






哈夫曼编码压缩及解压文件(C语言及Java实现)
设计说明
哈夫曼编码作为压缩里面的无损压缩,还是很经典的;在数据结构中树章节,哈夫曼树的主要应用也是作为最小生成树来编码内容,来达到压缩的效果
以较为简单的压缩文本开始,到后面进行文件IO操作,来压缩及解压文件(包括文本文件与图片文件等)
在C语言实现的过程中遇到了问题,所以有好几版代码,可以直接下载最新的代码,贴在文章中的不是最好的代码,是有bug的
实现说明
实现思路:
1、获取文本编码的频率,得到Map集合,后通过哈夫曼树生成算法,生成哈夫曼树(生成哈夫曼树的算法其实很简单,就重复两个步骤,排序,取前面最小的两个结点的组成一个新的结点,删除选择的两个结点,添加新生成的结点,重复这个过程,直到只剩下最后一个节点,即生成好了哈夫曼树)
2、通过哈夫曼树得到哈夫曼编码,然后采用哈夫曼编码对文本字节数组进行转化为二进制字符串,然后再转化为新的字节数组
3、得到相应的解压编码,然后根据压缩后的字节数组还原得到编码的二进制串,还原为原来的字符即可
Java实现的简单文本压缩及解压
步骤与上述说明的一致,代码函数命名较为清晰,就没有写注释了,相信是可以看的明白的
package test;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
/**
* @author bbyh
* @date 2023/4/5 0005 21:46
* @description
*/
public class Hoffman {
private static final HashMap<Byte, String> ENCODE_MAP = new HashMap<>();
private static final HashMap<String, Byte> DECODE_MAP = new HashMap<>();
private static Integer LENGTH_OF_BIT;
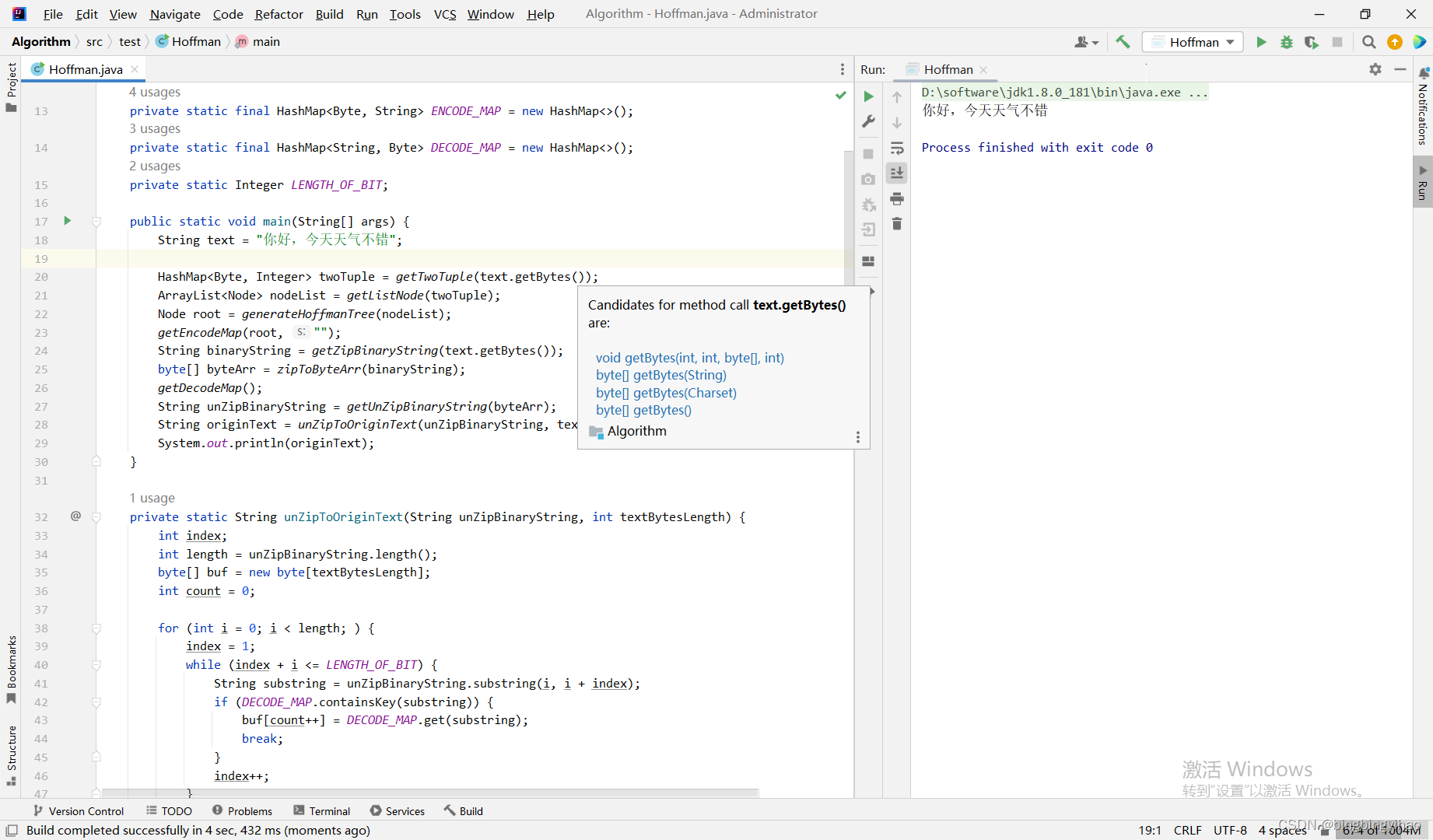
public static void main(String[] args) {
String text = "你好,今天天气不错";
HashMap<Byte, Integer> twoTuple = getTwoTuple(text.getBytes());
ArrayList<Node> nodeList = getListNode(twoTuple);
Node root = generateHoffmanTree(nodeList);
getEncodeMap(root, "");
String binaryString = getZipBinaryString(text.getBytes());
byte[] byteArr = zipToByteArr(binaryString);
getDecodeMap();
String unZipBinaryString = getUnZipBinaryString(byteArr);
String originText = unZipToOriginText(unZipBinaryString, text.getBytes().length);
System.out.println(originText);
}
private static String unZipToOriginText(String unZipBinaryString, int textBytesLength) {
int index;
int length = unZipBinaryString.length();
byte[] buf = new byte[textBytesLength];
int count = 0;
for (int i = 0; i < length; ) {
index = 1;
while (index + i <= LENGTH_OF_BIT) {
String substring = unZipBinaryString.substring(i, i + index);
if (DECODE_MAP.containsKey(substring)) {
buf[count++] = DECODE_MAP.get(substring);
break;
}
index++;
}
i += index;
}
return new String(buf);
}
private static String getUnZipBinaryString(byte[] byteArr) {
StringBuilder builder = new StringBuilder();
for (byte b : byteArr) {
builder.append(Integer.toBinaryString((b & 0xFF) + 0x100).substring(1));
}
return builder.toString();
}
private static void getDecodeMap() {
for (Byte b : ENCODE_MAP.keySet()) {
DECODE_MAP.put(ENCODE_MAP.get(b), b);
}
}
private static byte[] zipToByteArr(String byteString) {
LENGTH_OF_BIT = byteString.length();
StringBuilder byteStringBuilder = new StringBuilder(byteString);
for (int i = 0; i < byteStringBuilder.length() % 8; i++) {
byteStringBuilder.append("0");
}
byteString = byteStringBuilder.toString();
int length = byteString.length();
int index = 0;
byte[] byteArr = new byte[length / 8];
while (index < byteArr.length) {
byteArr[index] = (byte) (Integer.parseInt(byteString.substring(8 * index, 8 * (index + 1)), 2));
index++;
}
return byteArr;
}
private static String getZipBinaryString(byte[] bytes) {
StringBuilder builder = new StringBuilder();
for (byte b : bytes) {
builder.append(ENCODE_MAP.get(b));
}
return builder.toString();
}
private static void getEncodeMap(Node root, String s) {
if (root == null) {
return;
} else if (root.left == null && root.right == null) {
ENCODE_MAP.put(root.data, s);
}
if (root.left != null) {
getEncodeMap(root.left, s + "0");
}
if (root.right != null) {
getEncodeMap(root.right, s + "1");
}
}
private static Node generateHoffmanTree(ArrayList<Node> nodeList) {
while (nodeList.size() > 1) {
Collections.sort(nodeList);
Node leftNode = nodeList.get(0);
Node rightNode = nodeList.get(1);
Node root = new Node(null, leftNode.value + rightNode.value);
root.left = leftNode;
root.right = rightNode;
nodeList.remove(1);
nodeList.remove(0);
nodeList.add(root);
}
return nodeList.get(0);
}
private static ArrayList<Node> getListNode(HashMap<Byte, Integer> twoTuple) {
ArrayList<Node> nodeList = new ArrayList<>();
for (Byte b : twoTuple.keySet()) {
Node node = new Node(b, twoTuple.get(b));
nodeList.add(node);
}
return nodeList;
}
private static HashMap<Byte, Integer> getTwoTuple(byte[] bytes) {
HashMap<Byte, Integer> twoTuple = new HashMap<>();
for (byte b : bytes) {
if (twoTuple.containsKey(b)) {
twoTuple.replace(b, twoTuple.get(b) + 1);
} else {
twoTuple.put(b, 1);
}
}
return twoTuple;
}
static class Node implements Comparable<Node> {
Byte data;
int value;
Node left;
Node right;
public Node(Byte data, int value) {
this.data = data;
this.value = value;
}
@Override
public String toString() {
return "Node{" +
"data=" + data +
", value=" + value +
'}';
}
@Override
public int compareTo(Node o) {
return this.value - o.value;
}
}
}
演示效果:
英文肯定更没问题
Java的文件压缩及解压
在明白了上述文本的压缩,实际文件的压缩和解压也是一致的,都可以转化为byte数组
只是需要添加一些文件IO的操作
package test;
import java.io.*;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
/**
* @author bbyh
* @date 2023/4/5 0005 21:46
