






榜单系统的定位和业务价值
榜单遍布B站直播相关业务的各个角落,直播打赏、直播间互动、付费玩法、互动玩法、活动、主播PK、语聊房、人气主播排名、高价值用户排名、增值集卡、up主充电等等,在这众多的业务场景中,我们能看到各种各样的榜单。
榜单的存在,可以激发主播提升表演水平、提高表演质量的积极性,从而吸引更多的观众。观众也可以通过榜单展现的排名,了解其他人对主播的互动打赏情况,激励他更加积极地参与互动或打赏,从而获得认同感和存在感。通过榜单,主播又能获得更高的收益和更多的曝光流量。总之,榜单是一道连接平台、主播、观众的重要桥梁,对提升整个直播的良好氛围有着极大的作用。另外,用户上榜的规则是多样化的,确保消费打赏行为不会过度商业化,在引导观众理性消费和平台健康发展方面也起着积极的作用。
业务概览
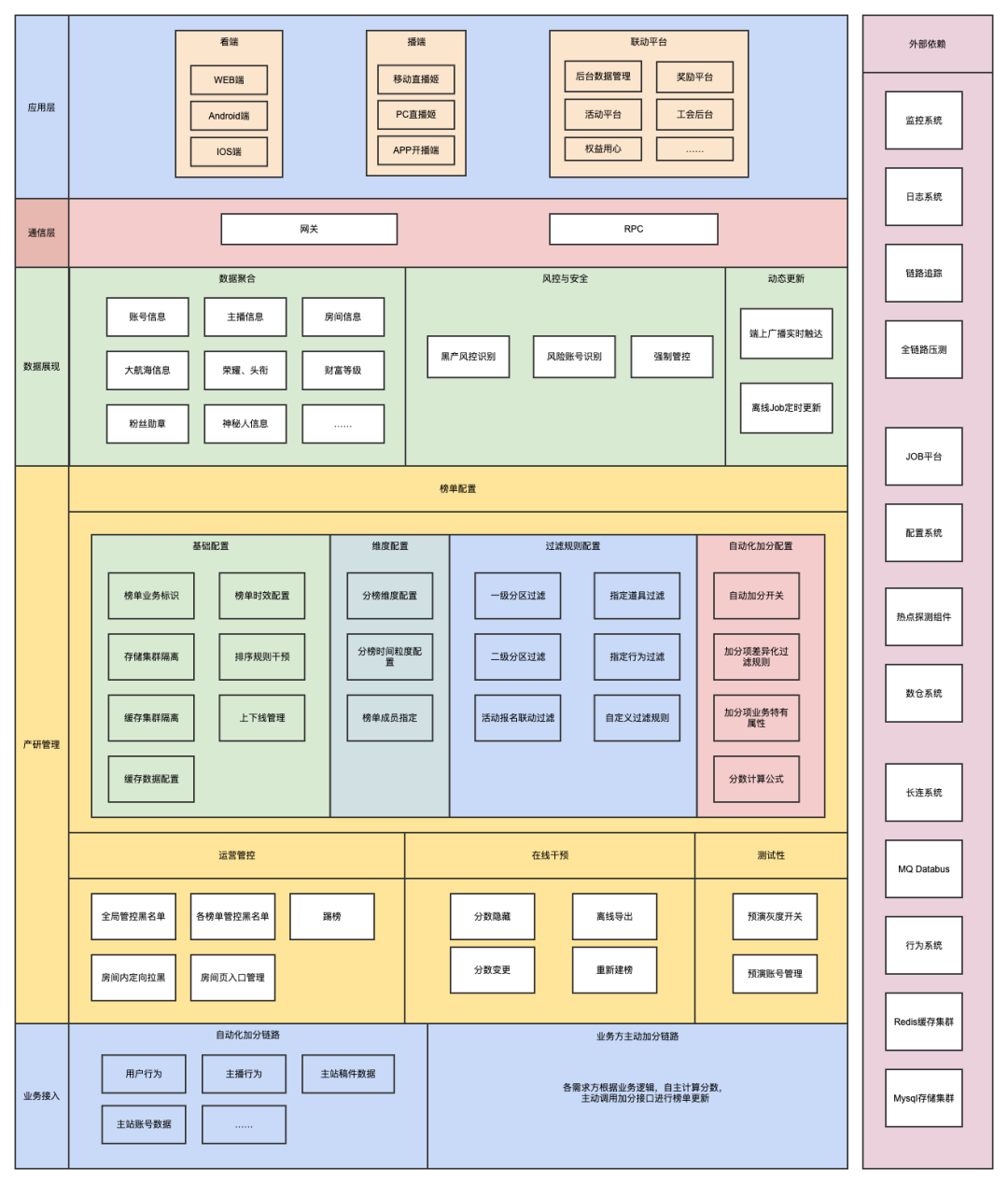
下面是榜单系统的产品业务架构图,虽然忽略了很多细节,但从此图可以对B站直播榜单系统的全貌有个初步的认识。
系统介绍
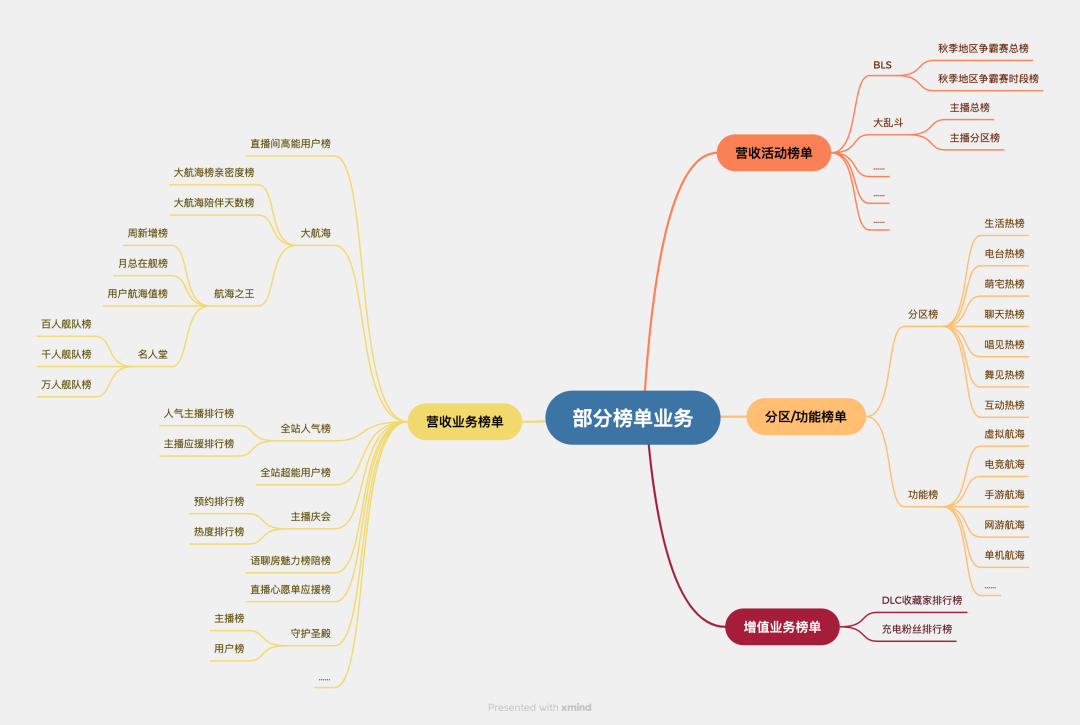
在文章开头已经介绍到了直播业务中榜单的种类是非常多的。
从榜单成员角色看,有主播榜、用户榜、道具榜、房间榜、厅榜、公会榜;
从竞争排名的范围看,有全站榜、分区榜、活动赛季榜、直播场次榜;
从结榜时间粒度看,可以分为长期榜、季度榜、月榜、周榜、日榜、小时榜;
从具体场景上看,一些业务还会对榜单进行“赛道”划分,如地区榜、男生女生榜,“赛道”的含义由业务方自定义、自理解。
由此可见,榜单系统所承载的业务不仅仅是场景多,而且接入形态各异。所以从接入易用性和开发效率上讲,对榜单系统的通用性和灵活性有着较高的要求。接来下我们就从榜单配置化、业务接入、面临的挑战等几个方面介绍一下榜单系统。
榜单配置
