






1、背景
2024 年 7 月 2 日 10:04,我站机房 A 公网物理光缆中断,导致机房 A 公网无法访问。本文将从 DCDN 架构及多活治理的视角,分析本次故障中我们发现的问题和治理优化措施。
2、止损过程
故障发生后,SRE与网工接收到大量专线中断、公网探测告警,快速拉起线上会议协同进行故障定位及止损操作;
在此期间核心业务(如首页推荐、播放等)因在 DCDN 侧配置了源站机房级别自动容灾生效,未受影响;
首先定位到的是单个运营商线路存在大量丢包异常,优先将该运营商用户流量切向具有专线回源的 CDN 专线节点,此时这部分用户流量恢复,但整体业务未完全恢复;
继续定位到整个机房 A 公网完全无法访问,而从机房 B 核心业务场景因自动容灾生效存在流量上升且观测业务 SLO 正常,决策执行全站多活业务切流至机房 B 止损。此时多活业务完成止损,非多活业务仍有损;
继续对非多活业务流量执行降级,将用户流量切向 CDN 专线节点回源,此时非多活业务流量完成止损。
3、问题分析
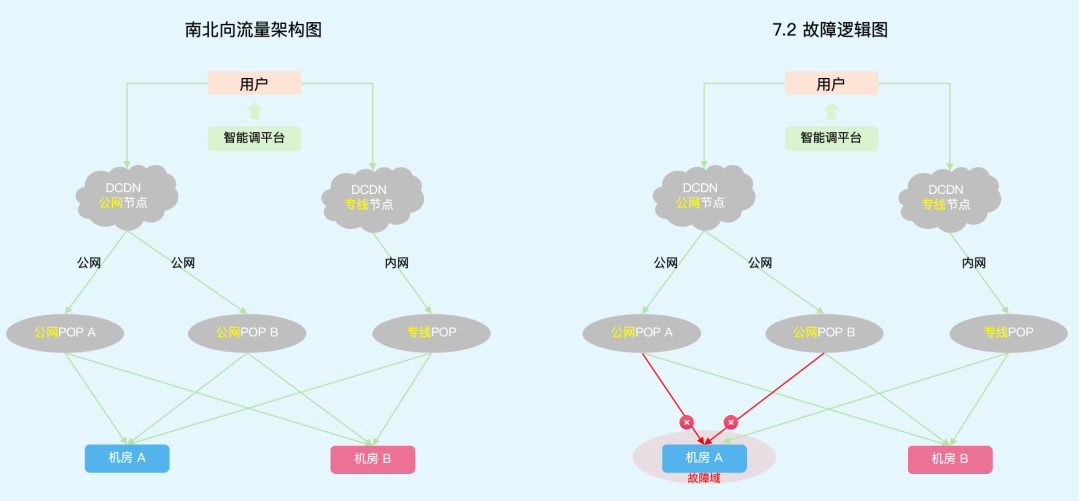
图1:南北向流量架构图 / 0702故障逻辑图
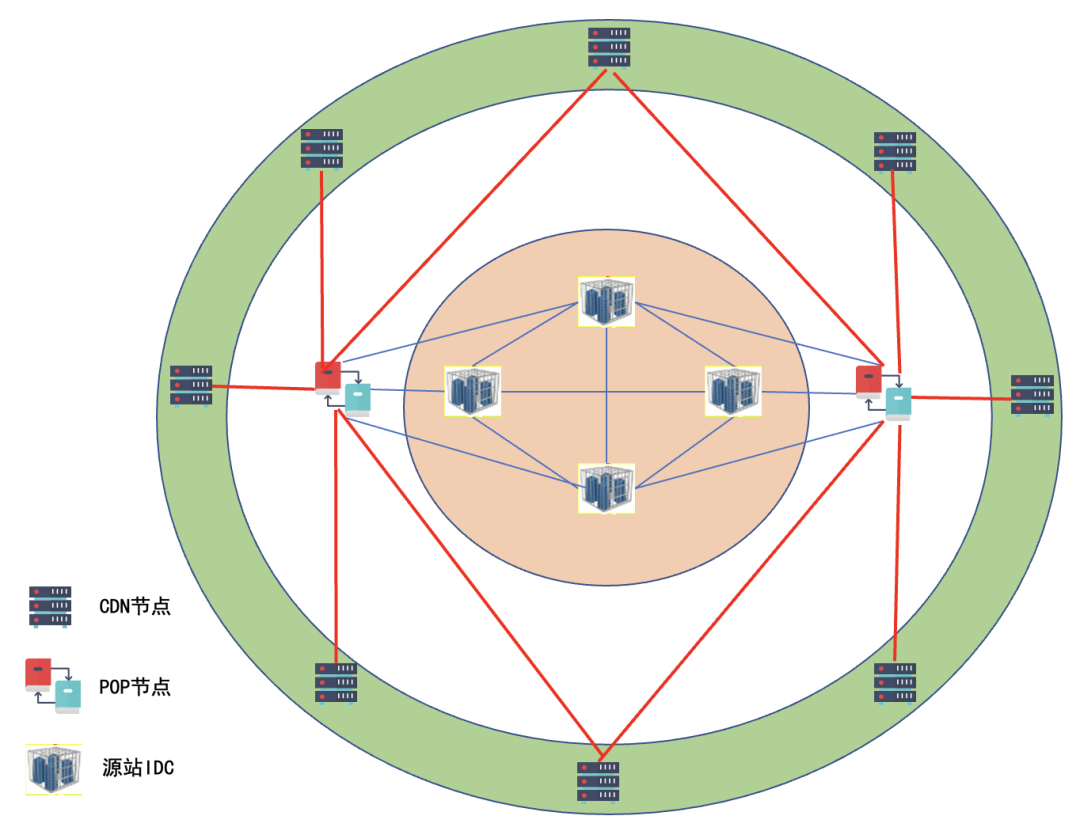
图2:B2-CDN环网示意图
先简单介绍一下 B 站源站架构,从上图1可以看出,B 站在线业务有两个核心机房,每个机房都有两个互联网接入点(公网 POP ),且这两个互联网接入点分布在不同的省市。这样设计的核心思路:网络接入(以下统称为 POP )和算力中心(以下统称为机房)解耦,达到接入层故障可容灾的效果。