* @description
*/
public class Hoffman {
private static final HashMap<Byte, String> ENCODE_MAP = new HashMap<>();
private static final HashMap<String, Byte> DECODE_MAP = new HashMap<>();
private static Integer LENGTH_OF_BIT;
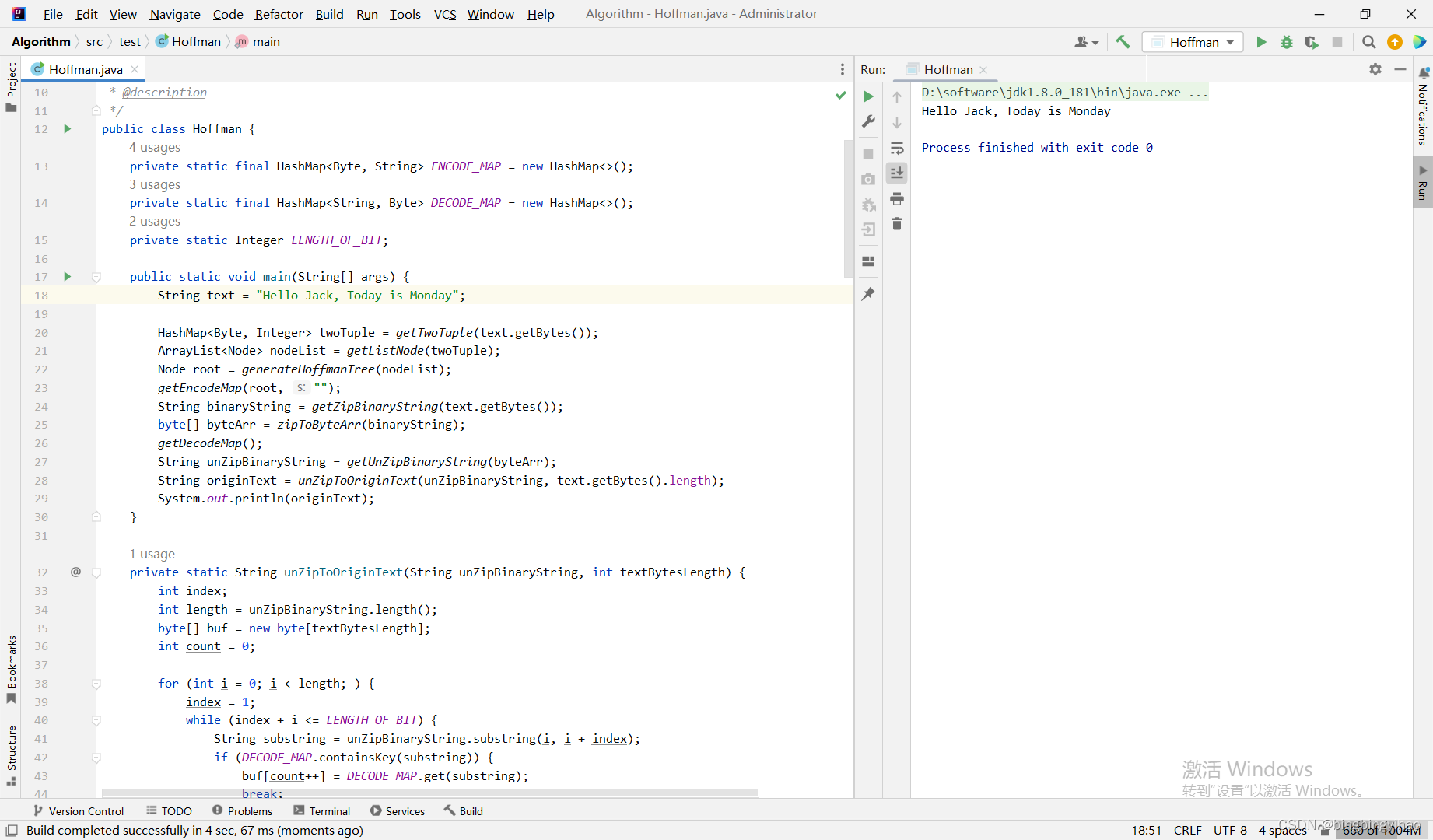
public static void main(String[] args) {
String originFileName = "D:/test.txt";
byte[] textBytes = getBytesFromFile(originFileName);
if (textBytes == null) {
System.out.println("当前字节数组为空,无法压缩与解压");
return;
}
HashMap<Byte, Integer> twoTuple = getTwoTuple(textBytes);
ArrayList<Node> nodeList = getListNode(twoTuple);
Node root = generateHoffmanTree(nodeList);
getEncodeMap(root, "");
String binaryString = getZipBinaryString(textBytes);
byte[] byteArr = zipToByteArr(binaryString);
String zipFileName = "D:/test.myZip";
generateZipFile(zipFileName, byteArr);
getDecodeMap();
String unZipBinaryString = getUnZipBinaryString(byteArr);
String unZipFileName = "D:/test1.txt";
unZipToOriginText(unZipBinaryString, textBytes.length, unZipFileName);
System.out.println("压缩与解压完成");
}
private static void generateZipFile(String zipFileName, byte[] byteArr) {
try (FileOutputStream outputStream = new FileOutputStream(zipFileName)) {
outputStream.write(byteArr);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private static byte[] getBytesFromFile(String originFileName) {
File file = new File(originFileName);
if (!file.exists()) {
return null;
}
try (FileInputStream inputStream = new FileInputStream(originFileName)) {
int available = inputStream.available();
byte[] buf = new byte[available];
inputStream.read(buf);
return buf;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private static void unZipToOriginText(String unZipBinaryString, int textBytesLength, String unZipFileName) {
int index;
int length = unZipBinaryString.length();
byte[] buf = new byte[textBytesLength];
int count = 0;
for (int i = 0; i < length; ) {
index = 1;
while (index + i <= LENGTH_OF_BIT) {
String substring = unZipBinaryString.substring(i, i + index);
if (DECODE_MAP.containsKey(substring)) {
buf[count++] = DECODE_MAP.get(substring);
break;
}
index++;
}
i += index;
}
try (FileOutputStream outputStream = new FileOutputStream(unZipFileName)) {
outputStream.write(buf);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private static String getUnZipBinaryString(byte[] byteArr) {
StringBuilder builder = new StringBuilder();
for (byte b : byteArr) {
builder.append(Integer.toBinaryString((b & 0xFF) + 0x100).substring(1));
}
return builder.toString();
}
private static void getDecodeMap() {
for (Byte b : ENCODE_MAP.keySet()) {
DECODE_MAP.put(ENCODE_MAP.get(b), b);
}
}
private static byte[] zipToByteArr(String byteString) {
LENGTH_OF_BIT = byteString.length();
StringBuilder byteStringBuilder = new StringBuilder(byteString);
for (int i = 0; i < byteStringBuilder.length() % 8; i++) {
byteStringBuilder.append("0");
}
byteString = byteStringBuilder.toString();
int length = byteString.length();
int index = 0;
byte[] byteArr = new byte[length / 8];
while (index < byteArr.length) {
byteArr[index] = (byte) (Integer.parseInt(byteString.substring(8 * index, 8 * (index + 1)), 2));
index++;
}
return byteArr;
}
private static String getZipBinaryString(byte[] bytes) {
StringBuilder builder = new StringBuilder();
for (byte b : bytes) {
builder.append(ENCODE_MAP.get(b));
}
return builder.toString();
}
private static void getEncodeMap(Node root, String s) {
if (root == null) {
return;
} else if (root.left == null && root.right == null) {
ENCODE_MAP.put(root.data, s);
}
if (root.left != null) {
getEncodeMap(root.left, s + "0");
}
if (root.right != null) {
getEncodeMap(root.right, s + "1");
}
}
private static Node generateHoffmanTree(ArrayList<Node> nodeList) {
while (nodeList.size() > 1) {
Collections.sort(nodeList);
Node leftNode = nodeList.get(0);
Node rightNode = nodeList.get(1);
Node root = new Node(null, leftNode.value + rightNode.value);
root.left = leftNode;
root.right = rightNode;
nodeList.remove(1);
nodeList.remove(0);
nodeList.add(root);
}
return nodeList.get(0);
}
private static ArrayList<Node> getListNode(HashMap<Byte, Integer> twoTuple) {
ArrayList<Node> nodeList = new ArrayList<>();
for (Byte b : twoTuple.keySet()) {
Node node = new Node(b, twoTuple.get(b));
nodeList.add(node);
}
return nodeList;
}
private static HashMap<Byte, Integer> getTwoTuple(byte[] bytes) {
HashMap<Byte, Integer> twoTuple = new HashMap<>();
for (byte b : bytes) {
if (twoTuple.containsKey(b)) {
twoTuple.replace(b, twoTuple.get(b) + 1);
} else {
twoTuple.put(b, 1);
}
}
return twoTuple;
}
static class Node implements Comparable<Node> {
Byte data;
int value;
Node left;
Node right;
public Node(Byte data, int value) {
this.data = data;
this.value = value;
}
@Override
public String toString() {
