







收集整理了一份《2024年最新Python全套学习资料》免费送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Python知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来
如果你需要这些资料,可以添加V无偿获取:hxbc188 (备注666)

正文
今天公司有个需求,需要做一些指定网站查询后的数据的抓取,于是花了点时间写了个demo供演示使用。
思想很简单:就是通过Java访问的链接,然后拿到html字符串,然后就是解析链接等需要的数据。
技术上使用Jsoup方便页面的解析,当然Jsoup很方便,也很简单,一行代码就能知道怎么用了:
Document doc = Jsoup.connect(“http://www.oschina.net/”)
.data(“query”, “Java”) // 请求参数
.userAgent(“I ’ m jsoup”) // 设置 User-Agent
.cookie(“auth”, “token”) // 设置 cookie
.timeout(3000) // 设置连接超时时间
.post(); // 使用 POST 方法访问 URL
下面介绍整个实现过程:
1、分析需要解析的页面:
网址:http://www1.sxcredit.gov.cn/public/infocomquery.do?method=publicIndexQuery
页面:
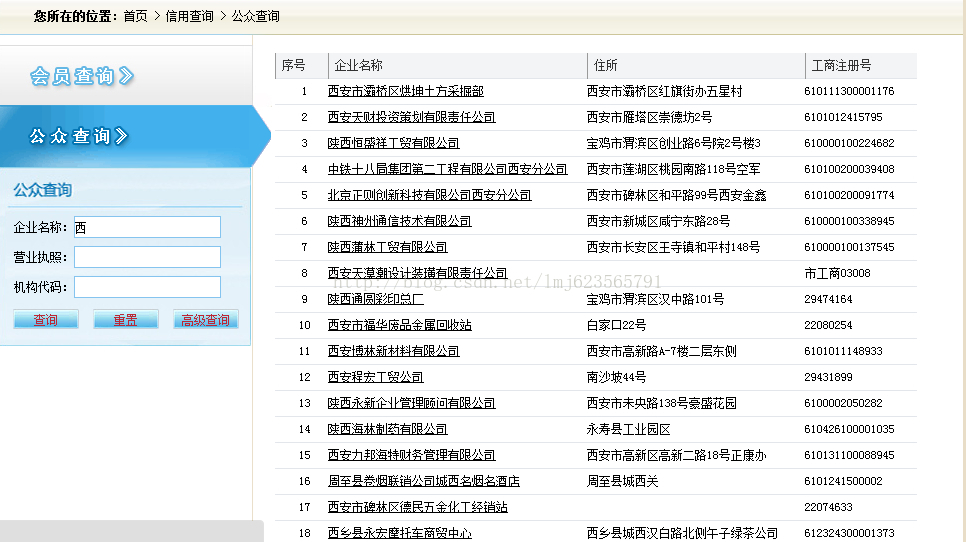
先在这个页面上做一次查询:观察下请求的url,参数,method等。
这里我们使用chrome内置的开发者工具(快捷键F12),下面是查询的结果:
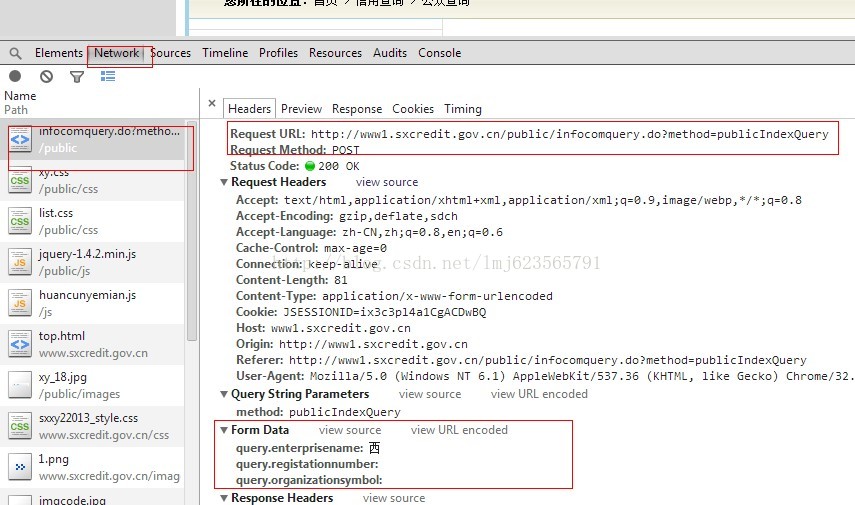
我们可以看到url,method,以及参数。知道了如何或者查询的URL,下面就开始代码了,为了重用与扩展,我定义了几个类:
1、Rule.java用于指定查询url,method,params等
package com.zhy.spider.rule;
/**
-
规则类
-
@author zhy
*/
public class Rule
{
/**
- 链接
*/
private String url;
/**
- 参数集合
*/
private String[] params;
/**
- 参数对应的值
*/
private String[] values;
/**
- 对返回的HTML,第一次过滤所用的标签,请先设置type
*/
private String resultTagName;
/**
-
CLASS / ID / SELECTION
-
设置resultTagName的类型,默认为ID
*/
private int type = ID ;
/**
*GET / POST
- 请求的类型,默认GET
*/
private int requestMoethod = GET ;
public final static int GET = 0 ;
public final static int POST = 1 ;
public final static int CLASS = 0;
public final static int ID = 1;
public final static int SELECTION = 2;
public Rule()
{
}
public Rule(String url, String[] params, String[] values,
String resultTagName, int type, int requestMoethod)
{
super();
this.url = url;
this.params = params;
this.values = values;
this.resultTagName = resultTagName;
this.type = type;
this.requestMoethod = requestMoethod;
}
public String getUrl()
{
return url;
}
public void setUrl(String url)
{
this.url = url;
}
public String[] getParams()
{
return params;
}
public void setParams(String[] params)
{
this.params = params;
}
public String[] getValues()
{
return values;
}
public void setValues(String[] values)
{
this.values = values;
}
public String getResultTagName()
{
return resultTagName;
}
public void setResultTagName(String resultTagName)
{
this.resultTagName = resultTagName;
}
public int getType()
{
return type;
}
public void setType(int type)
{
this.type = type;
}
public int getRequestMoethod()
{
return requestMoethod;
}
public void setRequestMoethod(int requestMoethod)
{
this.requestMoethod = requestMoethod;
}
}
简单说一下:这个规则类定义了我们查询过程中需要的所有信息,方便我们的扩展,以及代码的重用,我们不可能针对每个需要抓取的网站写一套代码。
2、需要的数据对象,目前只需要链接,LinkTypeData.java
package com.zhy.spider.bean;
public class LinkTypeData
{
private int id;
/**
- 链接的地址
*/
private String linkHref;
/**
- 链接的标题
*/
private String linkText;
/**
- 摘要
*/
private String summary;
/**
- 内容
*/
private String content;
public int getId()
{
return id;
}
public void setId(int id)
{
this.id = id;
}
public String getLinkHref()
{
return linkHref;
}
public void setLinkHref(String linkHref)
{
