







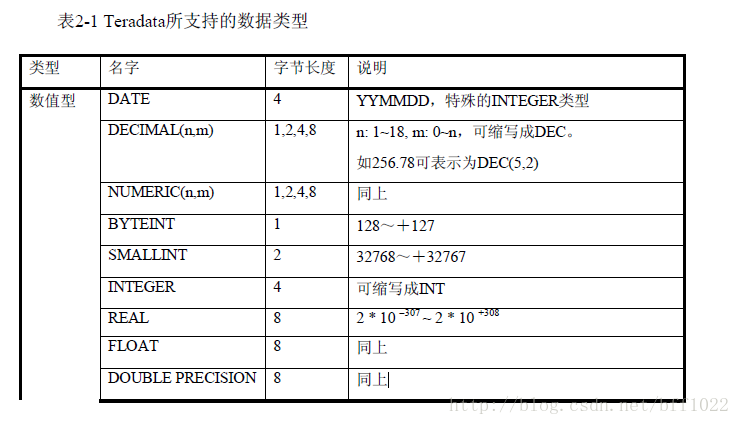
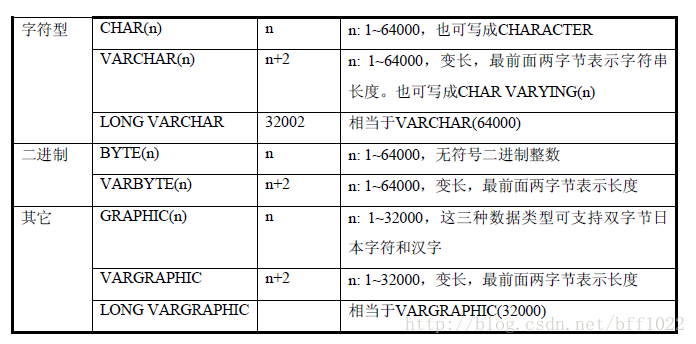
通过下面的命令来观察有哪些会话层参数:
show control;
改变交易处理模式的命令如下:
.SET SESSION TRANSACTION [ANSI|BTET]
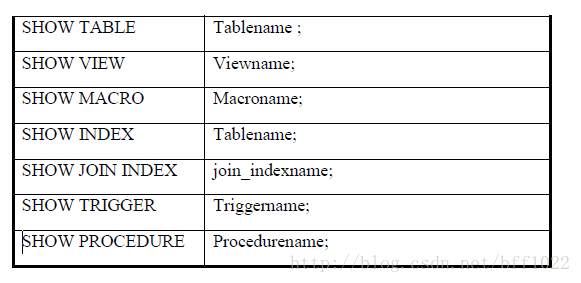
Teradata的帮助系统主要由三条命令组成,一条是HELP,一条是SHOW,另一
条是EXPLAIN。HELP命令可以提供有关数据库中各种目标的信息,SHOW命令则
用来显示这些目标的结构,包括创建这些目标的DDL语句。EXPLAIN命令以英文
文字的方式显示了系统处理一个SQL交易请求的执行过程。

使用方法:前面的+后面的参数
利用EXPLAIN命令,可以了解Teradata
执行一个SQL交易请求的详细过程和计划,这对于更进一步地理解Teradata的查询
处理机制有很大的帮助。另一方面,对于复杂SQL交易的调试来说,这也是不可缺
少的一个工具。
利用EXPLAIN解释一个SQL交易的方法很简单,就是在原来SQL语句的前面
加上EXPLAIN即可,其它完全不变。系统返回的信息包括:
! 提供完整的由分解器对SQL语句进行分解和优化后的AMP执行步。
! 这种执行计划是基于当前的数据分布情况而作出的,因此当数据分布发生
变化时,同样SQL语句产生的执行步可能不相同。
! EXPLAIN还会产生执行每个SQL步骤大致所需要的时间,但需要注意的
是,这个时间由于是根据早期版本的CPU处理时间来计算,因此往往和实
际情况相差很多,仅能作参考而已。

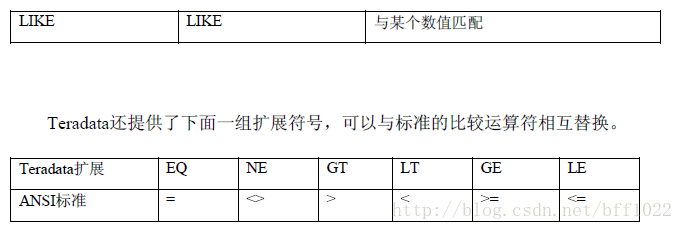
匹配符LIKE
LIKE用来进行字符串数据的模式匹配。用作匹配的字符串中可以包含下面的
通配符。
! %:表示除了NULL外的零个或多个字符组成的字符串。
! _:表示任何单个字符位置。
在LIKE结构的字符串中,'%'和'_'可以作为通配符使用,但是如果
需要匹配这些字符本身(比如查找95%),即把它们作为一般字符时使用,该如何区
分呢?