return "Node{" +
"data=" + data +
", value=" + value +
'}';
}
@Override
public int compareTo(Node o) {
return this.value - o.value;
}
}
}
压缩文本文件演示
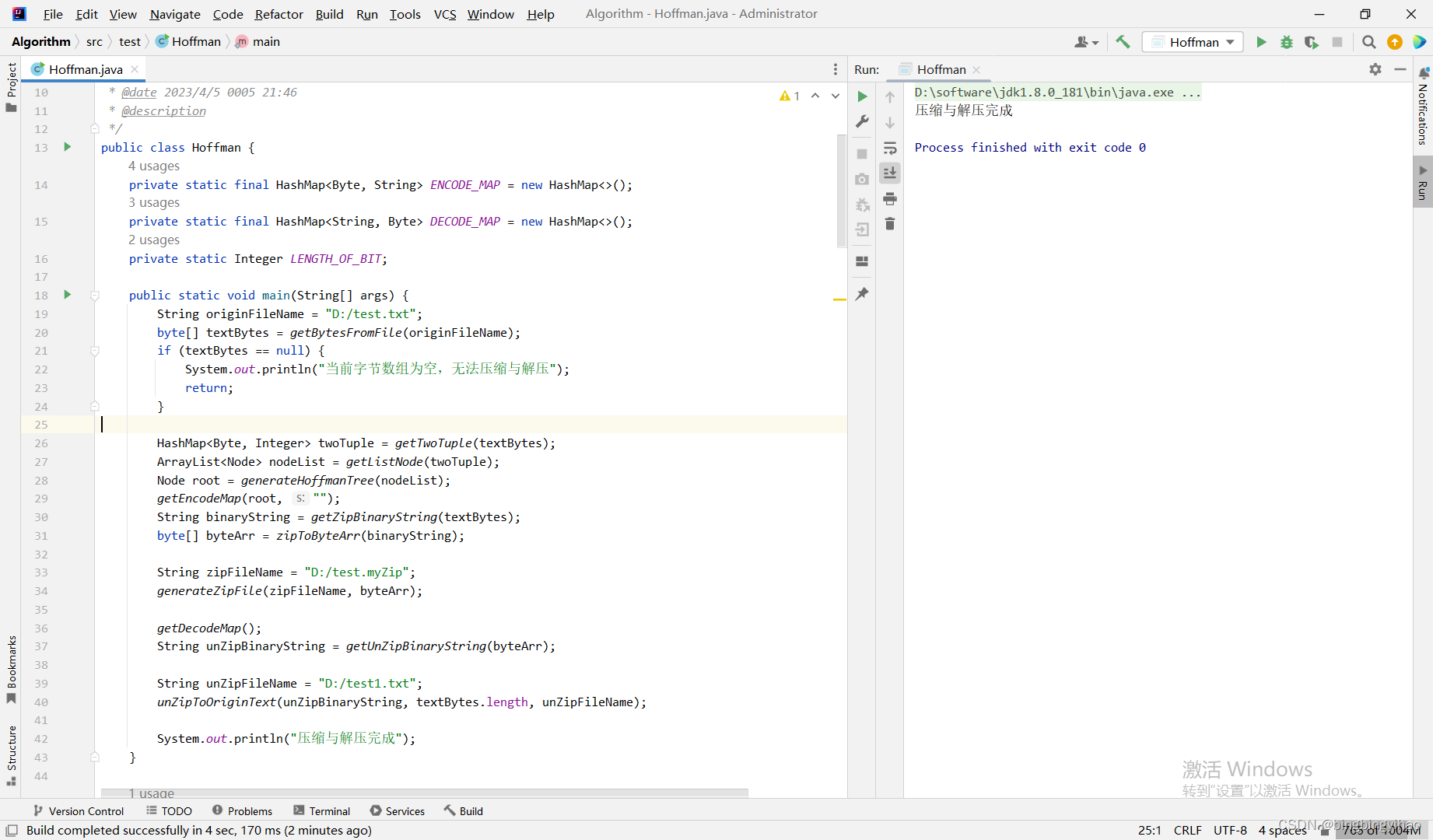
压缩图片文件演示
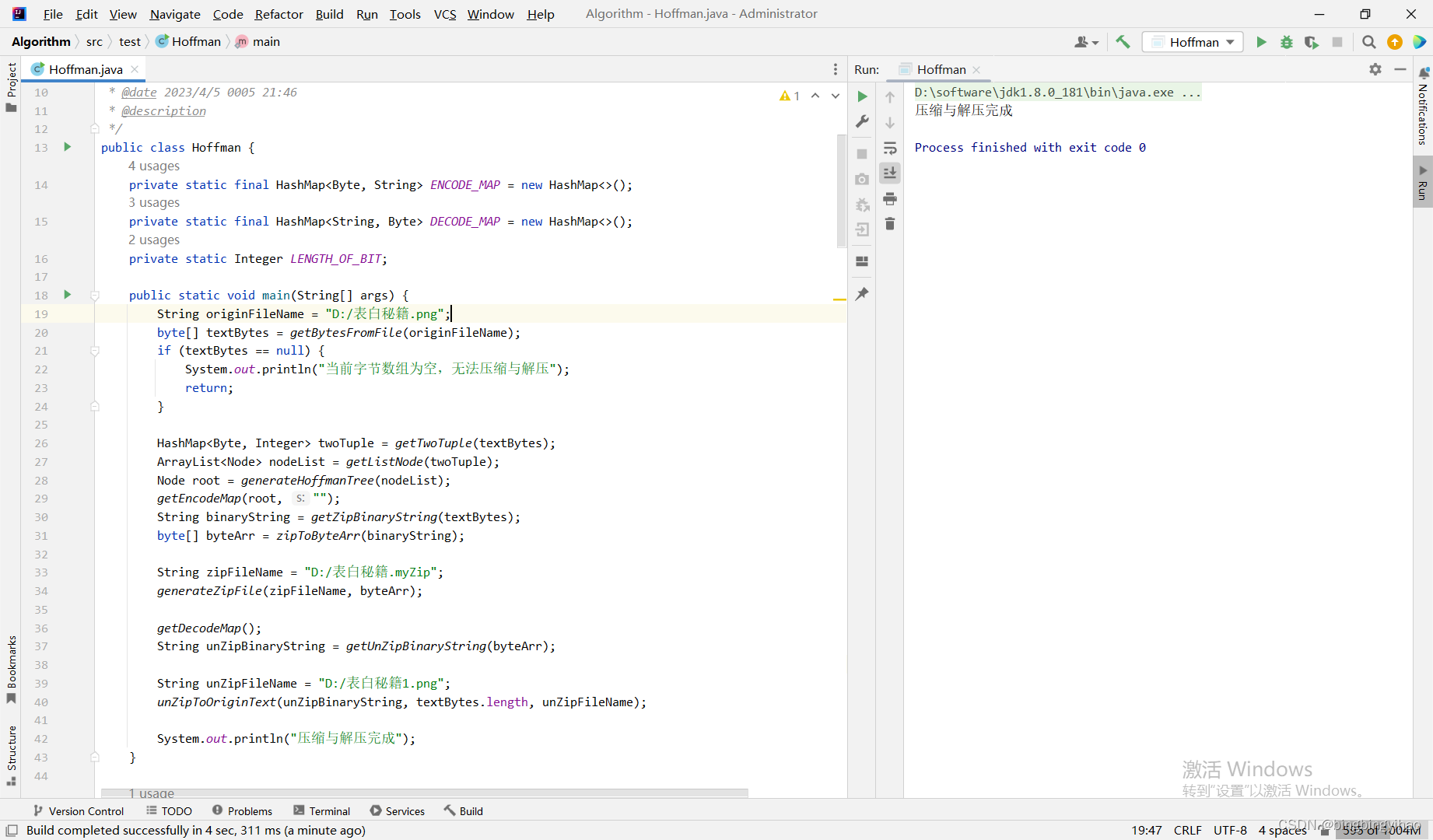
压缩音频文件演示(直接堆内存溢出了,说明算法是有问题的,需要改进,不能单纯的用字符串进行运算;但也不是每次都会堆溢出,但发现的新问题就是压缩率不高,且压缩效率较慢)
Java带界面的文件压缩与解压
前面两个文件的压缩与解压都只是演示,并不是正常的完整流程,正常流程中,压缩的文件内是需要将encodeMap一同写入的,然后解压的时候再读出来
下面是完整流程代码
package test;
import javax.swing.*;
import java.awt.*;
import java.io.*;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
/**
* @author bbyh
* @date 2023/4/5 0005 23:40
* @description
*/
public class HoffmanMainFrame extends JFrame {
private static Zip zip = new Zip();
public HoffmanMainFrame(String title) {
setTitle(title);
setSize(500, 200);
setLocationRelativeTo(null);
setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
setLayout(null);
Font font = new Font("楷体", Font.BOLD, 20);
JLabel label = new JLabel("暂未选择文件", SwingConstants.CENTER);
JButton chooseFile = new JButton("选择文件");
JButton zip = new JButton("压缩");
JButton unZip = new JButton("解压");
add(label);
add(chooseFile);
add(zip);
add(unZip);
label.setFont(font);
chooseFile.setFont(font);
zip.setFont(font);
unZip.setFont(font);
label.setBounds(30, 20, 440, 40);
chooseFile.setBounds(40, 100, 120, 40);
zip.setBounds(180, 100, 120, 40);
unZip.setBounds(320, 100, 120, 40);
chooseFile.addActionListener(e -> {
JFileChooser fileChooser = new JFileChooser(new File("D:\\"));
fileChooser.setFileSelectionMode(JFileChooser.FILES_AND_DIRECTORIES);
fileChooser.showOpenDialog(null);
File selectedFile = fileChooser.getSelectedFile();
label.setText(selectedFile.getAbsolutePath());
});
zip.addActionListener(e -> {
String originFileName = label.getText();
byte[] textBytes = getBytesFromFile(originFileName);
if (textBytes == null) {
JOptionPane.showMessageDialog(null, "当前字节数组为空,无法压缩");
return;
}
HashMap<Byte, Integer> twoTuple = getTwoTuple(textBytes);
ArrayList<Node> nodeList = getListNode(twoTuple);
Node root = generateHoffmanTree(nodeList);
getEncodeMap(root, "");
String binaryString = getZipBinaryString(textBytes);
byte[] byteArr = zipToByteArr(binaryString);
String zipFileName = originFileName.substring(0, originFileName.lastIndexOf(".")) + ".myZip";
generateZipFile(zipFileName, byteArr);
JOptionPane.showMessageDialog(null, "压缩完成");
});
unZip.addActionListener(e -> {
String originFileName = label.getText();
String zipFileName = originFileName.substring(0, originFileName.lastIndexOf(".")) + ".myZip";
String unZipBinaryString = getUnZipBinaryString(zipFileName);
String unZipFileName = "D:/test1.txt";
unZipToOriginText(unZipBinaryString, unZipFileName);
JOptionPane.showMessageDialog(null, "解压完成");
});
}
public static void main(String[] args) {
new HoffmanMainFrame("哈夫曼压缩与解压工具").setVisible(true);
}
static class Zip implements Serializable {
private static final long serialVersionUID = 1L;
HashMap<Byte, String> encodeMap = new HashMap<>();
final HashMap<String, Byte> decodeMap = new HashMap<>();
Integer lengthOfBit;
Integer lengthOfTextBytes;
}
static class Node implements Comparable<Node> {
Byte data;
int value;
Node left;
Node right;
public Node(Byte data, int value) {
this.data = data;
this.value = value;
}
@Override
public String toString() {
return "Node{" +
"data=" + data +
", value=" + value +
'}';
}
@Override
public int compareTo(Node o) {
return this.value - o.value;
}
}
private static void unZipToOriginText(String unZipBinaryString, String unZipFileName) {
int index;
int length = unZipBinaryString.length();
byte[] buf = new byte[zip.lengthOfTextBytes];
int count = 0;
for (int i = 0; i < length; ) {
index = 1;
while (index + i <= zip.lengthOfBit) {
String substring = unZipBinaryString.substring(i, i + index);
if (zip.decodeMap.containsKey(substring)) {
buf[count++] = zip.decodeMap.get(substring);
break;
}
index++;
}
i += index;
}
try (FileOutputStream outputStream = new FileOutputStream(unZipFileName)) {
outputStream.write(buf);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private static String getUnZipBinaryString(String zipFileName) {
try (FileInputStream inputStream = new FileInputStream(zipFileName)) {
ObjectInputStream objectInputStream = new ObjectInputStream(inputStream);
zip = (Zip) objectInputStream.readObject();
zip.decodeMap.clear();
for (Byte b : zip.encodeMap.keySet()) {
zip.decodeMap.put(zip.encodeMap.get(b), b);
}
byte[] buf = new byte[(zip.lengthOfBit + 7) / 8];
System.out.println(inputStream.read(buf));
StringBuilder builder = new StringBuilder();
for (byte b : buf) {
builder.append(Integer.toBinaryString((b & 0xFF) + 0x100).substring(1));
}
return builder.toString();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
private static void generateZipFile(String zipFileName, byte[] byteArr) {
