






1. 前言
视频场景分类算法是计算机视觉领域研究的热门内容,并作为复杂任务系统的前置算法,能够应用于我们多媒体实验室多项业务,如内容自适应转码、画质智能修复和视频质量评估(VQA)中。通过针对不同类型的图像自适应抉择不同的模型,从而精准有效提升算法在业务中的实际效果。语言、视觉是人类感知世界最基本的方法,也是人工智能理解世界的两大支柱。多模态是结合了图像、文本、音频等多种数据类型的一种技术方案。该技术不仅提高了模型的泛化能力,还扩展了人工智能技术的应用方向,如图像分类、图像问答、文本图像生成等。本文研究了多模态算法在多媒体系统中进行场景分类的应用,探讨了实施过程中的挑战并给出对应的解决方案。
2. 背景
B站作为一个聚集了海量创作者投稿视频的社区,拥有丰富的多品类、多场景的优质视频内容。然而,随着用户年龄和兴趣圈层的不断扩展,UGC(User Generated Content,用户生成内容)视频内容五花八门,画质良莠不齐,这给多媒体分析与处理带来了极大挑战。以画质修复为例,多媒体系统会对视频画质进行增强处理,辅助改善用户的视频观看体验。由于同一个视频内可能会包含不同类型的场景,且不同场景画质质量差异较大,使用相同的增强方式处理不同场景往往不是最佳选择。因此,迫切需要一个能够识别和分类视频场景的前置算法,使多媒体系统根据场景特征自适应选择最合适的画质修复算法,从而实现更加精细和高效的画质增强处理。视频场景分类算法可以通过识别单帧图像特征进行分类来实现。
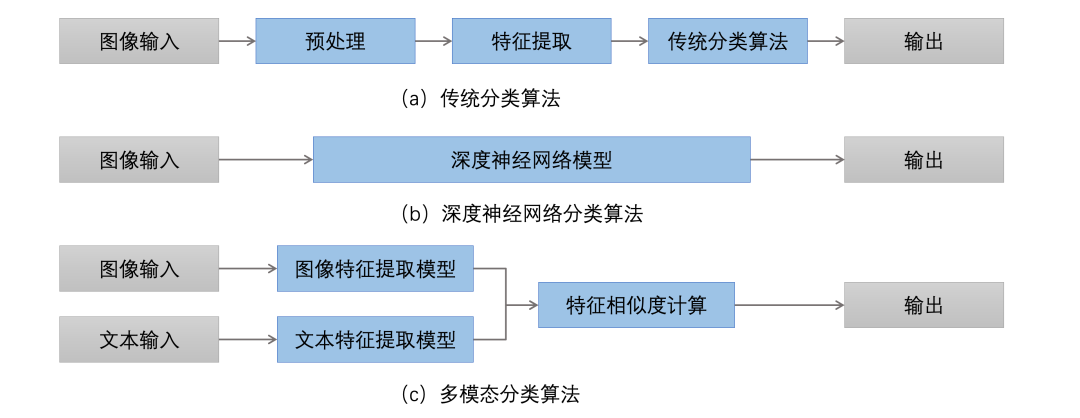
图1 图像分类算法简要流程
传统的图像分类方法通常使用 SIFT(Scale Invariant Feature Transform,尺度不变特征变换)、HOG(Histogram of Oriented Gradients,方向梯度直方图) 等技术,从图像中提取出关键信息,如颜色、形状和纹理。再使用SVM(Support Vector Machine,支持向量机)、决策树、随机森林、K近邻算法和朴素贝叶斯等方法对标注好的训练数据进行分类训练。尽管这些算法在某些任务上取得了较好的效果,但它们通常需要大量的手工调整和参数优化,且在处理大规模图像数据集时,性能有限。