经过这么长时间的发展,榜单几乎成了每次业务迭代的伴生需求。很多时候每上线一个新的业务需求,就会同时上线一个甚至多个新的榜单,榜单系统因此就成了日常业务需求迭代的“基础组件”。
那我们如何快速配置上线一个新榜单呢?做法就是打开管理后台,配一配。
基础配置
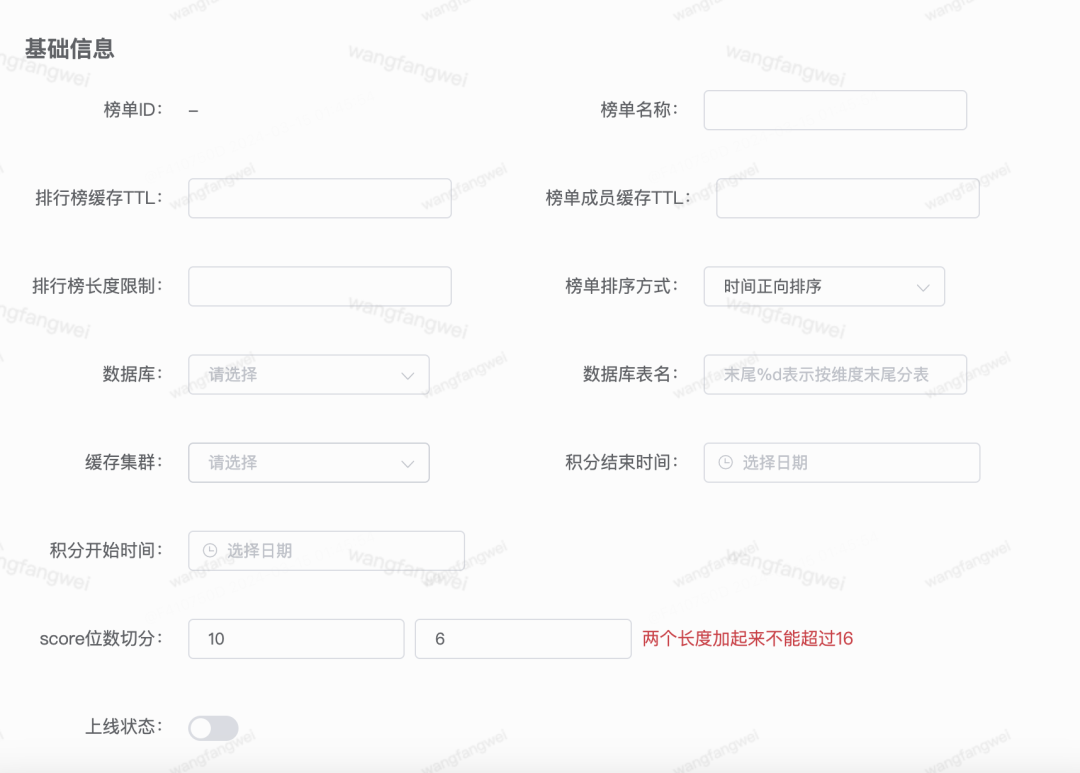
榜单ID会在新榜单配置时由系统自动生成,生成后不再改变。后续通过接口进行榜单数据的读取、更新时,都需要指定榜单ID。榜单ID是榜单系统中的“硬通货”。
榜单名称就是业务标识,方便辨识。
榜单系统使用Mysql作为持久化存储,并使用redis kv作为榜单成员分数的缓存,而排行榜功能的实现则是依赖Redis zset的能力。排行榜的缓存TTL、榜单成员分数的缓存TTL根据需求设定,要兼顾考虑业务流量压力和缓存集群的内存压力。排行榜长度限制也是必须设置的,也就是要限制zset的长度,在满足产品需求的同时要避免在Redis存储节点中产生大key,了解redis核心线程模型和事件模型的人应该都知道Redis中出现大key的危害。
研发侧还可以根据实际业务情况来指定要使用的Mysql集群和Redis集群分别是哪一套,从而做出合理的存储、流量隔离。毕竟有的榜单业务的读写QPS可能都不过百,而有的业务单榜单的日常读取QPS可以超过10万。不同业务之间的榜单数据量级也是有很大差别的,有的业务榜单数据量比较大,但生命周期不长,可以为其分配单独的存储,制定不同的定期清理归档策略。
积分开始时间、积分结束时间应该不需要多解释了,其实就是榜单在线上的有效时间范围,多用在自动化加分且为定时上线的榜单中。
score位数切分配置与上方的榜单排序方式是有关联的。在实际需求中,会有诸如“分数相同时先获得此分数的排在前面”、“分数相同时粉丝勋章等级高的排在前面”等要求的排序策略。