







哈希表
要理解HashMap,首先得知道什么是哈希表
哈希表是用来存储数据的一种数据结构,其表现形式如下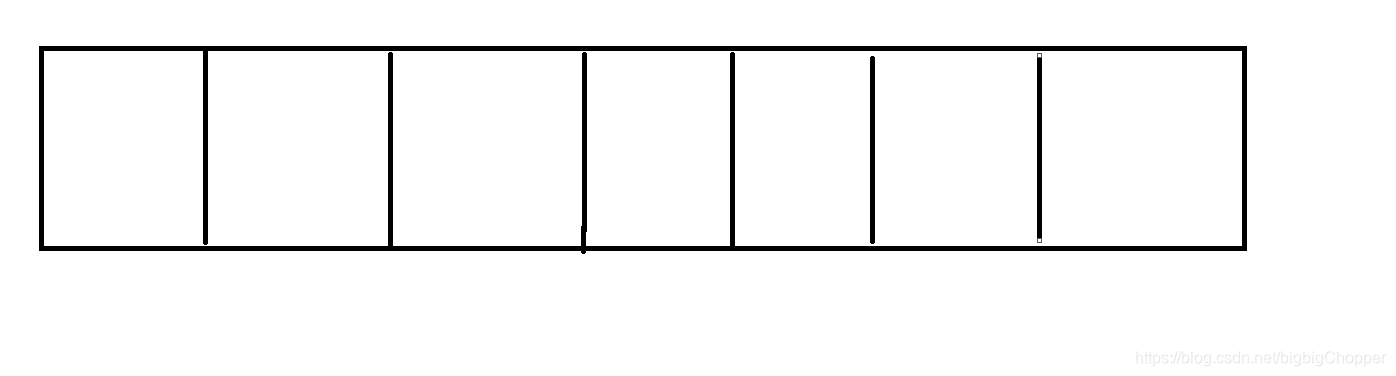
哈希表的主干是数组,如果我们需要存储某个元素,那么我们需要通过一个哈希函数确定此元素在哈希表(数组)中的位置,再将此元素存进去
也就是说哈希表的存储过程如下
x → f(hash) → 地址 → 存放
那么这就难免出现通过哈希函数f所求到的地址一样的情况,这种情况称为哈希冲突,或者哈希碰撞。
这个时候就有人提出了这样的办法,在数组的某个位置尾端加一个链表来解决哈希冲突,例如这样子: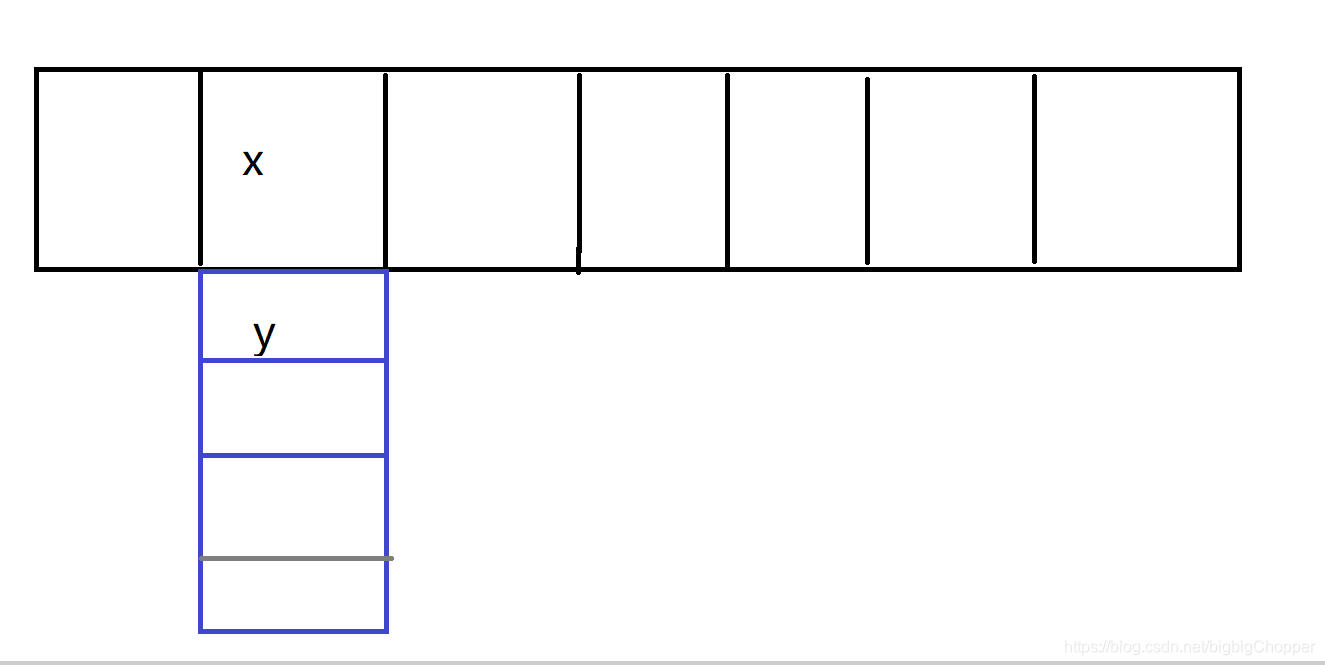
当x和y通过哈希函数f都求出了同一个地址,那么后来的y将存放在此地址下的链表中
这种方法称为链地址法,而HashMap正是运用了这种存储结构
HashMap
HashMap继承于AbstractMap类,实现了Map接口。Map是"key-value键值对"接口,AbstractMap实现了"键值对"的通用函数接口。
HashMap是通过"拉链法"实现的哈希表。它包括几个重要的成员变量:table, size, threshold, loadFactor, modCount。
table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的"key-value键值对"都是存储在Entry数组中的。
size是HashMap的大小,它是HashMap保存的键值对的数量。
threshold是HashMap的阈值,用于判断是否需要调整HashMap的容量。threshold的值=“容量*加载因子”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
loadFactor就是加载因子。
modCount是用来实现fail-fast机制的(快速失败机制,一种错误检测机制,当多个线程对集合进行结构上的改变操作时,就有可能会产生fail-fast事件)。
HashMap的实现原理
HashMap的主干是数组+链表,要注意的是它存储的是键值对,而除了键值对外还存有hash值以及指向下一个地址的指针next,它的整体结构如下:
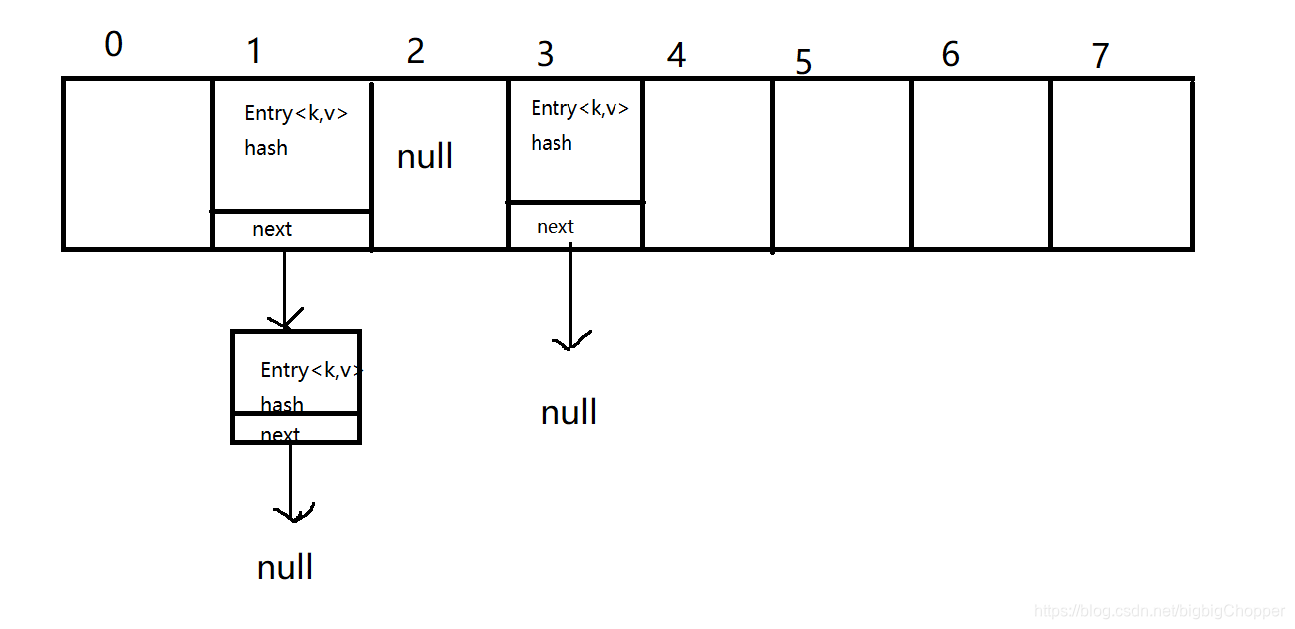
HashMap的存储过程
- x → f(hash) → 地址 → 是否冲突?
否:直接存放
是:存放到链表中
HashMap的查找过程
- x → f(hash) → 地址 → 是否为所需值?
是:找到返回结果
否:遍历链表,用key对象的equals方法判断是否为所需值
当发生哈希冲突并且size大于阈值的时候,要对哈希表进行扩容,将原大小的数组扩展为原来的2倍新数组,并且将原来Entry数组中的东西全部传输到新的数组中。
同时我们应该知道:
- HashMap的数组大小一定是2的n次幂,这样能使哈希冲突的概率更小
- 如果我们重写了equals方法,那么对应地要重写hashCode方法
- HashMap是线程不安全的
为什么HashMap的数组大小(负载因子)一定是2的 n次幂
一个哈希表为了减少哈希运算,我们可以运用取余的办法,也就是说当往一个数组大小为16的HashMap中填充数据的时候,我们利用%确定这个数据对象的位置,例如我要把11放进这个hashmap,那么我们通过11%16等于11的方法,判断到11这个数应该放在第十一个桶。
但是在计算机中,取余的计算效率是不高的,然后工程师就想到了按位与&的方法,怎样才能利用&达到和取余相同的功能呢?这就是这个问题的关键。我们可以发现,只要实现按位与的另一个数二进制全为1就能够实现相同的功能。例如,11的二进制01011,与01111按位与的话,得到的是01011,还是11,效果一样。
那么为什么是2的n次幂?我们可以想想2的n次幂用二进制都是怎样表示的。 2 4 2^{4} 24=16的二进制是10000, 2 3 2^{3} 23=8的二进制是1000,发现了吗,2的几次方就是1后面跟多少个0,顺着这个思路想,只要 2 n 2^{n} 2n-1就是0111…1111的形式,是不是就可以实现这个功能了呢?
所以只要实现了length为 2 n 2^{n} 2n,那么hash%length==hash&(length-1)就能够成立了














 3670
3670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