随着深度学习技术的快速发展,CNN(Convolutional Neural Networks,卷积神经网络)作为一种端到端(end-to-end)的模型,能够通过卷积、池化、全连接层等操作,从数据中学习到更加丰富的特征表示,无需手动设计特征和分类器,可以获得更好的分类效果。然而大多数基于深度学习的算法均需要大量的标签数据进行训练,而公开的数据集并不一定适合实际业务场景,因此需要人工收集和标注更适合业务场景的大规模数据集。
近年来,多模态算法成为解决特定问题或任务的重要研究方向。这类算法能够处理包括视觉、语音、文本在内的多种模态数据类型,并将这些数据映射到同一个空间域中。这种方式不仅提高了模型的泛化能力,还使得跨模态的分类算法成为可能,进一步扩展了人工智能在复杂应用场景中的应用潜力。同时,大模型的快速发展也使得预训练特征提取模型在各种应用场景成为可能。
3. 现有技术
图像分类是计算机视觉领域的核心任务,旨在将图像准确地分配到预定义的类别中。随着深度学习技术的快速发展,图像分类算法受益于丰富的数据资源和强大的算法模型,取得了显著的进展。为了更好地理解这一领域,本文首先介绍常用的图像分类数据库,随后介绍图像分类现有的算法方案。
3.1. 现有的数据库介绍
高质量的数据集是深度学习研究的重要组成部分,直接影响了模型训练的准确性和鲁棒性。以下是图像分类任务中部分常用数据库的介绍:
1)CIFAR-10
CIFAR-10 数据集是由 CIFAR 研究所的研究人员开发包含飞机、汽车、鸟等 10 个类别,由尺寸为 32 × 32 像素的彩色图像构成,10 类之间相互独立,无任何重叠的情况。训练集包含 50, 000 个样本和 50, 000 个标签,测试集包含 10, 000 个样本和 10, 000 个标签,总数为 60, 000 张。
2)CIFAR-100
CIFAR-100 数据集是由 100 个不同类别的 60, 000 张 32 x 32 像素的彩色图像组成。数据集中的训练集和测试集,各包含 50, 000 张训练图像和 10, 000 张测试图像。CIFAR-100 的类别分为 20 个粗分类,每个粗分类下有 5 个细分类。例如,“人类”这个粗分类下的细分类包括:婴儿、男孩、女孩、男人和女人。
3)ImageNet
ImageNet 是一个于 2009 年创立的计算机视觉领域的大型视觉数据库,包含超过 1, 400 万张标注过的图像,涵盖 2 万多个类别,其中有超过 100 万幅图像有明确的类别标注和主要物体的定位边框。在图像分类、目标检测和目标识别等任务中成为了一个重要的基准数据集。
