






在数据库应用开发中,我们经常需要面对复杂的SQL式计算,比如多层分组中的关联计算。在SQL中,分组必须同时进行汇总计算,并且不能进行对象式关联访问,因此处理这类问题会比较复杂,只能用窗口函数嵌套多层子查询这类高级技巧来实现。而本文要介绍的SPL能够支持真正的分组,进行直观的对象式关联访问,从而解决这类问题更加容易。
分组关联在实际业务中遇到的很多,下面以实际业务为蓝本设计一个比较通用的例子,以此说明SPL实现分组关联的具体过程:
计算目标:查询出缺货的DVD分店,即现存的DVD拷贝不到4类的分店。
数据结构:
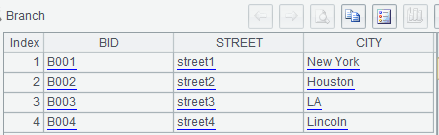
l Branch表,存储DVD分店信息;
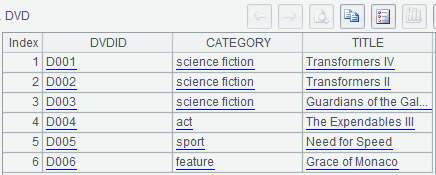
l DVD表,存储DVD的标题及分类信息,DVD是虚拟的数据,比如“变形金刚4”是一个DVD,但它不是一张可见的光盘
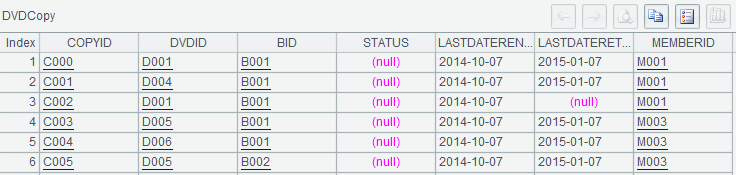
l DVDCopy表,存储DVD的多张拷贝,DVD拷贝是真正的光盘,以实体形式存放于各个分店。注意:DVDCopy表以BranchID字段和Branch表关联,以DVDID字段和DVD表关联。
下面是部分数据示例:
Branch表:
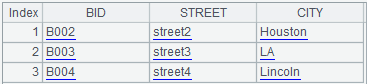
| BID | Street | City |
| B001 | street1 | New York |
| B002 | street2 | Houston |
| B003 | street3 | LA |
| B004 | street4 | Lincoln |
DVD表:
| DVDID | Category | Title |
| D001 | science fiction | Transformers IV |
| D002 | science fiction | Transformers II |
| D003 | science fiction | Guardians of the Galaxy |
| D004 | act | The Expendables III |
| D005 | sport | Need for Speed |
| D006 | feature | Grace of Monaco |
DVDCopy表:
| CopyID | DVDID | BID | Status | LastDateRented | LastDateReturned | MemberID |
| C000 | D001 | B001 | 7/10/2014 | 7/13/2014 | M001 | |
| C001 | D004 | B001 | 7/10/2014 | 7/13/2014 | M001 | |
| C002 | D001 | B001 | 7/10/2014 | M001 | ||
| C003 | D005 | B001 | 7/10/2014 | 7/13/2014 | M003 | |
| C004 | D006 | B001 | 7/10/2014 | 7/13/2014 | M003 | |
| C005 | D005 | B002 | 7/10/2014 | 7/13/2014 | M003 | |
| C006 | D002 | B002 | 7/10/2014 | 7/13/2014 | M006 | |
| C007 | D002 | B002 | 7/10/2014 | 7/13/2014 | M007 | |