try (FileOutputStream outputStream = new FileOutputStream(zipFileName)) {
ObjectOutputStream objectOutputStream = new ObjectOutputStream(outputStream);
objectOutputStream.writeObject(zip);
outputStream.write(byteArr);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private static byte[] getBytesFromFile(String originFileName) {
File file = new File(originFileName);
if (!file.exists()) {
return null;
}
try (FileInputStream inputStream = new FileInputStream(originFileName)) {
int available = inputStream.available();
zip.lengthOfTextBytes = available;
byte[] buf = new byte[available];
System.out.println(inputStream.read(buf));
return buf;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private static byte[] zipToByteArr(String byteString) {
zip.lengthOfBit = byteString.length();
StringBuilder byteStringBuilder = new StringBuilder(byteString);
for (int i = 0; i < byteStringBuilder.length() % 8; i++) {
byteStringBuilder.append("0");
}
byteString = byteStringBuilder.toString();
int length = byteString.length();
int index = 0;
byte[] byteArr = new byte[length / 8];
while (index < byteArr.length) {
byteArr[index] = (byte) (Integer.parseInt(byteString.substring(8 * index, 8 * (index + 1)), 2));
index++;
}
return byteArr;
}
private static String getZipBinaryString(byte[] bytes) {
StringBuilder builder = new StringBuilder();
for (byte b : bytes) {
builder.append(zip.encodeMap.get(b));
}
return builder.toString();
}
private static void getEncodeMap(Node root, String s) {
if (root == null) {
return;
} else if (root.left == null && root.right == null) {
zip.encodeMap.put(root.data, s);
return;
}
if (root.left != null) {
getEncodeMap(root.left, s + "0");
}
if (root.right != null) {
getEncodeMap(root.right, s + "1");
}
}
private static Node generateHoffmanTree(ArrayList<Node> nodeList) {
while (nodeList.size() > 1) {
Collections.sort(nodeList);
Node leftNode = nodeList.get(0);
Node rightNode = nodeList.get(1);
Node root = new Node(null, leftNode.value + rightNode.value);
root.left = leftNode;
root.right = rightNode;
nodeList.remove(1);
nodeList.remove(0);
nodeList.add(root);
}
return nodeList.get(0);
}
private static ArrayList<Node> getListNode(HashMap<Byte, Integer> twoTuple) {
ArrayList<Node> nodeList = new ArrayList<>();
for (Byte b : twoTuple.keySet()) {
Node node = new Node(b, twoTuple.get(b));
nodeList.add(node);
}
return nodeList;
}
private static HashMap<Byte, Integer> getTwoTuple(byte[] bytes) {
HashMap<Byte, Integer> twoTuple = new HashMap<>();
for (byte b : bytes) {
if (twoTuple.containsKey(b)) {
twoTuple.replace(b, twoTuple.get(b) + 1);
} else {
twoTuple.put(b, 1);
}
}
return twoTuple;
}
}
演示效果
C语言的压缩及解压
与Java类似的步骤;但是不一样的是,C语言的文件读写功能有许多点需要自己实现及注意
主要是读写文件的二进制读写问题
# include <iostream>
# include <stdlib.h>
# include <stdio.h>
# include <string.h>
# include <sys/stat.h>
# include <algorithm>
# include <vector>
# include <map>
using namespace std;
// 读取文件得到int数组转化成哈夫曼编码得到哈夫曼树,进行压缩与解压
typedef int elementType;
struct Node
{
elementType data;
int value;
Node* left;
Node* right;
};
struct Zip
{
string originFileName;
string destFileName; // 压缩生成的文件名
elementType* buff = NULL; // 读入的文件字符数据
map<elementType, int> twoTuple; // 字符串转化为二元组形式,表示各个字符出现的频率
map<elementType, string> encodeMap; // 由哈夫曼树生成的编码表
string res; // 生成的二进制编码字符串
int size = 0; // 所占字节数
int zipSize = 0; // 所占比特数(用于处理末尾数字补全)
};
struct UnZip
{
string originFileName; // 要解压的文件名
string destFileName; // 解压生成的文件名
int zipSize = 0; // 所占比特数
map<string, elementType> decodeMap;
};
// 将int数组转化为二元组形式,表示各个int数字出现的频率
map<elementType, int> getList(int* text, int length);
//自定义排序函数
bool cmp(const Node* node1, const Node* node2);
// 通过二元组创建哈夫曼树
Node* createHafumanTree(vector<Node*> list);
// 获取编码
void getCodes(Node* root, string path, map<elementType, string>& encodeMap);
// 读取文件内容,得到int数组
elementType* readFile(string fileName, int& size);
// 根据编码表将int数组转化为新的编码
string transform(elementType* buff, int length, map<elementType, string> encodeMap);
// 获取文件生成的二进制编码字符串
void generateCodes(Zip& zip);
//将传入的二进制字符串转换成十进制,并返回十进制数字
int binToTen(string binaryString);
// 将新编码字符串转化为int数组(转化采用末尾不够补0),减少占用空间,并写入文件中,返回文件比特数
void zipFile(string res, string fileName, int& zipSize);
//将传入的int转换成二进制字符串
string intToBin(int ch);
// 根据编码表将文件还原
void unZipFile(string originFileName, string destFileName, int size, map<string, elementType> decodeMap);
int main()
{
Zip zip;
UnZip unZip;
zip.originFileName = "D:/test.txt";
zip.destFileName = "D:/test.myZip";
generateCodes(zip);
zipFile(zip.res, zip.destFileName, zip.zipSize);
unZip.zipSize = zip.zipSize;
unZip.originFileName = zip.destFileName;
unZip.destFileName = "D:/test1.txt";
for (auto& it : zip.encodeMap)
{
unZip.decodeMap.insert(map<string, char>::value_type(it.second, it.first));
}
