







目录
1.matplotlib简介
matplotlib是Python的基本绘图模块,包含了大量的工具。
我们可以使用matplotlib创建各种图像,包括简单的折线图、柱状图等,甚至是复杂的三维图像。
matplotlib模块里有一个非常方便的子模块:pyplot,我们之后要绘制的图像主要都是依赖于这个子模块~
2.安装并且导入对应的模块
安装的时候,使用的是: pip install matplotlib 指令
和以前导入模块的方法略有不同,我们在导入matplotlib模块时,使用的是matplotlib.pyplot,可以理解为导入matplotlib模块下最常用的pyplot子模块。
通常,会使用 plt 作为matplotlib.pyplot的简写,方便以后调用。
# TODO 使用import导入matplotlib模块下的pyplot子模块
# 并使用 plt 作为该模块的简写
import matplotlib.pyplot as plt3.设置中文字体
像下面的这个情况之所以会出现,原因就是我们对于这个字体的设置没有成功,我们需要根据自己的操作系统去设置对应的字体;
解决中文不显示的问题,我们可以在导入matplotlib.pyplot后,在代码中对plt.rcParams["font.sans-serif"]进行赋值,来自定义字体。
在本地运行时,如果是Windows系统,可以把字体设置成 SimHei ;
如果是macOS系统,可以把字体设置为 Arial Unicode MS 。
# 导入matplotlib.pyplot,并使用"plt"作为该模块的简写
import matplotlib.pyplot as plt
# TODO 将字体设置为SimHei,以windows作为例子
plt.rcParams["font.sans-serif"] = "SimHei"4.创建画布
# 导入matplotlib.pyplot,并使用"plt"作为该模块的简写
import matplotlib.pyplot as plt
# 通过 rcParams 参数将字体设置为 SimHei
plt.rcParams["font.sans-serif"] = "SimHei"
# TODO 使用plt.figure()函数创建画布
# 添加参数figsize设置画布大小为(4,3)
# 添加参数facecolor设置画布颜色为'blue'
plt.figure(figsize=(4,3),facecolor='blue')创建画布之后,我们的图形并不会显示出来,我们想要图片显示出来,需要使用plt.show()函数
5.绘制折线图
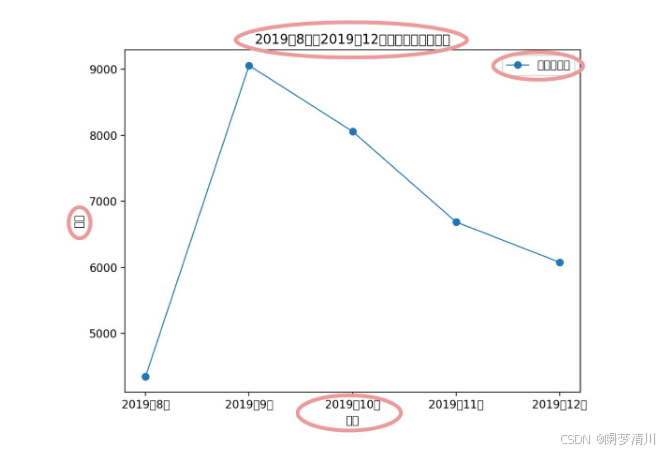
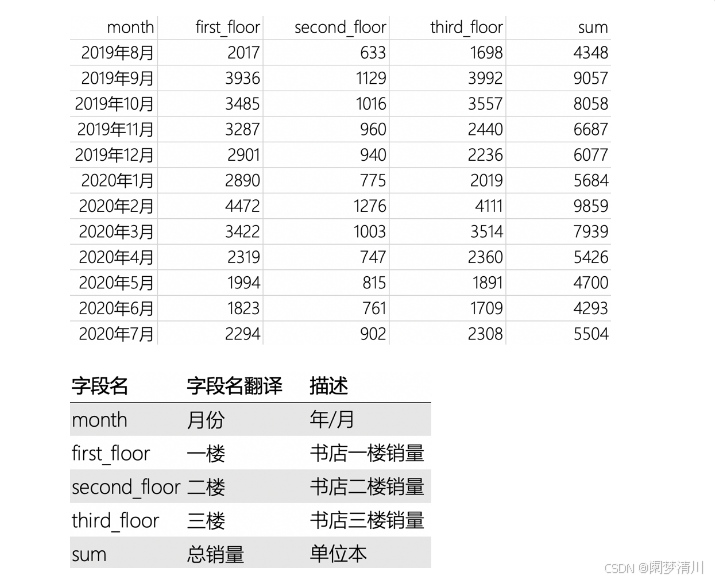
我们首先设定一个下面的场景:每一月的每层楼的销售书的数据,来回根据这个数据进行折线图的绘制;
# 导入matplotlib.pyplot,并使用"plt"作为该模块的简写
import matplotlib.pyplot as plt
# 导入pandas,并使用"pd"作为该模块的简写
import pandas as pd
# 读取路径为 "/Users/yequ/书店每月销量数据.csv" 的CSV文件,并将结果赋值给变量data
data = pd.read_csv("/Users/yequ/书店每月销量数据.csv")
# 通过 rcParams 参数将字体设置为 Arial Unicode MS
plt.rcParams["font.sans-serif"] = "Arial Unicode MS"
# TODO 使用plt.plot()函数
# 以data["month"]为x轴的值和data["sum"]为y轴的值,绘制折线图
plt.plot(data["month"],data["sum"])
# TODO 使用plt.show()函数显示图像
plt.show()这个就是先导入数据,plot函数的第一个参数就是我们的月份,第二个参数就是我们的总计的销售量 ;
6.对于折线图的美化
# 导入matplotlib.pyplot,并使用"plt"作为该模块的简写
import matplotlib.pyplot as plt
