







轻量化网络整理
基本的知识储备
CNN(卷积神经网络)的参数,计算量,FLOPs,Multi-Add概念详解:
Multi-Add: 卷积神经网络的卷积过程包含两个操作 乘法操作和加法操作
CNN参数:
卷积的参数即在一个卷积窗口内的计算个数也可以理解为一个卷积结果元素产生的运算操作。以331的输入被33卷积核卷积,参数有331个乘法操作和33-1个加法操作一共有331+33-1=17个参数。
拓展到CNN参数:
(KhKwCi + KhKwCi - 1) Co = (2KhKwCi - 1) Co (没有偏置bias的情况)
其中 Kh:卷积核高 Kw:卷积核宽 Ci:卷积核通道数 Co:输出通道数(卷积核的个数)
有偏置项:
(KhKwCi + KhKwCI - 1)* Co + Co = 2KhKw*Co
**CNN的计算量:**对所有输出特征图的所有元素的求和
CNN参数 * Ho * Wo
FLOPS: 注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
FLOPs: 注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
这里FLOPs就等于CNN的计算量。
常规卷积的参数量:
假设卷积核尺寸 :Dk × Dk × M × N
Dk 是空间尺寸,M是输入通道,N输出通道,DF 输出特征图尺寸
该卷积过程计算量:
Dk × Dk × M × N × DF × DF
一、人工结构轻量化设计
1.1 mobileNet V1,V2结构
1.1.1 V1:Depthwise Separable Convolution
论文:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
将传统卷积过程分两步实现:深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)。
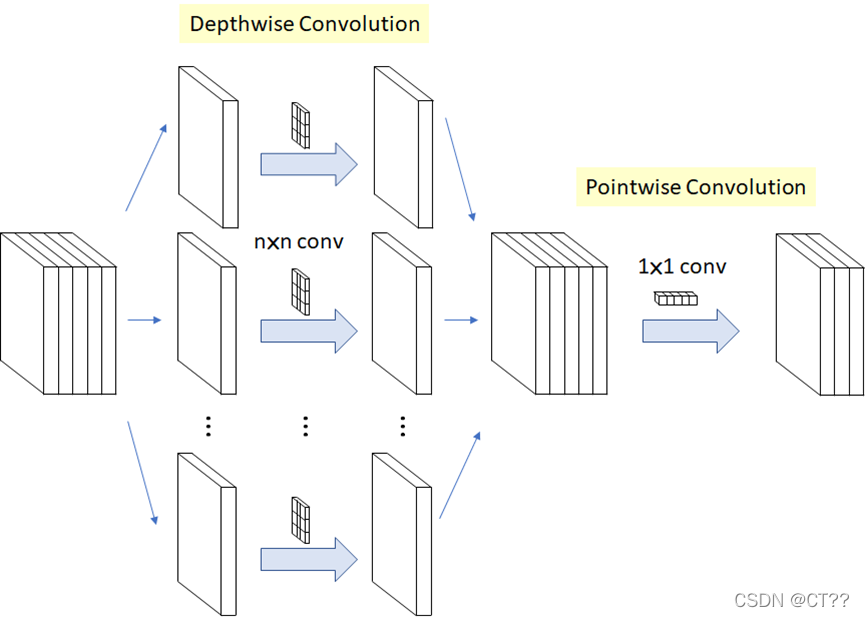
深度可分离卷积的计算量 = 分离卷积 + 逐点卷积 = Dk × Dk × M × DF × DF + M × N × DF × DF
