







 本文详细介绍了推荐系统的传统算法模型,包括协同过滤、矩阵分解、逻辑回归和因子分解机,以及梯度提升树在推荐中的应用。接着探讨了特征工程的重要性,如数据清洗、特征转换和选择。进一步讲解了Embedding的概念和作用,并概述了深度神经网络模型在推荐系统中的应用。最后,文章讨论了工业级推荐模型的架构和推荐流程。
本文详细介绍了推荐系统的传统算法模型,包括协同过滤、矩阵分解、逻辑回归和因子分解机,以及梯度提升树在推荐中的应用。接着探讨了特征工程的重要性,如数据清洗、特征转换和选择。进一步讲解了Embedding的概念和作用,并概述了深度神经网络模型在推荐系统中的应用。最后,文章讨论了工业级推荐模型的架构和推荐流程。
推荐算法模型1
传统推荐算法模型
推荐系统
- 目的:建立一个数学模型或者目标函数去预测用户在某一特定场景下对某个物品的偏好程度。
- 关键:用户、物品、场景
最简单的推荐模型:协同过滤
- 用户对物品的评价:显式评价(用户直接打分)、隐式评价(从用户的行为推断,观看时间、点击次数)。前者需要用户额外的工作,不容易获取,后者相反。
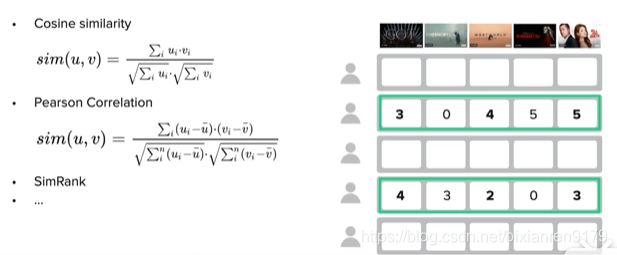
- 交互矩阵:记录每个用户对物品的评价。
- 从矩阵中已有的值预测矩阵中没有出现的评价。

- 协同过滤不考虑用户所处场景,物以类聚人以群分,思想在于:the users who have agreed in the past tend to also agree in the future.
- 将用户对于某个物品的偏好值建模为一系列相似的用户或者相似的物品的一系列加权组合。
r u , i = ∑ v w u v ⋅ r v , i # of neighbors r_{u, i}=\frac{\sum_{v} w_{u v} \cdot r_{v, i}}{\# \text { of neighbors }} ru,i=# of neighbors ∑vwuv⋅rv,i - 关键:如何定义相似度。
- 常见相似度计算方法:余弦相似度(衡量两个向量夹角的大小)、皮尔逊系数(使用了用户的平均分,减少不同用户之间的喜好评价差异)……
8. 相似度计算的改进:对于大多数人都喜欢的作品的喜爱可能不具有很大参考性,应该对具有比较大争议的增加权重;计算相似度的时候考虑共同观看的剧的集数;设置条件过滤掉不是很相似的用户,设置阈值和最大相似用户数(邻居数)
9. 协同过滤的优劣:好处,好计算、可解释;坏处,需要大的内存、数据稀疏导致预测不准。
矩阵分解模型
-
Intuition:表达更高级的属性
-
对每个用户和物品嵌入embeddings(隐含了很多特殊信息的向量)
-
将交互矩阵分解成为两个低秩矩阵获得embeddings。左边矩阵可以分解为右边两个矩阵的点积。矩阵分解的过程为最小化右下角的目标函数:第一项为使embeddings重构交互矩阵的误差尽可能小,第二项为正则项。优化问题可以通过梯度下降的方法来完成。

-
有了embeddings后可以加入不同的元素,即在模型里面加入不同的偏置。
-
矩阵分解的优劣:优势,有一定泛化能力,存储空间小(只需存储低维的embeddings向量);劣势:比起协同过滤来说更难解释,以及稀疏性问题。
逻辑回归模型
- Intuition: add context information to our model
- 将推荐建模成为二分类任务,预测用户和物品产生交互的概率,根据概率的大小来推荐。二分类分为:会交互、不会交互两类。
- r u , i = 1 1 + e − ( W x + b ) r_{u, i}=\frac{1}{1+e^{-(W x+b)}}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









