
echo "未成年"
else
echo "成年人"
fi
if [ 条件判断 ]
then
语句
elif [ 条件判断 ]
then
语句
else
语句
fi
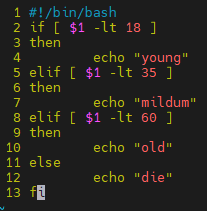
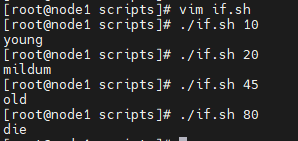
#!/bin/bash
if [ $1 -lt 18 ]
then
echo "未成年"
elif [ $1 -lt 35 ]
then
echo "青年人"
elif [ $1 -lt 60 ]
then
echo "壮年人"
else
echo "老年人"
fi
case语句
if 如果遇到多个条件,写起来会很麻烦,可以使用 case 改写
case $变量名 in
“值1”)
语句
;;
“值2”)
语句
;;
…省略其他分支…
*)
语句
;;
esac
注意事项
- case行结尾必须为单词"in",每一个模式匹配必须以右括号")"结束
- 双分号 “;;” 表示命令序列结束,相当于跳出当前判断语句
- 最后 “*)” 表示默认模式结尾,不符合最终的出口
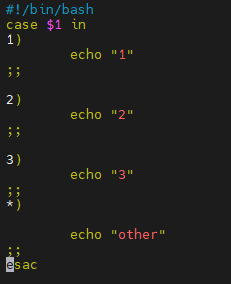
#!/bin/bash
case $1 in
1)
echo "值为1"
;;
2)
echo "值为2"
;;
3)
echo "值为3"
;;
*)
echo "其他数字"
;;
esac
for循环
循环语句用于重复执行某个操作。
for语句就是循环命令,可以指定循环的起点、终点和终止条件。
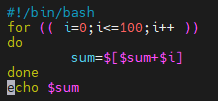
基本语法1
for (( 初始值; 循环控制条件; 变量变化))
do
语句
done
#!/bin/bash
for (( i=0;i<=100;i++ ))
do
sum=$[$sum+$i]
done
echo $sum

基本语法2
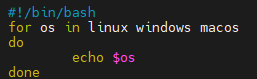
for 变量 in 值1 值2 值3…
do
语句
done
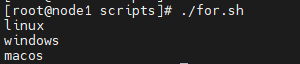
#!/bin/bash
for os in linux windows macos
do
echo $os
done
内部运算符
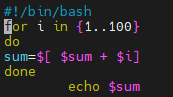
在shell中,{}是内部运算符,{}表示一个序列,例如,从1写到100: {1…100}
#!/bin/bash
for i in {1…100}
do
sum= [ [ [sum+$i]
done
echo $sum

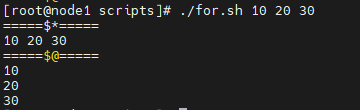
$*和$@
$*和$@非常相似,都代表命令行所有的参数,但是$*把参数看成是一个整体,例如123 456。而$@把每个参数区分对待,例如换行显示。 在没有循环遍历时候,两者效果一致
#!/bin/bash
echo '=====$*====='
for param in "$*"
do
echo $param
done
echo '=====$@====='
for param in "$@"
do
echo $param
done
while循环
while [ 条件判断 ]
do
语句
done
#!/bin/bash
a=1
while [ $a -le $1 ]
do
sum=$[$sum+$a]
a=$[$a+1]
done
echo $sum
#!/bin/bash
a=1
while [ $a -le $1 ]
do
# sum=$[$sum+$a]
# a=$[$a+1]
let sum+=a
let a++
done
echo $sum
7.读取控制台输入
基本语法
read 选项 参数
选项:
-p:指定读取值时候的提示符
-t:指定读取值时候的等待时间(秒) 如果不添加 -t 表示一直等待
参数:
变量:指定读取值的变量名
read -t 10 -p "请输入您的名字:" name
echo "welcome,$name"

8.系统函数
函数的本质就是一段可以反复调用的代码块
在Shell中,函数细分为系统函数和自定义函数
系统函数
可以测试系统命令,如使用率非常高的 date ,还可以获取时间戳 date +%s
当需要打印写一些系统日志信息文件的时候,文件的命名规则通常在最后会添加上时间戳
#!/bin/bash
filename="$1_log_$(date +%s)"
echo $filename
使用的系统命令(或者系统函数)date +%s要进行命令替换,也就是添加$(date +%s)
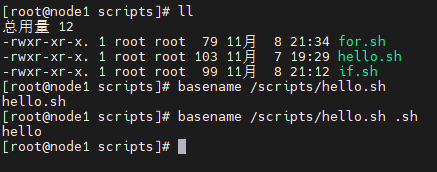
basename
basename 的作用是获取文件名称,它会删除所有的前缀包括最后一个"/"字符,然后将字符串显示出来
基本语法
basename [string/pathname][suffix]
suffix为后缀,如果suffix被指定了,basename将会pathname或string中的suffix去掉
可以先拿一个路径或者字符串测试
basename /scripts/cmd_test.sh
basename /scripts/cmd_test.sh .sh
basename /abc/def/cmd_test.sh
/abc/def/cmd_test.sh .sh
之前的特殊变量$n,其中$0是获取当前名字,但是带有路径,希望只获取名字,所以可以通过basename 去掉路径,甚至去掉后缀:
#!/bin/bash
echo '=====$n====='
echo script name:$0
#!/bin/bash
echo '=====$n====='