1.1.2 V2:1、 linear Bottlennecks
论文:MobileNetV2: Inverted Residuals and Linear Bottlenecks
linear Bottlennecks: 在深度可分离卷积前后增加卷积机构,在前端增加PW层,将输出PW曾后的ReLU层更改为线性层。前端增加PW层的目的是为了提升通道数,因为DW卷积本身没有改变通道数的能力,在输入通道数少的情况下,DW也只能对少的通道进行操作,这样回限制后面抽取特征的能力。
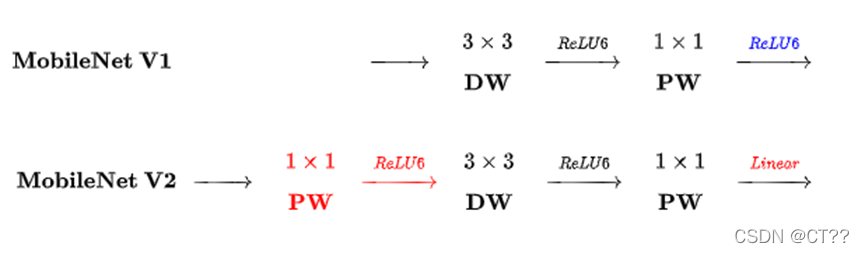
Inverted residual block是输入通道数很少,11卷积数据扩张,再经过33DW卷积进行特征抽取,最后1*1卷积数据升维,整个过程:输入特征 -> 扩张 -> 提取特征 -> 压缩 。

1.2 shuffleNet结构
1.2.1 V1:逐点分组卷积(point group convolution)和通道洗牌机制(channel shuffle)
论文:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
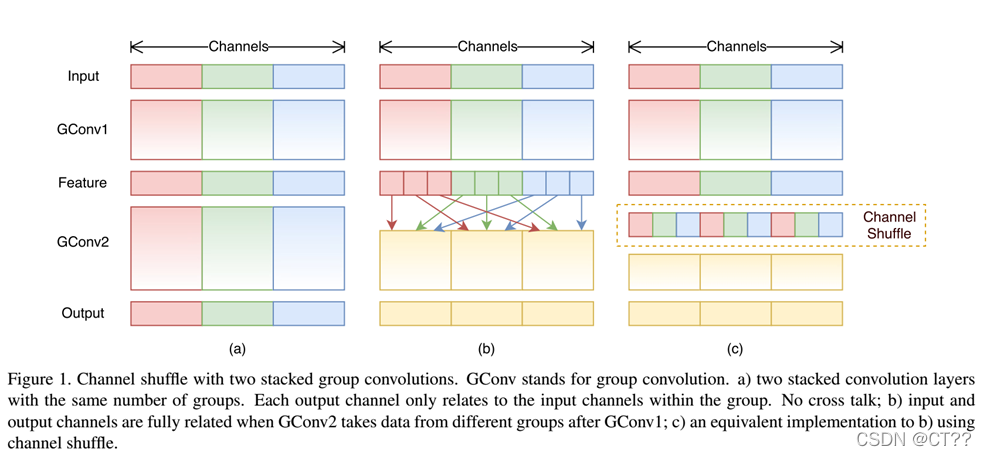
分组卷积从通道层面减少计算量,但是切断组件的特征联系。通道洗牌机制将不同分组之间的卷积结果进行交换,缓解了该问题。
1.2.2 V2:停止使用分组卷积,使用Channel split
论文:ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
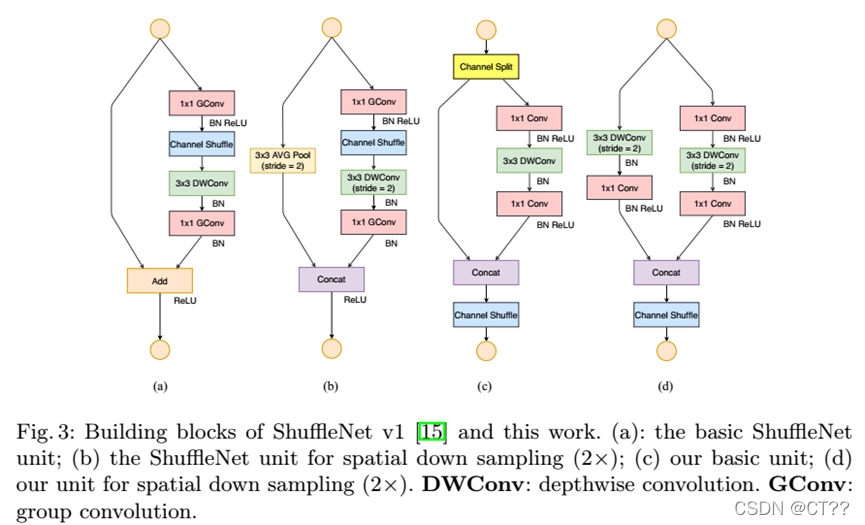
V2进行的结构更改,遵循实验得出的四个网络轻量化经验:
1)use "balanced\ convolutions (equal channel width);
平衡通道数
2)be aware of the cost of using group convolution;
分组卷积成本
3)reduce the degree of fragmentation;
减少琐碎化程度
4)reduce element-wiseoperations.