现有数据库的分类标签都是基于通用的标准制定的,缺乏对对特定业务场景的考虑,因此难以满足实际业务需求。为了更好的适应业务的具体目标,通常需要人工标注相应的分类标签。但人工标注分类标签是一个耗时费力的任务,特别是在面对大规模数据集时,工作量和成本会成倍的增加。因此如何减少大规模数据集的依赖,并提升算法的准确率成为本文的研究重点。
3.2. 现有的算法方案
3.2.1. 基于卷积神经网络的方案
CNN 是一类能够从图像中提取复杂特征并将其映射到高维空间的神经网络模型,如 LeNet5、GoogLeNet、VGG、ResNet、EfficientNet 等。其核心思想是通过卷积、池化等操作来提取图像特征,最后通过全连接层对特征进行分类和回归。
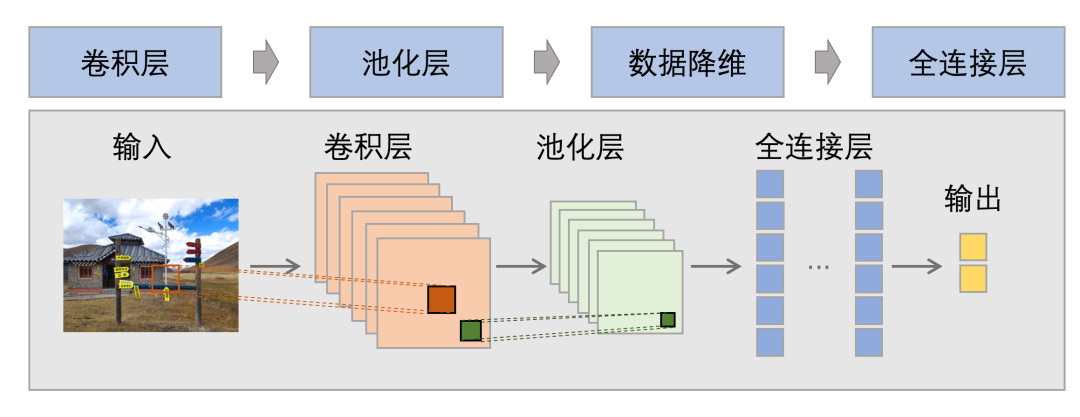
图2 CNN 简要流程
以 2015 年 ILSVRC( ImageNet Large Scale Visual Recognition Challenge,ImageNet 大规模视觉识别挑战赛)的冠军模型 ResNet(Residual Networks,残差网络)[1]为例,该模型利用残差块引入了跳跃连接(Skip Connections),这种设计不仅在网络深度增加时保持了训练效果,还有效解决了深度卷积网络中常见的梯度消失和梯度爆炸问题。
事实上,大多数 CNN 的性能提升往往依赖于对网络结构的不断优化,包括增加网络的深度、扩展网络的宽度(即增加卷积层的通道数),以及提高输入图像的分辨率。为了实现最佳性能,这一过程通常需要反复试验不同的模型架构和训练策略,同时引入大量的标注数据。
3.2.2. 基于多模态的算法方案
多模态算法是一种将不同类型数据映射到同一空间域的特征算法,可以形象地理解为一个人用多种感官去感知世界,并将这些感官信息整合起来进行理解和判断。以下为多模态领域经典算法的介绍。
Clip
clip(Contrastive Language-Image Pre-Training,对比语言-图像预训练)[2]是 openai 在 2021 年初发布的一种基于对比学习的多模态预训练模型,被广泛应用于 DALL・E 2 ,Stable Diffusion 等重要的文生图等大模型之中,是多模态领域的经典之作。
