






一、“2% GPT size, yet powerful.”
模型简介
Index-1.9B-32K 是一个拥有 1.9B (19亿)参数并具备 32K 上下文长度的语言模型(这意味着,这个超小精灵可以一次性读完 3.5 万字以上的文档)。
在多项长文本评测任务中,该模型在相近尺寸的模型中表现突出。以极小的体积和算力开销(仅仅约为 GPT-4 的 2%),实现了出色的长文本处理能力。如下图所示,我们的 1.9B 模型得分甚至远超 7B 大小的模型。以下是与 GPT-4、千问Qwen2 等模型的对比:

Index-1.9B-32K与GPT-4、Qwen2等模型长文本能力对比
该模型针对 32K 长文本进行了持续预训练(Continue Pre-Training)和监督微调(SFT),训练数据主要来源于我们精心清洗的长文本预训练语料以及自建的长文本指令集。
Github上模型、技术报告等下载
-
代码、模型、技术报告、运行工具下载地址:https://github.com/bilibili/Index-1.9B(⭐️)
-
所有模型、代码等已完全开源、免费使用。
-
所有评测指标可用已开源的代码自助运行并复现。
应用示例(英文财报翻译&总结)
运行我们已开源的交互工具,翻译并总结哔哩哔哩公司于2024.8.22发布的英文财报(英文财报原文:https://github.com/bilibili/Index-1.9B/tree/main/demo/data/user_long_text.txt),效果如下:

二、训练过程
Index-1.9B-32K基于我们已经开源的 Index-1.9B 进行继续训练,进行了额外两个阶段的训练:
1. Long PT:Long continue Pre-Training,长文本继续预训练,基于长数据进行持续预训练。
2. Long SFT:长文本监督微调,基于长指令进行 SFT。
*(RLHF / DPO):尽管我们已经具备强化学习(RLHF)、DPO 等对齐训练的经验,但是这个版本还未经过RLHF/DPO训练(后续版本将补充RLHF/DPO),我们仍然优先集中精力攻克模型在长文本处理方面的深层次能力上。

Index-1.9B-32K的训练流程
模型超参数
Context长度相关的参数
-
Rope Base:32 * 10000 (Rope是大模型主流的位置编码算法,由苏剑林提出)
-
最大序列长度:32768(决定了模型能处理的Token数量上限)
-
最大位置编码:32768(需大于等于“最大序列长度”)
Rope Base 的确定
-