unZipFile(unZip.originFileName, unZip.destFileName, unZip.zipSize, unZip.decodeMap);
system("pause");
}
map<elementType, int> getList(int* text, int length)
{
map<elementType, int> map;
for (int i = 0; i < length; i++)
{
if (map.count((int)text[i]) == 1)
{
map[text[i]] = map[text[i]] + 1;
}
else
{
map[text[i]] = 1;
}
}
return map;
}
bool cmp(const Node* node1, const Node* node2)
{
return node1->value > node2->value;
}
Node* createHafumanTree(vector<Node*> list)
{
while (list.size() > 1)
{
sort(list.begin(), list.end(), cmp);
Node* left = list.at(list.size() - 1);
Node* right = list.at(list.size() - 2);
Node* node = (Node*)malloc(sizeof(Node));
if (node == NULL)
{
cout << "内存不足" << endl;
return NULL;
}
node->value = left->value + right->value;
node->left = left;
node->right = right;
list.pop_back();
list.pop_back();
list.push_back(node);
}
return list.at(0);
}
void getCodes(Node* root, string path, map<elementType, string>& encodeMap)
{
if (root == NULL)
{
return;
}
if (root->left == NULL && root->right == NULL)
{
encodeMap.insert(map<elementType, string>::value_type(root->data, path));
}
getCodes(root->left, path + "0", encodeMap);
getCodes(root->right, path + "1", encodeMap);
}
elementType* readFile(string fileName, int& size)
{
struct stat buf;
stat(fileName.c_str(), &buf);
size = buf.st_size;
FILE* fp = NULL;
int* buff = new int[buf.st_size];
errno_t err;
if ((err = fopen_s(&fp, fileName.c_str(), "rb")) != 0)
{
cout << "文件打开失败" << endl;
return NULL;
}
int index = 0;
while (index < buf.st_size)
{
buff[index++] = fgetc(fp);
}
fclose(fp);
return buff;
}
string transform(elementType* buff, int length, map<elementType, string> encodeMap)
{
string res = "";
for (int i = 0; i < length; i++)
{
res += encodeMap[buff[i]];
}
return res;
}
void generateCodes(Zip& zip)
{
zip.buff = readFile(zip.originFileName, zip.size);
zip.twoTuple = getList(zip.buff, zip.size);
vector<Node*> list;
for (auto& it : zip.twoTuple)
{
Node* node = (Node*)malloc(sizeof(Node));
if (node == NULL)
{
cout << "内存不足" << endl;
return;
}
node->data = it.first;
node->value = it.second;
node->left = NULL;
node->right = NULL;
list.push_back(node);
}
Node* root = createHafumanTree(list);
getCodes(root, "", zip.encodeMap);
zip.res = transform(zip.buff, zip.size, zip.encodeMap);
}
int binToTen(string binaryString)
{
int parseBinary = 0;
for (int i = 0; i < binaryString.length(); ++i)
{
if (binaryString[i] == '1')
{
parseBinary += pow(2.0, binaryString.length() - i - 1);
}
}
return parseBinary;
}
void zipFile(string res, string fileName, int& zipSize)
{
zipSize = res.length();
if (res.length() % 8 != 0)
{
for (int i = 0; i < res.length() % 8; i++)
{
res += "0";
}
}
char* bytes = new char[res.length() / 8];
int index = 0;
for (int i = 0; i < res.length();)
{
string subStr = res.substr(i, 8);
i += 8;
bytes[index] = binToTen(subStr);
index++;
}
FILE* fp = NULL;
errno_t err;
if ((err = fopen_s(&fp, fileName.c_str(), "wb")) != 0)
{
cout << "文件写入失败" << endl;
return;
}
fwrite(bytes, sizeof(unsigned __int8), res.length() / 8, fp);
fclose(fp);
}
string intToBin(int ch)
{
string res = "";
for (int i = 7; i >= 0; i--)
{
if (ch & (128 >> 7 - i))
{
res += "1";
}
else
{
res += "0";
}
}
return res;
}
void unZipFile(string originFileName, string destFileName, int size, map<string, elementType> decodeMap)
{
FILE* fp = NULL;
// 为了凑整,省的用if语句了
int length = (size + 7) / 8;
int* buff = new int[length];
errno_t err;
if ((err = fopen_s(&fp, originFileName.c_str(), "rb")) != 0)
{
cout << "文件打开失败" << endl;
return;
}
int index = 0;
while (index < length)
{
buff[index++] = fgetc(fp);
}
fclose(fp);
string res = "";
for (int i = 0; i < length; i++)
{
res += intToBin(buff[i]);
}
string text = "";
for (int i = 0; i <= size;)
{
index = 1;
while (i + index <= size)
{
string temp = res.substr(i, index);
if (decodeMap.count(temp) == 1)
{
text += decodeMap[temp];
break;
}
index++;
}
i += index;
}
if ((err = fopen_s(&fp, destFileName.c_str(), "wb")) != 0)
{
cout << "文件写入失败" << endl;
return;
}
fwrite(text.c_str(), sizeof(unsigned __int8), text.length(), fp);
fclose(fp);
}
演示效果
C语言压缩解压文件的完整流程
上述的压缩和解压是放在一起的
实际也应该在压缩文件时,一并将编码写入到压缩文件中;这里采用写入结构体的方式
# include <iostream>
# include <stdlib.h>
# include <stdio.h>
# include <string.h>
# include <sys/stat.h>
# include <algorithm>
# include <vector>
# include <map>
using namespace std;
// 读取文件得到int数组转化成哈夫曼编码得到哈夫曼树,进行压缩与解压
typedef int elementType;
struct Node
{
elementType data;
int value;
Node* left;
Node* right;
};
struct ZipStruct
{
map<elementType, string> encodeMap; // 由哈夫曼树生成的编码表
int size = 0; // 所占字节数
int zipSize = 0; // 所占比特数(用于处理末尾数字补全)
};
struct Zip
{
string originFileName;
string destFileName; // 压缩生成的文件名
elementType* buff = NULL; // 读入的文件字符数据
map<elementType, int> twoTuple; // 字符串转化为二元组形式,表示各个字符出现的频率