同时从图2可知,为了提升自建 CDN 节点到源站核心机房的回源稳定性和效率。我们完成了 B2-CDN 环网的设计和建设,实现了从边缘 L1 & L2 自建 CDN 节点通过该环网进行回源,丰富了业务从边缘节点回核心源站获取数据的途径。其实 B2-CDN 环网的设计初衷是为了给各 L1 & L2 自建CDN节点在处理边缘冷流、温流、热流时能有更多的手段,以探索更加适合有 B 站业务特征的边缘网络调度方式。B2-CDN 环网底层通过二层 MPLS-VPN 技术实现各节点 Full-Mesh,并在此基础上通过三层路由协议(OSPF、BGP) 实现各节点与源站核心机房之间的互联互通。同时各业务保留通过公网回源核心机房的能力,做为 B2-CDN 环网出现极端故障情况下的兜底回源方案。
B 站接口类请求主要通过 DCDN 加速回到源站,DCDN 节点分为两种类型,通过公网回源的公网节点和通过专线回源的专线节点。正常情况下 DCDN 公网节点可通过双公网 POP 回到源站,DCDN 专线节点则通过内网专线回到源站。并且在 DCDN 层面,有针对源站的 Health Check 功能,会自动摘除探测异常的源站 IP。比如当 DCDN 节点请求回源 POP A 发生异常时,会重试到 POP B。DCDN 公网节点常态可通过双 POP 交叉回源站,应对 DCDN 到某一个源站 POP 点出现丢包或中断,容灾方案自动生效,对业务几乎无影响。
