







 该博客围绕波士顿房价数据集展开,介绍了其包含506个案例及14个属性,给出下载地址。对线性回归代码进行改进,从本地Excel文件加载数据。运行PredictBostonHousing.py文件后,得到测试集可视化、梯度算法训练损失等多种结果文件。
该博客围绕波士顿房价数据集展开,介绍了其包含506个案例及14个属性,给出下载地址。对线性回归代码进行改进,从本地Excel文件加载数据。运行PredictBostonHousing.py文件后,得到测试集可视化、梯度算法训练损失等多种结果文件。
目录
参考文献
数据来源:
Dataset之Boston:Boston波士顿房价数据集的简介、下载、使用方法之详细攻略_波士顿房价数据集下载-CSDN博客
参考书籍:《机器学习入门——基于数学原理的Python实战》戴璞微 潘斌著
代码运行环境
- 语言:Python3.6
- 集成环境:Anaconda3
- 编程IDE:Pycharm
一、Boston波士顿房价数据集的简介
该数据集包含美国人口普查局收集的美国马萨诸塞州波士顿住房价格的有关信息, 数据集很小,只有506个案例。
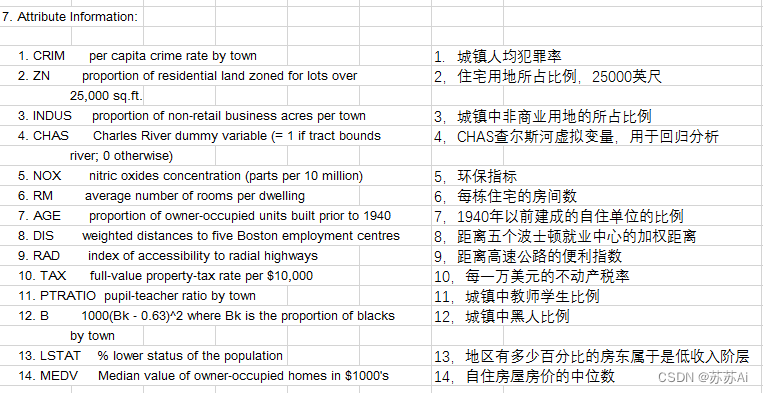
数据集都有以下14个属性:
- CRIM--城镇人均犯罪率 ------【城镇人均犯罪率】
- ZN - 占地面积超过25,000平方英尺的住宅用地比例。 ------【住宅用地所占比例】
- INDUS - 每个城镇非零售业务的比例。 ------【城镇中非商业用地占比例】
- CHAS - Charles River虚拟变量(如果是河道,则为1;否则为0 ------【查尔斯河虚拟变量,用于回归分析】
- NOX - 一氧化氮浓度(每千万份) ------【环保指标】
- RM - 每间住宅的平均房间数 ------【每栋住宅房间数】
- AGE - 1940年以前建造的自住单位比例 ------【1940年以前建造的自住单位比例 】
- DIS -波士顿的五个就业中心加权距离 ------【与波士顿的五个就业中心加权距离】
- RAD - 径向高速公路的可达性指数 ------【距离高速公路的便利指数】
- TAX - 每10,000美元的全额物业税率 ------【每一万美元的不动产税率】
- PTRATIO - 城镇的学生与教师比例 ------【城镇中教师学生比例】
- B - 1000(Bk - 0.63)^ 2其中Bk是城镇黑人的比例 ------【城镇中黑人比例】
- LSTAT - 人口状况下降% ------【房东属于低等收入阶层比例】
- MEDV - 自有住房的中位数报价, 单位1000美元 ------【自住房屋房价中位数】
二、Boston波士顿房价数据集的下载
下载地址:https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data
三、线性回归代码:
在源代码的基础上进行了一些改进,源代码的问题:“load_boston由于道德问题,该数据集已从 1.2 版本开始从 scikit-learn 中删除。”
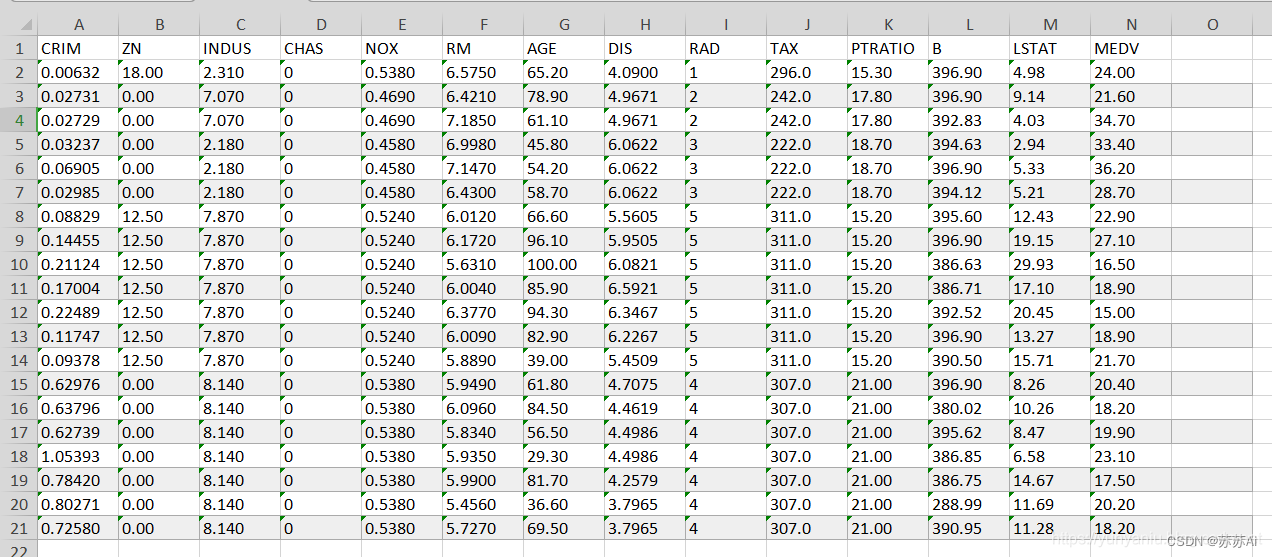