我们知道,Redis zset使用双精度浮点数( a double 64-bit floating point number)来表示成员的排序权重分值,而double类型的最大有效位数为16位。所以我们可以指定n位整数部分表示真实的业务分数,(16-n)位小数部分辅助二级排序。在某一时刻(记时间戳为ts)调用通用接口进行分数更新时,根据配置计算最终分值的方式有三种:
-
按时间正序排序。取入参score作为整数部分,取(999999999-ts)且按位数截断的结果作为小数部分。
-
按时间倒序排序。取入参score作为整数部分,取ts且按位数截断的结果作为小数部分。
-
自定义排序。取入参score作为整数部分,取入参subscore作为小数部分,即整数部分、小数部分都由业务计算。
最后再将整数部分和小数部分进行字面拼接作为zset成员分值。如果有榜单成员的最终分值还是相同时,就遵循zset的内部实现,按照榜单成员key的二进制字典序进行排列了。
榜单维度配置
在榜单上线之前,还需要配置榜单的加分维度、分榜的时间粒度等。

通用维度配置中的维度项,是基于直播业务中的常用维度进行预设,勾选了加分维度就意味着此榜单会横向进行分榜。可以举例说明:
-
若不勾选任何选项,则没有横向分榜的需求,即全站一张榜。比如主播人气榜,是全站所有的主播的人气排名,只需要一个榜单实例。
-
若勾选了主播,则表示针对每个主播会有一个榜单的实例。比如主播人气应援榜,是给某一特定主播助力人气值的所有用户的排名。
-
若勾选了主播、场次ID两个选项,则表示针对每个主播的每一个直播场次会有一个榜单的实例,比如主播进行的每次一次直播的打赏榜单,就可以这么实现。
-
拓展维度,是当预设的维度不能够满足逻辑需求时,留给业务方自定义加分维度时使用的,业务方自理解。进行榜单更新、榜单读取时,业务方自己使用统一的算法算出维度值。