然而本次故障中双 POP 至机房 A 故障,相当于机房 A 公网脱网。不同于单 POP 故障,常规双 POP 之间互相容灾方案无法生效。除了几个核心业务场景因前置配置了机房级别的故障容灾策略未受影响外,非自动容灾的多活业务需要执行机房维度切流进行止损。由于DCDN 专线节点可以通过 B2-CDN 环网专线回源不受本次故障影响,最终成为了非多活业务的逃生通道。
回顾整个止损过程,我们发现了以下问题:
-
机房极端断网故障,定界较慢且预案不够完备
-
部分多活的业务仍需要手动切流止损,是否可以更快速,甚至自动止损
-
非多活的业务应对机房出入口故障,如何主动逃生
4、优化措施
针对本次故障中遇到问题,我们重新评估了单机房故障的预案及改进措施,可以看到多活业务整体的止损预案是一致的,重点关注自动容灾生效及手动切流的效率;而非多活的业务需要有多种逃生手段:通过DCDN内网节点回源、或通过API网关跨机房转发。
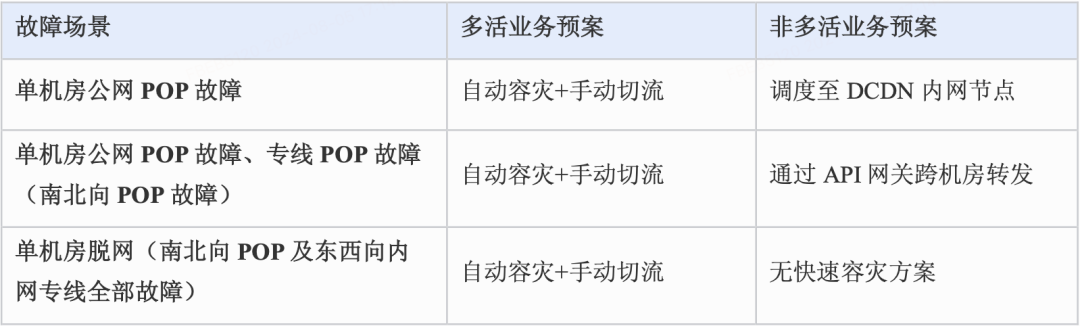
机房极端网络故障预案
如上文所述,源站有双公网POP加专线三个入口,所以逻辑上任意两个入口异常,都依然有机会保证业务可用性。因此我们做了如下措施:
-
对 DCDN 专线节点算力及规模扩容,尽力提升极端情况下的承载能力;
-
双公网 POP 出口异常情况下的调度预案,对域名和DCDN节点类型进行分组,支持非多活域名快速切到专线节点;由于多活域名可通过切流止损,为了不额外增加专线节点负载,不需要调度至专线节点;
-