减少逐个元素操作
因此,V2只进行了一次分组,中间过程使用了MobileV2中的线性瓶颈结构。
以该网络为主干网络,对二阶段目标检测程序进行轻量化。2019 ThunderNet: Towards Real-time Generic Object Detection。 在ARM上实现了实时检测
二、网络学习结构轻量化设计
因为博主的研究方向对强化学习涉猎不多,对具体实现步骤不了解,因此只对最近碰到的论文中的想法进行科普式展开。
2.1 MnasNet
论文:MnasNet: Platform-Aware Neural Architecture Search for Mobile
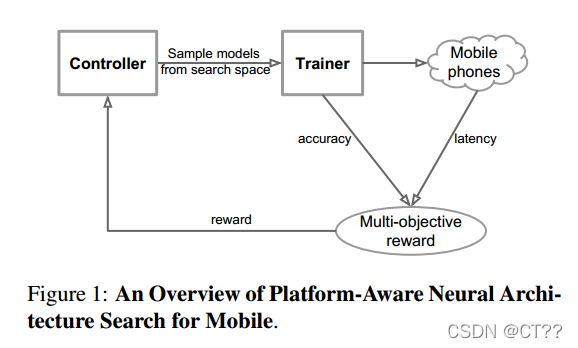
轻量化整体思路,controller生成网络模型,训练器训练提升准确度,在移动平台测试延时,最后返回得分。
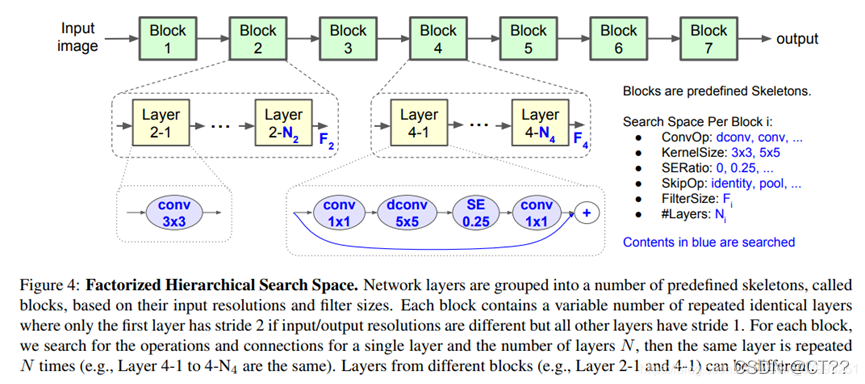
图中显示了搜索空间的基线结构。我们将CNN模型划分为一系列预定义的块,逐渐降低输入分辨率,并像许多CNN模型一样增加过滤器大小。每个块都有一组相同的层,它们的操作和连接由每个块子搜索空间决定。具体来说,块i的子搜索空间由以下选项组成
•卷积运算ConvOp:常规conv (conv)、深度conv (dconv)、移动倒瓶颈conv。