若配置了时间维度,每个榜单实例会根据配置的时间粒度再进行纵向分榜,时间范围为自然时间,标识就是自然时间段的起始时间。比如选择了自然天,则每天的0点时会自动切换到新的一天的榜单。实现方式也不复杂,就是根据每次加分行为的时间戳,算出当前时刻归属于哪个自然时间段,就会知道往哪个分榜上加分。榜单的读取亦然,根据请求中指定的时间戳也能算出应该读取哪一个分榜。
可以想到,每次针对榜单系统的写入、读取,都会有一个根据时间戳进行格式化计算时间的操作,而时间的格式化计算又比较耗费性能。所以这里有个优化点,我们可以将自然时间的起止时间戳和它对应的格式化结果进行缓存,不必每次都进行一次计算,只有当时间超出了缓存的有效范围时才进行重新计算,在一些开源的高性能日志库中也有类似的做法。
自动化加分配置
顾名思义,自动化加分就是当有特定的事件发生时,配置了此自动化加分的榜单都会被触发更新。

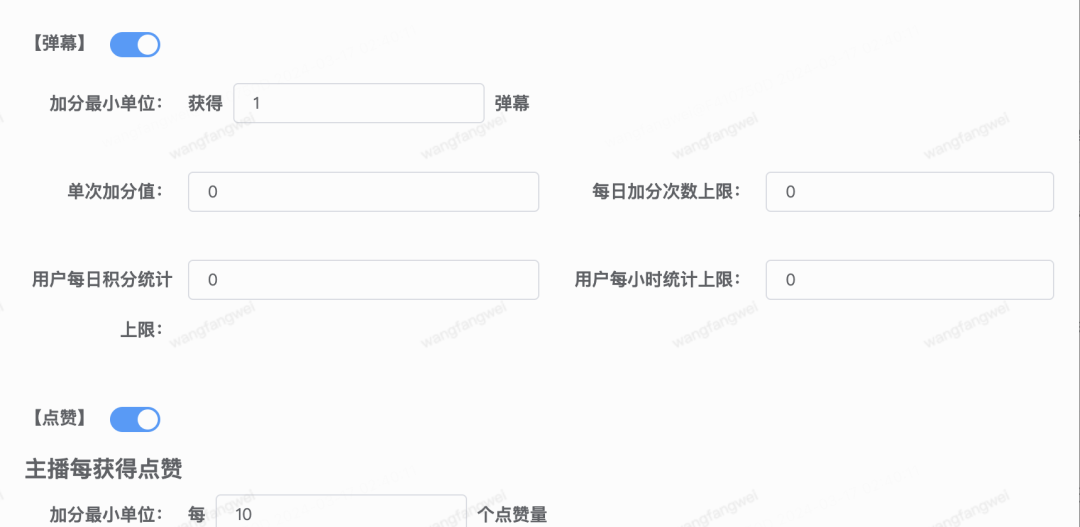
自动化加分的由来
直播相关的业务代码中,大量使用了MQ订阅上游业务消息,若每一次业务接入都要单独注册一遍消费者、实现一遍消费逻辑代码,会做大量的相似性工作。所以为了提升开发效率,降低各个业务方接入MQ的成本,部门内实现了一个行为系统,所有的上游消息都由行为系统统一订阅消费,然后调用下游各业务方的RPC接口进行行为事件投递。当然这里引入了另一个不可忽视的问题,但在本文不作重点讨论。
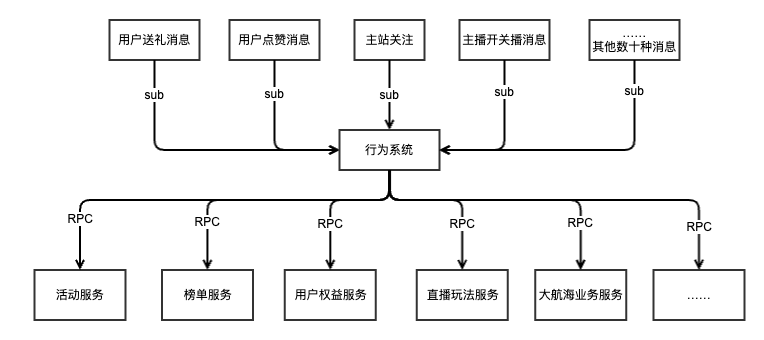
榜单服务作为行为系统的下游,当有行为事件发生时,榜单RPC接口被调用,行为事件会扇出到所有打开了对应开关的榜单上。这样业务方只需要在管理后台配置一个榜单,就可以在需要的地方直接展示榜单了,还是非常方便的。
当然,不是所有的业务都适合自动化加分的链路,它们需要在自己的业务层逻辑中计算好分数,再主动调用榜单系统的通用接口进行榜单更新。
具体的加分流程的逻辑后文再介绍。
过滤规则配置