我们可以通过定义ESCAPE字符来达到这个目的,紧跟在ESCAPE字符后的’%’
和’_’作为一般字符看待。
例:
LIKE ''%A%%AAA__'' ESCAPE ''A''
在这个表达式中,将字母A定义为ESCAPE字符,其中:
! 第一个%为通配符;
! 第一个 A和其后的%联合表示字符%;
! 第三个%为通配符;
! 第二个 A和其后的A联合表示字符A;
! 第四个 A和其后的’_’联合表示字符_;
! 最后一个’_’为通配符。

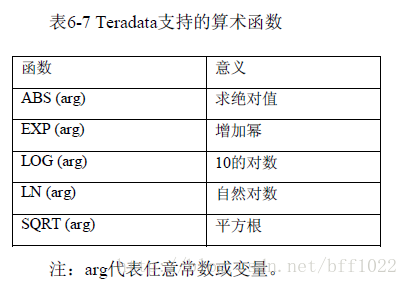
在Teradata数据库中将DATE型数据作为整数看待,但不容许无效的日期。计
算公式如下:
((YEAR - 1900) * 10000) + (MONTH * 100) + DAY
例:1997年3月31日的表达方式
YEAR = (1997 - 1900) * 10000 = 97 * 10000 = 970000
MONTH = (3 * 100) = 300
DAY = 31
DATE = 970331
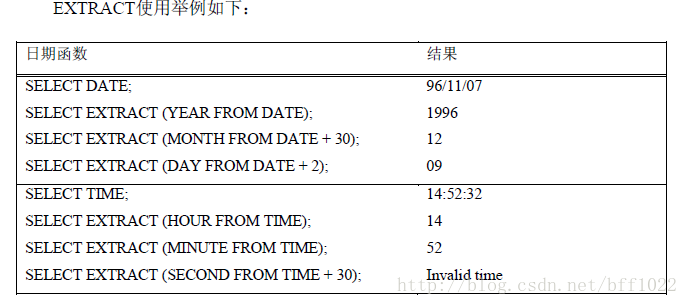
与日期有关的数据函数
中EXTRACT函数允许选取日期和时间中任意字段或任意间隔的值,
Teradata中EXTRACT函数支持日期数据中选取年、月、日,从时间数据中选取小
时、分钟和秒。
EXTRACT使用举例如下:
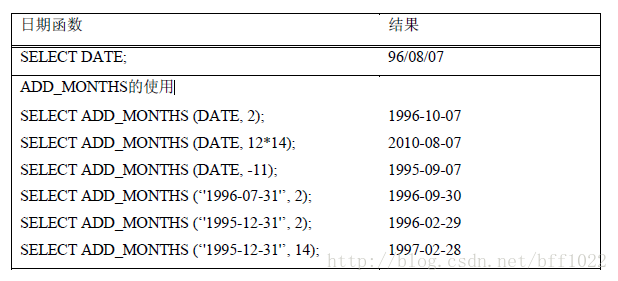
ADD_MONTHS表示从某日期增加或减少指定月份的日期。它考虑了大小月问
题,所以计算日期是准确的。ADD_MONTHS使用举例如下:
利用CAST作数据转换:利用CAST函数将一种数据类型转换成另一种数据类型。
例:
SELECT CAST (salary_amount AS INTEGER)
FROM employee;
Value Result
50500.75 50500
SELECT CAST (salary_amount AS DEC (6,0))
FROM employee;
Value Result
50500.75 50501.