改代码:以从本地 Excel 文件加载住房数据而不是使用load_bostonscikit-learn 中的函数,需要将调用替换load_boston为使用 读取 Excel 文件的代码pandas。由于数据保存在桌面上,路径为“C:\Users\31454\Desktop\housing_data.xlsx”,因此需要调整代码中的路径以匹配运行它的位置。以下是更新后的代码片段:
1、PredictBostonHousing.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/9/1610:19
# @Author : DaiPuWei
# E-Mail : 771830171@qq.com
# blog : https://blog.csdn.net/qq_30091945
# @Site : 中国民航大学北教25实验室506
# @File : PredictConcreteCompressiveStrength.py
# @Software: PyCharm
from LinearRegression import LinearRegression
from sklearn.model_selection import train_test_split
import matplotlib as mpl
import matplotlib
matplotlib.use('TkAgg') # 指定使用 TkAgg 后端
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
def Merge(data,col):
#这是生成DataFrame数据的函数
#:param data:输入数据
#:param col:列名称数组
Data = np.array(data).T
return pd.DataFrame(Data,columns=col)
def run_main():
"""
这是主函数
"""
# 从本地 Excel 文件加载数据,不再使用 load_boston
# 将文件路径替换为你电脑上 Excel 文件实际存储的路径
housing_data_path = "C:/Users/31454/Desktop/housing_data.xlsx"
housing_data = pd.read_excel(housing_data_path)
# 假设 Excel 文件的格式与波士顿数据集一致
# 特征在前 13 列,目标值(房价)在最后一列
InputData = housing_data.iloc[:, :-1].values
Result = housing_data.iloc[:, -1].values
# 为了方便实验,只取第 6 维特征,即为平均房间数目
InputData = InputData[:, 5].reshape(-1, 1)
Result = Result.reshape(-1, 1)
# 把数据集分成训练数据集和测试数据集
train_data,test_data,train_result,test_result = \
train_test_split(InputData,Result,test_size=0.1,random_state=50)
