






BFS
首先我们先来看一张图

如果我们用dfs,便是先序遍历:S L M N F F O P F Q F
而我们用bfs,则是一层层遍历: S L O M F P Q N F F F
我们想,如果结果是O的话,那么dfs则需要先遍历完所有的左子树,才可以找到结果,当数据较大时,dfs就会超时,所以我们采用bfs(广度优先搜索算)!!
**我们先来了解一下bfs一般来做那一类题目
-
用深度优先搜索找最优解时必须搜索完所有路径,即使一个目标结点在很浅的树枝上,也得等到它左边所有结点均被搜索后才能找到它。用这种方法求某些最优解时,效率比较低。而广度优先搜索,能较好地解决这个问题。
-
广度优先搜索是最简便和常用的图形搜索算法之一,从对图形的遍历来看,遵循“从浅入深”的搜索策略。在这种搜索过程中,树上的结点扩展是沿着深度的“断层”进行的,所以这种方法一定能保证找到最短(步数最少)的解答序列。在不少题中要求找到经历步骤最少而达到目标的方案时,多采用此种搜索方法
**最优化问题!!
**“广搜”所用的数据结构-队列:
为了体现先生成先扩展的执行方式又能保留所有生成的结点以待进一步扩展,广度优先搜索在数据结构上引用了“队列”结构。队列是一种线性表,具有先进先出的特点,对于它所有的插入和删除操作分别仅在队列尾和队列首进行。定义两个“指针”变量head和tail,分别用来指向队列的头和尾。初始结点先入队,头指针指向待扩展结点,每生成一个子结点,则尾指针tail增加1,当前结点的所有子结点均生成后,头指针向后移动(即加1),位于head指针之前的(已被删除)为已扩展结点,tail指向所有已生成结点的最后一个。若head指针大于tail指针,表示所有解答树上的结点已产生。如果目标结点仍求出现,说明“无解”。
**
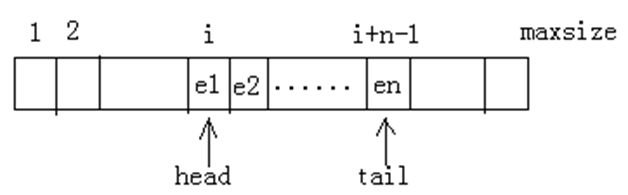
原理解释:

下标 1 2 3 4 5 6 7 8 9 10 11
father 0 1 1 2 2 3 3 4 5 6 7 8
state S L O M F P Q N F F F
模板:
广度优先搜索的算法描述:
其中,max为产生子结点的规则数:
program BFS
初始化,初始状态存入OPEN表;
队列首指针head=0;尾指针tail=1;
do {
指针head后移一位,指向待扩展结点(head++);
for I = 1 to max
if 子结点符合条件
tail指针增1,把新结点存入队列尾;
if 新结点与原已产生的结点重复 then 删去该结点(取消入队,tail减1)else
if 新结点是目标结点 then 输出并退出;
} while (head>=tail);

















 178
178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