clip 创新的将图像和文本映射到一个共享的多模态向量空间中,从而能够使模型理解图像和文本之间的关系。如下图所示,clip 是使用了双塔结构的神经网络,包括一个图像编码器(Image Encoder)和一个文本编码器(Text Encoder)的模型结构。其中文本 Encoder 可以采用 NLP(Natural Language Processing,自然语言处理)领域中常用的文本 transformer 模型,而 Image Encoder 可以采用 CNN 模型或者 ViT( Vision Transformer)模型。两个不同的编码器分别负责将图像和文本转换为对应的嵌入向量(Embedding)。然后计算两个embedding的余弦相似度(Cosine Similarity),相似性越大接近于1,意味着文本和图像之间越匹配,反之相似性越接近于 0 ,文本和图像越不匹配。
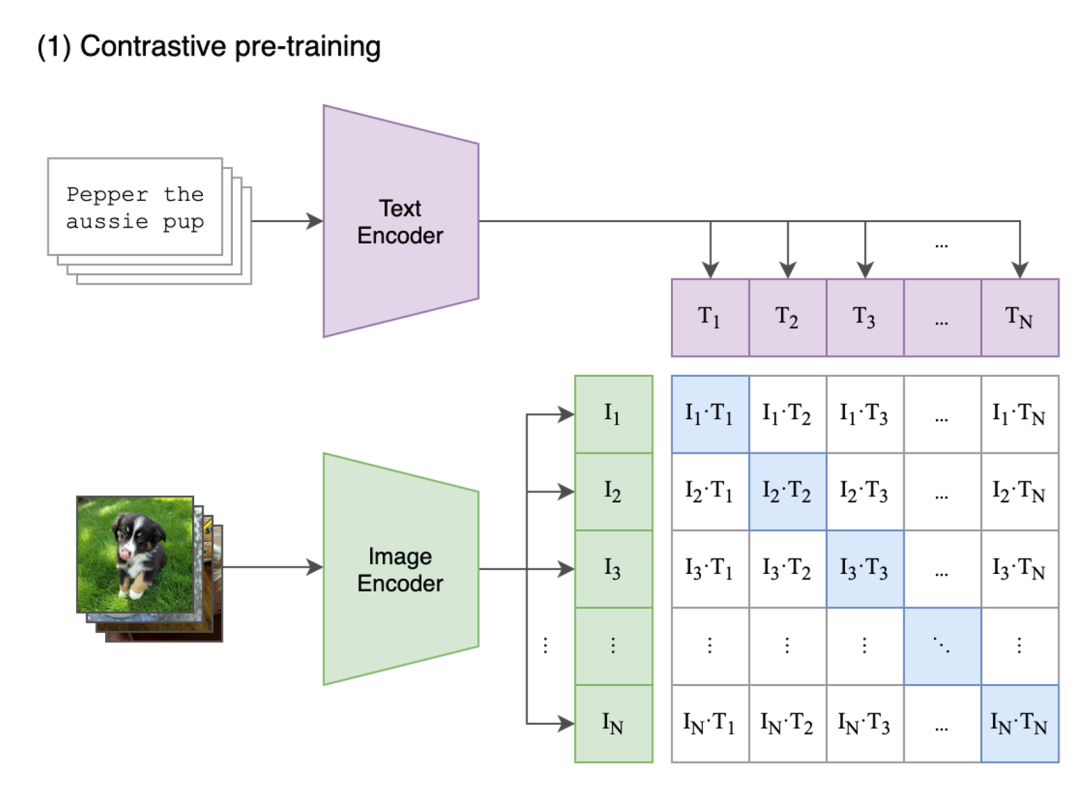
图3 clip 神经网络结构
clip 的优势在于其强大的跨模态理解能力,能够同时处理文本和图像数据,并在多种任务上展现卓越的性能。通过对大规模的数据进行训练,clip 模型具备了出色的泛化和迁移能力。尽管在自然分布的数据集上,其在零样本任务(zero-shot,即识别从未见过的数据)中表现出较强的鲁棒性,但当测试数据和训练数据差距较大时,性能会有所下降。具体到分类任务来说,clip 可以通过设置 prompt(提示词)来实现更灵活的分类标签。然而,仅使用手工设定好的 prompt,往往难以达到理想的业务效果。此外,人工设定的 prompt 可能完全不符合业务需求,需要反复调整文本以获得最佳效果。
Blip
在大模型出现之前,大多数预训练模型在训练完成之后,对新的下游任务的适应能力有限,不能有效泛化。blip(Bootstrapping Language-Image Pre-training, 引导语言-图像预训练)[3]是一个专为多模态任务设计能够统一视觉语言理解生成的预训练框架。该方法提出了一个多模态混合的 MED(Multimodal mixture of Encoder-Decoder,多模态混合的编解码)模型架构和数据增强方法,以适应更广泛的下游任务。
