







Apache Avro框架提供:
- 丰富的数据类型(原始类型和复杂类型)
- 紧凑、快速的二进制文件格式(.avro)
- 一种容器文件,用于存储avro数据
- RPC
- 容易与动态语言集成,无需生成代码。代码生成作为一种优化,只有在静态语言中使用才有价值。
下面是一个Avro MapReduce的实例,MapReduce作业统计Avro文件中的数据。Avro文件中的对象Schema如下:
{"namespace": "me.lin.avro.mapreduce",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}我们首先使用代码生成数据。生成的avro使用avro-tool查看,示例如下:
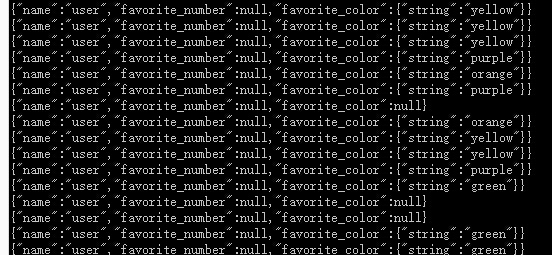
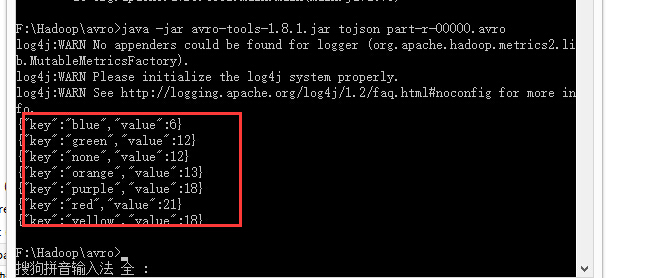
我们要统计给定的文件中喜欢不同颜色的人数,结果如下:
Maven项目创建
我们使用Maven来创建项目,POM文件如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>me.lin.avro</groupId>
<artifactId>avro-mapreduce</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.8.1</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
</goals>
<configuration>
<sourceDirectory>${project.basedir}/../</sourceDirectory>
<outputDirectory>${project.basedir}/src/main/java</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.8.1</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-mapred</artifactId>
<version>1.8.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
</dependencies>
</project>生成代码
我们根据Schema生成User类,运行mvn package命令即可。在源码目录下看到生成了User及相关的饿内部类:
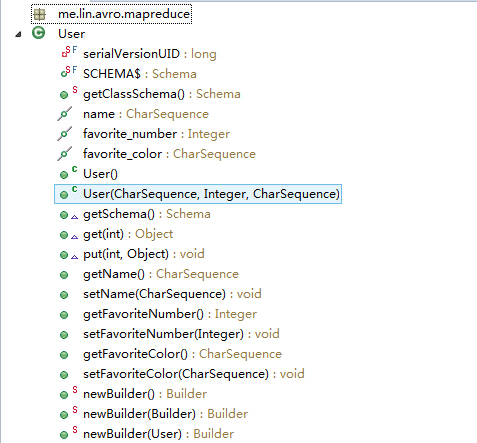
生成随机数据
接下来我们使用上述的Schema,随机生成喜欢不同颜色的数据,工具类如下:
package me.lin.avro.mapreduce;
import java.io.File;
import java.io.IOException;
import java.util.Random;
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.io.DatumWriter;
import org.apache.avro.specific.SpecificDatumWriter;
public class GenerateData {
public static final String[] COLORS = {"red", "orange", "yellow", "green", "blue", "purple", null};
public static final int USERS = 100;
public static final String PATH = "./input/users.avro";
public static void main(String[] args) throws IOException {
// Open data file
File file = new File(PATH);
if (file.getParentFile() != null) {
file.getParentFile().mkdirs();
}
DatumWriter<User> userDatumWriter = new SpecificDatumWriter<User>(User.class);
DataFileWriter<User> dataFileWriter = new DataFileWriter<User>(userDatumWriter);
dataFileWriter.create(User.SCHEMA$, file);
// Create random users
User user;
Random random = new Random();
for (int i = 0; i < USERS; i++) {
user = new User("user", null, COLORS[random.nextInt(COLORS.length)]);
dataFileWriter.append(user);
System.out.println(user);
}
dataFileWriter.close();
}
}可以指定生成多少条记录,我们这里生成100条,生成的users.avro文件中包含的数据就是前面提到的。
Mapper定义
Avro Mapper主要是在输入输出的数据类型上使用Avro,具体代码如下:
public static class ColorCountMapper extends
Mapper<AvroKey<User>, NullWritable, Text, IntWritable> {