在榜单系统的数据处理流程中,集成了通用化的过滤配置模块,具体配置页面见下图。
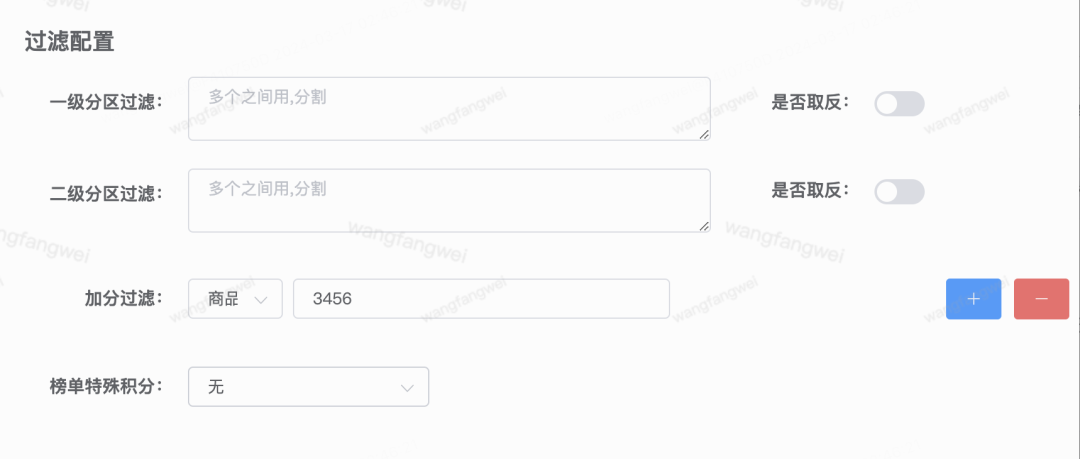
过滤规则是随着业务发展扩展出来的,适用面相对窄一点。一级、二级分区过滤表示只有当行为事件发生在特定的直播分区才会进行加分,否则不加分。取反则是反向过滤。
若行为事件是用户购买礼物消息,还可以指定只有特定的商品才给此榜单加分,在一些活动中常用。
特殊榜单加分则是为特殊的业务逻辑hook,可以理解为在通用化链路中为特殊业务放置了一个回调的钩子,也是在活动中常用。也可以理解为在通用化链路中耦合了一些业务逻辑,现在已经不推荐常规业务使用了。
数据存储
结合基础设施情况及自身的业务特点,在数据存储选型上,榜单系统了分别选择了mysql和redis作为持久化存储系统和缓存系统。特别地,也依赖了redis的zset提供的能力来实现排行榜列表。榜单系统在存储结构设计上,是和榜单加分维度配置的设计紧密关联、相互对应的。
MYSQL存储
通用榜单系统的mysql存储表的结构也是统一的,最主要的一些字段如下:
CREATE TABLE `some_rank` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
`rank_id` int(11) NOT NULL DEFAULT '0' COMMENT '榜单ID',
`type_id` varchar(100) NOT NULL DEFAULT '' COMMENT '子榜标识',
`item_id` bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT '榜单成员标识',
`score` bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT '榜单成员积分',
// ......