在模型方面,为了预训练一个既有理解能力,又有生成能力的统一模型,MED 包含三种结构:单模态编码器、基于图像的文本编码器和基于图像的文本解码器。在数据方面,blip 改进了 clip 的从互联网获取数据的方案,提出了 CapFilt(Captioning and Filtering)模块,既对给定的互联网图像生成文字,同时又通过判断原始文本、生成文本与图像是否匹配,过滤文本噪声提升语料库的质量。
4. 算法设计方案
UGC 视频通常会包含多个不同场景的视频片段,而这些片段往往属于不同的类别。在进行视频分类时,首先通过场景切分将视频划分为独立的场景片段。之后对这些视频片段进行分类。通过将场景切分技术与图像分类技术相结合,我们开发了一种适应特定任务需求的视频分类系统。这种系统能够高效地对视频内容进行分类,满足多样化的应用场景。
4.1. 标注数据集
作为一种在超大数据集上训练的模型,clip 算法能够在没有特定任务的监督数据情况下,在自然分布数据集上也有出色的表现。我们首先根据该算法 prompt 的设计规则,设计实际业务需求对应的 prompt 文本标签。然后,基于其 zero-shot 能力对少量未经标注的图像数据集进行预分类,生成伪标签。下图为预分类流程,先设定好业务需求的 prompt 文本标签,使用文本编码器将上述标签进行特征提取,得到文本向量。同时,将待检测的图像输入图像编码器,得到图像特征向量。最后将图像向量和文本向量进行相似度检测,得到该图像的类别。通过上述方式,我们能够为图像数据集进行初步分类。
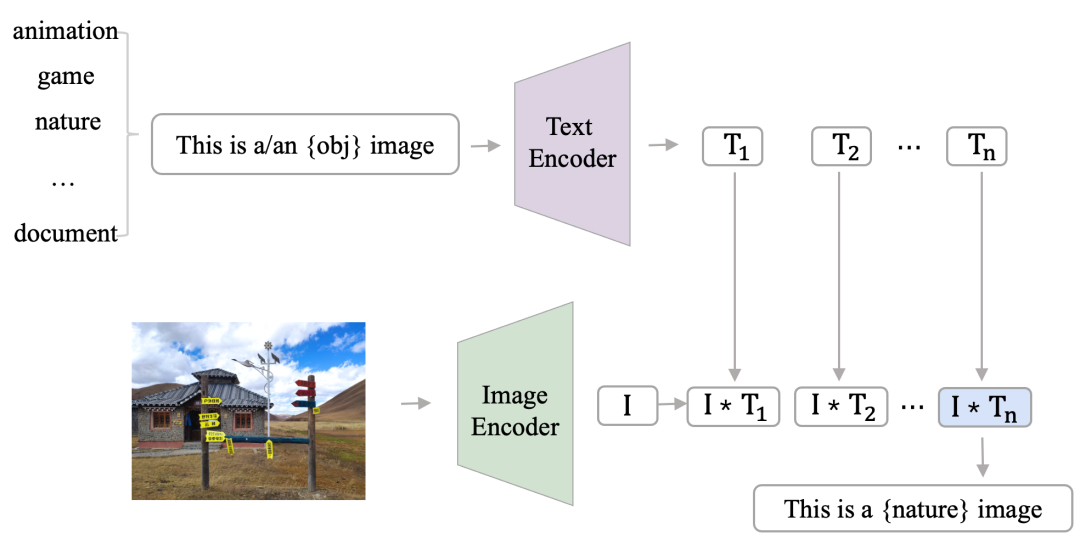
图4 数据预分类
基于人工设定的 prompt 文本标签,clip 在对陌生数据集进行分类时,无法达到完全的准确性。因此,需要将未准确分类的数据集进行数据清洗,剔除其中的噪声数据。经过上述步骤能够极大的减少人工标签的工作量,只需要对预分类好的数据集进行数据清洗,而不需要完全重新制作标签。
4.2. 模型训练
clip 算法是一个通过 4 亿文本和图像对以自监督的方式进行训练的大规模的图像-文本嵌入模型,这意味着 clip 的图像编码器和文本编码器都具有较强的特征提取的能力。我们在传统图像算法流程的基础上,使用 clip 的预训练好的图像编码器替换传统 SIFT、HOG 等作为特征提取器提取图像的特征,引入全连接层,使用清洗好的训练数据集对提取的图像特征进行分类训练。将训练后的模型重新应用到4.1中的标签制作中,不断迭代,最终得到能够准确分类的模型。