map<elementType, string> encodeMap; // 由哈夫曼树生成的编码表
string res; // 生成的二进制编码字符串
int size = 0; // 所占字节数
int zipSize = 0; // 所占比特数(用于处理末尾数字补全)
};
struct UnZip
{
string originFileName; // 要解压的文件名
string destFileName; // 解压生成的文件名
};
// 将int数组转化为二元组形式,表示各个int数字出现的频率
map<elementType, int> getList(int* text, int length);
//自定义排序函数
bool cmp(const Node* node1, const Node* node2);
// 通过二元组创建哈夫曼树
Node* createHafumanTree(vector<Node*> list);
// 获取编码
void getCodes(Node* root, string path, map<elementType, string>& encodeMap);
// 读取文件内容,得到int数组
elementType* readFile(string fileName, int& size);
// 根据编码表将int数组转化为新的编码
string transform(elementType* buff, int length, map<elementType, string> encodeMap);
// 获取文件生成的二进制编码字符串
void generateCodes(Zip& zip);
//将传入的二进制字符串转换成十进制,并返回十进制数字
int binToTen(string binaryString);
// 将新编码字符串转化为int数组(转化采用末尾不够补0),减少占用空间,并写入文件中,返回文件比特数,同时一并将编码表和字节与比特数写入
void zipFile(string res, string fileName, int& zipSize, ZipStruct* zipStruct);
//将传入的int转换成二进制字符串
string intToBin(int ch);
// 根据编码表将文件还原
void unZipFile(string originFileName, string destFileName, ZipStruct* zipStruct);
int main()
{
Zip zip;
UnZip unZip;
ZipStruct zipStruct;
zip.originFileName = "D:/test.png";
zip.destFileName = "D:/test.myZip";
generateCodes(zip);
zipStruct.encodeMap = zip.encodeMap;
zipStruct.size = zip.size;
zipFile(zip.res, zip.destFileName, zip.zipSize, &zipStruct);
unZip.originFileName = zip.destFileName;
unZip.destFileName = "D:/test1.png";
unZipFile(unZip.originFileName, unZip.destFileName, &zipStruct);
system("pause");
}
map<elementType, int> getList(int* text, int length)
{
map<elementType, int> map;
for (int i = 0; i < length; i++)
{
if (map.count((int)text[i]) == 1)
{
map[text[i]] = map[text[i]] + 1;
}
else
{
map[text[i]] = 1;
}
}
return map;
}
bool cmp(const Node* node1, const Node* node2)
{
return node1->value > node2->value;
}
Node* createHafumanTree(vector<Node*> list)
{
while (list.size() > 1)
{
sort(list.begin(), list.end(), cmp);
Node* left = list.at(list.size() - 1);
Node* right = list.at(list.size() - 2);
Node* node = (Node*)malloc(sizeof(Node));
if (node == NULL)
{
cout << "内存不足" << endl;
return NULL;
}
node->value = left->value + right->value;
node->left = left;
node->right = right;
list.pop_back();
list.pop_back();
list.push_back(node);
}
return list.at(0);
}
void getCodes(Node* root, string path, map<elementType, string>& encodeMap)
{
if (root == NULL)
{
return;
}
if (root->left == NULL && root->right == NULL)
{
encodeMap.insert(map<elementType, string>::value_type(root->data, path));
}
getCodes(root->left, path + "0", encodeMap);
getCodes(root->right, path + "1", encodeMap);
}
elementType* readFile(string fileName, int& size)
{
struct stat buf;
stat(fileName.c_str(), &buf);
size = buf.st_size;
FILE* fp = NULL;
int* buff = new int[buf.st_size];
errno_t err;
if ((err = fopen_s(&fp, fileName.c_str(), "rb")) != 0)
{
cout << "文件打开失败" << endl;
return NULL;
}
int index = 0;
while (index < buf.st_size)
{
buff[index++] = fgetc(fp);
}
fclose(fp);
return buff;
}
string transform(elementType* buff, int length, map<elementType, string> encodeMap)
{
string res = "";
for (int i = 0; i < length; i++)
{
res += encodeMap[buff[i]];
}
return res;
}
void generateCodes(Zip& zip)
{
zip.buff = readFile(zip.originFileName, zip.size);
zip.twoTuple = getList(zip.buff, zip.size);
vector<Node*> list;
for (auto& it : zip.twoTuple)
{
Node* node = (Node*)malloc(sizeof(Node));
if (node == NULL)
{
cout << "内存不足" << endl;
return;
}
node->data = it.first;
node->value = it.second;
node->left = NULL;
node->right = NULL;
list.push_back(node);
}
Node* root = createHafumanTree(list);
getCodes(root, "", zip.encodeMap);
zip.res = transform(zip.buff, zip.size, zip.encodeMap);
}
int binToTen(string binaryString)
{
int parseBinary = 0;
for (int i = 0; i < binaryString.length(); ++i)
{
if (binaryString[i] == '1')
{
parseBinary += pow(2.0, binaryString.length() - i - 1);
}
}
return parseBinary;
}
void zipFile(string res, string fileName, int& zipSize, ZipStruct* zipStruct)
{
zipSize = res.length();
zipStruct->zipSize = zipSize;
if (res.length() % 8 != 0)
{
for (int i = 0; i < res.length() % 8; i++)
{
res += "0";
}
}
char* bytes = new char[res.length() / 8];
int index = 0;
for (int i = 0; i < res.length();)
{
string subStr = res.substr(i, 8);
i += 8;
bytes[index] = binToTen(subStr);
index++;
}
FILE* fp = NULL;
errno_t err;
if ((err = fopen_s(&fp, fileName.c_str(), "wb")) != 0)
{
cout << "文件写入失败" << endl;
return;
}
fwrite(zipStruct, sizeof(ZipStruct), 1, fp);
fwrite(bytes, sizeof(unsigned __int8), res.length() / 8, fp);
fclose(fp);
}
string intToBin(int ch)
{
string res = "";
for (int i = 7; i >= 0; i--)
{
if (ch & (128 >> 7 - i))
{
res += "1";
}
else
{
res += "0";
}
}
return res;
}
