







系统中针对Blob字段操作一直是单独处理的,也就没有特别的关注过,默认该逻辑唯一且正确 o(*︶*)o
最近做了几个测试,发现了一个问题,当Blob数据被更新后,再读取Blob数据解析的时候程序异常了 o(╯╰)o
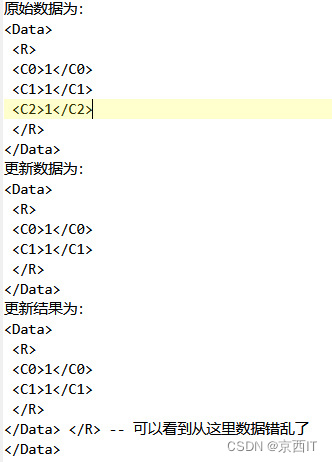
用pl/sql查出更新记录,点击查看Blob信息后发现,数据里面的标签错位了(存储的是xml报文),这才导致xml解析的时候报错。
那么是什么原因产生的呢?又试验了多次后确定了产生的条件,如下:
1、Blob存储的是文本文件数据;
2、原有Blob字段有数据信息;
3、更新的数据信息比原有的数据信息小;
举例:怎么也搞不定特殊字符,还是弄张图片算了 (#~#)
非文本文件不会出现上述问题 ╮(╯╰)╭,测试过的文件类型有:xls、xlsx、pdf、jpg、png
JAVA程序逻辑如下:
1、使用 select b1 from t1 for update方式锁住更新记录;
2、使用getBlob获取对象(PS:使用WebLogic的JNDI连接数据库时,需转换成weblogic.jdbc.vendor.oracle.OracleThinBlob对象才可操作)
3、通过流方式写入数据(应该就是这里的问题)
环境:JDK 1.8、Oracle 12c
解决方案:
一、
新增数据的程序逻辑为先插入该表的其他信息,同时通过empty_blob()函数初始化Blob字段,再通过流写入数据到Blob字段,这个时候是不会出现问题的。
那么在更新Blob字段之前,先通过update t1 set b1 = empty_blob()重新初始化Blob字段,再写入数据就可以避免上面的问题了,经测试此逻辑ok。
二、
不知道是JDBC升级后才支持的还是咋的,现在可以通过PreparedStatement对象的setBinaryStream方法操作Blob字段。插入的时候也无需使用empty_blob()函数初始化Blob字段,直接操作即可。
在Tomcat、WebLogic、IDea等环境下程序测试都ok。
结论:
强烈建议使用PreparedStatement对象的setBinaryStream方法操作Blob字段,新增和更新逻辑可以完全分离,且不再使用for update操作(容易有锁)。















 2420
2420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