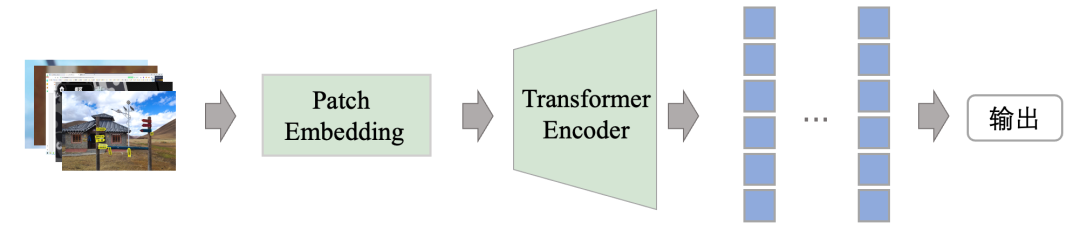
图5 训练模型结构
ResNet 50 在计算机视觉社区中得到了广泛采用和研究,其架构在各种图像分类竞赛中表现出色,实现了最先进的性能。我们以 ResNet 50 作为对比的算法,进行三分类任务实验,其中包括自然场景(nature)、动漫 / 游戏场景(animation / game)、文稿内容场景(document)。在实验中,总共有 5, 920 张人工标注的图片,其中 90% 用于训练集,其余数据为验证集。
训练输入尺寸设置为 224 × 224 ,在 RTX 3090 上进行单机单卡的训练。将 ResNet 50 训练 300 个 epoch(每个 epoch 是对训练集中的全部样本训练一次),大约为 180 分钟。而在相同条件下,对 clip 结合全连接层训练 600 个 epoch ,仅需约 125 秒即可收敛。我们从准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1 分数(F1 score)四个维度对包含 clip 的 zero-shot 方案在内的三种方法,在相同验证集上进行对比。验证结果如表1所示,基于 clip 结合全连接层的方案在各项指标上都明显优于 ResNet 50 和基于 clip 的 zero-shot 方案。若在实际业务中对准确率要求不高且没有足够的训练数据时,clip 的 zero-shot 方案可能是一个合适的选择。
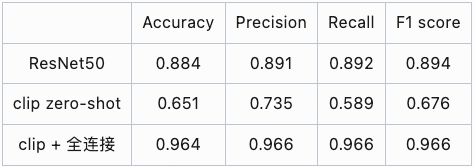
表1 不同训练方案验证结果
4.3. 视频场景分类
B站的 UGC 视频通常由多个不同的视频片段拼接而成,每个视频往往涵盖了多种类型场景。为了确保视频分类检测的准确性,我们专注于处理场景转换后的视频片段。一种常见的方法是基于帧间内容变化的场景切换检测。该方法通过比较邻帧间的视觉内容差异来识别场景切换点。一旦检测到场景切换,我们就从这些场景中抽取关键帧,并对这些帧进行图像分类。通过将分类预测得分归一化并按类别累加,最终确认每个场景的类别。
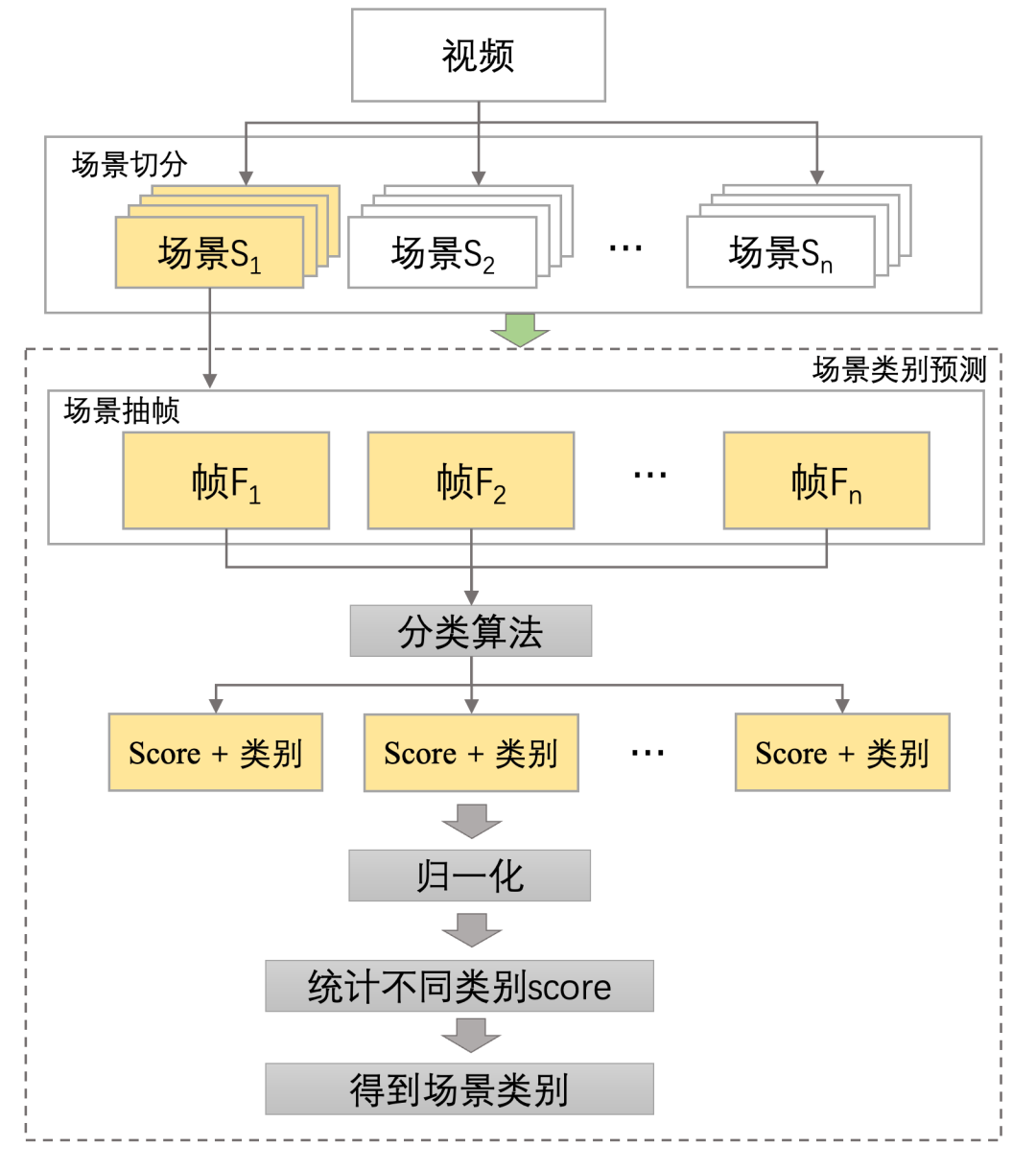
图6 基于场景切分的场景分类方案
5. 总结与展望