故障的定界效率提升,对重要监控的上报链路进行优化,与业务链路解耦,并且在公有云进行了容灾部署;同时优化网络拓扑面板,清晰展示每条链路的情况;以及告警和展示方式,方便快速定位问题。
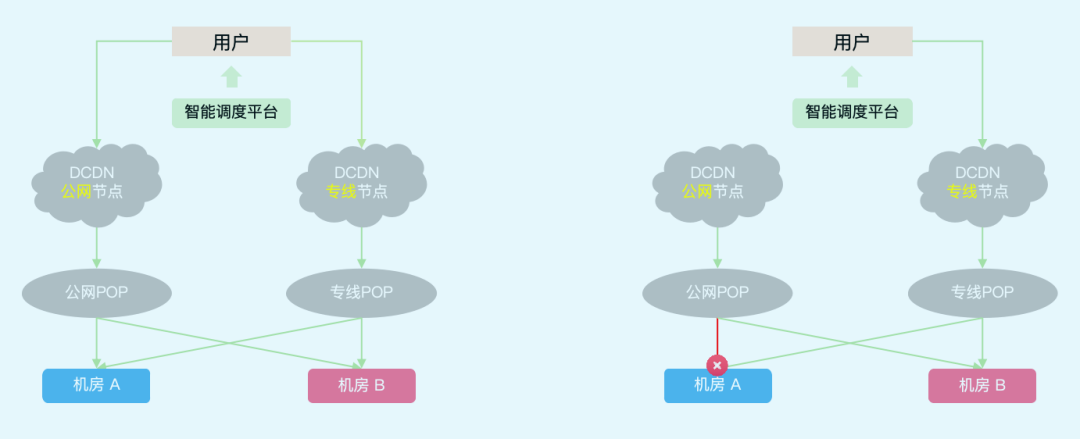
图3:DCDN流量调度架构:日常态 / 容灾态
多活建设持续推进及常态化演练
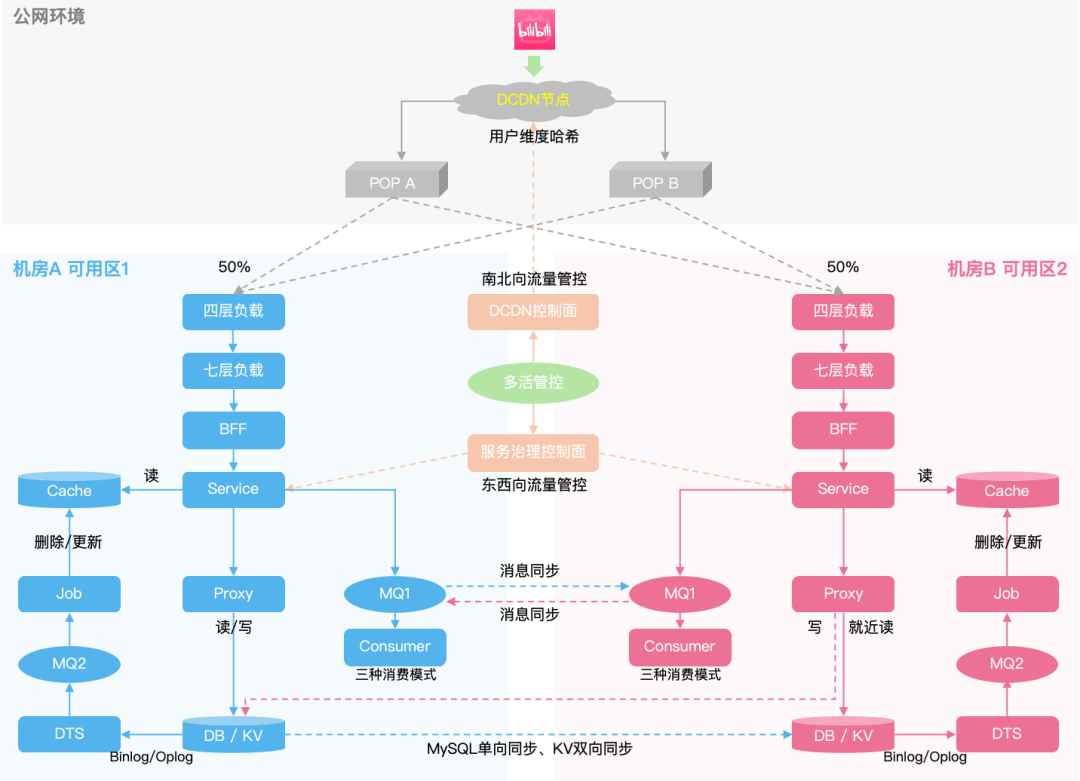
图4:同城多活架构简图
当前我站业务主要为同城多活架构,如图4所示,我们将多个机房逻辑上划分为两个可用区,每个可用区日常承担50%的流量,将整体多活架构分层来看:
-
接入层:
-
DCDN:南北向流量管控,基于用户纬度信息Hash路由至不同可用区的源站机房,支持可用区维度自动容灾;
-
七层负载/API网关:南北向流量管控,支持接口级别路由、超时控制、同/跨可用区重试、熔断、限流&客户端流控等;
-
服务发现/服务治理组件:东西向精细流量管控,框架 SDK 支持同可用区内优先调用,服务、接口级别流量调度;
-
缓存层:主要为 Redis Cluster、Memcache,提供 Proxy 组件供接入,不支持跨可用区同步,需双可用区独立部署;通过订阅数据库Binlog维护数据最终一致性,同时对于纯缓存场景需要改造;
-
消息层:原则上可用区内封闭生产/消费,支持 Topic 级别消息跨可用区双向同步,Local/Global/None 三种消费模式适配不同业务场景;
-