# 解决Matplotlib中的中文乱码问题,以便于后面实验结果可视化
mpl.rcParams['font.sans-serif'] = [u'simHei']
mpl.rcParams['axes.unicode_minus'] = False
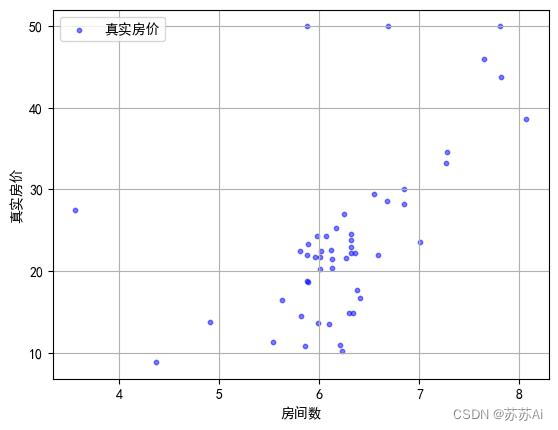
# 利用散点图可视化测试数据集,并保存可视化结果
col = ['真实房价']
plt.scatter(test_data,test_result,alpha=0.5,c='b',s=10)
plt.grid(True)
plt.legend(labels = col,loc='best')
plt.xlabel("房间数")
plt.ylabel("真实房价")
plt.savefig("./测试集可视化.jpg",bbox_inches='tight')
plt.show()
plt.close()
# 开始构建线性回归模型
col = np.shape(train_data)[1]+1
# 初始化线性回归参数theta
theta = np.random.random((col,1))
# BGD优化的线性回归模型
linearregression_BGD = LinearRegression(train_data, train_result,theta)
# SGD优化的线性回归模型
linearregression_SGD = LinearRegression(train_data, train_result,theta)
# MBGD优化的线性回归模型
linearregression_MBGD = LinearRegression(train_data, train_result,theta)
# 正则方程优化的线性回归模型
linearregression_NormalEquation = LinearRegression(train_data, train_result,theta)
# 训练模型
iter = 30000 # 迭代次数
alpha = 0.001 # 学习率
batch_size = 64 # 小样本规模
# BGD的训练损失
BGD_train_cost = linearregression_BGD.train_BGD(iter,alpha)
# SGD的训练损失
SGD_train_cost = linearregression_SGD.train_SGD(iter,alpha)
# MBGD的训练损失
MBGD_train_cost = linearregression_MBGD.train_MBGD(iter,batch_size,alpha)
# 利用正规方程获取参数
linearregression_NormalEquation.getNormalEquation()
# 三种梯度下降算法迭代训练误差结果可视化,并保存可视化结果
col = ['BGD','SGD','MBGD']
iter = np.arange(iter)
plt.plot(iter, BGD_train_cost, 'r-.')