我们通过理论计算,并结合之前的研究工作确定了 Rope Base 的范围,详见:2104.09864(https://arxiv.org/abs/2104.09864) 和 2310.05209(https://arxiv.org/abs/2310.05209)。
-
进一步,我们通过实际训练和对照实验,最终确定了 32*10000 这个 Rope Base。
-
我们也注意到很多其他公司使用百万级甚至更高的 Rope Base,例如,Gradient AI 使用的 Rope Base 甚至超过了 10 亿,因此我们也尝试将 Rope Base 增大到数百万,经过对照实验,结果显示这并不会带来性能提升。
-
Rope Base 和 Context Length 取值:如下图所示,在 32K 上下文情况下,32*10000 的 Rope Base 已经足够,坐标处于图中的红色区域,困惑度较低,能够有效适应32K上下文长度。
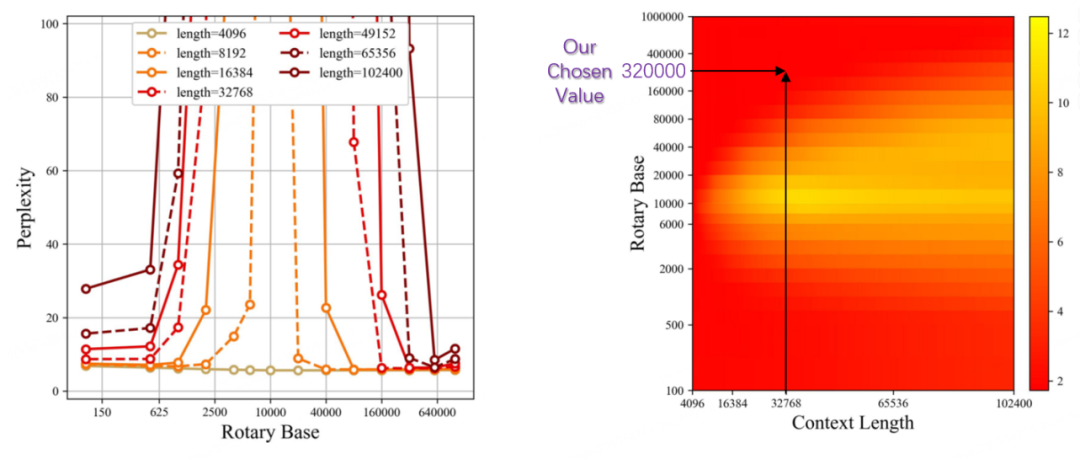
Rope Base与困惑度关系
阶段1:继续预训练(32K)
我们基于自建的长文本语料库进行了持续预训练。我们精心清洗了 100B+ 的长文本数据,在训练了 10B 之后,模型的长文本性能提升已比较显著。
Long PT训练参数
-
为了有效利用算力,使用Doc Packing方式训练(多条训练数据拼接并填满最大序列长度),并重置注意力掩码和位置 ID。
-
Token 级别的 Batch Size 为 4M。
-
峰值学习率为 1e-5。
-
学习率调度:余弦调度,开始时进行少量预热以稳定训练过程。
-
权重衰减:0.1,引入正则化,用来防止模型过拟合。
-
梯度裁剪:1.0,防止梯度爆炸,确保训练稳定性。
长文本语料
我们基于自建的海量语料池,构建了长文本预训练语料库。互联网上搜集到的大多数语料的 Token 量比较短,我们进行了统计,不同Token数量的区间统计如下:
-
73% 的文档包含的 Token 量处于 0~4K 之内。
-
32K以上长度的长文本语料不足 1%。

我们的语料库 Token 长度分布
阶段2:SFT(32K)
-
我们基于 3 万多条自建的长文本指令,并结合 5 万多条通用指令进行了 SFT,使模型具备了长文本指令遵循能力。我们也尝试使用数十万条指令进行训练,但结果没有显著变化,这一方面源于我们的指令的质量和多样性仍不佳。
-
在我们多次实验中,通常 2 个 epoch 就能达到较好的性能。
-
SFT 过程的训练集损失下降曲线如下,可以看到模型在前 100 步内性能急剧提升。
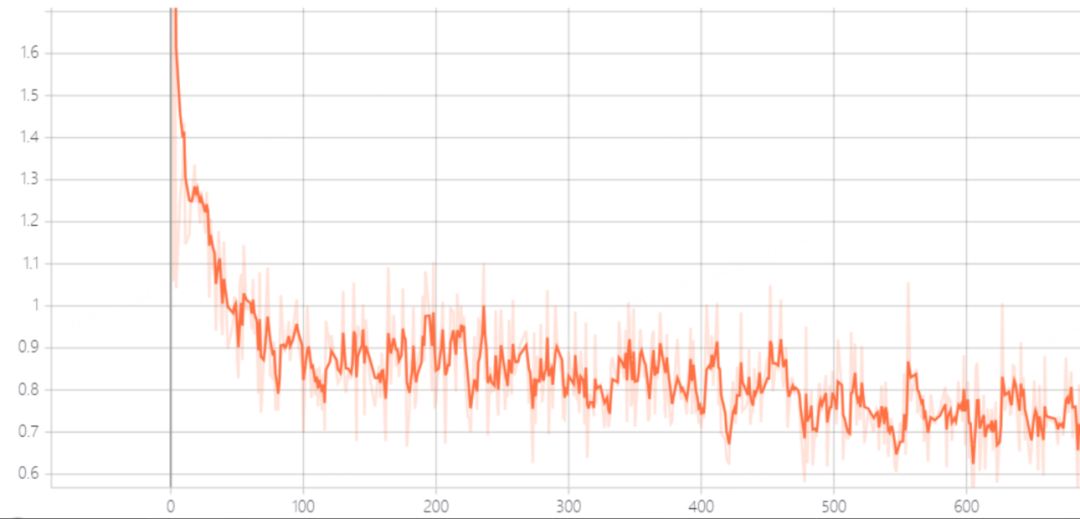
SFT 训练损失曲线