@Override
public void map(AvroKey<User> key, NullWritable value, Context context)
throws IOException, InterruptedException {
CharSequence color = key.datum().getFavoriteColor();
if (color == null) {
color = "none";
}
context.write(new Text(color.toString()), new IntWritable(1));
}
}这个Map将avro文件中的记录作为key,value为空。输出颜色及数量给Reducer。
Reducer定义
Reducer统计各颜色的人数:
public static class ColorCountReducer
extends
Reducer<Text, IntWritable, AvroKey<CharSequence>, AvroValue<Integer>> {
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
context.write(new AvroKey<CharSequence>(key.toString()),
new AvroValue<Integer>(sum));
}
}统计,然后将颜色-数量数据对输出到avro文件。
作业配置
@Override
public int run(String[] args) throws Exception {
if (args.length != 2) {
System.err
.println("Usage: MapReduceColorCount <input path> <output path>");
return -1;
}
Job job = new Job(getConf());
job.setJarByClass(MapReduceColorCount.class);
job.getConfiguration().setBoolean( Job.MAPREDUCE_JOB_USER_CLASSPATH_FIRST, true);
job.setJobName("Color Count");
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setInputFormatClass(AvroKeyInputFormat.class);
job.setMapperClass(ColorCountMapper.class);
AvroJob.setInputKeySchema(job, User.getClassSchema());
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputFormatClass(AvroKeyValueOutputFormat.class);
job.setReducerClass(ColorCountReducer.class);
AvroJob.setOutputKeySchema(job, Schema.create(Schema.Type.STRING));
AvroJob.setOutputValueSchema(job, Schema.create(Schema.Type.INT));
return (job.waitForCompletion(true) ? 0 : 1);
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new MapReduceColorCount(), args);
System.exit(res);
}
打包
运行mvn package,项目下的target目录得到如下打包好的代码:
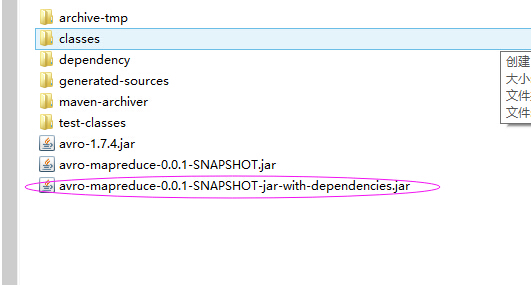
为了方便,我们将依赖包也打进来,这是在assembly插件中配置的,将含依赖的jar包和生成的数据上传到Hadoop集群的客户端机器。
运行
将前面生成的avro数据上传到HDFS:
hadoop fs -copyFromLocal /opt/job/ -ls /input/avro提交作业运行:
hadoop jar avro-mapreduce-0.0.1-SNAPSHOT.jar me.lin.avro.mapreduce.MapReduceColorCount /input/avro/users.avro /output/avro/mr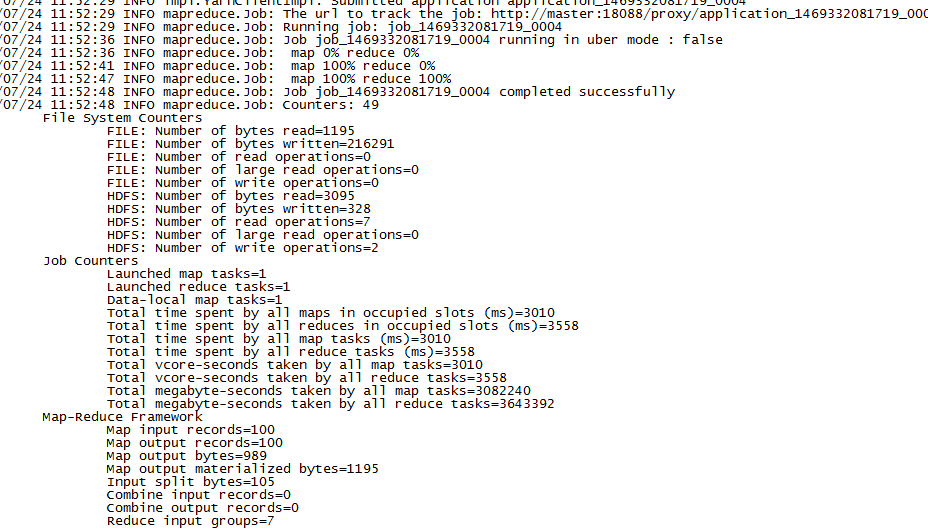
在运行作业的时候,一开始出现如下错误:
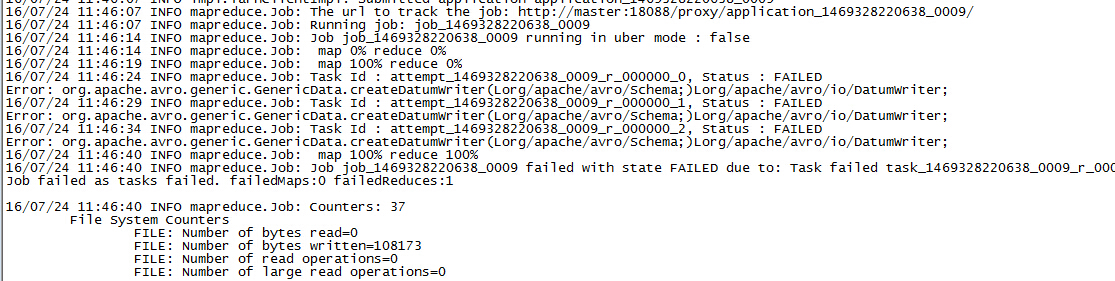
经过排查发现是Hadoop中的avro版本与我们的代码中使用的版本不一致。Hadoop中的版本为1.7.4,这个版本中是没有createDatumWriter方法的。为了使得作业运行时优先使用我们的jar包,而不是Hadoop的jar包(/share/mapreduce/lib/avro-1.7.4.jar),我们将作业设置为优先使用用户jar包:
job.getConfiguration().setBoolean( Job.MAPREDUCE_JOB_USER_CLASSPATH_FIRST, true);对应的属性名称为mapreduce.job.user.classpath.first.















 561
561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