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='xxx榜单数据表'对于id、rank_id、score、rank、score这些字段,从名字及注释可以非常容易的理解其含义,就没必要多做解释了。我们把重点放在type_id、item_id这两个字段上。
type_id字段类型是verchar,其值的计算是和榜单“维度项”配置是对应的。代码实现中封装了固定逻辑,根据勾选的加分维度的字段name的字典序进行拼装组合,得出type_id字段的值。榜单的加分维度固定后,算法结果也是相对稳定的。
比如某个业务榜单的加分维度配置如下:

那么在计算type_id时,就按照“${锚定的子榜起始时间点}_${主播uid}_${其他}”的字符串形式进行拼接。锚定的子榜起始时间点会根据加分或查询请求中的timestamp进行计算。
举例,某次加分Request请求体及字段注释如下:
{
"rank_id": 12345, //榜单ID
"item_id": 110000653, //榜单列表的一个成员ID,此请求传入的为用户的UID
"score": 1980, //本次请求所增加的分数值
"dimensions": { //加分维度必要的参数
"ruid": 110000260, //主播的UID,也就是加分通用维度中“主播”选项对应的参数及value
"timestamp": 1713165315, //加分行为的时间戳,用于锚定按时间切分的子榜
// 其他可能需要的维度参数
}
// 其他必传参数,如必要的幂等key、业务标识等等
}此加分行为携带的时间戳是1713165315,即2024-04-15 15:15:15,而时间维度配置为1个自然月,那么本次加分行为归属的自然月的起始时间就是2024-04-01 00:00:00,时间戳即1711900800,所以本次加分请求所计算的type_id就是“1711900800_110000260”,item_id字段所传的值即用户的uid。
那么,本次加分行为可以解读为:用户(uid:110000653)在主播(uid:110000260)本月的榜单上贡献了1980分,对应的数据行(主要字段)就如下所示。

rank_id、type_id、item_id就是数据行的一个主键。
同理,假使此榜单配置的时间维度为1自然日,那么本次加分行为归属自然日的起始时间就是2024-04-15 00:00:00,时间戳即1713110400,那么本次加分请求所计算的type_id就是“1713110400_110000260”。