this.linkHref = linkHref;
}
public String getLinkText()
{
return linkText;
}
public void setLinkText(String linkText)
{
this.linkText = linkText;
}
public String getSummary()
{
return summary;
}
public void setSummary(String summary)
{
this.summary = summary;
}
public String getContent()
{
return content;
}
public void setContent(String content)
{
this.content = content;
}
}
3、核心的查询类:ExtractService.java
package com.zhy.spider.core;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import javax.swing.plaf.TextUI;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.zhy.spider.bean.LinkTypeData;
import com.zhy.spider.rule.Rule;
import com.zhy.spider.rule.RuleException;
import com.zhy.spider.util.TextUtil;
/**
-
@author zhy
*/
public class ExtractService
{
/**
-
@param rule
-
@return
*/
public static List extract(Rule rule)
{
// 进行对rule的必要校验
validateRule(rule);
List datas = new ArrayList();
LinkTypeData data = null;
try
{
/**
- 解析rule
*/
String url = rule.getUrl();
String[] params = rule.getParams();
String[] values = rule.getValues();
String resultTagName = rule.getResultTagName();
int type = rule.getType();
int requestType = rule.getRequestMoethod();
Connection conn = Jsoup.connect(url);
// 设置查询参数
if (params != null)
{
for (int i = 0; i < params.length; i++)
{
conn.data(params[i], values[i]);
}
}
// 设置请求类型
Document doc = null;
switch (requestType)
{
case Rule.GET:
doc = conn.timeout(100000).get();
break;
case Rule.POST:
doc = conn.timeout(100000).post();
break;
}
//处理返回数据
Elements results = new Elements();
switch (type)
{
case Rule.CLASS:
results = doc.getElementsByClass(resultTagName);
break;
case Rule.ID:
Element result = doc.getElementById(resultTagName);
results.add(result);
break;
case Rule.SELECTION:
results = doc.select(resultTagName);
break;
default:
//当resultTagName为空时默认去body标签
if (TextUtil.isEmpty(resultTagName))
{
results = doc.getElementsByTag(“body”);
}
}
for (Element result : results)
最后
Python崛起并且风靡,因为优点多、应用领域广、被大牛们认可。学习 Python 门槛很低,但它的晋级路线很多,通过它你能进入机器学习、数据挖掘、大数据,CS等更加高级的领域。Python可以做网络应用,可以做科学计算,数据分析,可以做网络爬虫,可以做机器学习、自然语言处理、可以写游戏、可以做桌面应用…Python可以做的很多,你需要学好基础,再选择明确的方向。这里给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
👉Python所有方向的学习路线👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

👉Python必备开发工具👈
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

👉Python全套学习视频👈
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

👉实战案例👈
学python就与学数学一样,是不能只看书不做题的,直接看步骤和答案会让人误以为自己全都掌握了,但是碰到生题的时候还是会一筹莫展。
因此在学习python的过程中一定要记得多动手写代码,教程只需要看一两遍即可。

👉大厂面试真题👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

如果你需要这些资料,可以添加V无偿获取:hxbc188 (备注666)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
👉实战案例👈
学python就与学数学一样,是不能只看书不做题的,直接看步骤和答案会让人误以为自己全都掌握了,但是碰到生题的时候还是会一筹莫展。
因此在学习python的过程中一定要记得多动手写代码,教程只需要看一两遍即可。
👉大厂面试真题👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
如果你需要这些资料,可以添加V无偿获取:hxbc188 (备注666)
[外链图片转存中…(img-C6EmqlCe-1713813253147)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 776
776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









