






交叉分析通常用于两个或两个以上分组变量之间的关系,以交叉表形式进行变量间关系的对比分析。我们将两个具有一定联系的变量设置为行变量和列变量,把统计数据制作成二维交叉表格(数据透视表)。通常使用的函数是pivot_table()。
pivot_table(values, index, columns, aggfunc, fill_value)
参数说明如下:
| 参数 | 描述 |
|---|---|
| values | 数据透视表中的值 |
| index | 数据透视表中的行 |
| columns | 数据透视表中的列 |
| aggfunc | 统计函数 |
| fill_value | NA值的统一替换 |
可以对比excel中的数据透视表
我们用最熟悉的泰坦尼克号的数据来举例。我现在想知道年龄和舱室等级对存活率有什么影响。
#对年龄进行分组
bins = np.arange(0, 90, 10)
age_groups = pd.cut(data['Age'], bins)
data.pivot_table(values=['Survived'], index=['Pclass'], columns=age_groups, aggfunc=[np.mean])
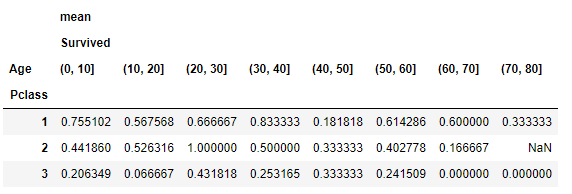
这张表的含义是一等舱中0到10岁的人的存活率为0.755,三等舱中30-40岁的人的存活率为0.253,其他的数据是一样的解读方法。很容易看出几乎每个年龄段的存活率都是一等舱的最高。
下面进行可视化:
for i in [1, 2, 3]:
plt.figure(figsize=(8, 8))
new_df.loc[i].plot(kind='bar', title='Pclass'+str(i)+' survival rate')
plt.xlabel('年龄段')
plt.ylabel('生存率')



交叉分析中的交叉维度最多两个维度即可,如果分的越多分的越细,就越找不到重点了,就越难发现问题和规律。















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