由此我们也可以看出,每一个单独的加分请求都要求传递一个行为发生的业务方时间戳,送礼加分行为携带的就是用户送礼时的实时时间戳,弹幕加分行为携带的就是用户发弹幕时的实时时间戳。这样,即使出现了偶发的网络抖动、MQ消息延迟等异常情况,也不会出现“昨天的送礼却给今天的子榜加了分”的事情发生,哪怕出现了消费游标重置、MQ rebalance等,当然这也需要幂等保证不会重复加分。
Redis缓存
Redis缓存榜单列表时,zset的key也由rank_id、type_id参与构成,这样加分、查询也都会根据时间戳锚定到正确的key。这里不再赘述。
榜单更新
介绍完了如何快速配置上线一个榜单,那么榜单配置完成之后,业务代码又是如何对榜单进行更新的。下面提供一张榜单加分的流程图作为说明。
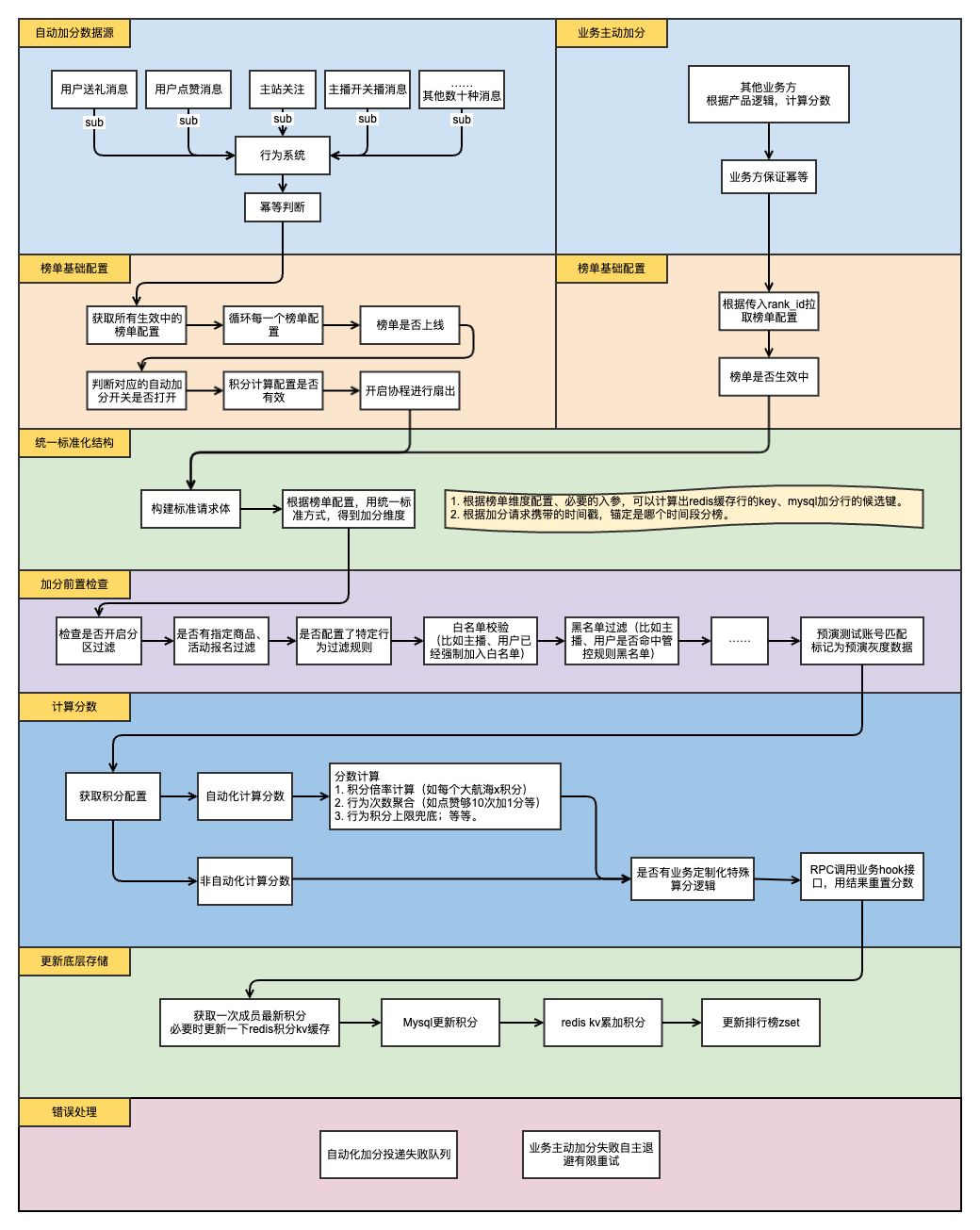
流程图展示了加分的大概步骤和简要的说明,这里再就几个关键的点需要注意。
自动化加分时,如果有多个榜单都打开了对应的自动化加分开关,那么一次行为触发对多个榜单进行更新。如果出现某个榜单更新失败,内部会自动针对这个榜单进行重试。
如果上游MQ重置了游标或触发rebalance,消息不会因为被重复消费而导致重复加分。
有一些榜单对用户的感知实时性要求较高,业务代码中会根据需要,依赖长连系统的能力将最新的榜单数据广播到端上,这样用户在不重新进房或者不主动刷新榜单的情况下也能看到最新的榜单数据。
业务挑战
本文开头就提到了榜单系统应用场景的广泛,也就意味着榜单系统的读写流量是非常高的。对一些榜单,观众能及时看到上榜或排名的变化是很有必要的,特别是消费打赏行为。榜单在平台运营中也扮演着重要的角色,比如对主播、用户的激励发放、活动结果的奖励结算,有不少是依赖其在榜单上的排名作为依据。
因此榜单数据的准确性、系统的健壮性、接口的高效性也是重要的健康指标。
写入性能
就目前来讲,榜单写入出现的性能瓶颈,多是来自自动化加分链路中用户互动行为事件,比如持续观播、点赞、发弹幕,这类行为一般是持续、海量的,且相对于用户的消费打赏行为来说对体验不敏感。
还有第二种情况就是当有大型赛事或活动时,就会出现单点热门直播间,大量的写入会造成存储分片(redis、mysql)的吞吐压力,可能会出现写入超时导致数据积压或者最终丢失,部分场景可能会出现重试雪崩。
针对第一种情况,榜单系统引入了一层”慢队列“。将互动行为事件的加分请求进行预处理后,不直接更新至存储,而是投递到慢队列中。慢队列MQ接入公司的异步事件处理平台,利用平台聚合能力,将相同写入维度的数据聚合之后再写入存储,大大降低存储压力。

* 图片来自异步事件处理平台说明文档
对于第二种情况,我们多是采用降级策略,这类直播间很多时候并不需要展示不必要的榜单,可以针对整个榜单进行降级,不写入不展示即可。也可以针对某些事件行为进行降级,比如当命中赛事直播间时,互动行为将降级为不加分。
