







散列表(Hash Table,也叫哈希表),是根据关键码值(key value)而进行直接访问的数据结构。它通过关键码值映射到表中的一个位置来访问记录,以加快访问的速度。这个映射函数叫做散列函数,存放的数组叫做散列表。
例如,关键字为k,则把k放在f(k)的存储位置上。由此,不需要比较便可直接获取所查的记录。f()就是这个散列函数,按这个思想建立的表叫做散列表。
对于不同的关键字,可能得到同一散列地址,即k1 ≠ k2,而f(k1) =f(k2),这种现象成为碰撞(Collision).具有相同的函数值得关键字对该散列函数来说叫做同义词。
综上所述,根据散列函数f(k)和处理碰撞的方法将一组关键字映射到一段有限的连续的地址集上(区间),并以关键字在地址集中的“像”作为记录在表中的从存储位置,这个表叫做散列表,这一映射过程叫做散列造表或者散列,所得的存储地址叫做散列地址。
对于任何一个关键字,经过散列函数映象到地址集合中任何一个地址上的概率是相等的,则称此类散列函数为均匀散列函数,这就是使关键字经过散列函数得到的一个“随机地址”,从而减少碰撞。
实际使用中根据不同的情况来选择相应的散列函数,通常考虑的因素有:
1、计算哈希函数所需时间
2、关键字的长度
3、哈希表的大小
4、关键字的分布情况
5、记录的查找频率
通常有一下几种哈希函数:
1、直接寻址法 :取关键字或关键字的某个线性函数作为散列地址。即H(key)=key或者H(key) = a*key + b,(a,b为常数)(这种散列函数又叫做自身函数)。若其中H(key)中已经有值了,就往下一个找,直到H(key)中没有值了,就放进去。
2、数字分析法:分析一组数据,比如一组员工的出生年月日,这时我们发现出生年月日的前几位数字大体相同,这样的话,出现冲突的几率就会很大,但是我们发现年月日的后几位表示月份和具体日期的数字差别很大,如果用后面的数字来构成散列地址,则冲突的几率会明显降低。因此数字分析法就是找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址。
3、平方取中法 :当无法确定关键字中哪几位分布比较均匀时,可以先求出关键字的平方值,然后按需要取平方值的中间几位作为哈希地址。(原因:平方后中间几位和关键字中的每一位都有关,故不同关键字会以较高的概率产生不同的哈希地址)
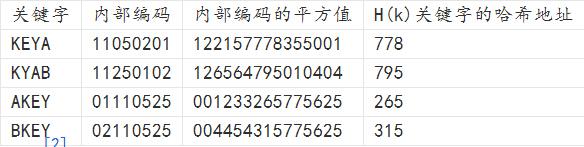
例:我们把英文字母在字母表中的位置序号作为该英文字母的内部编码。例如K的内部编码为11,E的内部编码为05,Y的内部编码为25,A的内部编码为01, B的内部编码为02。由此组成关键字“KEYA”的内部代码为11052501,同理我们可以得到关键字“KYAB”、“AKEY”、“BKEY”的内部编码。之后对关键字进行平方运算后,取出第7到第9位作为该关键字哈希地址,如下图所示
4、折叠法:将关键字分割成位数相同的几部分,最后一部分位数可以不同,然后取这几部分的叠加和(去除进位)作为散列地址。数位叠加可以有移位叠加和间界叠加两种方法。移位叠加是将分割后的每一部分的最低位对齐,然后相加;间界叠加是从一端向另一端沿分割界来回折叠,然后对齐相加。
5、 随机数法:选择一随机函数,取关键字的随机值作为散列地址,通常用于关键字长度不同的场合。
6、 除留余数法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即 H(key) = key MOD p,p<=m。不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模。对p的选择很重要,一般取素数或m,若p选的不好,容易产生同义词。(下边代码就用的此方法,冲突解决用的是线性探测再散列)
处理冲突的几种方法:
1、 开放寻址法:Hi=(H(key) + di) MOD m,i=1,2,…,k(k<=m-1),其中H(key)为散列函数,m为散列表长,di为增量序列,可有下列三种取法:
1.1. di=1,2,3,…,m-1,称线性探测再散列;
1.2. di=1^2,-1^2,2^2,-2^2,⑶^2,…,±(k)^2,(k<=m/2)称二次探测再散列;
1.3. di=伪随机数序列,称伪随机探测再散列。
2、 再散列法:Hi=RHi(key),i=1,2,…,k RHi均是不同的散列函数,即在同义词产生地址冲突时计算另一个散列函数地址,直到冲突不再发生,这种方法不易产生“聚集”,但增加了计算时间。
3、 链地址法(拉链法)
4、 建立一个公共溢出区
下边简单的实现了一下哈希表的插入,删除,查找
HashTable.h
#include<iostream>
using namespace std;
enum FlagType
{
FLAG_DATA, //已经有元素
FLAG_DELETED, //已经删除
FLAG_EMPTY, //没有元素,空
};
template<class KEY>
class HashTable
{
private:
KEY* _arr; //数组
FlagType* _flag; //元素标志
int _count; //当前数据已有元素个数
int _size; //Hash表大小
int _prime; //质数
int _cur; //当前地址,线性探测再哈希用
public:
HashTable(int table_size,int prime) //构造函数
{
_size = table_size;
_count = 0;
_prime = prime;