SELECT CAST (last_name AS CHAR (5))
FROM employee
WHERE department_number = 401;
last_name
Johns
Trade
Teradata也可以使用CAST函数来完成上面的操作,另外,它也作了扩充。举
例来说,为了完成上面相同的操作,也可以使用下面的表达方式:
SELECT salary_amount (INTEGER);
SELECT salary_amount (DEC(6,0));
SELECT last_name (CHAR(5));
Teradata对CAST函数本身也作了扩展,比如为了将显示结果以大写表示,可
以使用下面的SQL语句
SELECT CAST (last_name AS CHAR (5) UPPERCASE)
FROM employee
WHERE department_number = 401;
last_name
JOHNS
TRADE

宏的定义
宏是用CREATE MACRO命令来定义的,如下例所示:
CREATE MACRO birthday_list AS
(SELECT last_name
,first_name
,birthdate
FROM employee
WHERE department_number = 201
ORDER BY birthdate; );
宏的执行很简单,使用EXEC命令就可以。例如,为了执行上面定义的宏,可
以使用下面的语句:
EXEC birthday_list;
使用SHOW命令可以显示一个宏的定义,如下所示:
SHOW MACRO birthday_list;
使用REPLACE MACRO命令可以改变宏的定义,如:
REPLACE MACRO birthday_list AS
(SELECT last_name
,first_name
,birthdate
FROM employee
WHERE department_number = 201
ORDER BY birthdate, last_name; ) ;
函数:
CHARACTERS函数也是Teradata的扩展,用于计算VARCHAR型数据字段的
实际字符串长度。CHARACTERS函数可以简写成CHARACTER、CHARS或者
CHAR。
TRIM函数用于去除字符数据中前头或后端的空格或者二进制数据
(BYTE与VARBYTE)中前头或后端的零。
FORMAT短语中可以使用的格式化字符主要为:
$ 美元标识符
9 数字位
Z 将数字中的前缀零去除
, 在指定位置插入逗号
. 指定小数点位置
- 在指定位置插入连字号
/ 在指定位置插入斜线
% 在指定位置插入百分号
X 字符数据,每个X代表一个字符
G 图形数据.一个G代表一个逻辑字符(双字节)
B 在指定位置插入空格
日期数据的缺省输出格式是:YY/MM/DD,这和ANSI标准是
一样的。而ANSI标准建议的日期显示格式是:YYYY-MM-DD。
注意:由于2000年问题,ANSI推荐使用日期格式为YYYY-MM-DD,或者其
它采用四位年的格式。
下面是一些对日期进行格式化的例子。
句法 结果
FORMAT 'YYYY/MM/DD' 1996/03/27
FORMAT 'DDbMMMbYYYY' 27 Mar 1996
FORMAT 'mmmBdd,Byyyy' Mar 27, 1996
FORMAT 'DD.MM.YYYY' 27.03.1996
FORMAT 'MM/DD/YY' 03/27/96
FORMAT 'MMM.DD.YY' Mar.27.96
FORMAT 'yy -- mm -- dd' 96 -- 03 -- 27
FORMAT 'DDDYY' 08696
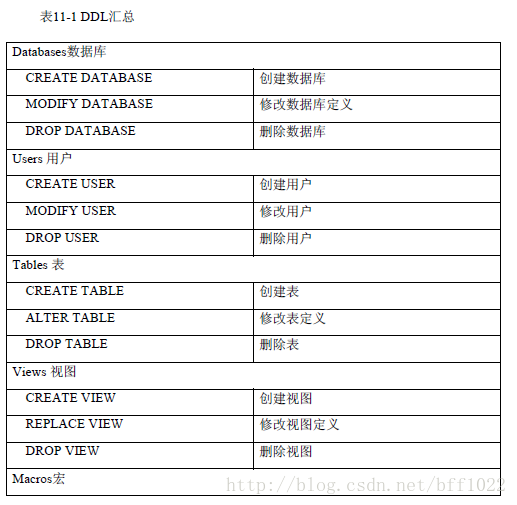

创建表:
CREATE <SET/MULTISET> TABLE <Table Name>