Long SFT训练参数
-
为了有效利用算力,使用Doc Packing方式训练(多条训练数据拼接并填满最大序列长度),并重置注意力掩码和位置 ID
-
Token 级别的 Batch Size 为 1M
-
峰值学习率为 5e-6
-
学习率调度:余弦调度,开始时进行少量预热以稳定训练过程。
-
权重衰减:0.1,引入正则化,用来防止模型过拟合。
-
梯度裁剪:1.0,防止梯度爆炸,确保训练稳定性。
三、效果与评测
-
对于模型的“长文本能力”,我们使用了三种评测方法:NeedleBench、LongBench 和 LEval。
-
对于模型的“短文本能力”,我们使用了自建的评测集和 MMLU 等传统评测方法。
-
评测主要基于 opencompass 完成。我们的模型运行、评测代码也已开源,可以复现我们的评测结果。OpenCompass提供了便捷且丰富的大模型评测框架,这极大地提升了我们模型的训练迭代节奏,特别鸣谢。
长文本能力评测
NeedleBench(大海捞针)
-
Index-1.9B-32K在32K长度的大海捞针测试下,评测结果如下图,可以看到,评测结果只在(32K 长度,%10 深度)区域有一处黄斑(91.08分),其他范围表现优异,几乎全绿。
-
大海捞针测试简介:大海捞针测试通过在长文本中随机插入关键信息,形成大型语言模型 (LLM) 的 Prompt,旨在检测大型模型是否能从长文本中提取出这些关键信息,从而评估模型处理长文本信息提取的能力。
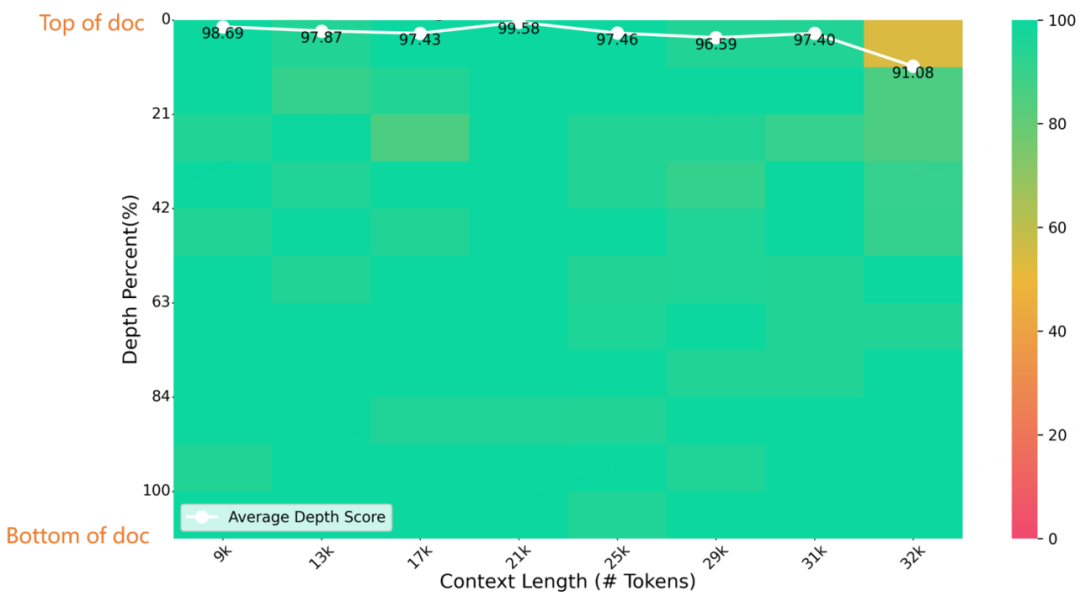
大海捞针评测
LongBench和LEval
-
Index-1.9B-32K在 LongBench 评测上的得分为 35.23,在 LEval 评测上的得分为 35.86。GPT-4和longchat-7b-v1.5-32k的得分摘自 这里 ,Index-1.9B-32K、Qwen2-1.5B-Instruct的得分是我们基于opencompass运行得出。
-
LongBench简介:LongBench是由 THUDM 构建的长文本数据集,由 21 个子任务构成,总计 4750 条测例。该数据集是第一个包含中英双语的长文本数据集,其中英语文本长度平均为 6711 词,中文文本平均长度为 13386 字。
-
LEval简介:LEval是由 OpenLMLab 构建的一个长文本数据集,由 18 个子任务组成,其中包含法律、经济、科技等各个领域的文本。
评测分数对比如下图,我们1.9B尺寸的模型分数甚至远超7B尺寸的模型:

Index-1.9B-32K与GPT-4、Qwen2等模型长文本能力对比
Alignment和短能力评测
