






网络安全工程师是非常重要的职业,他们负责设计、实施和维护网络安全系统,以防止网络遭受攻击。
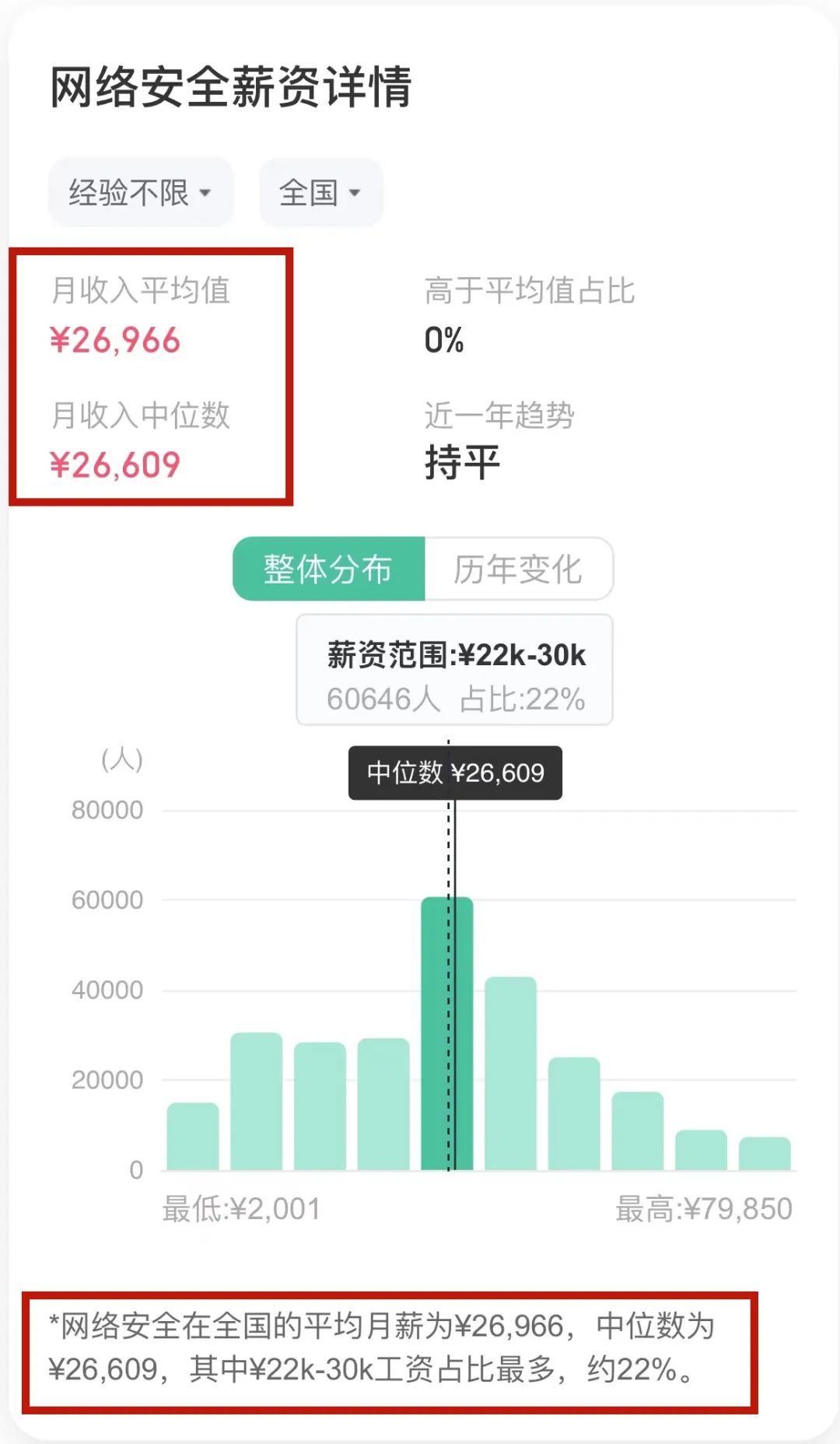
网络安全工程师月薪在2-80K左右,全国网络安全平均薪资为26.9K/月。
目前网络安全工程师就业岗位有安全服务工程师、网络安全工程师、渗透测试工程师、等保测评、攻防工程师、安全运维工程师、安全服务工程师、应急响应工程师、代码审计工程师等。
随着网络安全问题的凸显,网络安全领域也在不断扩大,因此网络安全工程师的需求量也在不断增加。现在网络安全人才缺口达到了140余万,工资也在逐渐上涨中。
↓ 收入与工作年限 ↓
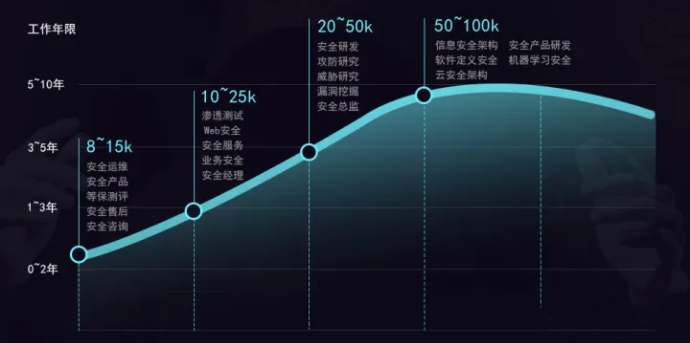
根据工作年限来看0-2年的网络安全小白收入能够达到8-15K,1-3年后工资可达15K以上。
↓ 最新招聘信息 ↓
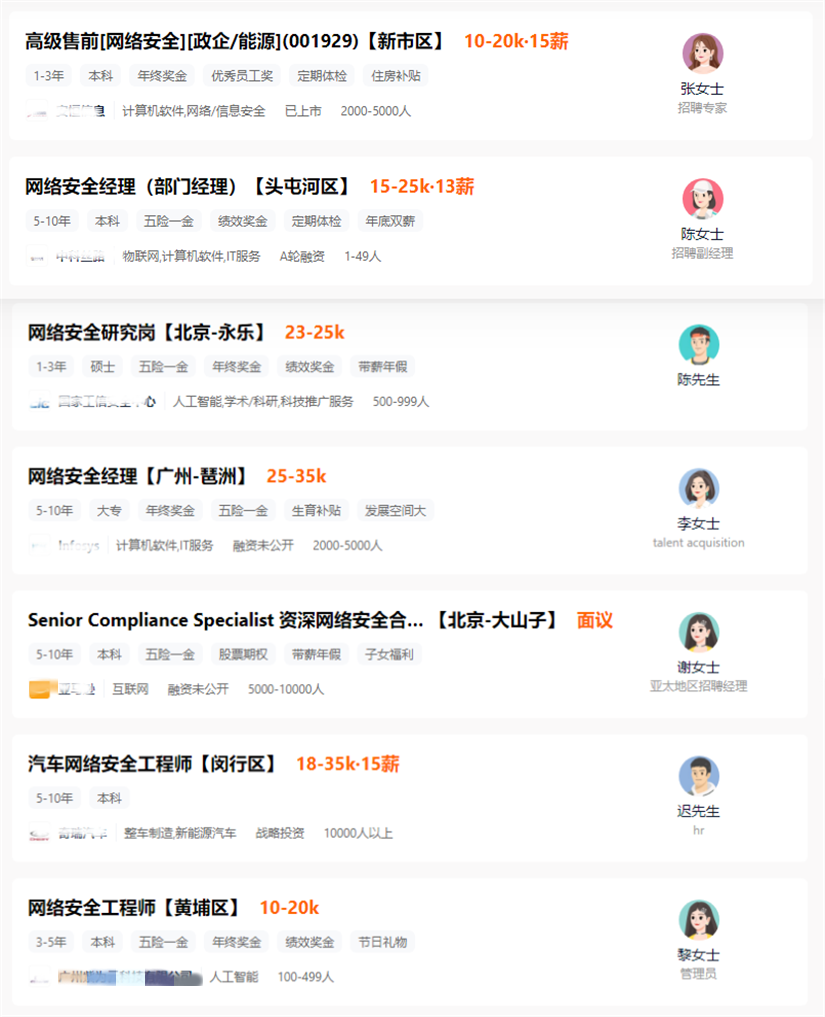
(来源:猎聘网)
各类企业对网络安区人才需求都很大,实打实的招聘信息就在这放着,学了网络安全、积累了工作经验就能拿到高薪offer,所以同学们赶紧动起来学习吧!
哪些人群适合学习网络安全?
学习网络安全并不是适合所有人,小编收集整理了以下几类适合的人员。
第一类:应届毕业生
应届毕业生已破1000万,面临巨大的就业和研究生升学问题。但是**随着5G互联网的升级,国家在号召:没有网络安全就没有国家安全。网络安全逐渐成为企业发展的重中之重。**所以应届毕业生尤其是计算机专业、软件技术专业的学生,学网络安全是很好的选择。
第二类:系统运维人员转岗