plt.plot(iter, SGD_train_cost, 'b-')
plt.plot(iter, MBGD_train_cost, 'k--')
plt.grid(True)
plt.xlabel("迭代次数")
plt.ylabel("平均训练损失")
plt.legend(labels = col,loc = 'best')
plt.savefig("./三种梯度算法的平均训练损失.jpg",bbox_inches='tight')
plt.show()
plt.close()
# 三种梯度下降算法的训练损失
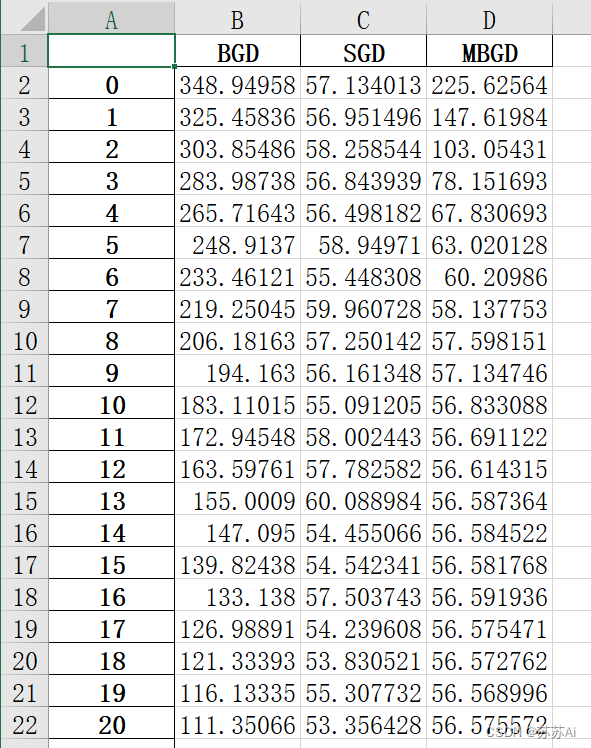
# 整合三种梯度下降算法的训练损失到DataFrame
train_cost = [BGD_train_cost,SGD_train_cost,MBGD_train_cost]
train_cost = Merge(train_cost,col)
# 保存三种梯度下降算法的训练损失及其统计信息
train_cost.to_excel("./三种梯度下降算法的训练训练损失.xlsx")
train_cost.describe().to_excel("./三种梯度下降算法的训练训练损失统计.xlsx")
# 计算4种调优算法下的拟合曲线
x = np.arange(int(np.min(test_data)), int(np.max(test_data)+1))
x = x.reshape((len(x),1))
# BGD算法的拟合曲线
BGD = linearregression_BGD.test(x)
# SGD算法的拟合曲线
SGD = linearregression_SGD.test(x)
# MBGD算法的拟合曲线
MBGD = linearregression_MBGD.test(x)
# 正则方程的拟合曲线
NormalEquation = linearregression_NormalEquation.test(x)
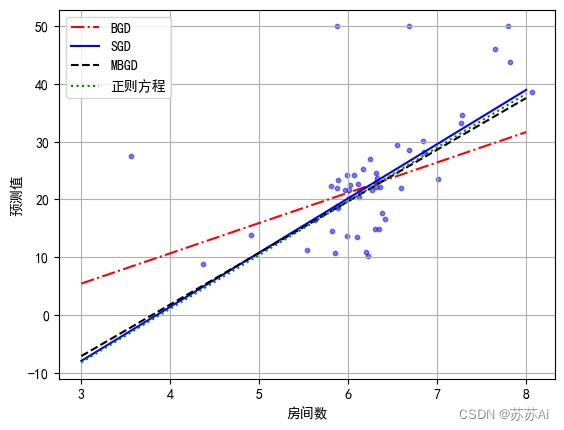
# 4种模型的拟合直线可视化,并保存可视化结果
col = ['BGD', 'SGD', 'MBGD', '正则方程']
plt.plot(x, BGD,'r-.')