虽然Index-1.9B-32K的长文本能力获得极其优异的结果,但短文本能力有所下降。我们使用了基于自建 benchmark 的评测,结果显示模型的“短文本能力”在多个评测指标上均有下降。在自建 benchmark 的评测中,性能下降了约 25%,因此,平衡模型的“长短文本能力”也将是我们未来的一个主要工作。
对 OpenCompass 的优化
在进行长上下文相关的评测时,我们遇到以下问题并进行了优化,这一优化已被 OpenCompass 合并到官方最新仓库,详见 opencompass/commit(https://github.com/open-compass/opencompass/commit/59586a8b4a3e4dc2c24b6e55a3d1074e5fbe10ab?diff=unified&w=0) 。
问题
在评估过程中,序列长度可能会超过模型的 max_seq_len,尤其是在长上下文评估中,这导致两个问题:
-
prompt被截断,只有一部分进入模型,导致关键信息(例如关键问题)丢失,模型无法理解prompt的意图。
-
在继续生成时,总长度超过max_seq_len 并出现以下警告:This is a friendly reminder - the current text generation call will exceed the model’s predefined maximum length (32768). Depending on the model, you may observe exceptions, performance degradation, or nothing at all.
解决方案
保留前 (0.5 * max_prompt_len) 的 tokens 和后 (0.5 * max_prompt_len )的 tokens,丢弃中间部分,因为Prompt中的问题通常位于开头或结尾。
四、其他上下文扩展技术的研究
我们对比了免训练的上下文长度扩展方法,例如 Dynamic NTK 、Naive Extrapolation(直接外推)等。
Dynamic NTK(Neural Tangent Kernel)是一种可用于扩展大模型上下文窗口长度的方法,主要原理是随着上下文长度的变化而动态地调整位置编码,以适应新的上下文长度,该方法不需要进行训练便能达到扩展上下文长度的目的。其中,我们对 Dynamic NTK 使用了多种 scaling factor,本文评测时使用的 scaling factor 为 8。各种技术的长上下文效果对比如下图。

各种Long Context方法的效果对比
五、讨论
-