做运维一个月工资3-5K,工资不高还随时‘背锅’,职业发展很快就会遇到瓶颈期,因此有远见的运维工程师会计划学习网络安全,4-5个月的培训,薪资很快就翻一倍。

第三类:编程开发从业人员
编程开发越来越卷,有代码基础的人员转岗安全相较于其他人员学习起来还是有优势的。
第四类:渗透技术爱好者
一些对安全渗透技术感兴趣有自学经验的人,但学习思路混乱、学习效率低,希望通过系统的学习进一步提高自己技能。

总之机会永远只给有准备的人,作为一个网安人,为了财务自由继续奋斗吧。
网络安全学习资源分享:
给大家分享一份全套的网络安全学习资料,给那些想学习 网络安全的小伙伴们一点帮助!
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
因篇幅有限,仅展示部分资料,朋友们如果有需要全套《网络安全入门+进阶学习资源包》,需要点击下方链接即可前往获取
读者福利 | CSDN大礼包:《网络安全入门&进阶学习资源包》免费分享 (安全链接,放心点击)

同时每个成长路线对应的板块都有配套的视频提供:

实战训练营

面试刷题

视频配套资料&国内外网安书籍、文档
当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料

所有资料共282G,朋友们如果有需要全套《网络安全入门+进阶学习资源包》,可以扫描下方二维码或链接免费领取~
读者福利 | CSDN大礼包:《网络安全入门&进阶学习资源包》免费分享 (安全链接,放心点击)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