# 导入pandas,并使用"pd"作为该模块的简写
import pandas as pd
# 读取路径为 "/Users/yequ/书店每月销量数据.csv" 的CSV文件,并将结果赋值给变量data
data = pd.read_csv("/Users/yequ/书店每月销量数据.csv")
# 通过 rcParams 参数将字体设置为 Arial Unicode MS
plt.rcParams["font.sans-serif"] = "Arial Unicode MS"
# 使用plt.plot()函数
# 以data["month"]为x轴的值和data["sum"]为y轴的值,将颜色设置为"orange","o"作为标记点的样式
# "每月总销量"作为图例,绘制折线图
plt.plot(data["month"],data["sum"],color="orange",marker="o",label="每月总销量")
# TODO 使用plt.xlabel()函数,将x轴标题设置为"月份"
plt.xlabel("月份")
# TODO 使用plt.ylabel()函数,将y轴标题设置为"销量"
plt.ylabel("销量")
# TODO 使用plt.title()函数,将图表标题设置为"2019年8月至2020年7月书店每月销量走势"
plt.title("2019年8月至2020年7月书店每月销量走势")
# 使用plt.legend()函数显示图例
plt.legend()
# 使用plt.show()函数显示图像
plt.show()- color是用来设置这个曲线的颜色;
- marker是用来表示这个曲线上面的标记点的形状;
- label是用来设计这个图例的,表明这个标记代表什么;legend函数显示图例
- xlabel,ylabel分别对于这个x,y轴进行说明,title就是这个折线图的题目说明;
- 这个地方顺便说明一下这个柱状图:使用plt.bar函数绘制,也是使用的xlabel和ylabel进行表示这个横纵坐标的含义,使用width进行这个柱状图的宽度的设置;
7.散点图的绘制
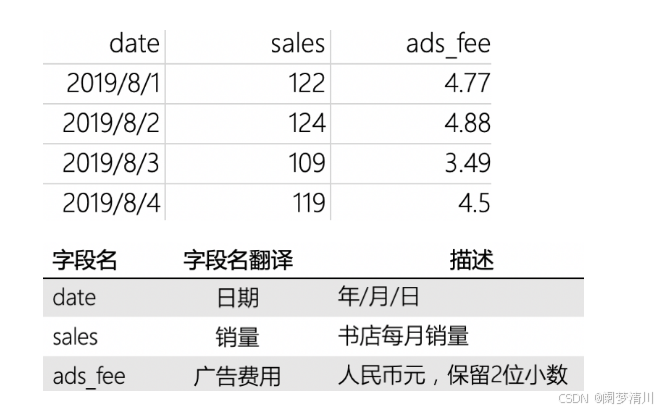
下面这个就是散点图的一个场景,绘制的是这个销量和广告费用的关系
其实可视化这个专题,都是大同小异:
# 导入matplotlib.pyplot,并使用"plt"作为该模块的简写
import matplotlib.pyplot as plt
# 导入pandas,并使用"pd"作为该模块的简写
import pandas as pd
# 读取路径为 "/Users/yequ/书店图书销量和广告费用.csv" 的CSV文件,并将结果赋值给变量data
data = pd.read_csv("/Users/yequ/书店图书销量和广告费用.csv")
# 通过 rcParams 参数将字体设置为 Arial Unicode MS
plt.rcParams["font.sans-serif"] = "Arial Unicode MS"
# TODO 使用plt.scatter()函数
# 以data["ads_fee"]为x轴的值和data["sales"]为y轴的值,绘制散点图
plt.scatter(data["ads_fee"],data["sales"])
# TODO 使用plt.xlabel()函数,将x轴标题设置为"广告费用"
plt.xlabel("广告费用")
# TODO 使用plt.ylabel()函数,将y轴标题设置为"销量"
plt.ylabel("销量")
# 使用plt.show()函数显示图像
plt.show()- 导入模块
- 读取文件内容
- 设置字体
- scatter函数用来绘制散点图
- xlabel和ylabel分别表示的就是横纵坐标
8.双y轴叠加图
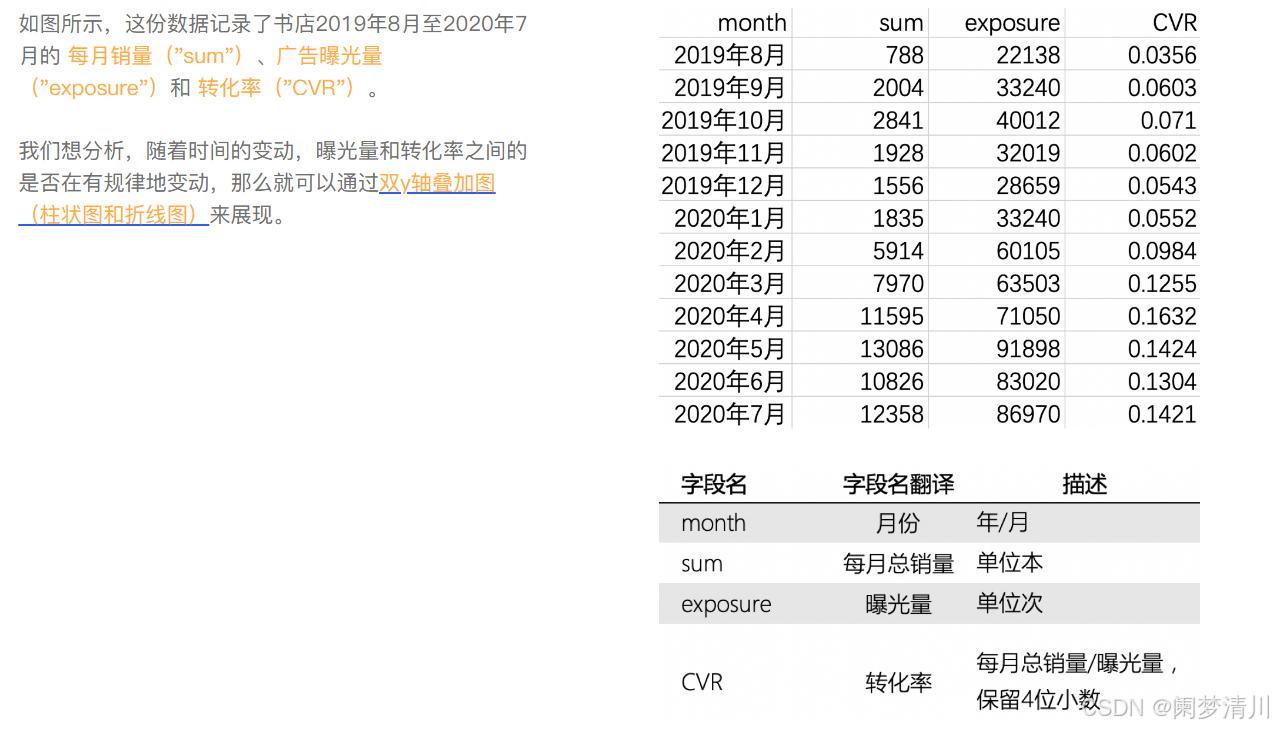
实际上这个图像需要我们的两个因变量都和这个自变量x有关系,这样的话,随着这个x的变化,这个两个y都可以有自己的变化,方便我们查看这个走势;