echo script name:$(basename $0 .sh)
dirname
dirname获取文件路径的绝对路径,从给定的包含绝对路径的文件名中去除文件名,然后返回剩余的路径
dirname /scripts/cmd_test.sh
dirname /abc/def/cmd_test.sh
可以获取某个文件的绝对路径:
#!/bin/bash
echo '=====$n====='
echo script path:$(cd $(dirname $0); pwd)
echo script name:$(basename $0 .sh)
9.自定义函数
基本语法
function 函数名(){
// 函数体
return 返回值
}
必须在调用函数之前,先声明函数
函数返回值可以通过$?获取,但注意,$?的值范围是0~255
实现一个两个数值相加的函数
#!/bin/bash
function add(){
s=$[$1 + $2]
echo "和:"$s
}
read -p "请输入第一个参数:" a
read -p "请输入第二个参数:" b
add $a $b
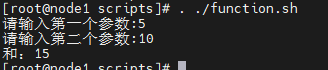
但是此时函数是没有返回值的,也就是无法获取函数的执行结果,可以将echo修改为return
#!/bin/bash
function add(){
s=$[$1 + $2]
return $s
}
read -p "请输入第一个参数:" a
read -p "请输入第二个参数:" b
add $a $b
echo "和:" $?
此时虽然有了返回值,因为$?的原因,计算结果最大也只能是255,我们可以换一种方式获取函数执行结果
#!/bin/bash
function add(){
sum=$[$1 + $2]
echo $sum
}
read -p "请输入第一个参数:" a
read -p "请输入第二个参数:" b
sum=$(add $a $b)
echo "和:" $sum
echo "和的平方:"$[$sum * $sum]
10.案例 归档文件
需求:实现一个目录归档备份的脚本,输入一个目录名称,将目录下所有文件按天归档保存,并将归档日期附加在文档文件名上,放在根目录下(/archive)
用到的归档命令:tar
后面可以加上-c选项表示归档,加上-z选项表示同时进行压缩,得到的文件后缀名为.tar.gz
#!/bin/bash
# 首先判断输入参数个数是否为1
if [ $# -ne 1 ]
then
echo "参数个数错误!应该输入一个参数作为归档目录名"
exit
fi
# 从参数中获取目录名称,查看目录名称是否存在
if [ -d $1 ]
then
echo
else
echo
echo "目录不存在!"
echo
exit
fi
# 获取绝对路径
DIR_NAME=$(basename $1)
DIR_PATH=$(cd $(dirname $1); pwd)
# 获取当前日期,归档文件拼接生成日期
DATE=$(date +%y%m%d)
# 定义生成的归档文件名称
FILE=archive_${DIR_NAME}_$DATE.tar.gz
# 定义生成归档文件的路径
DEST=/archive/$FILE
# 开始归档目录文件
echo "开始归档..."
echo
# -c 归档 z 压缩 f 可视化
tar -czf $DEST $DIR_PATH/$DIR_NAME
# 判断上面归档文件操作是否成功
if [ $? -eq 0 ]
then
echo
echo "归档成功"
echo "归档的文件为:$DEST"
echo
else
echo "归档出现问题!"
echo
fi
exit
只有当前用户具有之执行权限
chmod u+x daily_archive.sh
11.定时归档文件
将实现目录归档备份的脚本添加定时器,要求每天凌晨2点定时归档
crontab定时器:
f1 f2 f3 f4 f5 command
分 时 日 月 周 命令
第1列表示分钟0~59 每分钟用*或者 */1表示
第2列表示小时0~23(0表示0点)
第3列表示日期1~31
第4列表示月份1~12
第5列标识号星期0~6(0表示星期天)
第6列要运行的命令
crontab -l
crontab -e
*/1 * * * * date >> /scripts/crontab_test.txt #分钟-小时-日-月-周
crontab -r
在 12 月内, 每天的早上 6 点到 12 点,每隔 3 个小时 0 分钟执行一次 /usr/bin/backup
0 6-12/3 * 12 * /usr/bin/backup
周一到周五每天下午 5:00 寄一封信给 alex@domain.name
0 17 * * 1-5 mail -s "hi" alex@domain.name < /tmp/maildata
每月每天的午夜 0 点 20 分, 2 点 20 分, 4 点 20 分…执行 echo “haha”
20 0-23/2 * * * echo "haha"
给脚本添加定时器
0 2 * * * /scrtips/daily_archive.sh /scripts
12.正则表达式
正则表达式使用单个字符串来描述、匹配一系列符合某个语法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本。在 Linux 中,grep,sed,awk 等文本处理工具都支持通过正则表达式进行模式匹配
常规匹配
一串不包含特殊字符的正则表达式匹配它自己
cat /etc/passwd | grep root
常用特殊字符
特殊字符:^;
^匹配一行的开头
cat /etc/passwd | grep ^a
特殊字符:$
$匹配一行的结束
cat /etc/passwd | grep h$
^和$能否一起使用呢?