void unZipFile(string originFileName, string destFileName, ZipStruct* zipStruct)
{
FILE* fp = NULL;
errno_t err;
if ((err = fopen_s(&fp, originFileName.c_str(), "rb")) != 0)
{
cout << "文件打开失败" << endl;
return;
}
fread(zipStruct, sizeof(ZipStruct), 1, fp);
map<string, elementType> decodeMap;
for (auto& it : zipStruct->encodeMap)
{
decodeMap.insert(map<string, char>::value_type(it.second, it.first));
}
// 为了凑整,省的用if语句了
int size = zipStruct->zipSize;
int length = (size + 7) / 8;
int* buff = new int[length];
int index = 0;
while (index < length)
{
buff[index++] = fgetc(fp);
}
fclose(fp);
string res = "";
for (int i = 0; i < length; i++)
{
res += intToBin(buff[i]);
}
string text = "";
for (int i = 0; i <= size;)
{
index = 1;
while (i + index <= size)
{
string temp = res.substr(i, index);
if (decodeMap.count(temp) == 1)
{
text += decodeMap[temp];
break;
}
index++;
}
i += index;
}
if ((err = fopen_s(&fp, destFileName.c_str(), "wb")) != 0)
{
cout << "文件写入失败" << endl;
return;
}
fwrite(text.c_str(), sizeof(unsigned __int8), text.length(), fp);
fclose(fp);
}
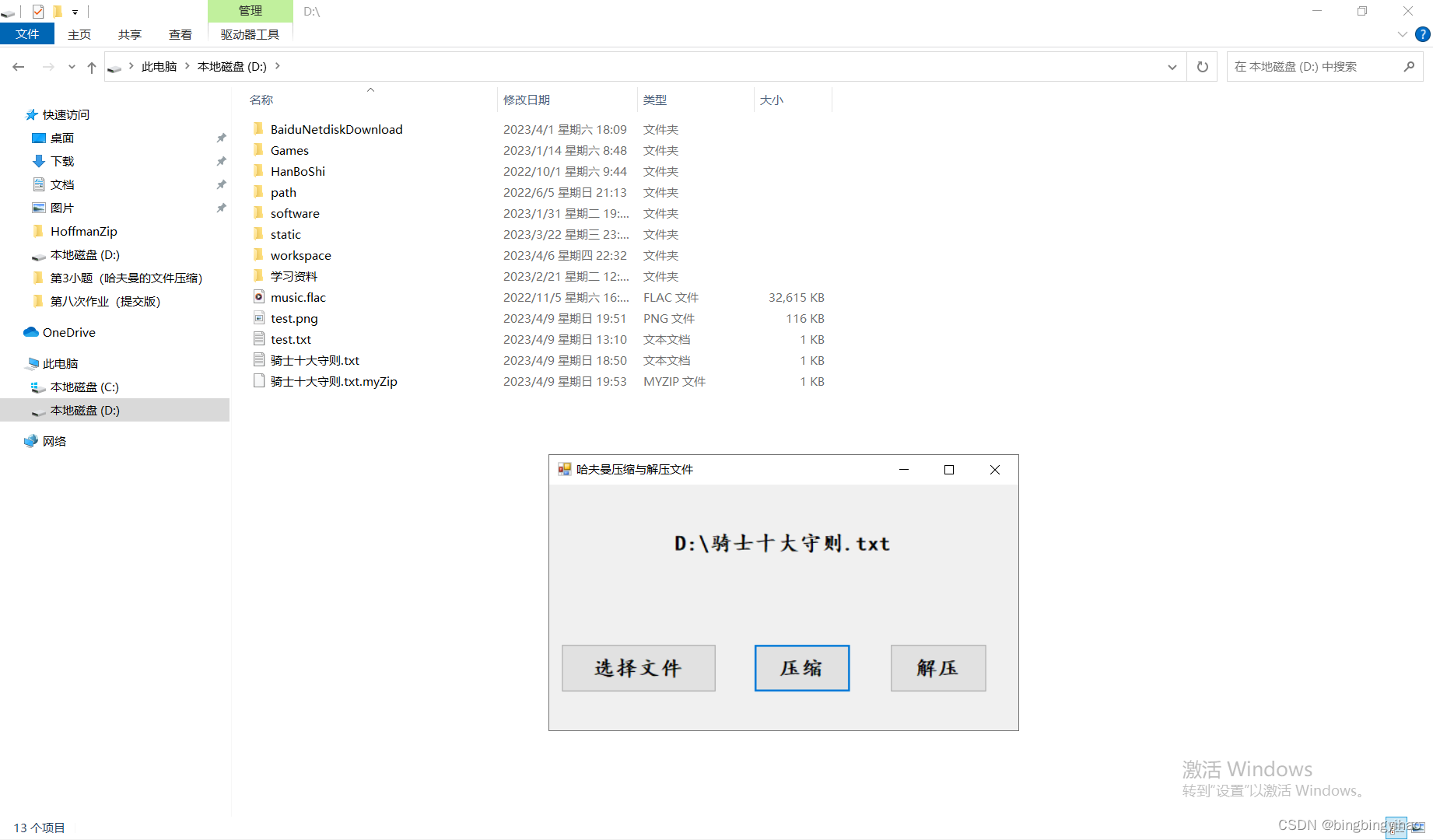
带界面的Winform调用exe程序的哈夫曼压缩小程序
考虑到分了两个步骤,所以将cpp文件也分为两个
在这个地方的测试,我发现原来的代码是有问题的;C语言对于结构体的读写不是这么简单的,那个map拿不到内容
结构体写入时需要写入数组,不能写入指针
这里采用写入字符出现频率的方式,在解压过程中重新构建一次哈夫曼树,得到同样的哈夫曼编码
采用这样的设计方式的原因是,写入可以更方便的读出;后续如果可能的话,将模拟Java序列化的方式解决这个问题
压缩
# include <iostream>
# include <stdlib.h>
# include <stdio.h>
# include <string.h>
# include <sys/stat.h>
# include <algorithm>
# include <vector>
# include <map>
using namespace std;
// 压缩思路,将字符出现的频率写入文件,以及将压缩后的编码写入文件
typedef char elementType;
struct Node {
elementType data;
int value;
Node* left;
Node* right;
};
int sizeOfOriginFile = 0;
vector<Node*> frequencyList; // 字符出现的频率
elementType* buff = NULL;
map<elementType, string> encodeMap;
int sizeOfZipFile = 0; // 压缩后的字符串的长度,用于恢复与处理末尾的0
void readFile(string fileName) {
struct stat buf;
stat(fileName.c_str(), &buf);
FILE* fp = NULL;
buff = new elementType[buf.st_size];
sizeOfOriginFile = buf.st_size;
errno_t err;
if ((err = fopen_s(&fp, fileName.c_str(), "rb")) != 0) {
cout << "文件打开失败" << endl;
return;
}
fread(buff, buf.st_size, 1, fp);
fclose(fp);
}
bool cmp(const Node* node1, const Node* node2) {
return node1->value > node2->value;
}
Node* createHafumanTree(string fileName) {
readFile(fileName);
map<elementType, int> map;
for (int i = 0; i < sizeOfOriginFile; i++) {
if (map.count(buff[i]) == 1) {
map[buff[i]] = map[buff[i]] + 1;
}
else {
map[buff[i]] = 1;
}
}
vector<Node*> list;
for (auto& it : map) {
Node* node = (Node*)malloc(sizeof(Node));
if (node == NULL) {
cout << "内存不足" << endl;
return NULL;
}
node->data = it.first;
node->value = it.second;
node->left = NULL;
node->right = NULL;
list.push_back(node);
frequencyList.push_back(node);
}
while (list.size() > 1) {
sort(list.begin(), list.end(), cmp);
Node* left = list.at(list.size() - 1);
Node* right = list.at(list.size() - 2);
Node* node = (Node*)malloc(sizeof(Node));
if (node == NULL) {
cout << "内存不足" << endl;
return NULL;
}
node->value = left->value + right->value;
node->left = left;
node->right = right;
list.pop_back();
list.pop_back();
list.push_back(node);
}
return list.at(0);
}
void getCodes(Node* root, string path, map<elementType, string>& encodeMap) {
if (root == NULL) {
return;
}
if (root->left == NULL && root->right == NULL) {
encodeMap.insert(map<elementType, string>::value_type(root->data, path));
}
getCodes(root->left, path + "0", encodeMap);
getCodes(root->right, path + "1", encodeMap);
}
string transform() {
string res = "";
for (int i = 0; i < sizeOfOriginFile; i++) {
res += encodeMap[buff[i]];
}
return res;
}
double binToTen(string binaryString) {
double parseBinary = 0;
for (int i = 0; i < binaryString.length(); ++i) {
if (binaryString[i] == '1') {
parseBinary += pow(2.0, binaryString.length() - i - 1);
}
}
return parseBinary;
}
void zipFile(string res, string fileName) {
sizeOfZipFile = (int)res.length();
for (int i = 0; i < res.length() % 8; i++) {
res += "0";
}
elementType* bytes = new elementType[res.length() / 8 + 1];
int index = 0;
for (int i = 0; i < res.length() && index < res.length(); i += 8) {
string subStr = res.substr(i, 8);
bytes[index] = (elementType)binToTen(subStr);
index++;
}
FILE* fp = NULL;
errno_t err;
if ((err = fopen_s(&fp, fileName.c_str(), "wb")) != 0) {
cout << "文件写入失败" << endl;
return;
}
int sizeOfList = (int)frequencyList.size();
fprintf_s(fp, "%d %d", sizeOfList, sizeOfZipFile);
sort(frequencyList.begin(), frequencyList.end(), cmp);
for (auto& it : frequencyList) {
fprintf_s(fp, " %d %d", (int)it->data, it->value);
}
fwrite(bytes, sizeof(unsigned __int8), res.length() / 8, fp);
fclose(fp);
}
int main(int argc, char** argv) {
if (argc < 3) {
cout << "请输入要压缩的文件名及压缩后的压缩包名称" << endl;
return 0;
}
string zipOriginFileName = argv[1];