数据层:主要为 MySQL、KV 存储,主从同步模式;提供 Proxy 组件供业务接入,支持多可用区可读、就近读、写流量路由至主、强制读主等;
-
管控层:Invoker 多活管控平台,支持多活元信息管理、南北向/东西向切流、DNS 切换、预案管理、多活风险巡检;
对于完成多活改造的业务,我们建设了多活管控平台对业务多活元信息进行统一维护,支持业务南北向及东西向多活切流管控。平台侧支持切流预案的维护,支持单业务、多业务、全站维护的快速切流。同时平台提供多活相关风险巡检能力,从多活流量比、业务容量、组件配置、跨机房调用等角度常态巡检风险,支持相关风险的治理运营。
前置完成进行预案维护和风险治理后,我们定期进行单个业务、多个业务组合南北向切流演练,验证服务自身、其依赖组件、其依赖下游的容量、限流等资源负载情况,常态保证多活的有效性,常态可切换可容灾。
机房级别自动容灾
对于用户强感知的场景涉及的核心服务,在DCDN侧配置源站机房级别的容灾策略,应对单个源站机房入口故障时可以自动将流量路由至另一个机房实现止损。
多活业务的自动容灾原先没有默认全配置,优先保障了首页推荐、播放相关等主场景,其余业务场景根据资源池水位情况执行切流。当前我们资源池平均CPU利用率已达35%+,在线业务平均峰值CPU利用率接近50%,我们已经对全站业务切流单机房的资源需求进行梳理,同时多活切流也将联动平台进行HPA策略调整,以及准备资源池的快速弹性预案,确保大盘资源的健康。后续将支持对社区互动、搜索、空间等更多用户强感知场景自动容灾策略配置。在遇到机房级别故障时候无需人工干预,多活业务可直接容灾止损。