plt.plot(x, SGD, 'b-')
plt.plot(x, MBGD, 'k--')
plt.plot(x, NormalEquation, 'g:',)
plt.scatter(test_data,test_result,alpha=0.5,c='b',s=10)
plt.grid(True)
plt.xlabel("房间数")
plt.ylabel("预测值")
plt.legend(labels = col,loc = 'best')
plt.savefig("./预测值比较.jpg",bbox_inches='tight')
plt.show()
plt.close()
# 利用测试集进行线性回归预测
# BGD算法的预测结果
BGD_predict = linearregression_BGD.test(test_data)
# SGD算法的预测结果
SGD_predict = linearregression_SGD.test(test_data)
# MBGD算法的预测结果
MBGD_predict = linearregression_MBGD.test(test_data)
# 正则方程的预测结果
NormalEquation_predict = linearregression_NormalEquation.test(test_data)
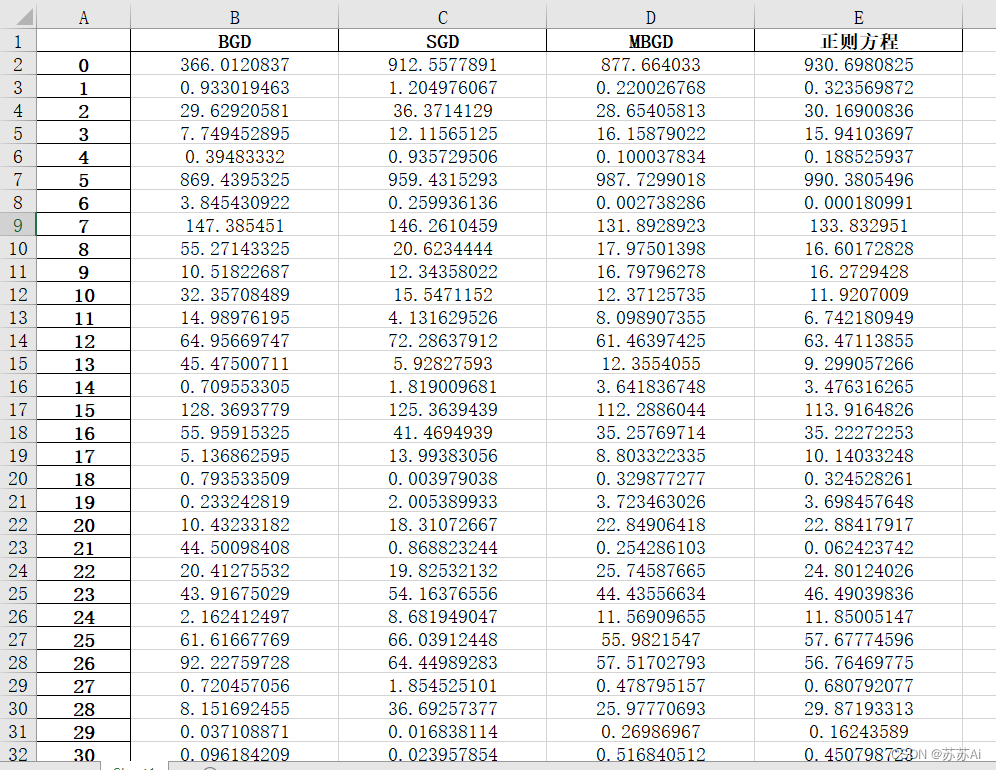
# 保存预测数据
# A.tolist()是将numpy.array转化为python的list类型的函数,是将A的所有元素
# 当作一个整体作为list的一个元素,因此我们只需要A.tolist()的第一个元素
data = [test_data.T.tolist()[0],test_result.T.tolist()[0],BGD_predict,
SGD_predict,MBGD_predict,NormalEquation_predict]
col = ["平均房间数目","真实房价",'BGD预测结果',
'SGD预测结果','MBGD预测结果','正规方程预测结果']
Data = Merge(data,col)
Data.to_excel('./测试数据与预测结果.xlsx')
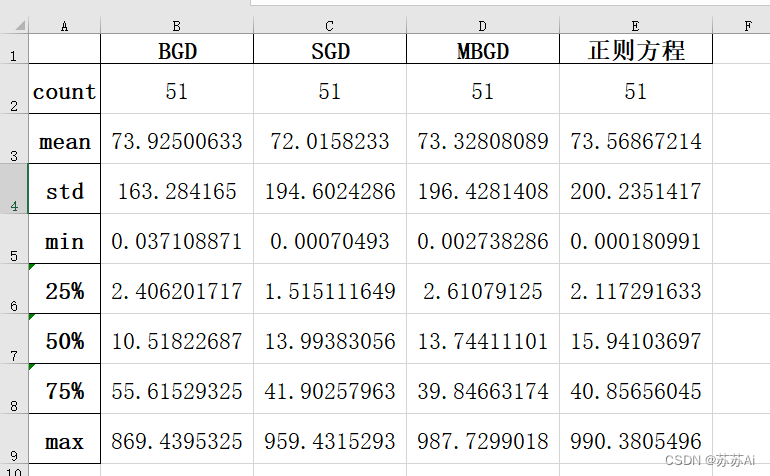
# 计算4种算法的均方误差以及其统计信息
# test_result之前的形状为(num,1),首先计算其转置后
# 获得其第一个元素即可
test_result = test_result.T[0]
# BGD算法的测试均方误差
BGD_error = ((BGD_predict-test_result)**2)
# SGD算法的测试均方误差
SGD_error = ((SGD_predict-test_result)**2)
# MBGD算法的测试均方误差
MBGD_error = ((MBGD_predict-test_result)**2)
# 正则方程的测试均方误差
NormalEquation_error = ((NormalEquation_predict-test_result)**2)
# 整合四种算法的测试均方误差到DataFrame
error = [BGD_error,SGD_error,MBGD_error,NormalEquation_error]
col = ['BGD', 'SGD', 'MBGD', '正则方程']
error = Merge(error,col)
# 保存四种测试均方误差及其统计信息
error.to_excel("./四种算法的均方预测误差原始数据.xlsx")
error.describe().to_excel("./四种算法的均方预测误差统计.xlsx")
if __name__ == '__main__':
run_main()2、 LinearRegression.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/9/1518:58
# @Author : DaiPuWei
# E-Mail : 771830171@qq.com
# blog : https://blog.csdn.net/qq_30091945
# @Site : 中国民航大学北教25实验室506
# @File : LinearRegression.py
# @Software: PyCharm
import numpy as np