# 导入matplotlib.pyplot,并使用"plt"作为该模块的简写
import matplotlib.pyplot as plt
# 导入pandas,并使用"pd"作为该模块的简写
import pandas as pd
# 使用pd.read_csv()函数
# 读取路径为 "/Users/yequ/每月曝光量和转化率.csv" 的CSV文件,并赋值给变量data
data = pd.read_csv("/Users/yequ/每月曝光量和转化率.csv")
# 通过给 plt.rcParams["font.sans-serif"] 赋值
# 将字体设置为 Arial Unicode MS
plt.rcParams["font.sans-serif"] = "Arial Unicode MS"
# TODO 使用plt.bar()函数
# 以data["month"]为x轴的值,data["exposure"]为y轴的值
# 绘制曝光量的柱状图
plt.bar(data["month"],data["exposure"])
# TODO 使用plt.twinx()函数,添加另一个y轴
plt.twinx()
# TODO 使用plt.plot()函数
# 以data["month"]为x轴的值,data["CVR"]为y轴的值
# 绘制转化率的折线图
plt.plot(data["month"],data["CVR"])
# 使用plt.show()函数显示图像
plt.show()- bar绘制柱状图,plot绘制折线图;
- twinx用来增加一个y轴;
- 我们在一个图里面绘制两个图像,如果都设置一个图例,就会出现下面的问题:
存在一个问题:柱状图和折线图的图例重合在了一起。
如果在绘图的时侯不设置图例位置,那么matplotlib会自动在图像中选择最合适的位置。
所以,柱状图和折线图的图例都被matplotlib模块放在了右上角,产生了重叠。
# TODO 使用plt.legend()函数和loc参数,将图例显示在左上角"upper left"
plt.legend(loc="upper left")9.簇形柱状图
这个图形就是对于一个维度上面的三个数据进行综合展示,比如和这个销售数据,同样是1月份的销售数据,可以同时显示出来2022年的1月,2023年的1月,2024年的1月;
# 导入matplotlib.pyplot,并使用"plt"作为该模块的简写
import matplotlib.pyplot as plt
# 导入pandas,并使用"pd"作为该模块的简写
import pandas as pd
# 使用pd.read_csv()函数
# 读取路径为 "/Users/yequ/书店每月销量数据.csv" 的CSV文件,并赋值给变量data
data = pd.read_csv("/Users/yequ/书店每月销量数据.csv")
# 通过给 plt.rcParams["font.sans-serif"] 赋值
# 将字体设置为 Arial Unicode MS
plt.rcParams["font.sans-serif"] = "Arial Unicode MS"
# TODO 对data变量使用plot.bar()函数绘制指定簇形柱状图
data.plot.bar("month",["first_floor","second_floor","third_floor"])
# 使用plt.show()函数显示图像
plt.show()- plot.bar就是用来绘制这个簇形柱状图的,第一个参数就是横坐标,第二个参数就是一个列表,表示的就是对个需要同时展示的结果;
10.百分比堆积柱状图
# 导入matplotlib.pyplot,并使用"plt"作为该模块的简写
import matplotlib.pyplot as plt
# 导入pandas,并使用"pd"作为该模块的简写
import pandas as pd
# 使用pd.read_csv()函数
# 读取路径为 "/Users/yequ/书店每月销量数据百分比.csv" 的CSV文件,并赋值给变量data
data = pd.read_csv("/Users/yequ/书店每月销量数据百分比.csv")