在多模态算法快速发展的时代,分类算法也随之不断地演进和创新,而预训练多模态算法则进一步提升了训练效率和准确性。我们结合实际的业务内容,重新审视了图像分类算法的技术发展,实现了一套基于多模态的场景分类算法方案,该算法在未来可用于多媒体实验室的画质智能修复、内容自适应转码和视频质量评估(VQA)等多媒体系统中,如在内容自适应转码项目中,使用与主观感受匹配度较高的 VMAF 作为画质评价的预设目标值,并通过深度学习准确预测视频转码参数。然而,对于不同类型的视频,达到相同的目标 VMAF 值,人眼的主观感受是不相同的,可以根据分类出的场景不同自适应决定不同的预设目标值,以期达到更精准的画质和码率控制。未来多媒体实验室还将继续探索在多媒体系统中引入更多的大模型及多模态技术,进一步提高整个系统的性能。
参考文献:
[1] He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. CVPR, 2016.
[2] Radford, Alec, et al. "Learning transferable visual models from natural language supervision." International conference on machine learning. PMLR, 2021.
[3] Li, Junnan, et al. "Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation." International conference on machine learning. PMLR, 2022.
哔哩哔哩多媒体实验室(bilibili mlab)是一支技术驱动的年轻队伍,具备完善的多媒体技术能力,以极致卓越的多媒体体验为目标,通过对自研视频编码器、高效转码策略、视频图像分析与处理、画质评价等技术的持续打磨和算法创新,提出了画质可控的自适应转码算法、视频超分、视频插帧、画质评价、高性能多媒体算法推理基座、自研编码器等诸多高质量的多媒体解决方案,从系统尺度提升了整个多媒体系统的性能和效率,助力哔哩哔哩成为体验最好的互联网视频社区。
-End-
作者丨什柒、天落、Jonathan 叶


















 655
655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