如果匹配规则只有^$会匹配什么呢?
cat /etc/passwd | grep ^root$
cat /scripts/daily_archive.sh | grep ^$
cat /scripts/daily_archive.sh | grep -n ^$
特殊字符:.
.匹配一个任意字符
cat /etc/passwd | grep r.t
cat /etc/passwd | grep r…t
特殊字符:*
* 不单独使用,他和上一个字符连用,表示匹配上一个字符 0 次或多次
cat /etc/passwd | grep ro*t
cat /etc/passwd | grep r.*t
字符区间(中括号):[]
[] 表示匹配某个范围内的一个字符
[6,8]------匹配6或者8
[0-9]------匹配一个0-9 的数字
[0-9]*------匹配任意长度的数字字符串
[a-z]------匹配一个 a-z 之间的字符
[a-z]*-----匹配任意长度的字母字符串
[a-c,e-f]—匹配 a-c 或者 e-f之间的任意字符
cat /etc/passwd | grep r[a,b]t
echo "23fsdfrat23f5y2t23sdf" | grep r[a,b]t
echo "23fsdfrat23f5y2t23sdf" | grep r[ab]t
echo "23fsdfraabat23f5y2t23sdf" | grep r[ab]*t
cat /etc/passwd | grep r[a-z]t
cat /etc/passwd | grep r[a-z]*t
特殊字符:\
\ 表示转义,并不会单独使用。由于所有特殊字符都有其特定匹配模式,当我们想匹配某一特殊字符本身时(例如,我想找出所有包含"$"的行),就会碰到困难。此时我们就要将转义字符和特殊字符连用,来表示特殊字符本身
cat /scripts/daily_archive.sh | grep ‘$’
匹配手机号
echo "14747696666" | grep ^1[345789][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]$
echo "14747696666" | grep -E ^1[345789][0-9]{9}$
13. cut
cut 的工作就是“剪”,具体的说就是在文件中负责剪切数据用的。cut 命令从文件的每行剪切字节、字符和字段并将这些字节、字符和字段输出。
基本用法
cut [选项参数] filename
说明:默认分隔符是制表符
选项说明
百 我
战 来
程 学
序 习
员 了
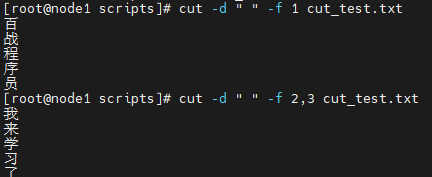
cut -d " " -f 1 cut_test.txt
cut -d " " -f 2,3 cut_test.txt
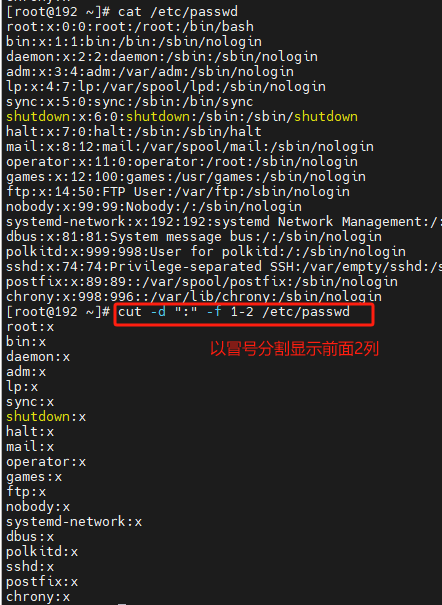
cat /etc/passwd | grep bash$
cat /etc/passwd | grep bash$ | cut -d ":" -f 1,7
cat /etc/passwd | grep bash$ | cut -d ":" -f 5-
cat /etc/passwd | grep bash$ | cut -d ":" -f -5
cat /etc/passwd | grep bash$ | cut -d ":" -f 5-7
ifconfig # 获取当前的IP
ifconfig ens33 # 获取ens33的信息
ifconfig ens33 | grep netmask # 获取具有IP的一行
ifconfig ens33 | grep netmask | cut -d " " -f 10 # 切分ens33的IP
ifconfig | grep netmask | cut -d " " -f 10 # 切分所有IP


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