# 通过给 plt.rcParams["font.sans-serif"] 赋值
# 将字体设置为 Arial Unicode MS
plt.rcParams["font.sans-serif"] = "Arial Unicode MS"
# TODO 使用plot.bar()函数
# 根据data变量,以"month"为x轴,["一楼","二楼","三楼"]为y轴
# 绘制百分比堆积柱状图
data.plot.bar("month",["一楼","二楼","三楼"],stacked=True)
# 使用plt.show()函数显示图像
plt.show()stacked=True会使DataFrame中每一行的值垂直堆叠放置,形成堆积柱状图。- 效果展示:

11.绘制多个子图(一个画布上面)
# 导入matplotlib.pyplot,并使用"plt"作为该模块的简写
import matplotlib.pyplot as plt
# 导入pandas,并使用"pd"作为该模块的简写
import pandas as pd
# 读取路径为 "/Users/yequ/书店每月销量数据.csv" 的CSV文件,并将结果赋值给变量data
data = pd.read_csv("/Users/yequ/书店每月销量数据.csv")
# 读取路径为 "/Users/yequ/书店图书销量和广告费用.csv" 的CSV文件,并将结果赋值给变量df
df = pd.read_csv("/Users/yequ/书店图书销量和广告费用.csv")
# 通过 rcParams 参数将字体设置为 Arial Unicode MS
plt.rcParams["font.sans-serif"] = "Arial Unicode MS"
# 使用plt.subplot()函数添加4个子图
# 子图有两行两列
# 选择序号为1子图
plt.subplot(2,2,1)
# 使用plt.plot()函数绘制折线图
plt.plot(data["month"],data["sum"])
# TODO 使用plt.xticks()函数旋转x轴的刻度至90度
plt.xticks(rotation=90)
# 选择序号为2子图
plt.subplot(2,2,2)
# 使用plt.scatter()函数
# 以df["ads_fee"]为x轴的值和df["sales"]为y轴的值,绘制散点图
plt.scatter(df["ads_fee"],df["sales"])
# 选择序号为3的子图
plt.subplot(2,2,3)
# 选择序号为4子图
plt.subplot(2,2,4)
# TODO 使用plt.tight_layout()函数来调整子图布局
plt.tight_layout()
# 使用plt.show()函数显示图像
plt.show()- plt.tight_layout这个就是为了调整我们的子图的布局情况;
- suplot函数用来绘制子图,前面的两个参数表示的是这个子图的行数和列数,第三个参数表示的就是这个子图位于那一个顺序上面;
- xticks(rotation=90)这个是为了旋转我们的x轴说明文字的位置,不让我们的下面的子图遮挡x的说明;
- 由于pandas模块不能像matplotlib.pyplot一样默认将图像绘制到当前的子图坐标轴上,所以需要传入
ax=plt.gca(),来确保图像绘制在当前子图的坐标轴中。 -
# 导入matplotlib.pyplot,并使用"plt"作为该模块的简写 import matplotlib.pyplot as plt # 导入pandas,并使用"pd"作为该模块的简写 import pandas as pd # 读取路径为 "/Users/yequ/书店每月销量数据.csv" 的CSV文件,并将结果赋值给变量data data = pd.read_csv("/Users/yequ/书店每月销量数据.csv") # 读取路径为 "/Users/yequ/书店图书销量和广告费用.csv" 的CSV文件,并将结果赋值给变量df df = pd.read_csv("/Users/yequ/书店图书销量和广告费用.csv") # 使用pd.read_csv()函数 # 读取路径为 "/Users/yequ/书店每月销量数据百分比.csv" 的CSV文件,并赋值给变量percentData percentData = pd.read_csv("/Users/yequ/书店每月销量数据百分比.csv") # 通过 rcParams 参数将字体设置为 Arial Unicode MS plt.rcParams["font.sans-serif"] = "Arial Unicode MS" #-------------------------------------------------------- # 使用plt.subplot()函数添加4个子图 # 子图有两行两列 # 选择序号为1子图 plt.subplot(2,2,1) # 使用plt.plot()函数绘制折线图 plt.plot(data["month"],data["sum"]) # 使用plt.xticks()函数旋转x轴的刻度至90度 plt.xticks(rotation=90) # 使用plt.xlabel()函数,将x轴标题设置为"月份" plt.xlabel("月份") # 使用plt.ylabel()函数,将y轴标题设置为"销量" plt.ylabel("销量") #--------------------------------------------------------- # 选择序号为2子图 plt.subplot(2,2,2) # 使用plt.scatter()函数 # 以df["ads_fee"]为x轴的值和df["sales"]为y轴的值,绘制散点图 plt.scatter(df["ads_fee"],df["sales"]) # 使用plt.xlabel()函数,将x轴标题设置为"广告费用" plt.xlabel("广告费用") # 使用plt.ylabel()函数,将y轴标题设置为"销量" plt.ylabel("销量") #-------------------------------------------------------- # 选择序号为3的子图 plt.subplot(2,2,3) # 使用plot.bar()函数和ax=plt.gca() # 根据data中的数据 # 以"month"为x轴,["first_floor","second_floor","third_floor"]为y轴 # 绘制簇形柱状图 data.plot.bar("month",["first_floor","second_floor","third_floor"],ax=plt.gca()) # 使用plt.xlabel()函数,将x轴标题设置为"月份" plt.xlabel("月份") # 使用plt.ylabel()函数,将y轴标题设置为"销量" plt.ylabel("销量") #-------------------------------------------------------------- # 选择序号为4子图 plt.subplot(2,2,4) # 使用plot.bar()函数,stacked=True和ax=plt.gca() # 根据percentData中的数据 # 以"month"为x轴,绘制对比["一楼","二楼","三楼"]的百分比堆积柱状图 # 这个是用的就是pandas模块 percentData.plot.bar("month",["一楼","二楼","三楼"],stacked=True,ax=plt.gca()) # 使用plt.xlabel()函数,将x轴标题设置为"月份" plt.xlabel("月份") # 使用plt.ylabel()函数,将y轴标题设置为"占比" plt.ylabel("占比") #----------------------------------------------------------- # 使用plt.tight_layout()函数来调整子图布局 plt.tight_layout() # 使用plt.show()函数显示图像 plt.show()
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