"""
这是线性回归算法的类,其中主要包括BGD、SGD、MBGD
三种梯度下降算法和正则方程方法这4种实现算法。在调整
梯度下降算法调整参数的损失函数为训练数据集的均方误差。
"""
class LinearRegression(object):
def __init__(self,input_data,realresult,theta = None):
"""
:param input_data: 输入数据
:param realresult: 真实结果
:param theta: 线性回归的参数,默认是None,即可以没有
"""
# 获得输入数据集的形状
row,col = np.shape(input_data)
# 构造输入数据数组
self.InputData = [0]*row
# 给每组输入数据增添常数项1
for (index,data) in enumerate(input_data):
Data = [1.0]
# 把input_data拓展到Data内,即把input_data的每一维数据添加到Data
Data.extend(list(data))
self.InputData[index] = Data
self.InputData = np.array(self.InputData)
# 构造输入数据对应的结果
self.Result = realresult
# thetha参数不为None时,利用thetha构造模型参数
if theta is not None:
self.Theta = theta
else:
# 随机生成服从标准正态分布的参数
self.Theta = np.random.normal((col+1,1))
def Cost(self):
"""
这是计算损失函数的函数
"""
# 在线性回归里的损失函数定义为真实结果与预测结果之间的均方误差
# 首先计算输入数据的预测结果
predict = self.InputData.dot(self.Theta).T
# 计算真实结果与预测结果之间的均方误差
cost = predict-self.Result.T
cost = np.average(cost**2)
return cost
def BGD(self,alpha):
"""
这是利用BGD算法进行一次迭代调整参数的函数
:param alpha: 学习率
"""
# 定义梯度增量数组
gradient_increasment = []
# 对输入的训练数据及其真实结果进行依次遍历
for (input_data,real_result) in zip(self.InputData,self.Result):
# 计算每组input_data的梯度增量,并放入梯度增量数组
g = (real_result-input_data.dot(self.Theta))*input_data
gradient_increasment.append(g)
# 按列计算属性的平均梯度增量
avg_g = np.average(gradient_increasment,0)
# 改变平均梯度增量数组形状
avg_g = avg_g.reshape((len(avg_g),1))
# 更新参数Theta
self.Theta = self.Theta + alpha*avg_g
def SGD(self,alpha):
"""
这是利用SGD算法进行一次迭代调整参数的函数
:param alpha: 学习率
"""
# 首先将数据集随机打乱,减小数据集顺序对参数调优的影响
shuffle_sequence = self.Shuffle_Sequence()
self.InputData = self.InputData[shuffle_sequence]
self.Result = self.Result[shuffle_sequence]
# 对训练数据集进行遍历,利用每组训练数据对参数进行调整
for (input_data,real_result) in zip(self.InputData,self.Result):
# 计算每组input_data的梯度增量
g = (real_result-input_data.dot(self.Theta))*input_data