| C008 | D001 | B002 | 7/10/2014 | 7/13/2014 | M008 | |
| C009 | D004 | B002 | 7/10/2014 | 7/13/2014 | M009 | |
| C010 | D005 | B002 | 7/10/2014 | 7/13/2014 | M010 | |
| C011 | D006 | B002 | Miss | 7/10/2014 | 7/13/2014 | M010 |
| C000 | D001 | B003 | 7/10/2014 | 7/13/2014 | M001 | |
| C001 | D004 | B003 | 7/10/2014 | 7/13/2014 | M001 | |
| C002 | D001 | B003 | Miss | 7/10/2014 | M001 | |
| C003 | D005 | B003 | 7/10/2014 | 7/13/2014 | M003 |
说明:
1. 计算结果应当是Branch表中的某些记录。
2. DVDCopy表中的Status字段如果是“Miss”,则说明光盘丢失。LastDateReturned字段如果为空,则说明光盘借出尚未归还。显然,丢失或未归还的光盘不在计算范围内,应当过滤掉。
3. 应当考虑某些分店可能在DVDCopy表中不存在记录,虽然这种情况比较罕见。
解题思路:
1. 从DVDCopy表过滤出店里现存的DVD拷贝(没有丢失或借出)。
2. 按照BID对DVDCopy表分组,每组就是一个门店所有的DVD拷贝。
3. 找到每个门店的DVD拷贝对应的DVD,再计算出这些DVD的分类数量。
4. 查询出现存的DVD分类数量小于4的门店,这样的门店符合要求。
5. 找到DVDCopy表中没出现过的门店,这样的门店也符合要求。
6. 将两类符合要求的门店合并。
SPL代码:
| A | |
| 1 | =Branch=db.query("select * from Branch") |
| 2 | =DVD=db.query("select * from DVD") |
| 3 | =DVDCopy=db.query("select * from DVDCopy") |
| 4 | =DVDCopy.switch(DVDID,DVD:DVDID; BID,Branch:BID) |
| 5 | =DVDCopy.select(STATUS!="Miss" && LASTDATERETURNED!=null) |
| 6 | =A5.group(BID) |
| 7 | =A6.new(~.BID:BonList, ~.(DVDID).id(CATEGORY).count():CatCount) |
| 8 | =A7.select(CatCount<4) |
| 9 | =A8.(BonList) | (Branch \ A7.(BonList)) |
| 10 | >file("shortage.xlsx").xlsexport@t(A9) |
A1-A3:从数据库中检索数据,分别命名为变量Branch、DVD、DVDCopy。计算结果如下:
A4:=DVDCopy.switch(DVDID,DVD:DVDID; BID,Branch:BID)
使用函数switch,将DVDCopy表中的DVDID字段切换成DVD表中对应的记录,将BID字段切换成Branch表中对应的记录。这一步是对象式关联访问的基础,计算后DVDCopy的结果如下:
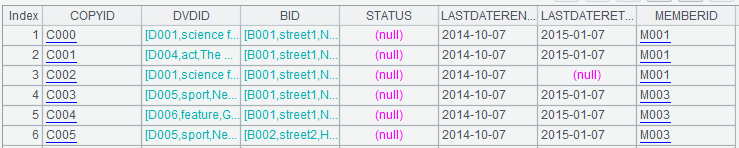
浅蓝色字体表示该字段对应为某条记录,点击后可查看,如下图:

此时,只需用操作符“.”就可以进行对象式关联访问,比如DVDCopy.(DVDID). (CATEGORY)表示每个DVD拷贝对应的DVD分类。DVDCopy.(BID)则可以取得每个DVD拷贝对应的分店详情(完整记录)。
A5:=DVDCopy.select(STATUS!="Miss" && LASTDATERETURNED!=null)
这句代码用来过滤数据,即:丢失的,未归还的DVD拷贝不在计算范围内,过滤后A5的值如下:

A6:=A5.group(BID)
上述代码用来对A5中的数据按照BID分组,每行代表一个门店的所有DVD拷贝,如下:
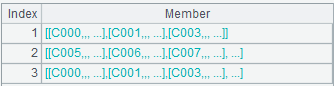
点击浅蓝色字体,可以看到组内成员:
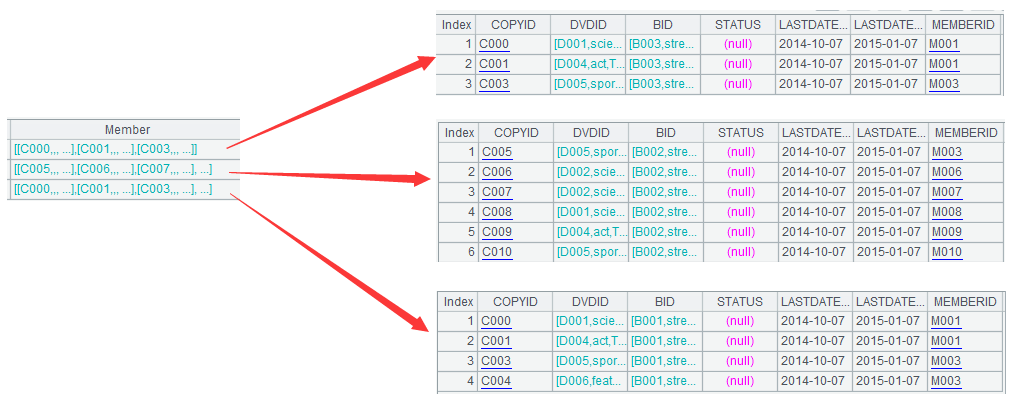
可以看到,函数group只对数据进行分组,并不会同时进行汇总计算,这一点和SQL中的分组函数不同。当我们需要对分组后的数据进行较深入加工,而不是简单汇总时,用SPL的group函数会更方便,比如A7中的代码。
A7:=A6.new(~.BID:BonList, ~.(DVDID).id(CATEGORY).count():CatCount)
上述代码用来计算每个门店对应的DVD拷贝各有几类。函数new可以根据A6中的数据生成新的对象A7,A7有两个列:BonList和CatCount,BonList直接来自A6中组内数据的BID列,CatCount来自于组内数据的DVDID列。CatCount的算法分为三部分:~.(DVDID)找到每个门店所有的DVD拷贝对应的DVD记录;id(CATEGORY)去除这些DVD记录中重复的Category;count()用来计算Category的数量。计算结果如下:
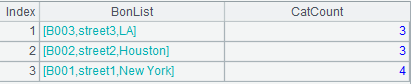
即:B002门店有3类DVD拷贝,B003门店有3类,B001门店有4类。
A8:A7.select(CatCount<4)
上述代码执行查询,求出CatCount小于4的门店,结果如下:

上述缺货的门店是根据DVDCopy表计算出的。但有些严重缺货的门店也许不会出现在DVDCopy表,比如该门店所有的DVD拷贝都借出去了,或者该门店完全没有DVD拷贝,因此要把这部分门店合并进来,代码如下:
A9:=A8.(BonList) | (Branch \ A7.(BonList))
上述代码中,运算符“|”表示将两个数据集进行并集计算(可用union函数代替),运算符“\”表示差集计算(可用函数diff代替)。A8.(BonList)、Branch、A7.(BonList)分别代表:DVDCopy表中缺货的门店、所有的门店、DVDCopy表中出现过的门店,其值分别为:

A9就是本案例最终的计算结果,其值为:
A10:>file("shortage.xlsx").xlsexport@t(A9)
最后将结果导出到excel文件shortage.xlsx,打开文件查看结果如下:
通过这个例子我们可以看到,SQL缺乏显式集合,不能用A8或Branch这样的变量来代表数据集,因此上述简短的SPL代码必须用几个冗长的SQL才能实现。
另外,SPL可被报表工具或java程序调用,调用的方法也和普通数据库相似,使用它提供的JDBC接口即可向java主程序返回ResultSet形式的计算结果,具体方法可参考相关文档。【Java如何调用SPL脚本】















 967
967











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