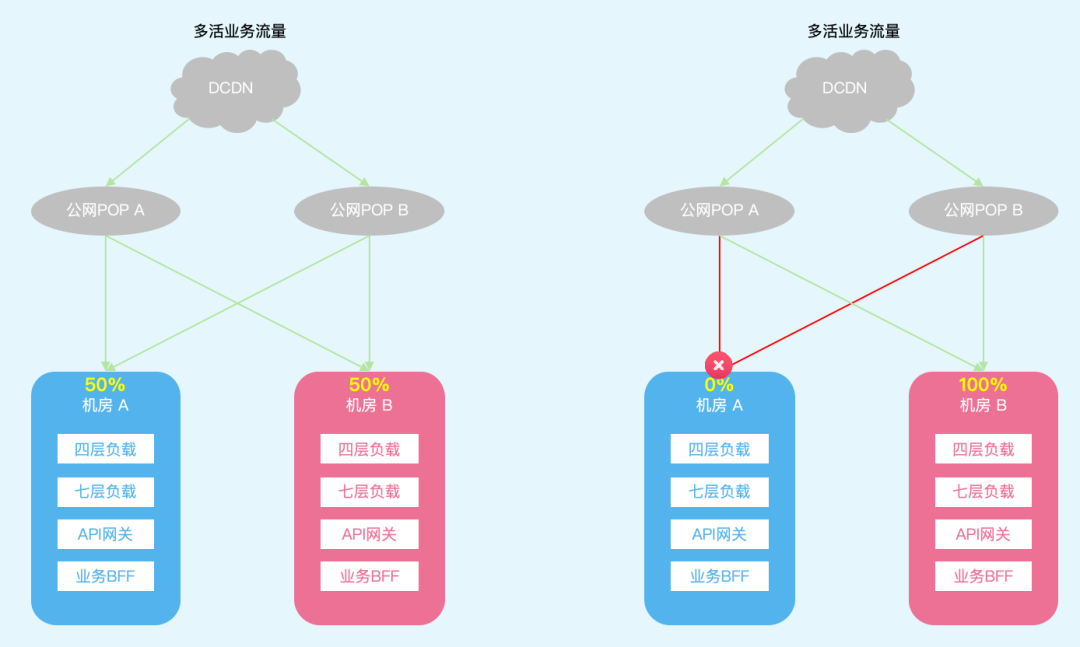
图5:多活业务南北向流量架构:日常态 / 容灾态
非多活流量逃生
部分业务当前是没有多机房多活部署的,仅在一个机房可以处理流量;因此在原来的方案中,这部分非多活业务流量只会回源至机房 A,无法应对机房 A 公网入口故障。如同本次事故中,非多活业务流量无法切流止损,依赖降级走CDN专线节点。
为了应对单机房公网入口、四层负载、七层负载故障等场景,我们计划在DCDN侧为非多活业务规则也配置源站级别自动容灾,在七层负载SLB实现多机房多集群的路由配置合并统一,确保非多活业务的流量在故障时可进入机房 B 路由至API网关;在API网关侧判断接口是否多活,非多活接口通过内网专线进行流量转发,实现流量逃生。
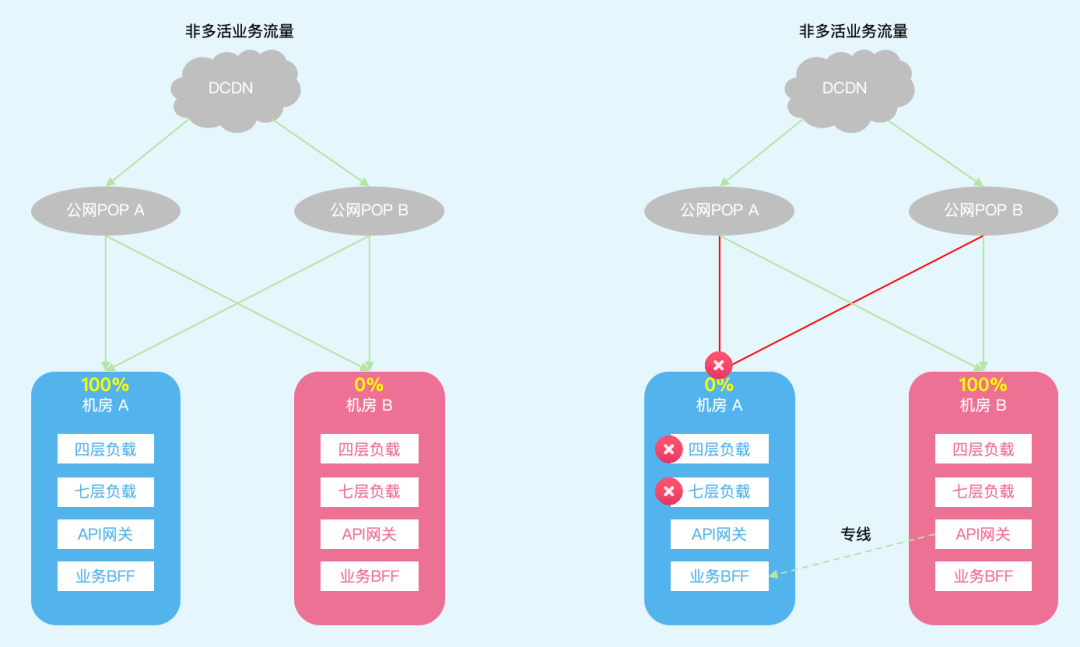
图6:非多活业务南北向流量架构:日常态 / 容灾态
5、总结
单个机房级别的故障,非常考验多活改造的完整性和有效性,同时必须需要故障演练来进行验证,下半年我们会继续重点关注多活风险治理,除了常态的切流演练外也会启动南北向、东西向的断网演练。后续也会有多活治理、演练相关的专题内容分享,敬请关注!
-End-
作者丨SRE团队、网络团队
















 1177
1177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









