







 本文详细介绍了Hadoop YARN架构,包括其核心出发点、体系架构、应用工作流程和资源调度模型。YARN作为资源管理平台,通过ResourceManager、NodeManager、ApplicationMaster和Container组件实现资源统一管理和调度。它提供了资源隔离,支持多种计算框架,并详细阐述了资源调度器如Capacity Scheduler和Fair Scheduler的工作原理。最后,文章讲解了如何实现一个简单的YARN Application框架。
本文详细介绍了Hadoop YARN架构,包括其核心出发点、体系架构、应用工作流程和资源调度模型。YARN作为资源管理平台,通过ResourceManager、NodeManager、ApplicationMaster和Container组件实现资源统一管理和调度。它提供了资源隔离,支持多种计算框架,并详细阐述了资源调度器如Capacity Scheduler和Fair Scheduler的工作原理。最后,文章讲解了如何实现一个简单的YARN Application框架。
1. 介绍
YARN(Yet Another Resource Negotiator)是一个通用的资源管理平台,可为各类计算框架提供资源的管理和调度。
其核心出发点是为了分离资源管理与作业调度/监控,实现分离的做法是拥有一个全局的资源管理器(ResourceManager,RM),以及每个应用程序对应一个的应用管理器(ApplicationMaster,AM),应用程序由一个作业(Job)或者Job的有向无环图(DAG)组成。
YARN可以将多种计算框架(如离线处理MapReduce、在线处理的Storm、迭代式计算框架Spark、流式处理框架S4等) 部署到一个公共集群中,共享集群的资源。并提供如下功能:
资源的统一管理和调度:
集群中所有节点的资源(内存、CPU、磁盘、网络等)抽象为Container。计算框架需要资源进行运算任务时需要向YARN申请Container, YARN按照特定的策略对资源进行调度进行Container的分配。资源隔离:
YARN使用了轻量级资源隔离机制Cgroups进行资源隔离以避免相互干扰,一旦Container使用的资源量超过事先定义的上限值,就将其杀死。
YARN是对Mapreduce V1重构得到的,有时候也成为MapReduce V2。
YARN可以看成一个云操作系统,由一个ResourceManager和多个NodeManager组成, 它负责管理所有NodeManger上多维度资源, 并以Container(启动一个Container相当于启动一个进程)方式分配给应用程序启动ApplicationMaster(相当于主进程中运行逻辑) 或运行ApplicationMaster切分的各Task(相当于子进程中运行逻辑)。
2. YARN体系架构
YARN架构如下图所示:
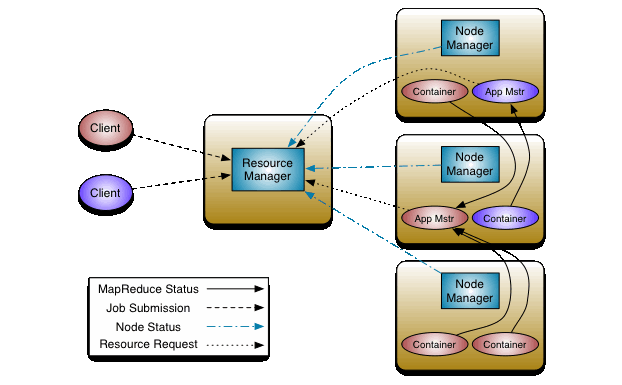
YARN总体上是Master/Slave结构,主要由ResourceManager、NodeManager、 ApplicationMaster和Container等几个组件构成。
ResourceManager(RM)
负责对各NM上的资源进行统一管理和调度。将AM分配空闲的Container运行并监控其运行状态。对AM申请的资源请求分配相应的空闲Container。主要由两个组件构成:调度器和应用程序管理器:调度器(Scheduler):调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序。调度器仅根据各个应用程序的资源需求进行资源分配,而资源分配单位是Container,从而限定每个任务使用的资源量。Shceduler不负责监控或者跟踪应用程序的状态,也不负责任务因为各种原因而需要的重启(由ApplicationMaster负责)。总之,调度器根据应用程序的资源要求,以及集群机器的资源情况,为应用程序分配封装在Container中的资源。
调度器是可插拔的,例如CapacityScheduler、FairScheduler。具体看下文的调度算法。应用程序管理器(Applications Manager):应用程序管理器负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动AM、监控AM运行状态并在失败时重新启动等,跟踪分给的Container的进度、状态也是其职责。
NodeManager (NM)
NM是每个节点上的资源和任务管理器。它会定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态;同时会接收并处理来自AM的Container 启动/停止等请求。ApplicationMaster (AM):
用户提交的应用程序均包含一个AM,负责应用的监控,跟踪应用执行状态,重启失败任务等。ApplicationMaster是应用框架,它负责向ResourceManager协调资源,并且与NodeManager协同工作完成Task的执行和监控。MapReduce就是原生支持的一种框架,可以在YARN上运行Mapreduce作业。有很多分布式应用都开发了对应的应用程序框架,用于在YARN上运行任务,例如Spark,Storm等。如果需要,我们也可以自己写一个符合规范的YARN application。Container:
Container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container 表示的。 YARN会为每个任务分配一个Container且该任务只能使用该Container中描述的资源。
3. YARN应用工作流程
如下图所示用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:
启动AM ,如下步骤1~3;
由AM创建应用程序为它申请资源并监控它的整个运行过程,直到运行完成,如下步骤4~7。
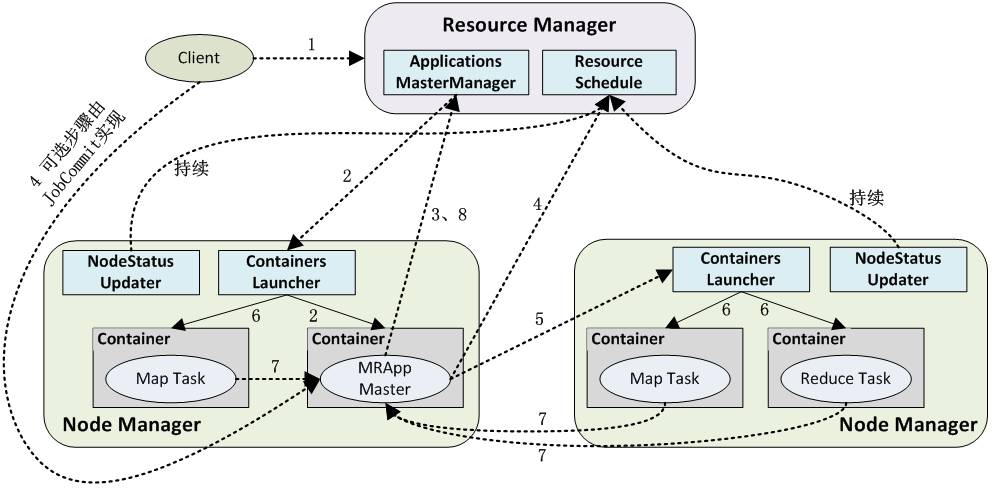
YARN应用工作流程图
1、用户向YARN中提交应用程序,其中包括AM程序、启动AM的命令、命令参数、用户程序等;事实上,需要准确描述运行ApplicationMaster的unix进程的所有信息。提交工作通常由YarnClient来完成。
2、RM为该应用程序分配第一个Container,并与对应的NM通信,要求它在这个Container中启动AM;
3、AM首先向RM注册,这样用户可以直接通过RM査看应用程序的运行状态,运行状态通过 AMRMClientAsync.CallbackHandler的getProgress() 方法来传递给RM。 然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4〜7;
4、AM采用轮询的方式通过RPC协议向RM申请和领取资源;资源的协调通过 AMRMClientAsync异步完成,相应的处理方法封装在AMRMClientAsync.CallbackHandler中。
5、—旦AM申请到资源后,便与对应的NM通信,要求它启动任务;通常需要指定一个ContainerLaunchContext,提供Container启动时需要的信息。
6、NM为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务;
7、各个任务通过某个RPC协议向AM汇报自己的状态和进度,以让AM随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;ApplicationMaster与NM的通信通过NMClientAsync object来完成,容器的所有事件通过NMClientAsync.CallbackHandler来处理。例如启动、状态更新、停止等。
8、应用程序运行完成后,AM向RM注销并关闭自己。
4. YARN资源调度模型
YARN提供了一个资源管理平台能够将集群中的资源统一进行管理。所有节点上的多维度资源都会根据申请抽象为一个个Container。
YARN采用了双层资源调度模型:
RM中的资源调度器将资源分配给各个AM:资源分配过程是异步的。资源调度器将资源分配给一个应用程序后,它不会立刻push给对应的AM,而是暂时放到一个缓冲区中,等待AM通过周期性的心跳主动来取;
AM领取到资源后再进一步分配给它内部的各个任务:不属于YARN平台的范畴,由用户自行实现。
也就是说,ResourceManager分配集群资源的时候,以抽象的Container形式分配给各应用程序,至于应用程序的子任务如何使用这些资源,由应用程序自行决定。
YARN目前采用的资源分配算法有三种。但真实的调度器实现中还对算法做了一定程度的优化。
1、 Capacity Scheduler:该调度器用于在共享、多租户(multi-tenant)的集群环境中运行Hadoop应用,对运营尽可能友好的同时最大化吞吐量和效用。
该调度器保证共享集群的各个组织能够得到容量的保证,同时可以超额使用集群中暂时没有人使用的资源。Capacity Scheduler为了实现这些目标,抽象了queue的概念,queue通常由管理员配置。为了进一步细分容量的使用,调度器支持层级化的queue(hierarchical queues),使得在特定组织内部,可以进一步有效利用集群资源。
Capacity调度器支持的一些特性如下:
- 层级队列(Hierarchical Queues)
- 容量保证
- 安全性:每个队列都有队列的访问权限控制(ACL)
- 弹性: 空闲资源可以额外分配给任何需要的队列
- 多租户
- 基于资源的调度(resouce-based scheduling): 对资源敏感的应用程序,可以有效地控制资源情况
- 支持用户(组)到queue的映射:基于用户组提交作业到对应queue。
- 运营支持:支持运行时配置队列的容量,ACL等。也可以在运行时停止queue阻止进一步往queue提交作业。
要使用该调度器,在conf/yarn-site.xml配置如下:
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>队列的配置通过/etc/hadoop/capacity-scheduler.xml来完成。更多关于此调度器的信息,参考
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









