







从HDFS读取数据MR操作后写入HBase
1、WordCount示例
package mapred;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
public class WordCountHBase {
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
private IntWritable i = new IntWritable(1);
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String s[] = value.toString().trim().split(" ");
for (String m: s) {
context.write(new Text(m), i);
}
}
}
public static class Reduce extends TableReducer<Text, IntWritable, NullWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for(IntWritable i : values) {
sum += i.get();
}
Put put = new Put(Bytes.toBytes(key.toString()));
put.add(Bytes.toBytes("content"), Bytes.toBytes("count"),
Bytes.toBytes(String.valueOf(sum)));
context.write(NullWritable.get(), put);
}
}
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
String tableName = "wordcount";
Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.property.clientPort", "2181");
config.set("hbase.zookeeper.quorum", "10.10.4.55");
config.set(TableOutputFormat.OUTPUT_TABLE, tableName);
HTableDescriptor htd = new HTableDescriptor(tableName);
HColumnDescriptor col = new HColumnDescriptor("content");
htd.addFamily(col);
HBaseAdmin admin = new HBaseAdmin(config);
if(admin.tableExists(tableName)) {
System.out.println("table exists, trying recreate table!");
admin.disableTable(tableName);
admin.deleteTable(tableName);
}
System.out.println("create new table : " + tableName);
admin.createTable(htd);
admin.close();
String input = "hdfs://10.10.4.55:9000/user/root/t.txt";
Job job = new Job(config, "WordCount table with " + input);
job.setJarByClass(WordCountHBase.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TableOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(input));
System.exit(job.waitForCompletion(true)?0:1);
}
}
输入文件内容:
hello world hello hadoop
bye world bye hadoop
输出表数据:
hbase(main):035:0> scan 'wordcount'
ROW COLUMN+CELL
bye column=content:count, timestamp=1378280133721, value=2
hadoop column=content:count, timestamp=1378280133721, value=2
hello column=content:count, timestamp=1378280133721, value=2
world column=content:count, timestamp=1378280133721, value=2
4 row(s) in 0.0890 seconds
[root@master hbase0941]#
2、应用服务器日志分析timespend示例
有内容如下日志文件,要分析每位用户花费的总时间。
01/01/2011 user1 3s
01/01/2011 user2 5s
01/01/2011 user3 10s
01/01/2011 user4 6s
01/02/2011 user1 4s
01/02/2011 user2 30s
01/02/2011 user3 4s
01/02/2011 user1 15s
01/02/2011 user2 15s
代码如下,首先是Mapper:
package mapred.t1;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class THMapper extends Mapper<LongWritable, Text, Text, Text> {
public void map(LongWritable key, Text value, Context context) {
String[] items = value.toString().split("\\W+");
String k = items[3];
String v = items[4];
System.out.println("key:" + k + "," + "value:" + v);
try {
context.write(new Text(k), new Text(v));
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
然后是Reduce:
package mapred.t1;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.Text;
public class THReducer extends TableReducer<Text, Text, ImmutableBytesWritable> {
public void reduce(Text key, Iterable<Text> values, Context context) {
String k = key.toString();
int num = 0;
