







一、将数据读取进入Python中,并对数据进行处理
这个地方使用了DataFrame.rest_index(),其用法如下:
DataFrame.reset_index(level=None, drop=False,inplace=False, col_level=0, col_fill="")
1、重置DataFrame的索引,并使用默认索引。
2、如果DataFrame有多个行索引,则此方法可以删除一个或多个行索引级别,可以让行索引变成列。
3、参数说明
level:只从行索引中删除给定的索引级别,默认情况下删除所有级别。level是原始df的index的层级,可用数字/名称表示。用数字表示的时候,0代表第一级行索引,1代表第二级行索引,以此类推。
drop:True/False 表示释放出来的行索引,变成列之后,是否要删除。
col_level:将释放出来的行索引作为列,插入到指定的列级别位置,默认情况下,它被插入到第一层。col_level表示列的层级。
col_fill:将释放出来的行索引作为列,插入到指定的列级别位置,并且给该列设置列名,如果没有设置,则重复其行索引名。
df11=df1.groupby(['花色','盎司']).agg({'订单数':sum,'销售额':sum,'销售额(订单金额)':sum,'销量':sum}).reset_index(drop=False)
print(df11.head())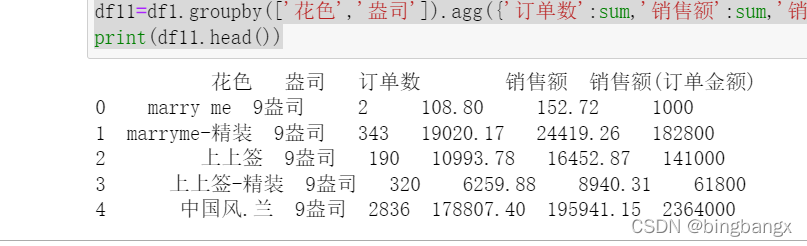
二、按销量进行排序
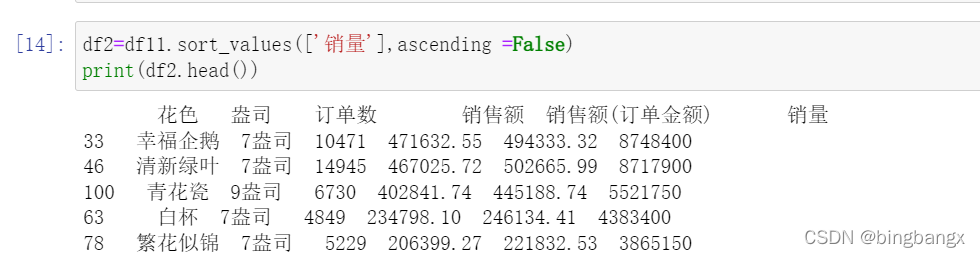
三、提取销量前**的花色,并生成列表

四、抓取前**花色的销售数据
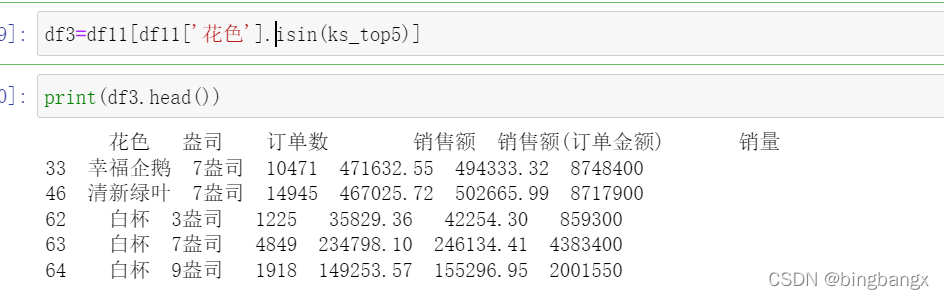
五、处理完毕,保存结果
df3.to_excel('hs.xlsx',index=False)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