_arr = new KEY[_size];
_flag = new FlagType[_size];
for (int i = 0; i < _size; i++)
{
_flag[i] = FLAG_EMPTY;
}
}
~HashTable()
{
delete[] _arr;
delete[] _flag;
}
void Clear()
{
for (int i = 0; i < _size; i++)
{
_flag[i] = FLAG_EMPTY;
}
_count = 0;
}
int Hash(const KEY key) //哈希函数 除留余数法
{
_cur = key % _prime;
return _cur;
}
int LinearProbe() //线性探测再哈希获得下一地址
{
_cur = (_cur + 1) % _size;
return _cur;
}
int Search_Hash(const KEY& key)
{
int i = Hash(key);
int firstIndex = i;
while (1)
{
if (FLAG_EMPTY == _flag[i])
{
return -1;
}
if (FLAG_DATA == _flag[i] && key == _arr[i])// 如果找到,并且打印
{
cout <<"key = "<<i<< " value = "<< _arr[i] << endl;
return i;
}
i = LinearProbe();
if (i == firstIndex)
{
break;
}
}
return -1;
}
bool Insert_Hash(KEY key)
{
int i = Hash(key);//根据key获得初始哈希地址
int firstIndex = i;
while (1)
{
if (FLAG_EMPTY == _flag[i] || FLAG_DELETED == _flag[i])
{
_flag[i] = FLAG_DATA;
_arr[i] = key;
_count++;
return true;
}
i = LinearProbe();
if (i == firstIndex)
{
break;
}
}
return false;
}
bool Delete_Hash(const KEY& key)
{
int i = Search_Hash(key);
if (i != -1)
{
_flag[i] = FLAG_EMPTY;
_count--;
return true;
}
return false;
}
int GetElementCount()
{
return _count;
}
int GetSize()
{
return _size;
}
void Display()
{
int i = 0;
int data = 0;
FlagType flag;
cout << "HashTable_Length: " << GetSize() <<endl<< "HashTable_Content: " << endl;
if (0 == GetElementCount())
{
cout << "Empty!" << endl << endl;
return;
}
for (int i = 0; i < GetSize(); i++)
{
flag = _flag[i];
if (flag == FLAG_DATA)
{
data = _arr[i];
cout << "arr[" << i << "]=" << data <<" ";
}
else
{
if (flag == FLAG_DELETED)
{
cout << "arr[" << i << "]=delete ";
}
else
{
cout << "arr[" << i << "]=NULL ";
}
}
if (4 == (i % 5))
{
cout << endl;
}
}
cout << endl;
return;
}
};
下边是测试用例
#include"HashTable.h"
void Test()
{
HashTable<int> hs(30,11);
hs.Insert_Hash(23);
hs.Insert_Hash(36);
hs.Insert_Hash(34);
hs.Insert_Hash(45);
hs.Insert_Hash(63);
hs.Insert_Hash(1);
hs.Insert_Hash(67);
hs.Insert_Hash(28);
hs.Insert_Hash(29);
hs.Insert_Hash(0);
hs.Insert_Hash(5);
hs.Insert_Hash(65);
hs.Insert_Hash(31);
hs.Insert_Hash(52);
hs.Insert_Hash(75);
hs.Insert_Hash(87);
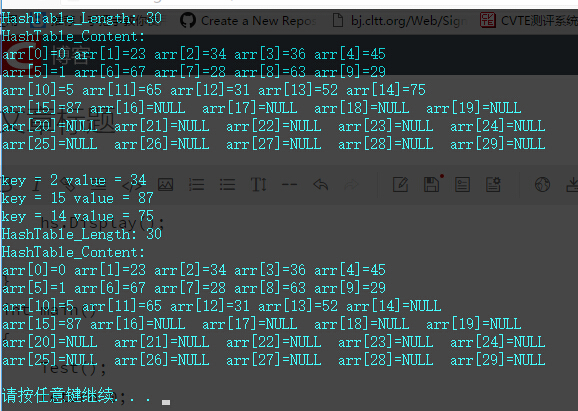
hs.Display();
hs.Search_Hash(34);
hs.Search_Hash(87);
hs.Delete_Hash(75);
hs.Display();
}
int main()
{
Test();
return 0;
}程序运行结果截图:















 2300
2300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