<Create Table Options>
<Column Definitions>
<Table-level Constraints>
<Index Definitions>;
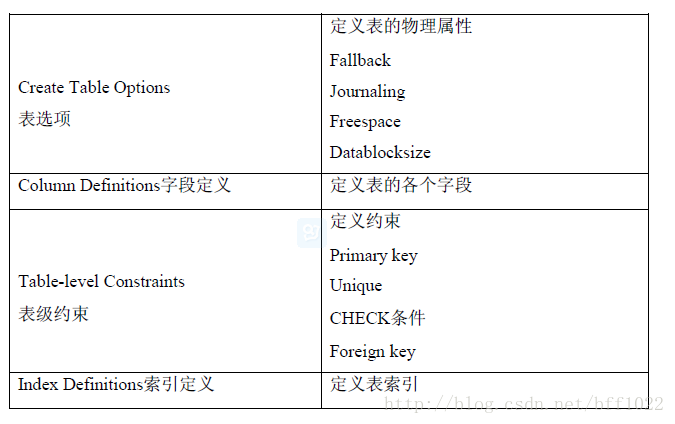
创建表的可选项(Create Table Options):
Teradata DDL允许在创建表时指定表的物理属性,包括:
是否允许重复记录
❍ SET 不允许记录重复
CREATE SET TABLE table1 ...
❍ MULTISET 允许记录重复
CREATE MULTISET TABLE table1 ...
数据保护
数据保护要结合FALLBACK和JOURNAL (流水或日志)。
FALLBACK是Teradata的一种数据保护机制,数据表的每一条记录都同时存放
两份,而且位于不同的AMP所控制的存储单元中;当数据发生问题或者AMP失败
时,可以利用存放在其他AMP上的数据保证对数据表的访问。
- FALLBACK 使用FALLBACK保护机制
- NO FALLBACK 不使用FALLBACK保护机制
日志有BEFORE和AFTER两种,分别保存了一条记录变化前后的状态。当系
统出错时,可以利用日志进行恢复。
存储空间选项
DATABLOCKSIZE用来指定数据块大小,最小的数据块为6144字节,最大的
数据块是32256字节。
FREESPACE用来定义在每个磁盘柱面上保留的空间(0-75%)。
例:
CREATE MULTISET TABLE table_1
, FALLBACK, NO JOURNAL
, FREESPACE = 10 PERCENT
, DATABLOCKSIZE = 16384 BYTES
(field1 INTEGER);
CONSTRAINT name 约束名称--可选
PRIMARY KEY 非空,无重复值
UNIQUE 无重复值
CHECK <布尔条件> 指定合法值的范围
REFERENCES 与其他字段的相关性(外键)
例:
CREATE TABLE employee_badge
(emp_id INTEGER NOT NULL
CONSTRAINT primary_1 PRIMARY KEY
,id_badge_number INTEGER
CONSTRAINT unique_1 UNIQUE
,salary INTEGER
CONSTRAINT check_1 CHECK (salary>0)
,job_code INTEGER
CONSTRAINT ref_1 REFERENCES job (job_code)
);
如在上面的例子中,最后一项定义了在EMPLOYEE_BADGE表中的
JOB_CODE必须和JOB表中的JOB_CODE对应,即前一个表中该字段的值必须在第
二个表中有对应的项。这实际上是一种所谓的参照完整性。另外要注意的是,具有
主键(Primary Key)约束的字段一定要定义为非空(NOT NULL)。
表级约束定义:
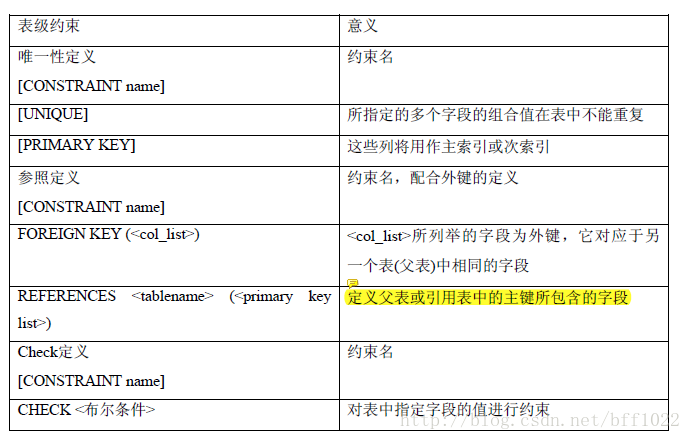
表级约束与字段级约束的主要区别是:在表级约束中可以指定当前表的多个
字段或其组合,而字段级约束只能引用当前字段。
我们来看一个表级约束的例子。
CREATE TABLE employee_badge
(emp_id INTEGER NOT NULL
,id_badge_num INTEGER NOT NULL
,salary INTEGER
,job_code INTEGER
,CONSTRAINT primary_1 PRIMARY KEY (emp_id)
,CONSTRAINT unique_1 UNIQUE (id_badge_num)
,CONSTRAINT check_1 CHECK (salary > 0 AND
job_code BETWEEN 100000 AND 499999)