string zipDestFileName = argv[2];
Node* root = createHafumanTree(zipOriginFileName);
getCodes(root, "", encodeMap);
string res = transform();
zipFile(res, zipDestFileName);
}
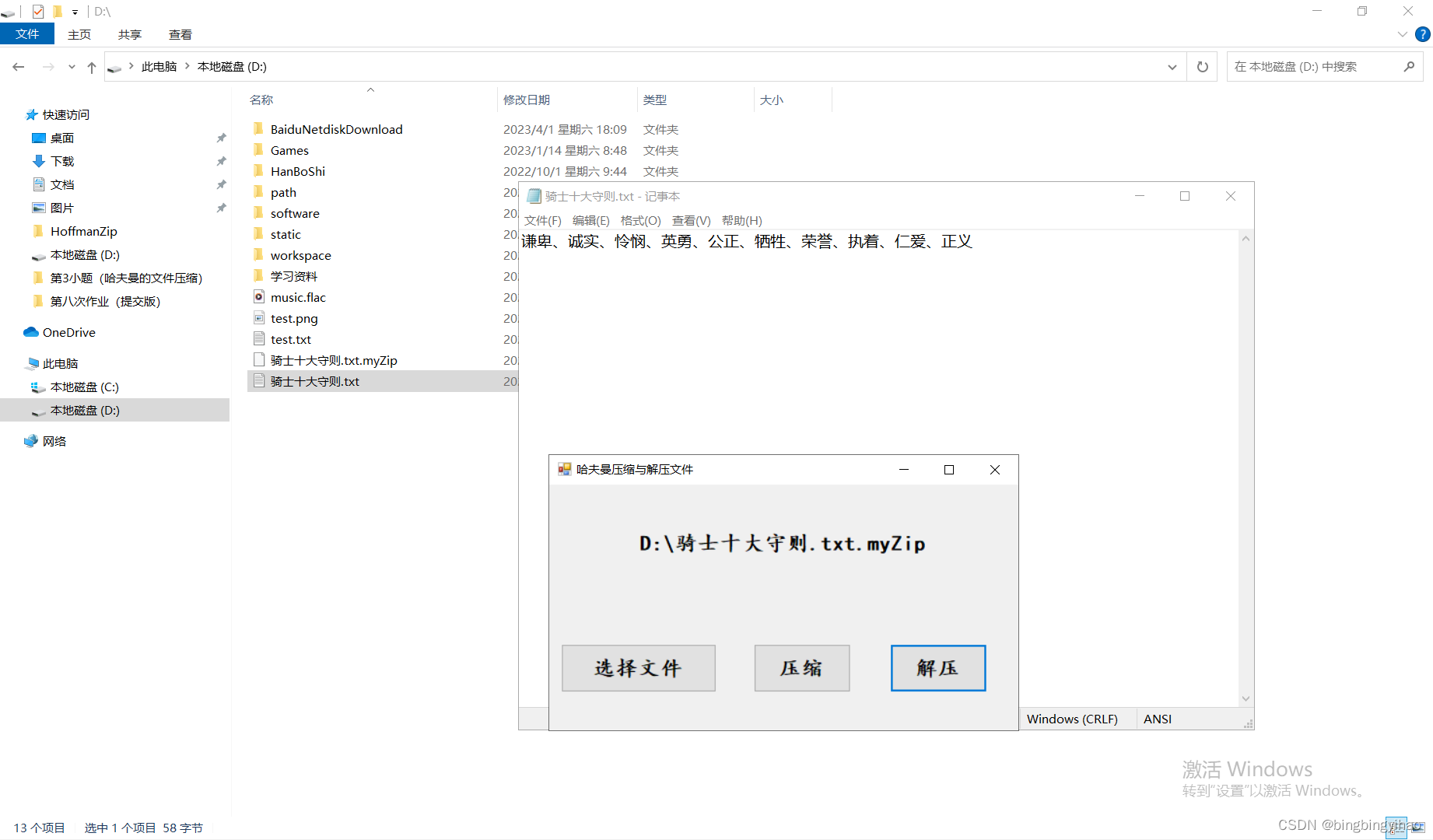
解压
# include <iostream>
# include <stdlib.h>
# include <stdio.h>
# include <string.h>
# include <sys/stat.h>
# include <algorithm>
# include <vector>
# include <map>
using namespace std;
// 先读出字符及出现频率,构建出哈夫曼树与编码,最后进行解压
typedef char elementType;
struct Node {
elementType data;
int value;
Node* left;
Node* right;
};
bool cmp(const Node* node1, const Node* node2) {
return node1->value > node2->value;
}
Node* createHafumanTree(vector<Node*> list) {
while (list.size() > 1) {
sort(list.begin(), list.end(), cmp);
Node* left = list.at(list.size() - 1);
Node* right = list.at(list.size() - 2);
Node* node = (Node*)malloc(sizeof(Node));
if (node == NULL) {
cout << "内存不足" << endl;
return NULL;
}
node->value = left->value + right->value;
node->left = left;
node->right = right;
list.pop_back();
list.pop_back();
list.push_back(node);
}
return list.at(0);
}
void getCodes(Node* root, string path, map<elementType, string>& encodeMap) {
if (root == NULL) {
return;
}
if (root->left == NULL && root->right == NULL) {
encodeMap.insert(map<elementType, string>::value_type(root->data, path));
}
getCodes(root->left, path + "0", encodeMap);
getCodes(root->right, path + "1", encodeMap);
}
string intToBin(int ch) {
string res = "";
for (int i = 7; i >= 0; i--) {
if (ch & (128 >> (7 - i))) {
res += "1";
}
else {
res += "0";
}
}
return res;
}
void unZipFile(string originFileName, string destFileName) {
FILE* fp = NULL;
errno_t err;
if ((err = fopen_s(&fp, originFileName.c_str(), "rb")) != 0) {
cout << "文件打开失败" << endl;
return;
}
int sizeOfList = 0;
int sizeOfZipFile = 0;
fscanf_s(fp, "%d %d", &sizeOfList, &sizeOfZipFile);
vector<Node*> frequencyList;
int data = 0;
int value = 0;
while (sizeOfList > 0) {
fscanf_s(fp, " %d %d", &data, &value);
Node* node = (Node*)malloc(sizeof(Node));
if (node == NULL) {
cout << "内存不足" << endl;
return;
}
node->data = (char)data;
node->value = value;
node->left = NULL;
node->right = NULL;
frequencyList.push_back(node);
sizeOfList--;
}
Node* root = createHafumanTree(frequencyList);
map<elementType, string> encodeMap;
map<string, elementType> decodeMap;
getCodes(root, "", encodeMap);
for (auto& it : encodeMap) {
decodeMap.insert(map<string, char>::value_type(it.second, it.first));
}
int length = (sizeOfZipFile + 7) / 8;
elementType* buf = new elementType[length];
fread(buf, length, 1, fp);
fclose(fp);
string res = "";
for (int i = 0; i < length; i++) {
res += intToBin(buf[i]);
}
int index;
string text = "";
for (int i = 0; i <= sizeOfZipFile;) {
index = 1;
while (i + index <= sizeOfZipFile) {
string temp = res.substr(i, index);
//cout << temp << endl;
if (decodeMap.count(temp) == 1) {
text += decodeMap[temp];
break;
}
index++;
}
i += index;
}
if ((err = fopen_s(&fp, destFileName.c_str(), "wb")) != 0) {
cout << "文件写入失败" << endl;
return;
}
fwrite(text.c_str(), sizeof(unsigned __int8), text.length(), fp);
fclose(fp);
}
int main(int argc, char** argv) {
if (argc < 3) {
cout << "参数过少,请给出压缩文件名称与解压后文件名称" << endl;
return 0;
}
string unZipOriginFileName = argv[1];
string unZipDestFileName = argv[2];
unZipFile(unZipOriginFileName, unZipDestFileName);
}
Winform的代码,调用命令行参数执行exe文件
using System;
using System.Diagnostics;
using System.Windows.Forms;
namespace HoffmanZip
{
public partial class 哈夫曼压缩与解压文件 : Form
{
public 哈夫曼压缩与解压文件()
{
InitializeComponent();
}
private void ChooseFile_Click(object sender, EventArgs e)
{
OpenFileDialog dialog = new OpenFileDialog
{
Multiselect = false,
Title = "请选择文件夹",
Filter = "所有文件(*.*)|*.*",
InitialDirectory = "D:\\"
};
if (dialog.ShowDialog() == DialogResult.OK)
{
label.Text = dialog.FileName;
}
}
private void Zip_Click(object sender, EventArgs e)
{
if (label.Text == "暂未选择文件")
{
MessageBox.Show("还未选择文件");
return;
}
string fileName = label.Text;
Process process = new Process();
ProcessStartInfo startInfo = new ProcessStartInfo("压缩.exe", fileName + " " + fileName + ".myZip");
process.StartInfo = startInfo;
process.Start();
MessageBox.Show("压缩成功");
}
private void UnZip_Click(object sender, EventArgs e)
{
if (label.Text == "暂未选择文件")
{
MessageBox.Show("还未选择文件");
return;
}
string fileName = label.Text;
if (!fileName.EndsWith(".myZip"))
{
MessageBox.Show("文件类型不匹配,需要为.myZip文件");
return;
}
Process process = new Process();
ProcessStartInfo startInfo = new ProcessStartInfo("解压.exe", fileName + " " + fileName.Substring(0, fileName.LastIndexOf(".")));
process.StartInfo = startInfo;
process.Start();
MessageBox.Show("解压成功");
}
}
}
效果演示
代码下载
链接:https://pan.baidu.com/s/16rZYDQUGxIRp2dJXmkldWg
提取码:0925
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