读取性能
榜单的读取流量基本都打到redis集群,通过redis集群是可以扛住日常压力的。较多出现读取性能瓶颈的依然是一些热门直播间,日常大v直播、大型赛事直播、大型晚会或活动直播等,这种情况下往往是对redis集群中的单个node压力过大。对于高热直播间,我们通过增加二级内存缓存的方式进行了解决。
-
接入CDN热门房间SDK。这是公司内的一个公共组件,通过这个组件提供的配置化能力,我们可以知道当前直播间是否判定为热门直播间。如果达到了热门直播间的阈值,系统会在内存中将榜单进行缓存,降低对redis集群中单个存储node压力。
-
开发了热点探测组件。通过对榜单zset的访问情况进行记录,将热点zset key进行内存级缓存。
-
配置化强制热门房间。必要时手工指定某些直播间为热门直播间,强制进行内存缓存。
加入二级缓存肯定会带来一定实时性的牺牲,但都会在业务可接受的范围内进行。
现状下的架构
这里引入一个内部的简化版架构示意图,仅供参考。
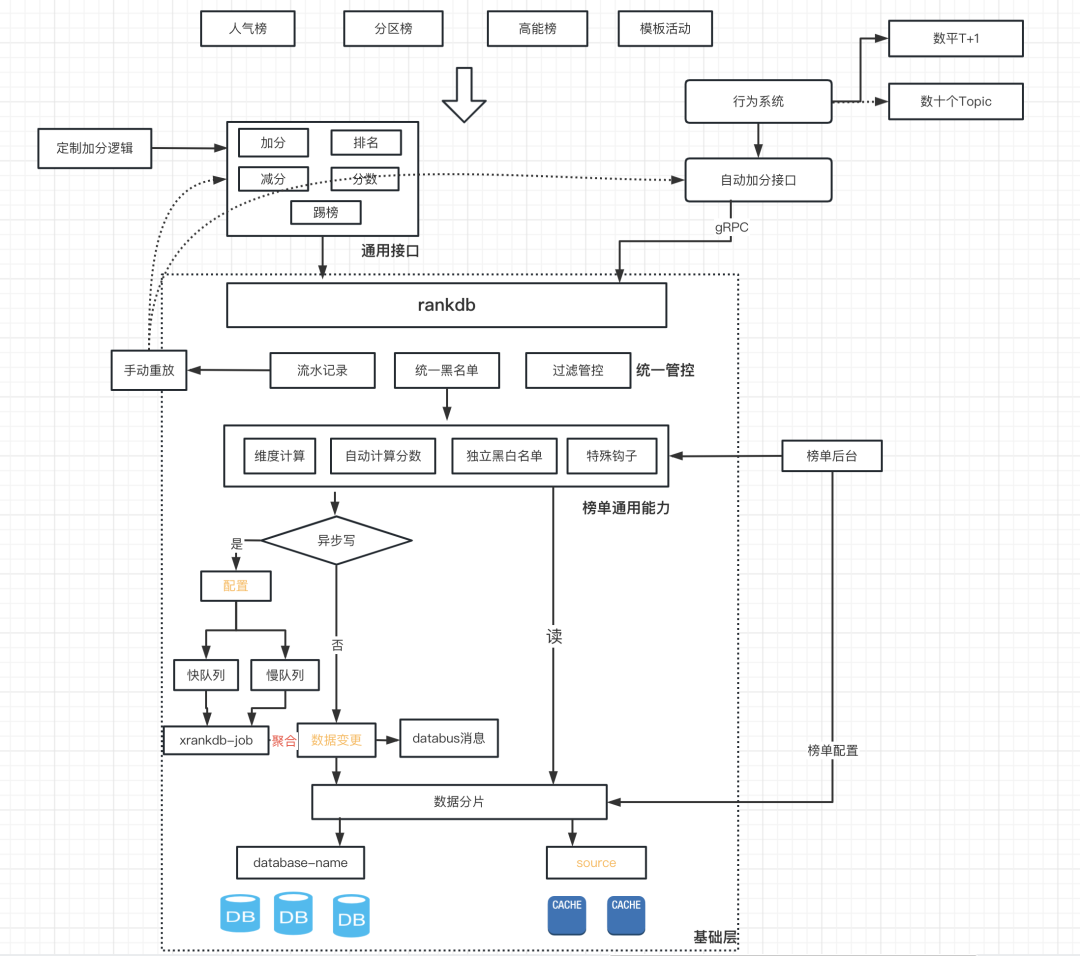
后续规划
代码质量的进一步提升
任何系统的设计,都脱离不了实际的适用场景,需要在各方面进行折衷取舍。现状下的榜单系统其实就是“边跑边换轮子”的产物,比如还有很多业务逻辑还耦合在通用链路中。之前有过一些分层设计理念,也试图引入更合理的设计模型来增强可扩展性、可维护性,但都并没有完全的落地,需要继续推进。
日志治理
目前榜单系统的日志量非常大,最多时每天将近20T。其中不乏噪音日志、含义重复、大结构输出等不合理的做法,需要进行梳理治理。
存储治理
-
老旧数据、过期数据较多,有很多不再使用的榜单遗留的配置、存储表、无TTL缓存等,且mysql数据没有自动过期的能力,可以建设自动化告警、定制化归档的能力。
-
虽有集群隔离,但有的业务榜单在代码中通过hard code交叉使用多个集群,所谓的“核心”、“非核心”数据隔离存储的优势也丧失,总体感觉使用有些混乱。
-
缺少快捷的可视化、业务体感能力,想要查看榜单系统目前存储集群的使用情况,需要分别翻看多个mysql、redis集群的多个平台的监控,如容量监控、访问流量监控等等,然后再汇总评估。
榜单系统新架构
基于目前榜单系统的一些痛点
-
更合理的架构分层、领域间更清晰的边界划分;榜单内核加业务层支撑,可扩展、可测试的自洽闭环。
-
加分行为处理的实时性、数据一致性的优化提升。
-
更加科学的存储选型。
-End-
作者丨芳苇


















 268
268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









