






代码复用与函数递归
代码复用与模块化设计
紧耦合:两个部分交流很多,无法独立存在
松耦合:两个部分交流较少,可以独立存在
函数递归的理解
链条:计算过程中存在递归链条
基例:存在一个或多个不需要再次递归的基例
函数+分支语句
字符串s反转后输出
def rus(s):
if s=="":
return s
else:
return rvs(s[1:])+s[0]
斐波那契数列
def f(n):
if n==1 or n==2:
return 1
else:
return f(n-1)+f(n-2)
汉诺塔
count=0
def hanoi(n,src,dst,mid):
global count
if n==1:
print("{}:{}->{}".format(1,src,dst))
count+=1
else:
hanoi(n-1,src,mid,dst)
print("{}:{}->{}".format(n,src,dst))
count+=1
hanoi(n-1,mid,dst,src)
PyInstaller库
将源代码转换成可执行文件

组合数据类型
集合类型:不存在可变数据类型
建立集合类型用{} 或set()
建立空集合类型必须使用set()
集合操作符

增强操作符
集合处理方法
S.clear() 移除S中所有元素
S.pop() 随即返回S的一个元素,更新S,若S为空产生KeyError异常
S.copy() 返回集合S的一个副本
len(S) 返回集合S的元素个数
x in S 判断S中元素x,x在集合S中,返回True,否则返回False
x not in S 判断S中元素x,x不在集合S中,返回True,否则返回False
set(x)将其他类型变量x转变为集合类型
A={"p","y",123}
for item in A:
print(item,end="")
try:
while True:
print(A.pop(),end="")
except:
pass
数据去重
序列类型及操作
序列是具有先后关系的一组元素,是一维元素向量,元素类型可以不同(基本数据类型)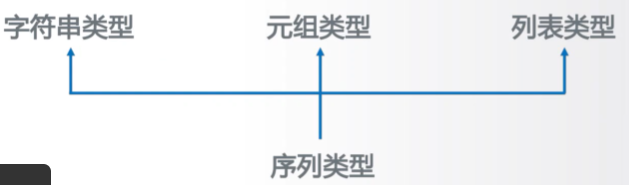
序号:正向递增(0)&反向递减(-1)
序列通用操作符
len(s)长度 min(s)最小元素 max(s)最大元素
s.index(x)或s.index(x,i,j)返回序列s从i开始到j位置中第一次出现元素x的位置
元组 是一种序列类型,一旦创建就不能被修改
使用小括号()或tuple()创建,元素间用,分隔
可以使用或不使用小括号
列表 是序列类型的一种扩展,十分常用,是一种序列类型,创建后可以随意被修改。使用【】或list()创建,元素间用逗号,分隔

基本统计值
总个数:len()
求和:for…in
def getNum():
nums=[]
iNumStr=input("请输入数字(回车退出):")
while iNumStr!="":
nums.append(eval(iNumStr))
iNumStr=input("请输入数字(回车退出)")
return nums
def mean(numbers): #计算平均数
s=0.0
for num in numbers:
s=s+num
return s/len(numbers)
def dev(numbers,mean): #计算方差
sdev=0.0
for num in numbers:
sdev=sdev+(num-mean)**2
return pow(sdev/(len(numbers)-1),0.5)
def median(numbers): #计算中位数
sorted(numbers)
size=len(numbers)
if size % 2 ==0:
med = (numbers[size//2-1]+numbers[size//2]/2)
else:
med = numbers[size//2]
return med
字典类型及操作
字典类型定义
映射是一种键(索引)和值(数据)的对应
映射类型由用户为数据定义索引
键值对:键是数据索引的扩展
字典是键值对的集合,键值对之间无序
生成字典: 采用{}或dict()创建,键值对用:表示
<字典变量>={<键1>:<值1>,<键2>:<值2>,…,<键n>:<值n>}
也可以赋予它新的键值对应关系
<值>=<字典变量>[<键>]
<字典变量>[<键>]=<值>
{}空默认生成字典类型


jieba库
精确模式:把文本精确的切分开,不存在冗余单词
全模式:把文本中所有可能的词语都扫描出来,有冗余
搜索引擎模式:在精确模式基础上,对长词再次切分


文本词频统计
def getText():
txt=open("hamlet.txt","r").read()
txt=txt.lower()
for ch in "'!#$%^&*()_+=<>,.{}{}:;'\|/":
txt=txt.replace(ch,"")
return txt
hamletTxt=getText()
words=hamletTxt.split()
counts={}
for word in words:
counts[word]=count.get(word,0)+1
items=list(count.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(10):
word,count=items[i]
print("{0:<10}{1:>5}".format(word ,count))















 382
382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