,CONSTRAINT ref_1 FOREIGN KEY (job_code)
REFERENCES job (job_code));
比较字段级约束和表级约束的例子,可以看到:
字段级约束必须写在每个字段定义的后面,而表级约束是在字段定义结束后
再进行的。在表级约束中,一个约束可以同时定义多个字段。
下面是一个比较复杂的创建表的例子,注意学习。创建该表后用SHOW
TABLE观察一下内部的表达方式。
CREATE MULTISET TABLE emp_data
,FALLBACK
,NO BEFORE JOURNAL
,NO AFTER JOURNAL
,FREESPACE = 30
,DATABLOCKSIZE = 10000 BYTES (
employee_number INTEGER NOT NULL
,department_number SMALLINT
CONSTRAINT dep_check
CHECK (department_number BETWEEN 100 AND 999)
REFERENCES Department (department_number)
,job_code INTEGER COMPRESS
,last_name CHAR(20) NOT NULL
,first_name VARCHAR (20)
,street_address VARCHAR (30) TITLE 'Address'
,city CHAR (15) DEFAULT 'Boise'
COMPRESS Boise'
,state CHAR (2) WITH DEFAULT
,birthdate DATE FORMAT 'mm/dd/yyyy'
,salary_amount DECIMAL (10,2)
,sex CHAR (1) UPPERCASE
,CONSTRAINT emp_key
PRIMARY KEY (employee_number)
) INDEX (department_number);
删除表:
可以使用DROP TABLE语句删除表,该语句将删除表中的所有数据和在数据
字典中的表结构定义。
例:
删除前面例子中创建的雇员数据表。
DROP TABLE emp_data;
删除了表emp_data中的所有数据,并删除了emp_data在数据字典中的定义。如
果希望在使用这个表,必须重新创建。
例:
DELETE FROM emp_data;
或
DELETE emp_data;
删除了表emp_data中的所有数据。表定义仍然存在,可以增加数据。
修改表:
例:增加或删除字段
ALTER TABLE emp_data
ADD educ_level CHAR(1), ADD insure_type SMALLINT;
ALTER TABLE emp_data
DROP educ_level, DROP insure_type;
例:修改已有字段的属性
ALTER TABLE emp_data
ADD birthdate FORMAT 'mmmBdd,Byyyy'';
例:对没有FALLBACK的表建立FALLBACK保护
ALTER TABLE emp_data, FALLBACK;
例:同时修改表的多个属性
ALTER TABLE emp_data
, NO FALLBACK
DROP insure_type
, ADD educ_level CHAR(1);
例:修改约束定义
增加约束
ALTER TABLE emp_data
ADD CONSTRAINT
CHECK (sex = 'F' OR sex = 'M');
修改约束:
ALTER TABLE emp_data
MODIFY CONSTRAINT sal_range
CHECK ( salary_amount > 0 AND salary_amount < 1000000);
注意:表中已有数据如果不符合新的约束条件,约束的增加或修改不能成
功。
删除约束:
ALTER TABLE emp_data
DROP CONSTRAINT sal_range;
次索引:
主索引只能在CREATE TABLE时定义,而次索引既可以在创建表时定义,也
可以使用CREATE INDEX来定义。
例:为雇员表创建下面两个次索引。
为雇员名字建立命名的唯一次索引USI
CREATE UNIQUE INDEX fullname (last_name, first_name)
ON emp_data;
为工作代码建立非唯一性次索引NUSI,不命名NUSI
CREATE INDEX (job_code) ON emp_data;
例:显示表emp_data上的所有索引。
HELP INDEX emp_data;
当次索引创建后,也可以利用DROP INDEX来删除它们。注意,只有次索引
可以被删除,主索引是不能被删除的。
当删除命名索引时,可以只指定索引名称,也可以指定索引定义。而删除未
命名索引时,必须指定索引定义。
例:删除雇员表的所有次索引
删除命名索引
DROP INDEX FullName ON emp_data;
删除未命名索引
DROP INDEX (job_code) ON emp_data;
数据操作:
INSERT语句用于向表中添加一行或多行记录。插入一行记录的命令格式为:
INSERT INTO <表名> (列名1,列名2,...,列名n)
VALUES (列值表达式1,列值表达式2, ...,列值表达式n);
例:在雇员表中添加一新雇员信息:
INSERT INTO employee (last_name, first_name, hire_date, birthdate,
salary_amount, employee_number)
VALUES( arcia', aria',861027,541110,76500.00,1291);
如果添加整条记录,即给每个字段都有相应的值,则表名后的字段名可以省
略。如上面的例子可以改写成:
INSERT INTO employee
VALUES (1210,NULL,401,41201, mith', ames',890303,460421,41000);
Teradata对INSERT作了扩充,增加了一个称为INSERT-SELECT的功能。它以
子查询的方式将一个表的数据抽取并插入到另一个表中。举例来说,假设表
emp_copy与表emp的结构相同,下面的语句可以把表emp的所有行添加到表
emp_copy中,即复制表emp。
INSERT INTO emp_copy
SELECT * FROM emp;
INSERT-SELECT也可以将不同结构表的记录添加到目标表中。例如,我们创
建一张雇员生日表:
CREATE TABLE birthdays
(empno INTEGER NOT NULL
, lname CHAR(20) NOT NULL
, fname VARCHAR(30)
, birth DATE)
UNIQUE PRIMARY INDEX(empno);
然后,我们从雇员表中提取生日信息添加到生日表中。
INSERT INTO birthdays
SELECT employee_number ,last_name, first_name, birthdate
FROM employee;
update:
UPDATE语句用来更新表内满足条件的数据记录,基本语法为:
UPDATE <表名>
SET <列名1>=<列值表达式1>
,<列名2> = <列值表达式2>
, ...
,<列名n>=<列值表达式n>
WHERE <条件子句>;
DELETE:
DELETE删除表中满足条件的记录,基本语法为:
DELETE FROM <表名>
WHERE <条件子句>;
交易完整性:
我们在这章介绍了对数据库记录的更新、插入和删除。试想一下,如果某个
数据库的更新操作在进行到一半时系统产生问题,如突然停电等,交易的完整性是
否能得到保证?