Iterator<Text> it = values.iterator();
String timeStr;
while(it.hasNext()) {
timeStr = it.next().toString();
num += Integer.parseInt(timeStr.substring(0, timeStr.length()-1));
}
Put putrow = new Put(k.getBytes());
putrow.add("spend".getBytes(), "time".getBytes(),
Integer.toString(num).getBytes());
try {
context.write(new ImmutableBytesWritable(key.getBytes()), putrow);
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
然后是Driver:
package mapred.t1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.util.Tool;
public class THDriver extends Configured implements Tool {
@Override
public int run(String[] arg0) throws Exception {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum.", "10.10.4.55");
Job job = new Job(conf, "Txt-to-Hbase");
job.setJarByClass(TxtHbase.class);
/**
* 事先创建表结构
*/
String tableName = "timespend";
HTableDescriptor htd = new HTableDescriptor(tableName);
HColumnDescriptor col = new HColumnDescriptor("spend");
htd.addFamily(col);
HBaseAdmin admin = new HBaseAdmin(conf);
if(admin.tableExists(tableName)) {
System.out.println("table exists, trying recreate table!");
admin.disableTable(tableName);
admin.deleteTable(tableName);
}
System.out.println("create new table : " + tableName);
admin.createTable(htd);
admin.close();
Path in = new Path("hdfs://10.10.4.55:9000/user/root/t1.txt");
job.setInputFormatClass(TextInputFormat.class);
FileInputFormat.addInputPath(job, in);
job.setMapperClass(THMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
TableMapReduceUtil.initTableReducerJob(tableName,
THReducer.class, job);
job.waitForCompletion(true);
return 0;
}
}
最后是主类:
package mapred.t1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.util.ToolRunner;
public class TxtHbase {
public static void main(String [] args) throws Exception{
int mr;
mr = ToolRunner.run(new Configuration(),new THDriver(),args);
System.exit(mr);
}
}
通过以上代码,mapreduce实现之后,在hbase的shell中查看结果表timespend如下:
hbase(main):002:0> scan 'timespend'
ROW COLUMN+CELL
user1 column=spend:time, timestamp=1378282924060, value=22
user2 column=spend:time, timestamp=1378282924060, value=50
user3 column=spend:time, timestamp=1378282924060, value=14
user4 column=spend:time, timestamp=1378282924060, value=6
4 row(s) in 0.2650 seconds
hbase(main):003:0>
Reduce中要把处理之后的结果写入hbase的表中,所以与普通的mapreduce程序有些区别,由以上代码可以知道,reduce类继承的是TableReducer,通过查询API(如下图1)知道,它继承Reducer类,与其他的reduce类一样,它的输入k/v对是对应Map的输出k/v对,它的输出key可以是任意的类型,但是value必须是一个put或delete实例。
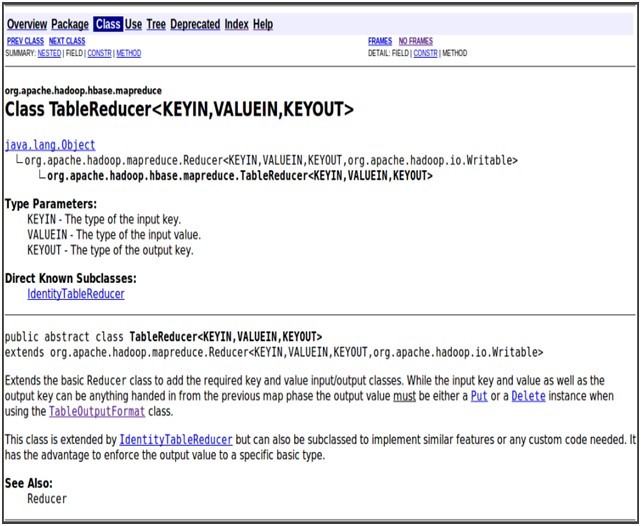
图1:TableReducer类详解
Reduce的输出key是ImmutableWritable类型(org.apache.hadoop.hase.io),API 中的解释,它是一个可以用作key或value类型的字节序列,该类型基于BytesWritable,不能调整大小。Reduce的输出value是一个put。如下面代码:
context.write(newImmutableBytesWritable(key.getBytes()),putrow);
Driver中job配置的时候没有设置job.setReduceClass(); 而是用 TableMapReduceUtil.initTableReducerJob(tablename,THReducer.class,job);来执行reduce类。
TableMapReduceUtil类(org.apache.hadoop.hbase.mapreduce):a utility for TableMapper or TableReducer。因为本例子中的reduce继承的是TableReducer,所以也就解释了用TableMapReduceUtil来执行的原因。该类的方法有:addDependencyJars(),initTableMapperJob(),initTableReducerJob(),limitNumReduceTasks(),setNumReduceTasks()等,具体用法可以查看API。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