# 调整每组input_data的梯度增量的形状
g = g.reshape((len(g),1))
# 更新线性回归模型参数
self.Theta = self.Theta + alpha * g
def Shuffle_Sequence(self):
"""
这是在运行SGD算法或者MBGD算法之前,随机打乱后原始数据集的函数
"""
# 首先获得训练集规模,之后按照规模生成自然数序列
length = len(self.InputData)
random_sequence = list(range(length))
# 利用numpy的随机打乱函数打乱训练数据下标
random_sequence = np.random.permutation(random_sequence)
return random_sequence # 返回数据集随机打乱后的数据序列
def MBGD(self,alpha,batch_size):
"""
这是利用MBGD算法进行一次迭代调整参数的函数
:param alpha: 学习率
:param batch_size: 小样本规模
"""
# 首先将数据集随机打乱,减小数据集顺序对参数调优的影响
shuffle_sequence = self.Shuffle_Sequence()
self.InputData = self.InputData[shuffle_sequence]
self.Result = self.Result[shuffle_sequence]
# 遍历每个小批量样本
for start in np.arange(0, len(shuffle_sequence), batch_size):
# 判断start+batch_size是否大于数组长度,
# 防止最后一组小样本规模可能小于batch_size的情况
end = np.min([start + batch_size, len(shuffle_sequence)])
# 获取训练小批量样本集及其标签
mini_batch = shuffle_sequence[start:end]
Mini_Train_Data = self.InputData[mini_batch]
Mini_Train_Result = self.Result[mini_batch]
# 定义梯度增量数组
gradient_increasment = []
# 对小样本训练集进行遍历,利用每个小样本的梯度增量的平均值对模型参数进行更新
for (data,result) in zip(Mini_Train_Data,Mini_Train_Result):
# 计算每组input_data的梯度增量,并放入梯度增量数组
g = (result - data.dot(self.Theta)) * data
gradient_increasment.append(g)
# 按列计算每组小样本训练集的梯度增量的平均值,并改变其形状
avg_g = np.average(gradient_increasment, 0)
avg_g = avg_g.reshape((len(avg_g), 1))
# 更新模型参数theta
self.Theta = self.Theta + alpha * avg_g
def getNormalEquation(self):
"""
这是利用正规方程计算模型参数Thetha
"""
"""
0.001*np.eye(np.shape(self.InputData.T))是
防止出现原始XT的行列式为0,即防止原始XT不可逆
"""
# 获得输入数据数组形状
col,rol = np.shape(self.InputData.T)
# 计算输入数据矩阵的转置
XT = self.InputData.T+0.001*np.eye(col,rol)
# 计算矩阵的逆
inv = np.linalg.inv(XT.dot(self.InputData))
# 计算模型参数Thetha
self.Theta = inv.dot(XT.dot(self.Result))
def train_BGD(self,iter,alpha):
"""
这是利用BGD算法迭代优化的函数
:param iter: 迭代次数
:param alpha: 学习率
