







ER图
矩形框:
- 表示实体,在矩形框中写上实体的名字
椭圆形框:
- 表示实体或联系的属性
菱形框:
- 表示联系,在框中记入联系名
连线:
- 实体与属性之间;实体与联系之间;联系与属性之间用直线相连,(对于一对一联系,要在两个实体连线方向各写1; 对于一对多联系,要在一的一方写1,多的一方写N;对于多对多关系,则要在两个实体连线方向各写N,M。)。
范式
三级范式
1FN
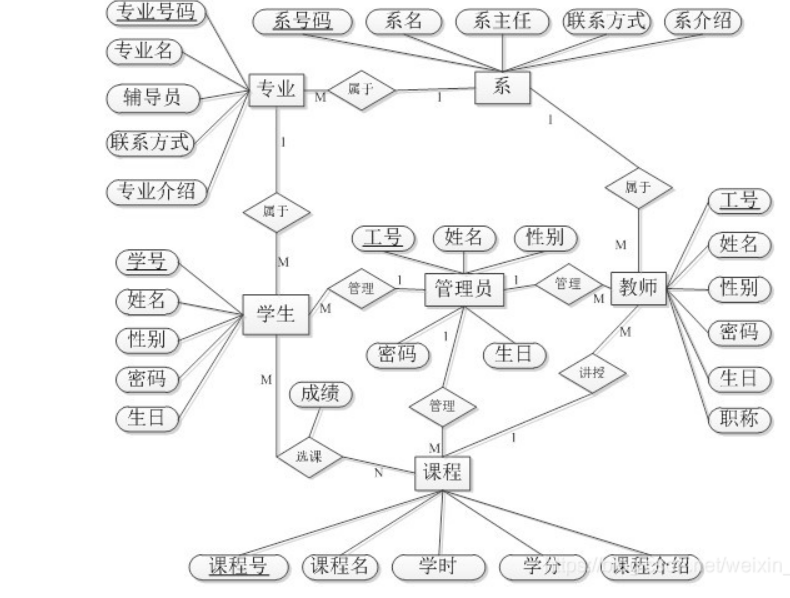
一张表的每一个属性都是原子性的, 就是说不能一个属性不能表示一个集合, 他的语义要是确定的
2FN
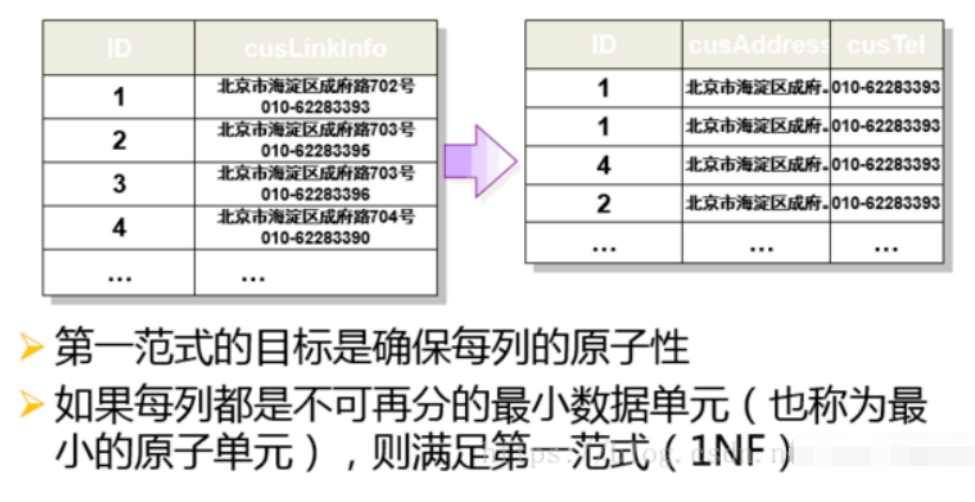
在1FN的基础上, 非主属性直接完全依赖或间接完全依赖候选键。(不可部分依赖候选键), 二级范式要求一张表就表述一件事情
例:学生选课表的设计应该如何实现?
假设选课关系表为学号、姓名、年龄、课程名称、乘积、学分。
那么这个表里面的主键应该为学号和课程名称联合作为主键,这是毫无疑问的,但是不符合第二范式:因为姓名
可以由学号完全决定,和课程名称没有任何关系,也就是说姓名这个非主键字段对这个联合主键有部分依赖关系存在。
同理,学分完全由课程名称来决定,也是部分依赖的。
成绩是不存在部分依赖的,是由学号和课程名称共同决定的
解决不满足第二范式情况的办法是分解主键
建立学生表(学号,姓名,年龄)课程表(课程名称、学分)和选课关系(学号,课程名称,成绩)
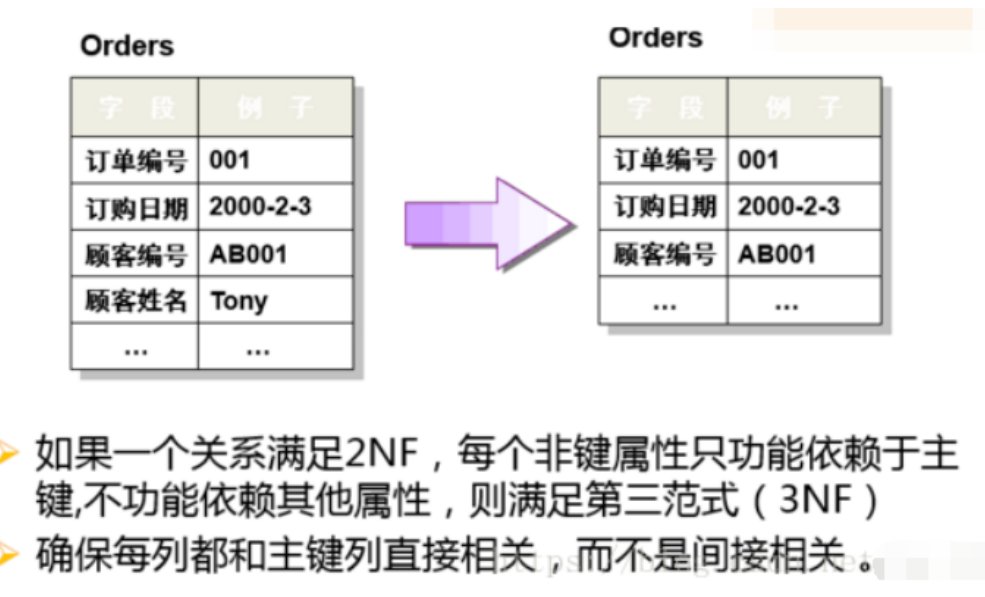
3FN
非主属性直接完全依赖候选键(表中的每一列只与主键直接相关而不是间接相关)
怎么在数据库中的表中表示关系
一对一
- 通过外键或者建立一张关系表
一对多
- 用多的那一端来存放外键(比如部门和领导关系, 假设一个部门只能又一个领导, 一个员工可以是多个不能的领导, 那么就应该在部门中添加一个领导的外键)
- 还可以用关系表方式。
多对多
- 只有关系表方式
分库分表主从备份
分库
- 按照业务模块分库, 没什么好说的
分表
- 将一直大的表分成几张小表
垂直分表
- 将一些字段分离出来带上主键成立新的表, 比如说txt大字段
水平分表
考虑使用水平分表的情况
- 未来表容易达到500W行
- 未来表大小容易2G以上
如何分区(表)
-
在创建表的时候用
-
CREATE TABLE customer703 ( cust_name varchar2(20) , cust_id NUMBER , time_id varchar2(20) ) PARTITION BY RANGE (time_id) ( PARTITION sales_q1_2006 VALUES LESS THAN (TO_DATE('2010-04-01','yyyy-mm-dd')) , partition sales_q_other VALUES LESS THAN(maxvalue) ); -