在Teradata中,系统将保证一个交易的完整。怎样才算是一个交易呢,在
Teradata中,根据其所处方式的不同在处理时也有所不同。在Teradata缺省模式下,
以分号结束的每个SQL语句都是一个完整的交易,也可以使用BT (Begin
Transaction)和ET (End Transaction)来显示地定义一个交易。下面看一个例子:
例:
缺省方式
.LOGON
INSERT row1; (txn #1)
INSERT row2; (txn #2)
.LOGOFF
用BT和ET显示定义交易
.LOGON
BT;
INSERT row1; (txn #1)
INSERT row2;
COMMIT WORK;
ET;
.LOGOFF
第一部分中有两个SQL语句,用分号结束,表示两个交易,任何一个失败不会
影响另一个的执行。而第二部分用BT和ET显示地规定:在BT和ET之间的所有SQL
是一个交易,只有最后的COMMIT WORK执行成功后,才会真正地更新数据库。
执行过程中任何一个SQL语句失败,都会使整个交易失败,系统将自动进行恢复
(Rollback)处理。
在ANSI方式下,必须进行显示地提交才能完成一个交易。换言之,执行多个
数据记录插入动作后,如果不显示提交就退出,则这些插入动作都将Rollback。
.LOGON
INSERT row1; (txn #1)
INSERT row2;
.LOGOFF
没有显示提交就退出,两个INSERT将Rollback
.LOGON
INSERT row1; (txn #1)
INSERT row2;
COMMIT WORK;
.LOGOFF
显示提交,两个INSERT作为一个交易,要么完全成功,要么两个都失败。
参数宏:
所谓参数宏,是指在宏中包含可以替代值的变量。下面是一个简单的参数宏
定义:
CREATE MACRO dept_list(dept INTEGER)
AS
( SELECT last_name
FROM employee
WHERE department_number = :dept );
该宏的功能是在雇员表中选取某个部门全部雇员的姓,宏dept_list定义了一个
参数dept,类型是整数。作为部门代码参数。
运行宏dept_list的语句为:
EXEC dept_list(301);
其结果是返回部门编号为301的所有雇员的姓。
如同这个简单的例子,参数在宏中的引用是通过冒号(:) +参数名而实现的。
多参数宏:
参数宏可以包含多个参数,每个参数可以定义各自的类型和属性。我们通过
参数宏new_dept来介绍多参数宏的创建和运行。
宏new_dept的功能是向部门表添加一行数据,每个字段的值通过参数传递;然
后,显示添加的部门信息。具体的宏定义如下:
CREATE MACRO new_dept
(dept INTEGER
,budget DEC(10,2) DEFAULT 0
,name CHAR(30)
,mgr INTEGER)
AS
( INSERT INTO department
(department_number
,department_name
,budget_amount
,manager_employee_number)
VALUES( :dept
,:name
,:budget
,:mgr);
SELECT department_number (TITLE 'number')
,department_name (TITLE 'name')
,budget_amouunt (TITLE 'budget')
,manager_employee_number (TITLE 'manager')
FROM department
WHERE department_number = :dept;
);
利用宏实现参照完整性:
这里用一个例子来说明。
CREATE MACRO new_employee
( number INTEGER
,MGR INTEGER
,dept INTEGER
,job INTEGER
,lastname CHAR (20)
,firstname VARCHAR (30)
,hired DATE
,birth DATE
,salary DECIMAL (10, 2))
AS
(ROLLBACK WORK `Invalid Hire'
WHERE (:hired - :birth) / 365 > 21;
ROLLBACK WORK `Invalid Department'
WHERE :dept NOT IN
(SELECT department_number
FROM department
WHERE department_number = :dept);
ROLLBACK WORK `Invalid Job Code'
WHERE :job NOT IN
(SELECT job_code
FROM job
WHERE job_code = :job);
INSERT INTO employee
( employee_number
,manager_employee_number
,department_number
,job_code
,last_name
,first_name
,hire_date
,birthdate
,salary_amount )
VALUES
( :number
, :mgr
, :dept
, :job
, :lastname
, :firstname
, :hired
, :birth
, :salary );
);
利用这个宏来录入新雇员时,必须满足如下条件:
! 受雇时应年满21岁
! 应有一个合法的部门编号
! 应有一个合法的工作代码
实际上,在创建表时也可以定义参照完整性(约束),如:
CREATE TABLE employee
(employee_number INTEGER
, ......
,salary_amount DECIMAL (10,2)
,CHECK (hire_date - birthdate) /365 < 21)
,FOREIGN KEY (department_number)
REFERENCES department (department_number)
,FOREIGN KEY (job_code)
REFERENCES job (job_code)
);















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