"""
# 定义训练损失数组,记录每轮迭代的训练数据集的训练损失
Cost = []
# 开始进行迭代训练
for i in range(iter):
# 利用学习率alpha,结合BGD算法对模型进行训练
self.BGD(alpha)
# 记录每次迭代的训练损失
Cost.append(self.Cost())
Cost = np.array(Cost)
return Cost
def train_SGD(self,iter,alpha):
"""
这是利用SGD算法迭代优化的函数
:param iter: 迭代次数
:param alpha: 学习率
"""
# 定义训练损失数组,记录每轮迭代的训练数据集的训练损失
Cost = []
# 开始进行迭代训练
for i in range(iter):
# 利用学习率alpha,结合SGD算法对模型进行训练
self.SGD(alpha)
# 记录每次迭代的训练损失
Cost.append(self.Cost())
Cost = np.array(Cost)
return Cost
def train_MBGD(self,iter,batch_size,alpha):
"""
这是利用MBGD算法迭代优化的函数
:param iter: 迭代次数
:param batch_size: 小样本规模
:param alpha: 学习率
"""
# 定义训练损失数组,记录每轮迭代的训练数据集的训练损失
Cost = []
# 开始进行迭代训练
for i in range(iter):
# 利用学习率alpha,结合MBGD算法对模型进行训练
self.MBGD(alpha,batch_size)
# 记录每次迭代的训练损失
Cost.append(self.Cost())
Cost = np.array(Cost)
return Cost
def test(self,test_data):
"""
这是对测试数据集的线性回归预测函数
:param test_data: 测试数据集
"""
# 定义预测结果数组
predict_result = []
# 对测试数据进行遍历
for data in test_data:
# 预测每组data的结果
predict_result.append(self.predict(data))
predict_result = np.array(predict_result)
return predict_result
def predict(self,data):
"""
这是对一组测试数据预测的函数
:param data: 测试数据
"""
# 对测试数据加入1维特征,以适应矩阵乘法
tmp = [1.0]
tmp.extend(data)
data = np.array(tmp)
# 计算预测结果,计算结果形状为(1,),为了分析数据的方便
# 这里只返矩阵的第一个元素
predict_result = data.dot(self.Theta)[0]
return predict_result3、__init__.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/9/1518:47
# @Author : DaiPuWei
# E-Mail : 771830171@qq.com
# @Site :
# @File : __init__.py.py
# @Software: PyCharm
def run_main():
"""
这是主函数
"""
if __name__ == '__main__':
run_main()四、代码运行结果
运行PredictBostonHousing.py文件的 if __name__ == '__main__',得到下述运行结果:
1、测试集可视化.jpg
2、三种梯度算法的平均训练损失.jpg
3、三种梯度下降算法的训练训练损失.xlsx
4、三种梯度下降算法的训练训练损失统计.xlsx
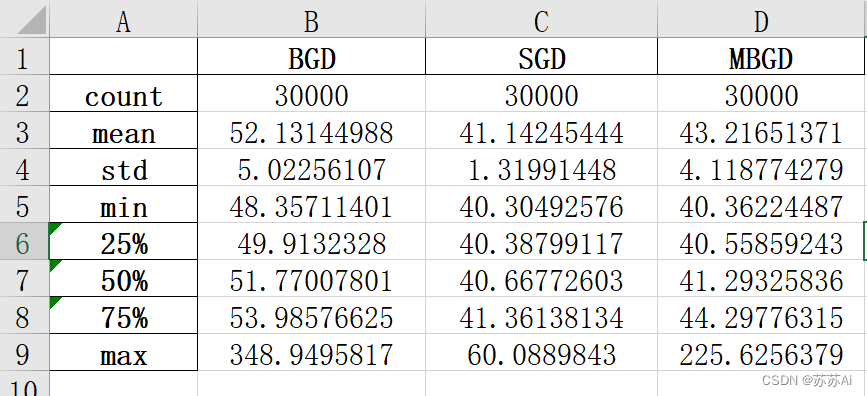
5、预测值比较.jpg
6、测试数据与预测结果.xlsx
7、四种算法的均方预测误差原始数据.xlsx
8、四种算法的均方预测误差统计.xlsx


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}