相比于业界相近尺寸的开源模型,Index-1.9B-32K的长文本性能取得了非常优异的结果。我们也公开了 benchmark 运行代码,可以复现这些评测结果。
-
通过大量研究和实验发现,长文本能力和短文本能力在很多情况下像跷跷板,兼顾两者是一个有趣且具有挑战性的课题。
当然,我们还进行了很多失败的尝试,不完全列举如下。
失败尝试1:上下文长度预热(Context Length Warmup)
我们最初认为 LLM 对文本长度的感知能力应当逐步从短到长提升,因此尝试构建长度递增的数据集并按顺序进行训练。模型的损失(Loss)在初期下降迅速,但随后出现反弹且无法进一步下降。我们推测这可能与数据分布不均有关,后续将对此展开更深入的研究。
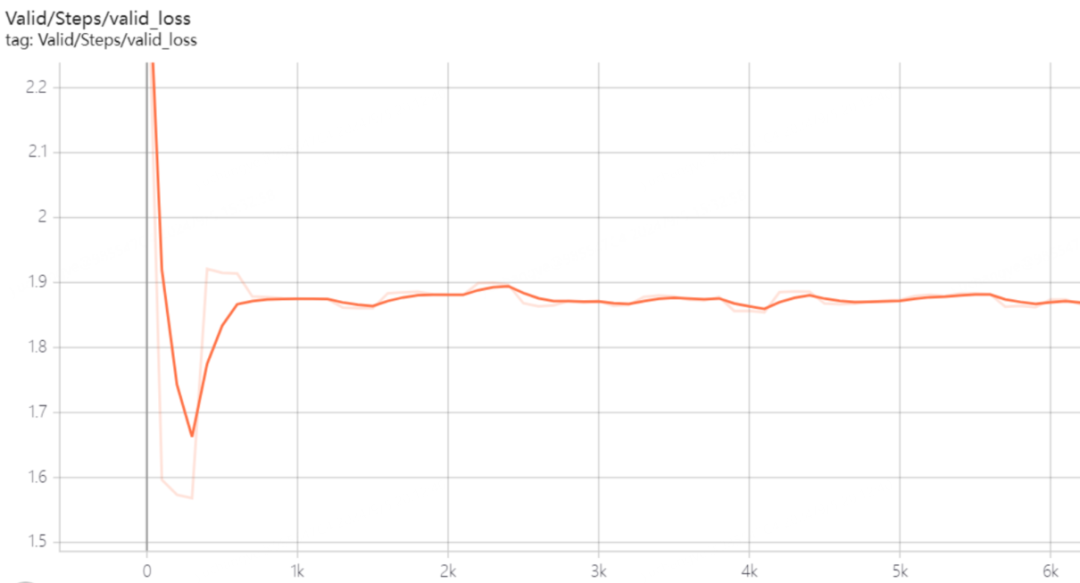
上下文长度预热训练的验证集损失曲线
失败尝试2:Packing VS Non-Packing
我们认为Doc Packing 方式的训练可能会影响梯度下降,特别是在混合不同长度指令时。然而,实验结果显示,两种训练方式的差异极小(小于 1%)。
失败尝试3:1‰ 长指令 SFT
我们注意到 LLaMA 3 的Paper中提到他们只使用了 1‰ 的长指令进行微调,我们对这一结果感到好奇,于是进行了实验,实验结果为负向。
写在最后
本文对我们的长文本大模型(Long Context)工作做了简略介绍,我们仍在持续更新、升级 Long Context 能力,请关注后续进展,欢迎交流。
局限性与免责申明
Index-1.9B-32K在某些情况下可能会产生不准确、有偏见或其他令人反感的内容。模型生成内容时无法理解、表达个人观点或价值判断,其输出内容不代表模型开发者的观点和立场。因此,请谨慎使用模型生成的内容,用户在使用时应自行负责对其进行评估和验证,请勿将生成的有害内容进行传播,且在部署任何相关应用之前,开发人员应根据具体应用对模型进行安全测试和调优。我们强烈警告不要将这些模型用于制造或传播有害信息,或进行任何可能损害公众、国家、社会安全或违反法规的活动,也不要将其用于未经适当安全审查和备案的互联网服务。我们已尽所能确保模型训练数据的合规性,但由于模型和数据的复杂性,仍可能存在无法预见的问题。如果因使用这些模型而产生任何问题,无论是数据安全问题、公共舆论风险,还是因模型被误解、滥用、传播或不合规使用所引发的任何风险和问题,我们将不承担任何责任。
-End-
作者丨Index team


















 825
825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









