







 Hive是由Facebook开发的大数据仓库软件,使用SQL进行大数据分析,避免了编写MapReduce程序的复杂性。Hive的数据存储在HDFS上,元数据通常存储在MySQL,支持内部表和外部表,以及分区和桶的概念。Hive的执行过程涉及将Hive语句转化为MapReduce任务在YARN上执行。Hive支持多种文件格式,如TEXTFILE、SEQUENCEFILE、RCFILE和ORC File,其中ORC File提供了更好的性能和压缩。Hive的ROW FORMAT允许使用自定义或内置Serde进行数据序列化和反序列化。
Hive是由Facebook开发的大数据仓库软件,使用SQL进行大数据分析,避免了编写MapReduce程序的复杂性。Hive的数据存储在HDFS上,元数据通常存储在MySQL,支持内部表和外部表,以及分区和桶的概念。Hive的执行过程涉及将Hive语句转化为MapReduce任务在YARN上执行。Hive支持多种文件格式,如TEXTFILE、SEQUENCEFILE、RCFILE和ORC File,其中ORC File提供了更好的性能和压缩。Hive的ROW FORMAT允许使用自定义或内置Serde进行数据序列化和反序列化。
Hive
Hive简介
Facebook为了解决海量日志数据的分析而开发了Hive,后来开源给了Apache软件基金会。
官网定义:
The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL.
Hive是一种用类SQL语句来协助读写、管理那些存储在分布式存储系统上大数据集的数据仓库软件。
Hive的几个特点
Hive最大的特点是通过类SQL来分析大数据,而避免了写MapReduce程序来分析数据,这样使得分析数据更容易。
数据是存储在HDFS上的,Hive本身并不提供数据的存储功能
Hive是将数据映射成数据库和一张张的表,库和表的元数据信息一般存在关系型数据库上(比如MySQL)。
数据存储方面:它能够存储很大的数据集,并且对数据完整性、格式要求并不严格。
数据处理方面:因为Hive语句最终会生成MapReduce任务去计算,所以不适用于实时计算的场景,它适用于离线分析。
Hive架构
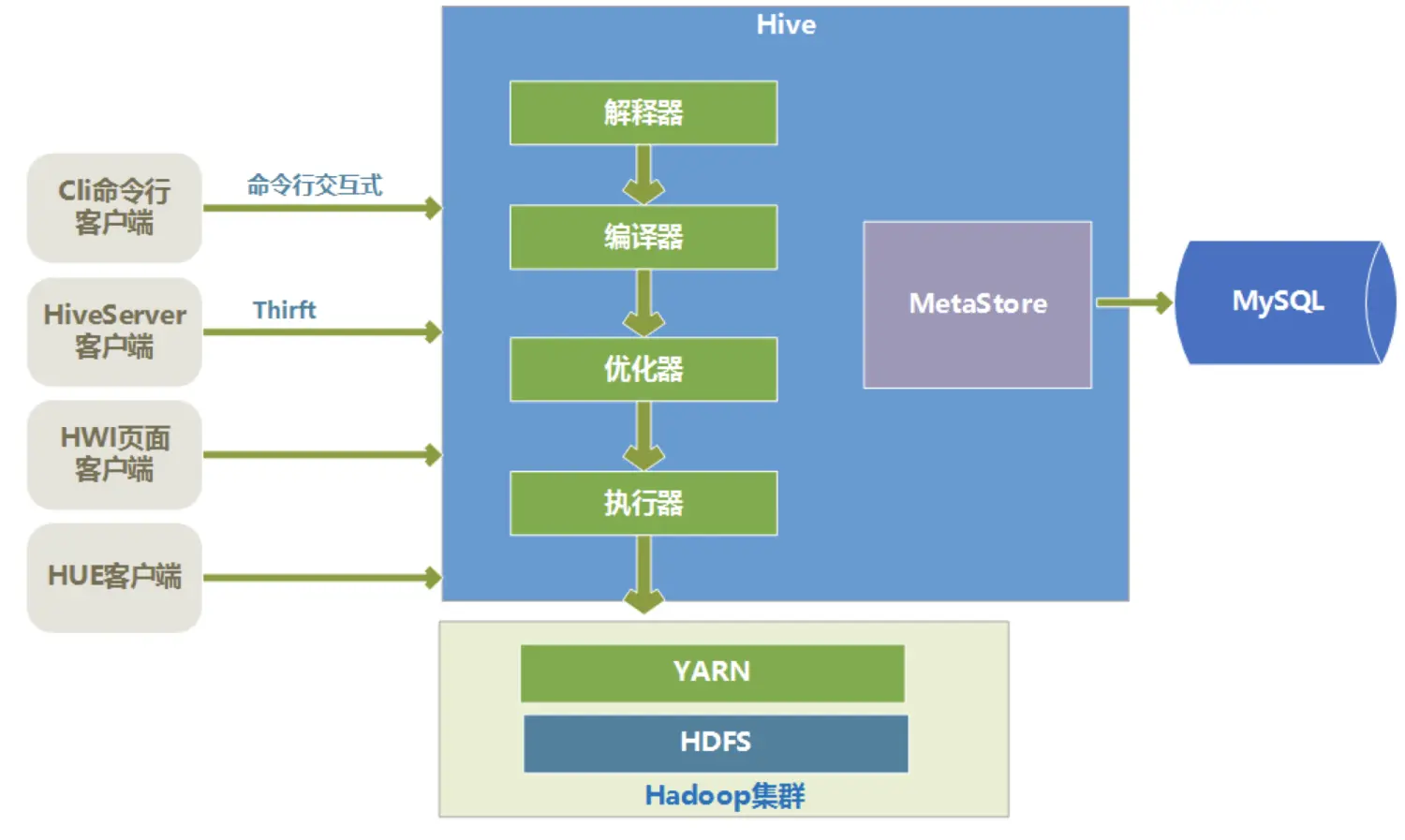
image.png
Hive的底层存储
Hive的数据是存储在HDFS上的。Hive中的库和表可以看作是对HDFS上数据做的一个映射。所以Hive必须是运行在一个Hadoop集群上的。
Hive语句的执行过程
Hive中的执行器,是将最终要执行的MapReduce程序放到YARN上以一系列Job的方式去执行。
Hive的元数据存储
Hive的元数据是一般是存储在MySQL这种关系型数据库上的,Hive和MySQL之间通过MetaStore服务交互。
Hive重要概念
外部表和内部表
内部表(managed table)
- 默认创建的是内部表(managed table),存储位置在
hive.metastore.warehouse.dir设置,默认位置是/user/hive/warehouse。 - 导入数据的时候是将文件剪切(移动)到指定位置,即原有路径
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 978
978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