卷积内核大小:3x3, 5x5。
•挤压-激励比SERatio: 0,0.25。
•跳过ops (SkipOp):池,身份剩余,或没有跳过。
•输出滤波器尺寸Fi。
•每个块Ni的层数。
文中我们使用MobileNetV2作为参考对所有搜索选项进行离散化。
但是该方法在ImageNet训练集训练时,Controller生成8000个模型,最有只有15个模型跑完ImageNet训练。
2.2 NetAdapt
论文:NetAdapt: Platform-Aware Neural Network Adaptation for Mobile Applications
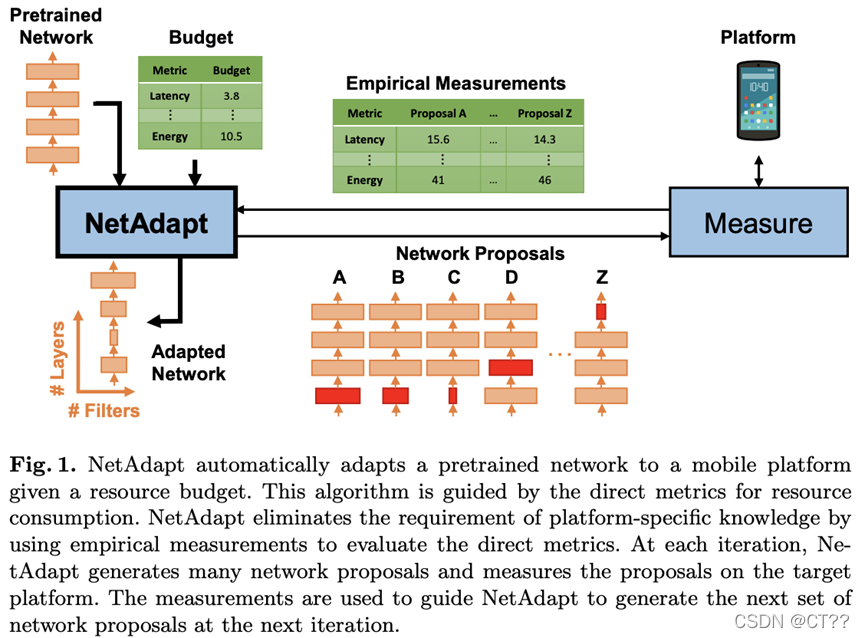
1)step1:按照给定的资源约束选择当前层需要剪掉的filter数量,文章中是基于在实验平台上实验得到的结果进行选择剪裁的数量,在对应的filter被剪裁掉之后与之对应后续层的channel数也应做相应的修改;
2)step2:在确定好需要剪裁掉的filter数量之后就需要确定那些不重要的filter需要被剪裁掉。对此,文章使用的重要性选择方式是使用上一轮迭代产生的梯度信息,将其L2-norm,之后按照其值选择最不重要的几个,将这些filter裁掉。除了这种基于梯度的方法还可以使用基于特征图间相互作用的方法,例如使用Lasso回归。