-
项目中如何使用
Mycat
-
是中间件软件服务, 需要单独的部署
-
配置文件
-
service.xml
-
配置Mycat服务的基本信息, 包括用户名, 密码
-
<user name="test"> <property name="password">test</property> <property name="schemas">lunch</property> <property name="readOnly">false</property> <!-- 表级 DML 权限设置 --> <!-- <privileges check="false"> <schema name="TESTDB" dml="0110" > <table name="tb01" dml="0000"></table> <table name="tb02" dml="1111"></table> </schema> </privileges> --> </user>
-
-
schema.xml
-
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <!-- 数据库配置,与server.xml中的数据库对应 --> <schema name="lunch" checkSQLschema="false" sqlMaxLimit="100"> <table name="lunchmenu" dataNode="dn1" /> <table name="restaurant" dataNode="dn1" /> <table name="userlunch" dataNode="dn1" /> <table name="users" dataNode="dn1" /> <table name="dictionary" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2" rule="mod-long" /> </schema> <!-- 分片配置 --> <dataNode name="dn1" dataHost="test1" database="lunch" /> <dataNode name="dn2" dataHost="test2" database="lunch" /> <!-- 物理数据库配置 --> <dataHost name="test1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user();</heartbeat> <writeHost host="hostM1" url="192.168.0.2:3306" user="root" password="123456"> </writeHost> </dataHost> <dataHost name="test2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user();</heartbeat> <writeHost host="hostS1" url="192.168.0.3:3306" user="root" password="123456"> </writeHost> </dataHost> </mycat:schema>
-
-
rule.xml
-
<tableRule name="mod-long"> <rule> <columns>id</columns> <algorithm>mod-long</algorithm> </rule> </tableRule> <function name="mod-long" class="io.mycat.route.function.PartitionByMod"> <!-- how many data nodes --> <property name="count">2</property> </function>
-
-
Sharding-JDBC
- 两者的区别
- mycat是中间件软件服务, 需要单独的部署; shardingJdbc是jar包
- mycat不需要改造sql, shardingJdbc需要改造sql
常见的分区规则
- 时间范围
- 固定值
- hash
- 一致性hash
- 为什么一致性hash 是2的32次方
- 因为一致性hash算法是来做服务器的负载均衡,而服务器的IP地址是32位,所以是2^32-1次方的数值空间
- (38条消息) 一致性哈希为何2的32次方 - CSDN
- 为什么一致性hash 是2的32次方
其他
-
分表与分区的区别
-
广义上来说, 我们说的分表就是分区
-
狭义上来说
-
分表
- 把一张表粉尘N个表, 对外有感知
-
分区
- 把一张表的数据分成N个区块, 在逻辑上看最终只是一张表, 对外无感知, 但在底层是N个雨里区块组成
-
-
















 2394
2394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