3)step3:对当前裁剪的层进行short-term的finetune使其恢复精度。在所有的层完成裁剪之后选择其满足资源需求且finetune之后网络性能最好的一个;
4)step4:判断当前迭代论述的模型是否满足算法预先设计的资源需求限制,若满足则对模型进行long-term的finetune得到最后的结果;
2.3 MobileNetV3
论文:Searching for MobileNetV3
V3:在MobileNet V2的基础上,使用MnasNet进行全局的网络结构优化。然后,使用NetAdapt优化每层的滤波器个数。
三、减少特征层的冗余
论文:GhostNet: More Features from Cheap Operations
GhostNet:针对特征层冗余问题
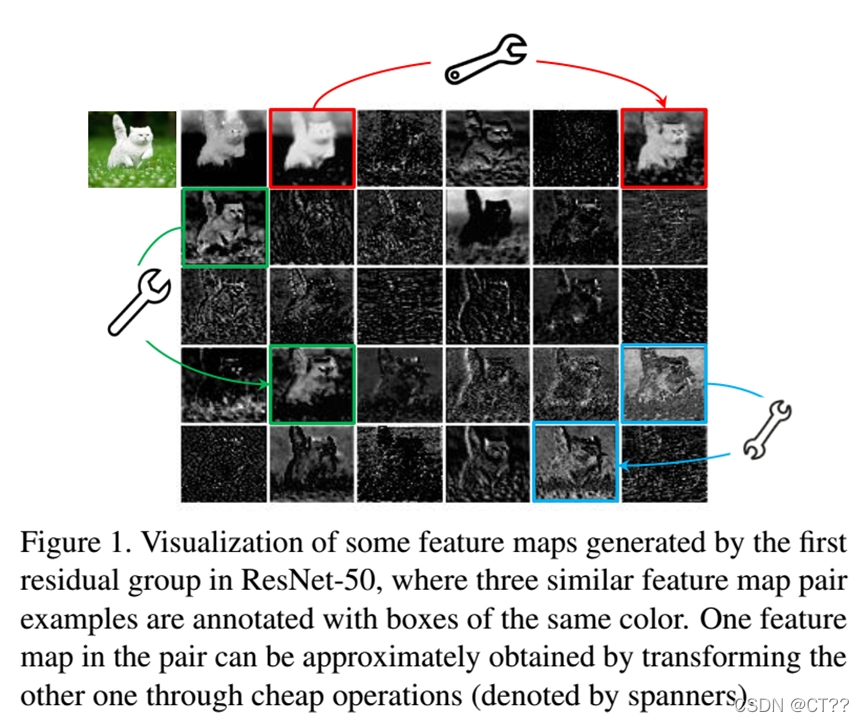
所谓冗余指特征图中有很多相似的特征图,因此引出思路,可否用一小部分特征图通过线性变换去生成特征图。论文中的线性操作是采用的卷积。
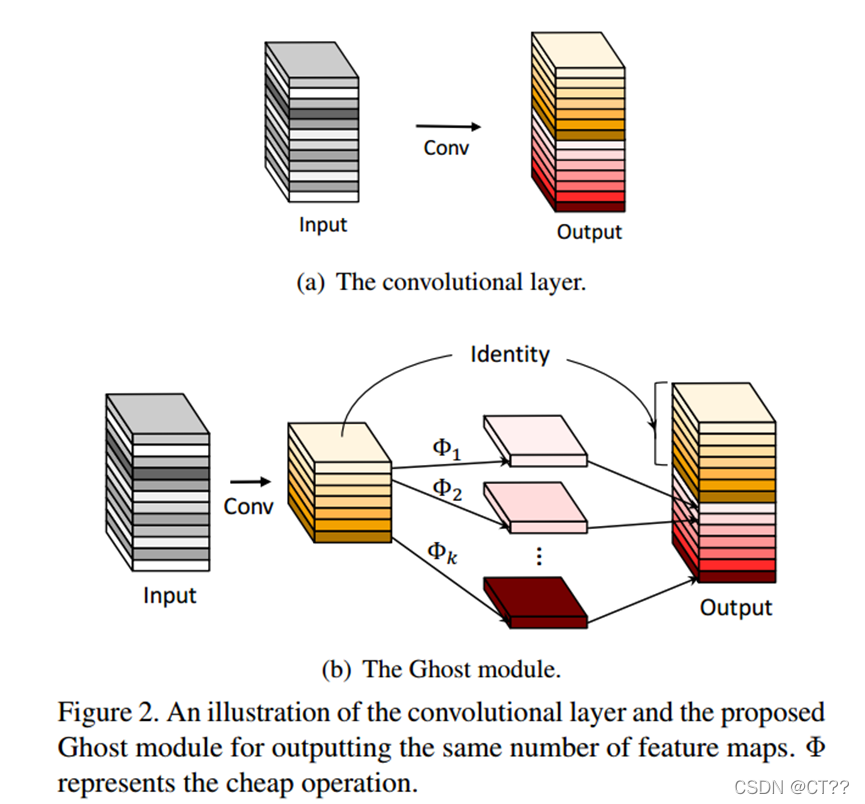
该方法的计算量:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









